分钟级实时数据分析的背后——实时湖仓产品解决方案
随着信息技术的深入应用,企业对市场的响应速度也在不断提升,而且这种响应速度正在变得越来越快,没有最快只有更快。对数据实时性要求的提高,是眼下很多企业遇到的一个新的挑战。
从生产侧的视角来看,系统实时监控与实时健康状态检测已成为确保系统稳定性和可靠性不可或缺的关键功能。它们能够即时捕捉并处理潜在问题,对系统的顺畅运行起到保驾护航的作用。而在营销侧领域,搜索推荐、实时营销策略制定以及分钟级趋势分析能力,则成为了企业运营团队的核心竞争力。具体到业务实操层面,实时欺诈检测技术、异常交易监测机制、精准的行为认证手段和高效的账户校验系统等,在现今的商业环境中都扮演着至关重要的角色。
简单来说,数据的时效性,是否足够“快、精、准”,会真正影响到一个企业的生存。
随着技术的发展,湖仓一体的概念开始被提出,袋鼠云在结合当前数据湖技术的基础上,建设实时湖仓平台,满足客户亟待解决的数据需求。本文将详细介绍实时湖仓解决方案,让企业能够更专注地去解决他们的业务价值。
实时业务场景遇到的问题
数字化时代,实时数据运用广泛,尤其在互联网、电商、金融等行业,实时数据反馈对业务运营和决策制定至关重要,对于数据时效的要求都达到了分钟级甚至秒级。
