Pandas库(二)
Pandas库(二)
首先导入pandas和numpy库:
import pandas as pd
import numpy as np
然后读入接下来要使用的数据文件,'豆瓣电影数据.xlsx'。
df = pd.read_excel('豆瓣电影数据.xlsx')
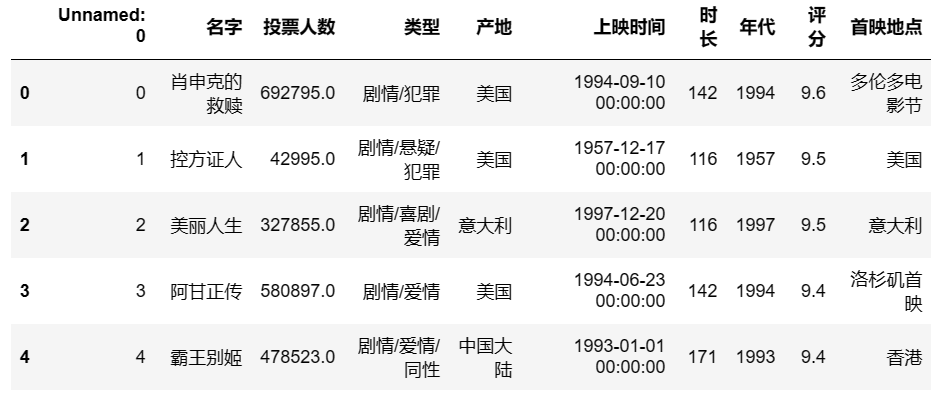
查看数据的前五行:
df.head()
## 输出结果
1. 数据格式转换
-
查看数据格式
dtype# 查看某一列的数据类型 df['投票人数'].dtype ## 输出结果 dtype('float64') -
转换数据格式
astypedf['投票人数'] = df['投票人数'].astype(int) #将投票人数这一列的数据类型转换为整型在进行数据格式转换时如果报错可能存在异常值
2. 排序
默认是按index排序的
-
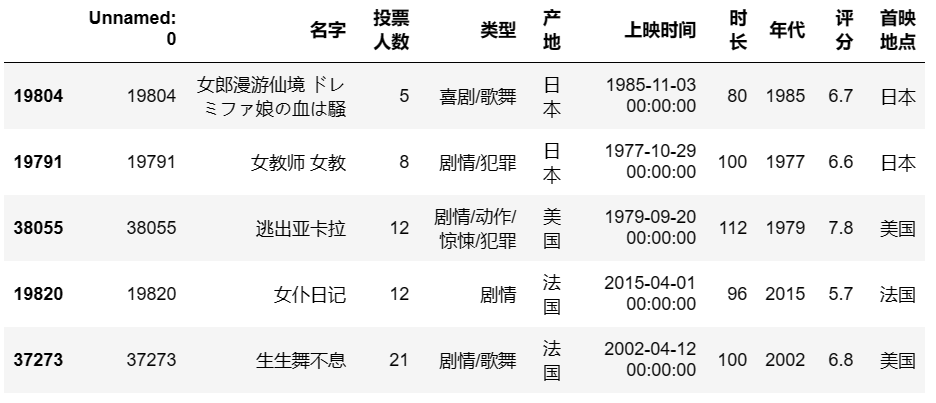
指定按某一列的值排序:
sort_valuesdf.sort_values(by = '投票人数').head() #按投票人数排序,并只查看前5行,默认是升序 ## 输出结果
降序时,使用参数 ascending = False,即df.sort_values(by = '投票人数',ascending = False)
-
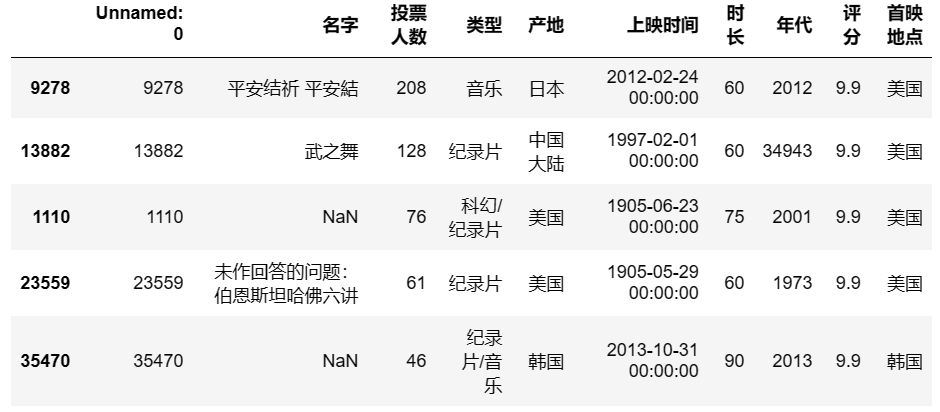
按照多个值排序:
sort_valuesdf.sort_values(by = ['评分','投票人数'],ascending = False).head() #先按照评分降序,再按照投票人数降序,并只查看前5行 ## 输出结果
