【Java】【数据库】索引为何使查询变得更快?--B+树
排序数据的二分查找
二分查找的时间复杂度是,明显快于暴力搜索。
索引
建立索引的数据,就是通过事先排好顺序,在查找时可以应用二分查找来提高查询效率。
所以索引应该尽可能建立在主键这样的字段上,因为主键必须唯一,所以这样生成的二叉查找树的效率是最高的。
数据库索引的原理-- B+ 树
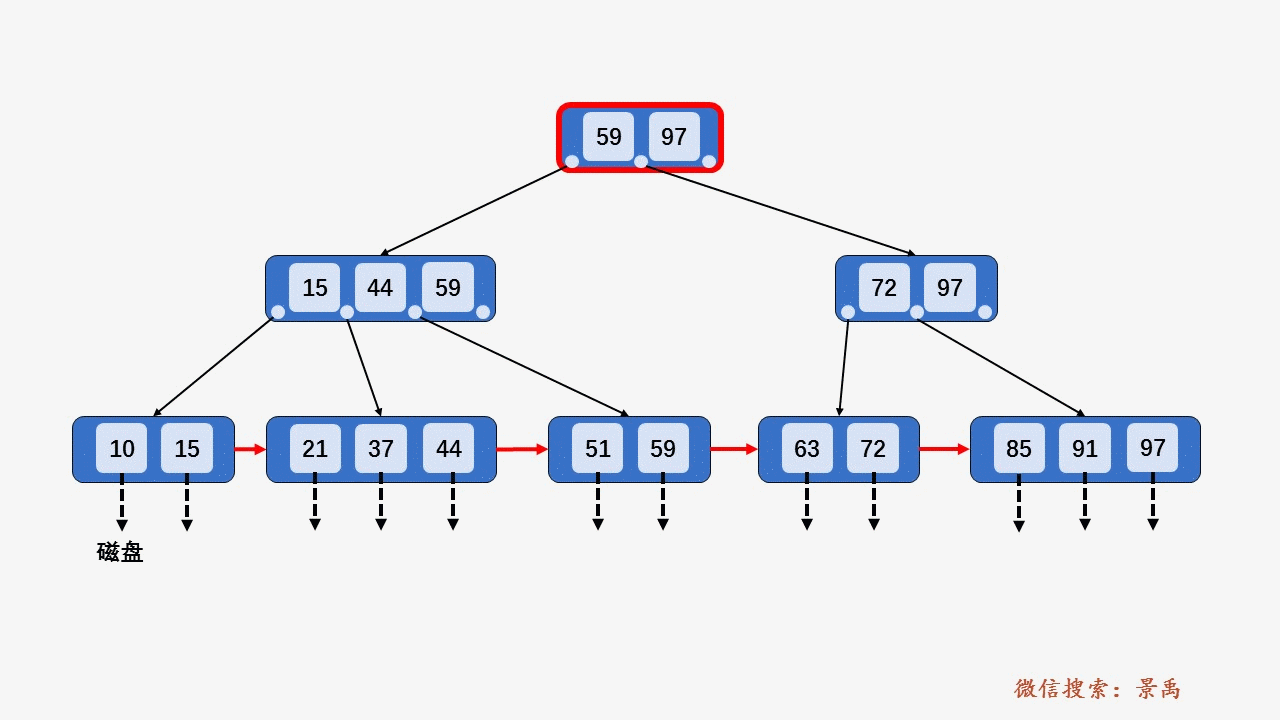
数据库用 B+ 树来实现索引
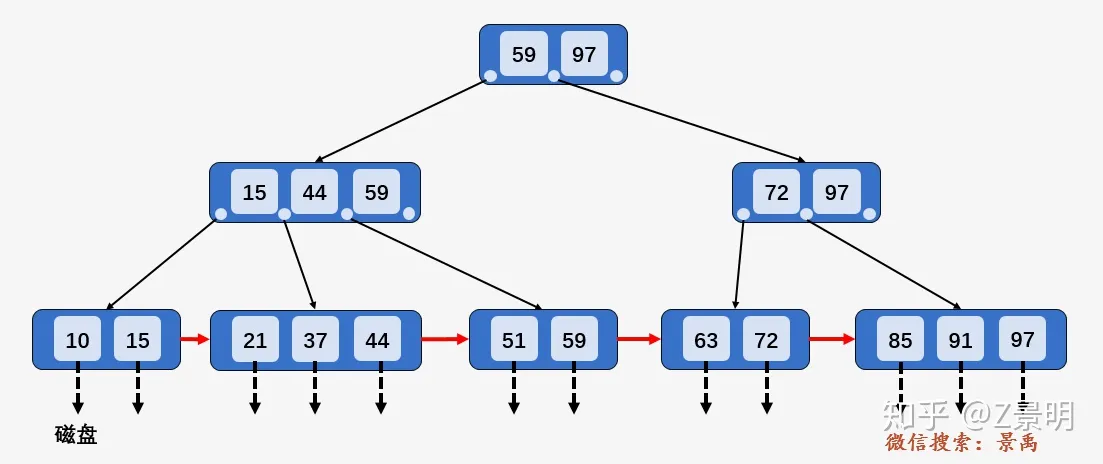
其中, 非叶子节点形如
以第一层为例,.满足数据部分()从小到大有序排列,且指针指向的下一个节点满足 , 例如图中的树,59在它左边节点指向的树里,44在它左边结点指向的树里,15在它左边结点指向的树里,且都是在最右边的位置。
B+树延伸
查找操作
以上图查找为例,
先访问根节点, 发现小于等于根节点中的第一个数, 于是继续访问左边的指针指向的节点, 发现小于等于第三个树, 于是访问左边的指针指向的叶子节点, 遍历找到要查找的元素.
叶子节点的详细结构如下图
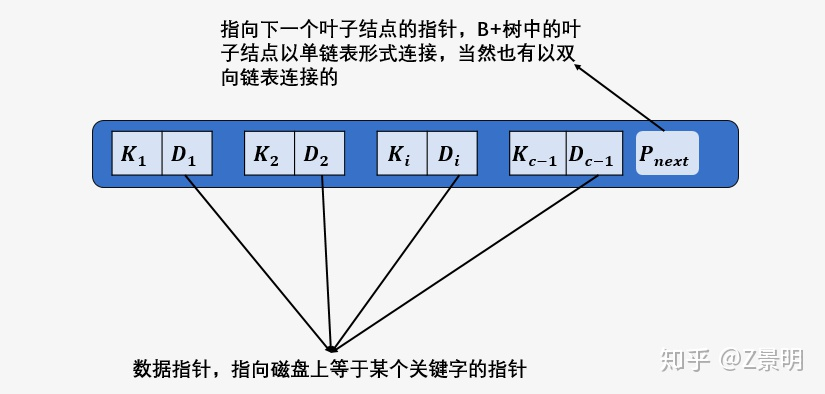