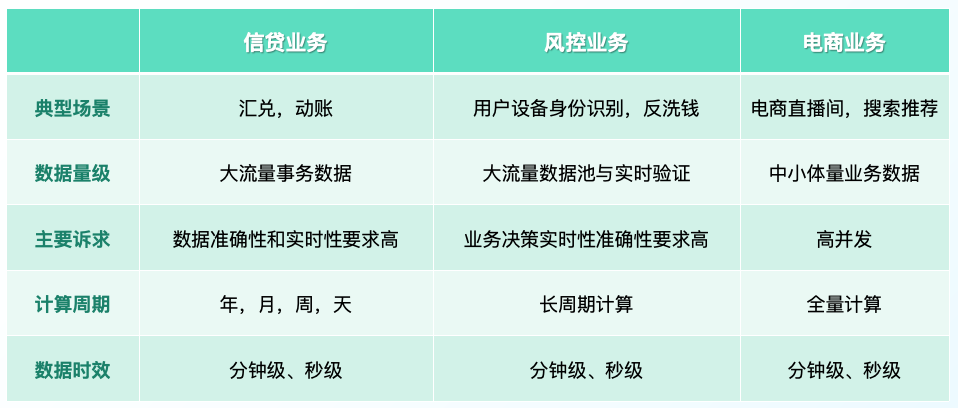
下文以信贷业务的银行动帐场景为例,介绍当前实时数据应用的业务场景,以及遇到的困境。
动帐交易,主要指开通帐户线上发生的业务,包括支付转帐、内部转帐、转存、网上缴费等交易。如:“交易流水表” 23:00:00,张三转入100元;“客户表” 张三的余额从100元更新为200元。
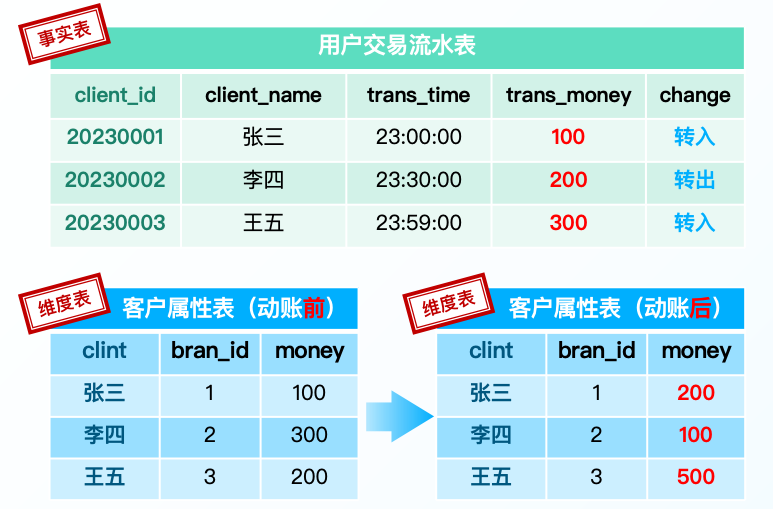
每次的一次动账操作都是一个事务,至少要操作两张表。第一张表是交易流水表,记录转账的一次行为,第二张则是用户的属性表,其中有一个字段是用户的余额,需要随着转账同步更新。
• 用户交易流水表
主要为 Insert 操作,记录行为信息,适合增量计算,如:统一开户、取款、贷款、购买理财等事件行为。
• 客户属性表
主要为 Update 操作,记录属性信息,适合全量计算,如:客户存款、贷款、理财、基金、保险等产品的余额。
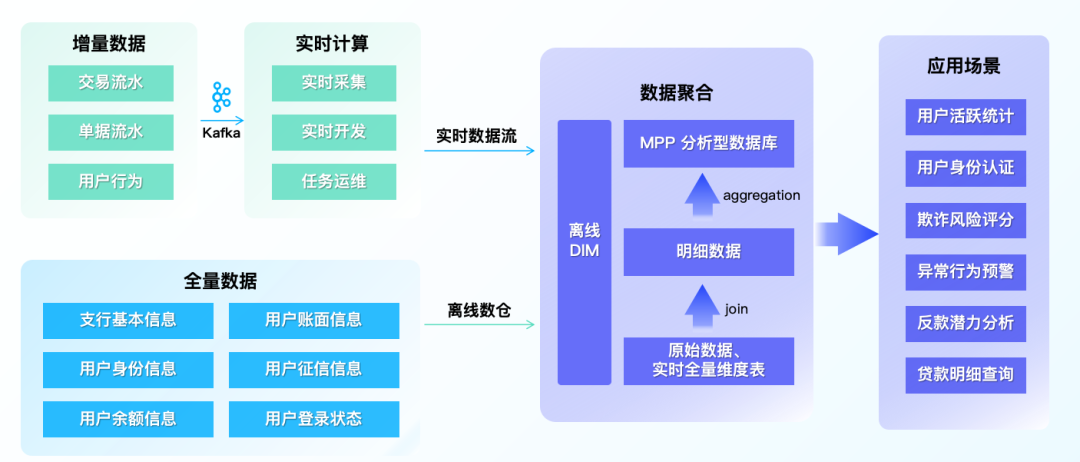