3. 基本统计分析
-
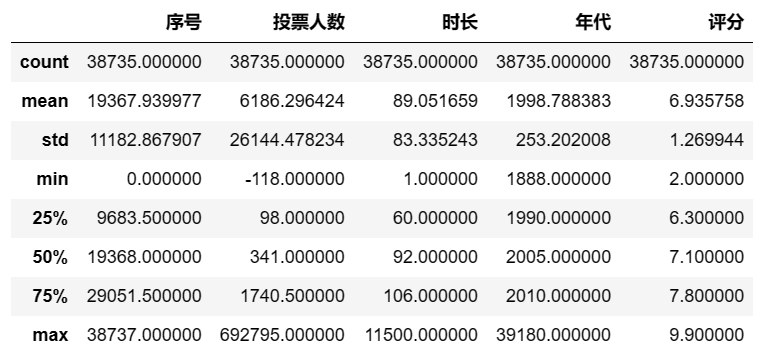
描述性统计
describedf.describe() #对数据df做描述性统计分析 ## 输出结果
-
在做分析时可能会发现一些异常值,可以依次修改或删除,例如:
df.drop(df[df['时长'] > 1000].index,inplace = True) #将时长超过1000的行删除 -
最值
df['投票人数'].max() #求投票人数的最大值,输出结果为692795 df['投票人数'].min() #求投票人数的最小值,输出结果为-118 -
均值和中位数
df['评分'].mean() #求评分的均值,输出结果为6.935560662001942 df['评分'].median() #求评分的中位数,输出结果为7.1 -
方差和标准差
df['评分'].var() #求评分的方差,输出结果为1.6124934753477749 df['评分'].std() #求评分的标准差,输出结果为1.2698399408381258 -
求和
df['投票人数'].sum() #求投票人数的和,输出结果为239625925 -
相关系数,协方差
df[['投票人数','评分']].corr() #求投票人数和评分的相关系数 ## 输出结果 投票人数 评分 投票人数 1.000000 0.122948 评分 0.122948 1.000000df[['投票人数','评分']].cov() #求投票人数和评分的协方差 ## 输出结果 投票人数 评分 投票人数 6.836005e+08 4081.979888 评分 4.081980e+03 1.612493 -