由于数据指针只在叶子节点上,所以 B+ 树所有查询所有关键字的磁盘 的次数都是树的高度。
区间查找
在上面的叶子节点图中,我们可以看到每个叶子节点有一个指针, 它的作用体现在区间查找的时候。
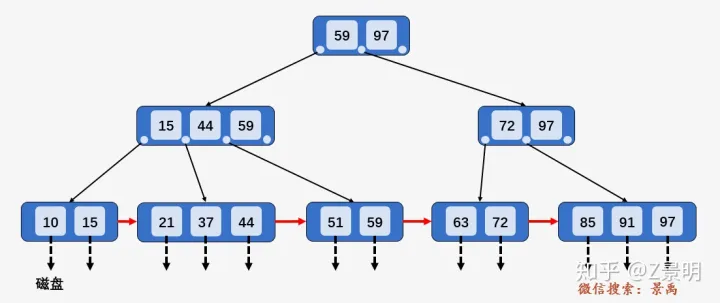
例如,需要查询之间的关键字。
- ,访问左边指针指向的节点.
- , 访问左边指针指向的叶子节点.
- 遍历这个叶子节点找到,下面的操作就如同单链表的遍历,一直遍历到即可.
插入操作
不细说了,这篇文章的动图能说明一切知乎文章
只把动图贴到这里
没有超出叶子结点的最大容量m
超出m,要分裂叶子节点
分裂叶子节点导致上层的节点也超出m,要分裂上层的节点
插入数值比当前最大值还大,要保证新的最大值在根节点中,需要重新调整 B+ 树
B+ 树的复杂度
查找、插入和删除等操作的时间复杂度都是
至于这个结论怎么得出的,还是看那篇知乎文章吧,写得太好了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 周边上新:园子的第一款马克杯温暖上架
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
· 使用C#创建一个MCP客户端