在湖仓技术出现以前,企业在做数据建设时基本采用 Lambda 架构实现流和批数据流的架构。原因在于,Lambda 架构是当时比较成熟稳定的流/批数据处理模式,在各个领域的应用也非常广泛;同时因为其耦合度低,标准化高的优点,使得 Lambda 架构数据处理模式可以更简便、高效、稳定地应用于各个场景。出于稳妥的考虑,大多数企业会将 Lambda 流批分离的方式建构实时和离线的数仓。
应用在银行动帐场景中,如下图所示:
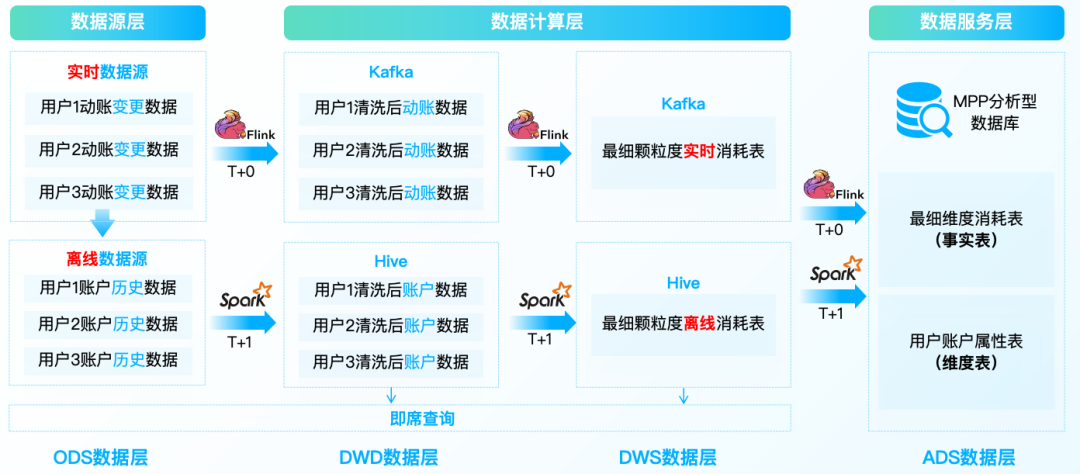
但是它有很多致命的弱点:
· 数据具有二义性,难保证一致
· 数据重复计算,资源占用多
· 需要开发和维护两套代码逻辑
· ……
同时,Lambda 架构下 Hive 和 Kafka 也存在问题。Kafka 作为高性能的消息队列和流处理平台,数据无法持久化存储,并且不支持直接 OLPA 查询。
Hive 作为大数据仓库工具,存在不支持 ACID,无法同时读写;不支持行列更新,只能全表更新;对于 Schema、Patition 变更不友好;数据查询性能慢等问题。
实时湖仓技术架构
面对上述问题,应该如何应对?袋鼠云给出了「实时湖仓」这个答案。