计数
len(df) #查看df的长度,即共有多少行 df['产地'].unique() #查看产地中有哪些唯一值,返回数组 ## 输出结果 array(['美国', '意大利', '中国大陆', '日本', '法国', '英国', '韩国', '中国香港', '阿根廷', '德国', '印度', '其他', '加拿大', '波兰', '泰国', '澳大利亚', '西班牙', '俄罗斯', '中国台湾', '荷兰', '丹麦', '比利时', 'USA', '苏联', '墨西哥', '巴西', '瑞典', '西德'], dtype=object)df['产地'].replace('USA','美国',inplace = True) #使用“美国”替换“USA” df['产地'].replace(['西德','苏联'],['德国','俄罗斯'],inplace = True) #分别使用“德国”替换“西德”,用“俄罗斯”替换“苏联”df['年代'].value_counts().head() #统计每个年代有几行数据,即每年产出多少部电影,默认升序排序,这里只查看前5行 ## 输出结果 2012 2042 2013 2001 2008 1962 2014 1887 2010 1886 Name: 年代, dtype: int64
4. 数据透视
pandas提供了一个类似excel中数据透视表的功能,名为pivot_table
-
基本形式
pd.pivot_table(df,index = ['年代']) #对数据df进行数据透视,以年代为索引,根据年代分类汇总,默认是统计每年各个变量的均值 ## 输出结果