新型的湖仓一体格式,都有一个共同特点,就是可以做流批统一,比如:流批的读写接口都具备,拥有 ACID 的能力,流批一体可以并发去读写。能够很好地解决 Kafka 和 Hive 中存在的问题:
· 基于数据湖存储,可以让流数据持久化
· 支持使用 OLAP 分析引擎直接查询中间结果数据
· 支持 ACID 语义(并发读写),支持行级数据更新
· Schema Evolution 机制,可灵活修改表、分区信息
· 更高效扫描计划,数据查询效率提升
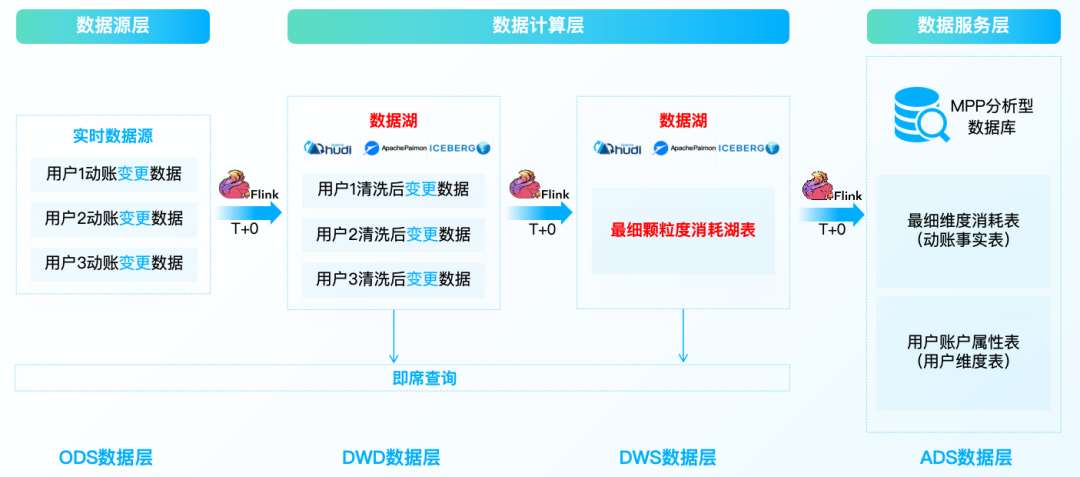
只是湖仓一体还不够,面对如上文所述的实时场景需求,以前的T+1已经不能满足,T+0实时场景越来越多。针对实时场景,做一个新的技术架构,这就是实时湖仓,实现技术与应用场景的支持和融合。
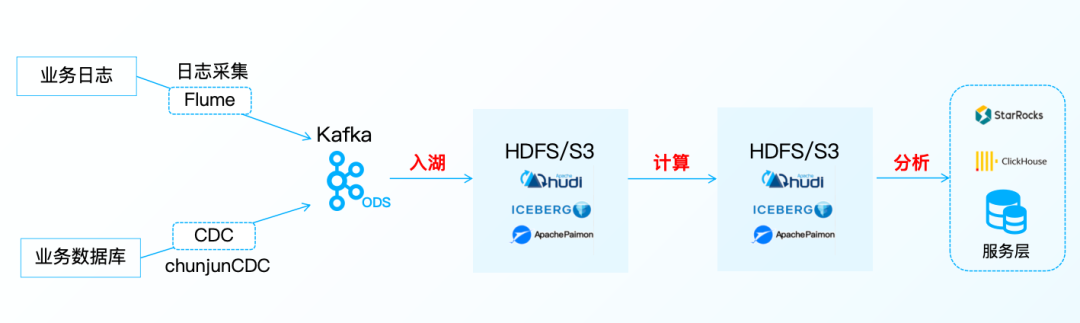
批处理技术在离线数仓场景中扮演关键角色,有效解决了数据更新滞后、表结构变更复杂等长期存在的痛点问题;而流处理则着力于解决流式数仓所面临的挑战,诸如数据不落地导致的易丢失风险。将两者融合为流批一体架构,通过减少数据在不同处理阶段间的流转环节,从而提高了整个系统从数据输入到输出的一致性和可靠性,满足了实时和历史数据分析的双重需求。