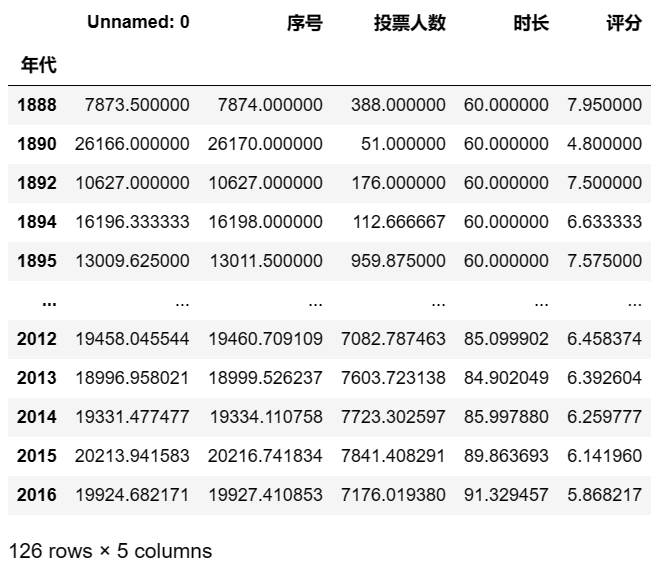
要想中间不用省略号省略,而是全部显示出来,可以通过pd.set_option('display.max_rows',500)设置显示的最大行数。
-
可以设置多个索引
pd.pivot_table(df,index = ['年代','产地']) ## 输出结果
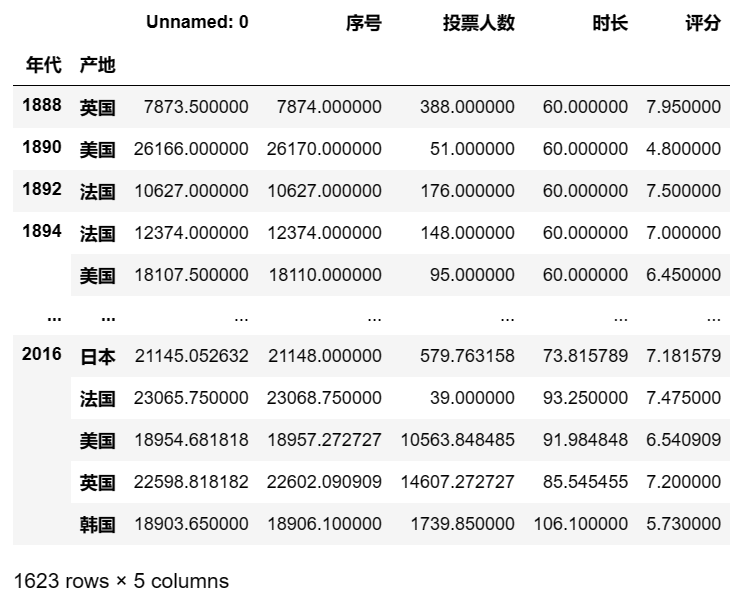
-
可以指定需要统计汇总的数据
pd.pivot_table(df,index = ['年代','产地'],values = ['评分']) #只对评分汇总 ## 输出结果
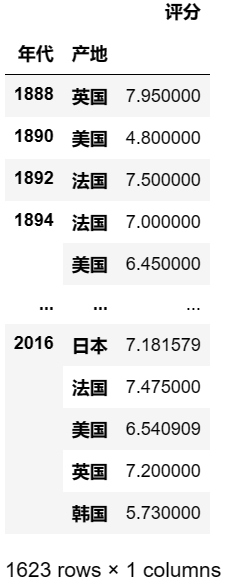
-
可以指定函数,统计不同的统计值
pd.pivot_table(df,index = ['年代','产地'],values = ['投票人数'],aggfunc = np.sum) #统计每个国家每年的总投票人数 ## 输出结果
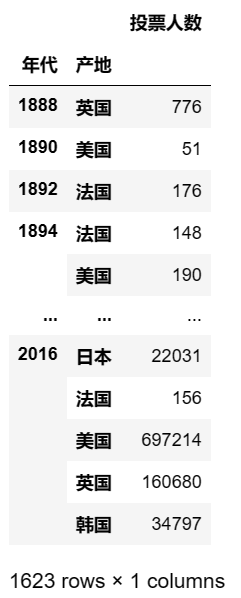
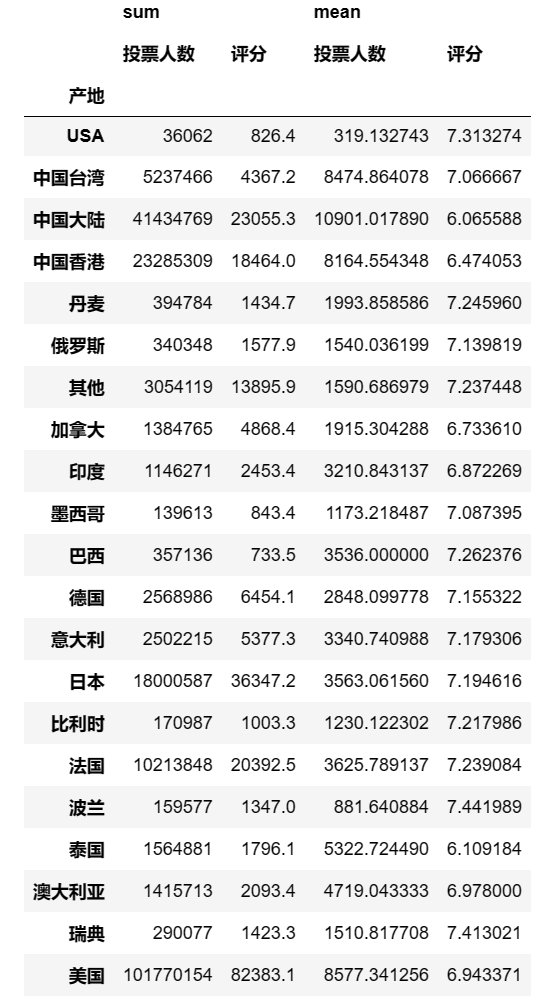
pd.pivot_table(df,index = ['产地'],values = ['投票人数','评分'],aggfunc = [np.sum,np.mean]) #统计每个国家的投票人数和电影评分的总和以及均值
## 输出结果
-
非数字(NaN)可以通过
fill_value将其设置为0pd.pivot_table(df,index = ['产地'],aggfunc = [np.sum,np.mean],fill_value = 0) -