技术上,通过流批一体设计,实时湖仓能够整合流处理与批量处理,从而有效降低数据链路的重复开发成本;在存储层面,它解决了传统架构中存储分离的问题,实现统一的数据存储管理,进而降低了存储运维成本。同时,在数据管理方面,实时湖仓提供了统一的元数据和权限管理体系,确保了数据的安全性和一致性,实现了从技术到存储再到数据安全层面的高度融合与优化。
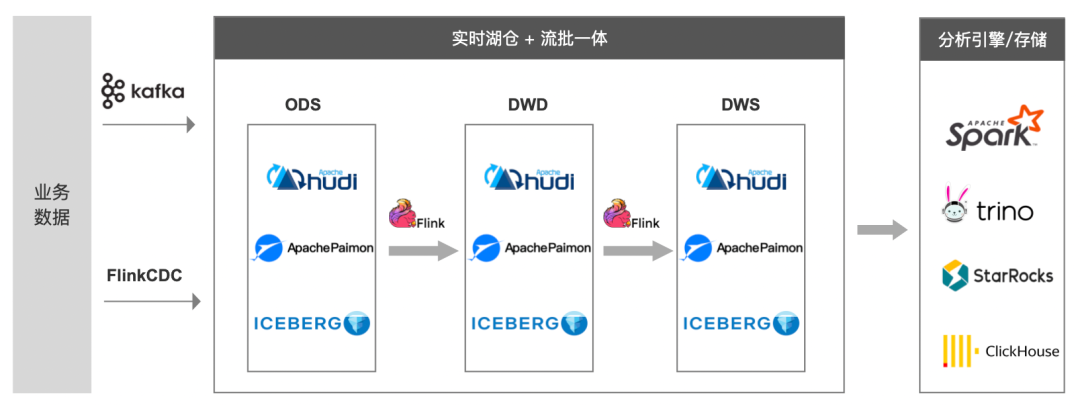
袋鼠云实时湖仓产品解决方案
基于上述实时湖仓技术架构和技术优势,袋鼠云推出实时湖仓产品解决方案。
可以帮助用户快速构建实时湖仓平台,提供流批一体存储、实时湖仓建设、湖内元数据管理、湖内数据治理、湖内数据探索的能力。解决传统数仓的痛点难点,无缝对接不同的计算引擎,为数据价值挖掘提供统一的数据基础。
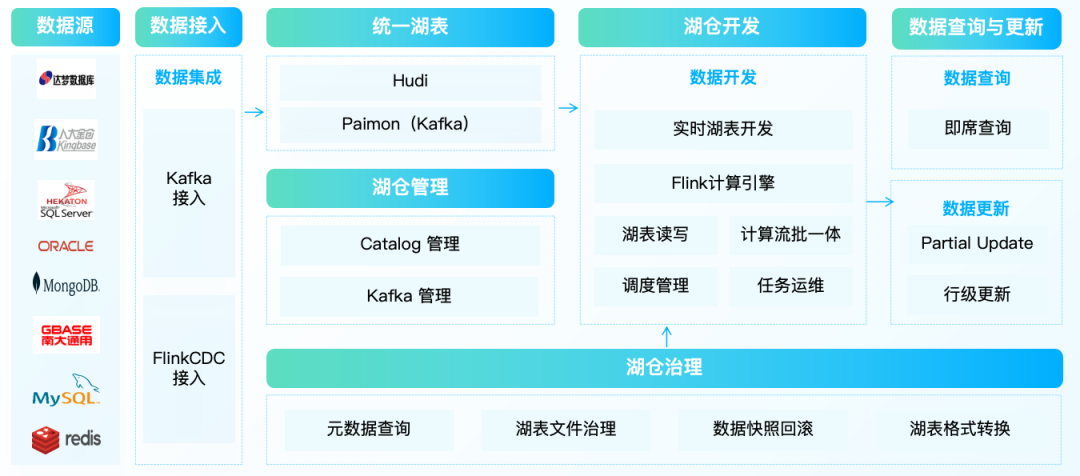
湖仓管理,建设实时湖仓的基础,通过这一层的建设,你可以:
· 借助 Flink Catalog 管理,构建一套虚拟湖仓分层架构,类似传统离线数仓中的主题域、DW 分层设计