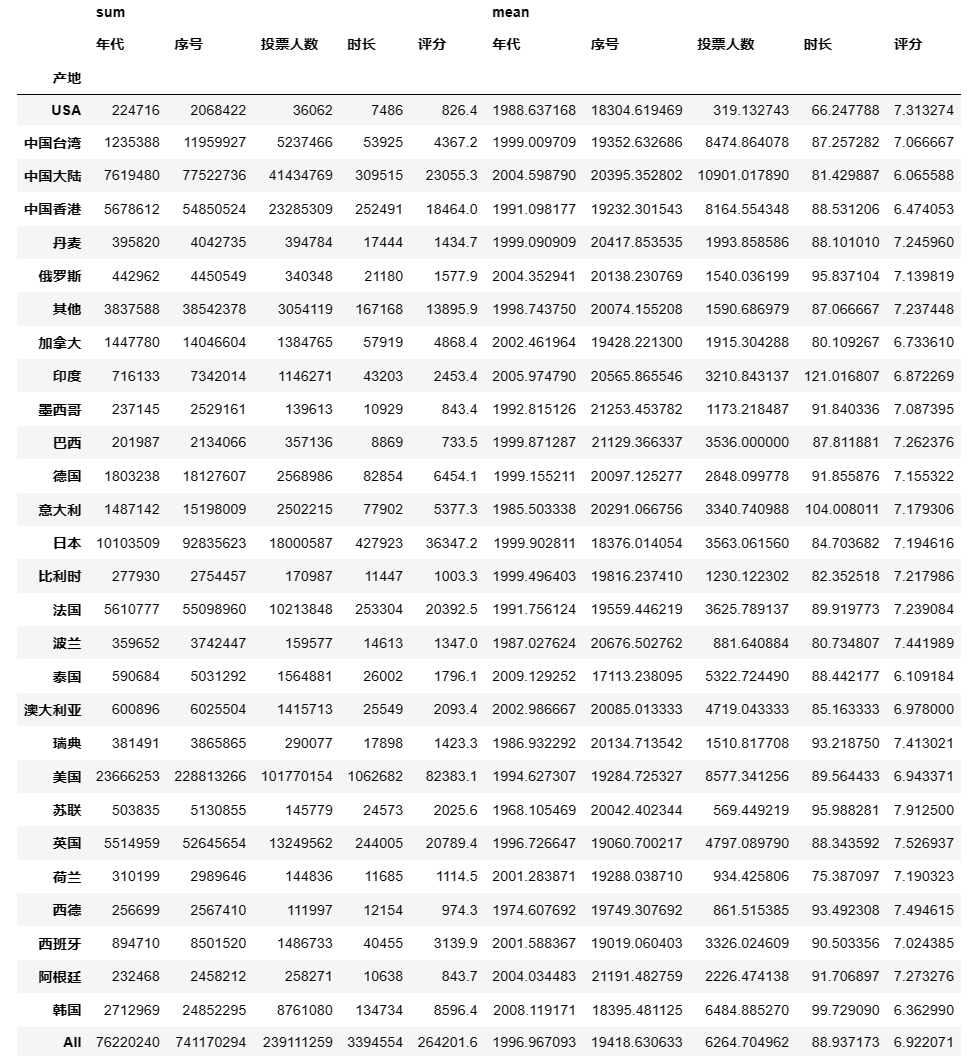
加入
margins = True,可以再下方显示一些总和数据pd.pivot_table(df,index = ['产地'],aggfunc = [np.sum,np.mean],fill_value = 0,margins = True) ## 输出结果
-
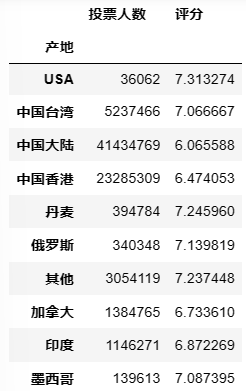
对不同值执行不同函数
pd.pivot_table(df,index = ['产地'],values = ['投票人数','评分'],aggfunc = {'投票人数':np.sum,'评分':np.mean},fill_value = 0) #对投票人数求和,对评分求均值 ## 输出结果,只展示一部分
-
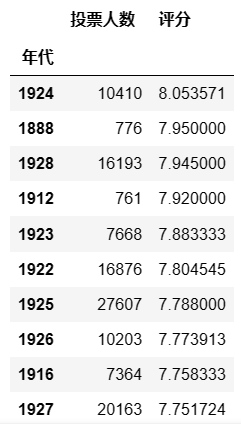
透视表过滤
table = pd.pivot_table(df,index = ['年代'],values = ['投票人数','评分'],aggfunc = {'投票人数':np.sum,'评分':np.mean},fill_value = 0) #将得到的数据透视表赋值给table,table也是一个dataframe,可以对table执行各种操作,例如对评分排序 table.sort_values(by = '评分',ascending = False) ## 输出结果,只展示一部分

 浙公网安备 33010602011771号
浙公网安备 33010602011771号