· 可视化创建湖表,平台支持 Hudi、Paimon、Iceberg 三种湖表创建,并分别提供对应的 DDL DEMO
· 通过 Flink 表管理,持久化存储基于 RDB、Kafka 创建的 Flink 映射表,和湖表一起,为实时计算提供表管理能力
· 作为实时计算领域最常用的数据介质,平台同时也支持对 Kafka Topic 进行基础的增删改查、数据统计分析等功能
湖仓开发,建设实时湖仓的核心能力,按应用场景主要分为:
· 数据入湖:通过实时消费 Kafka,或者读取 RDB 的 CDC 数据,将业务数据实时打入数据湖,构建实时湖仓的 ODS 层,为后续的流/批读写提供统一的数据基础
· 湖仓加工:借助湖表格式的事务特性、快照特性等能力,通过 FlinkSQL 任务读写湖表,构建湖仓中间层
· 流批一体:在湖仓加工过程中,根据不同的业务场景,可以选择流读或批读。在流批一体的设计上,可以选择先批读存量数据,无缝衔接流读增量数据,也可以选择流读增量数据,批读进行数据订正
湖仓治理,在湖仓开发过程中,我们可以通过湖仓治理能力,不断优化完善实时湖仓:
· 湖表文件治理:在湖仓开发过程中,会产生大量小文件、过期快照、孤儿文件等数据,严重影响湖表的读写性能。通过文件治理功能,可以定期合并小文件、清理过期快照/孤儿文件,提高开发效率
· 元数据查询:在提供 Catalog/Database/Table 基础信息查询的同时,会对湖表的存储、行数、任务依赖等信息进行统计,方便全局判断湖表价值
· Hive 表转换:对于历史 Hive 表,平台支持在不影响历史数据的前提下,一键转换表类型
下文以 Hudi 版为例,具体介绍袋鼠云实时湖仓产品实践。
数据入湖,搭建实时湖仓贴源层
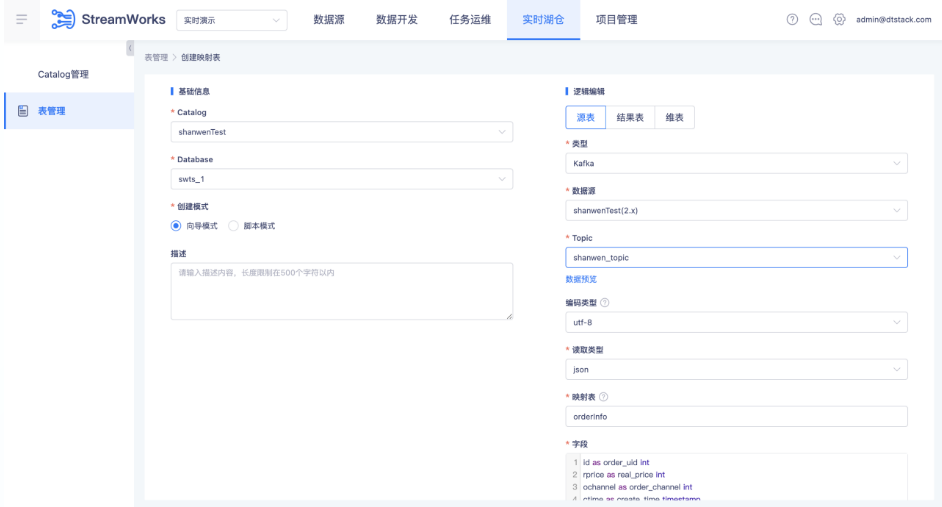
● 创建 Flink 源端映射表
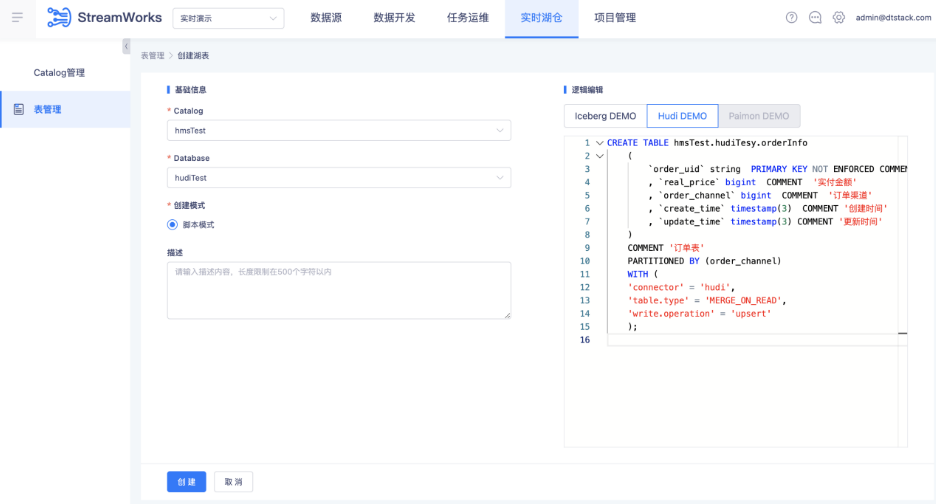
● 创建 Hudi 湖表
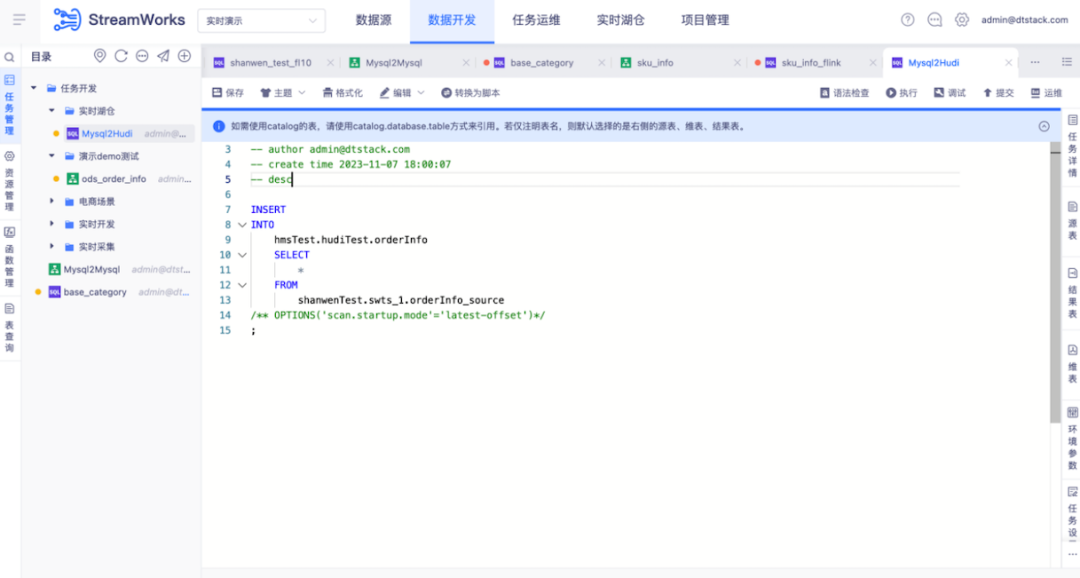
● 开发入湖任务
湖仓开发,搭建实时湖仓计算层
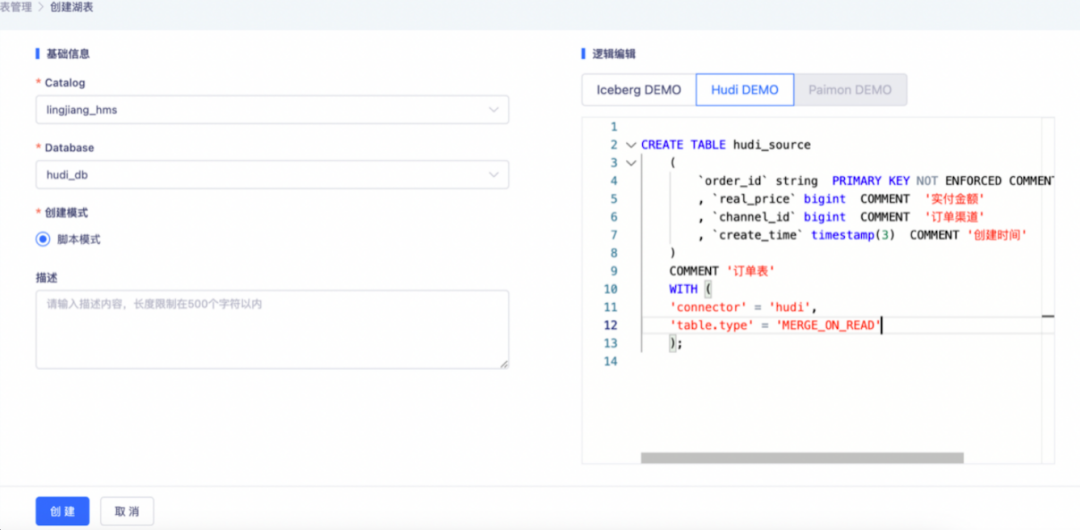
● 创建 Hudi Source 表
● 创建 Hudi Sink 表
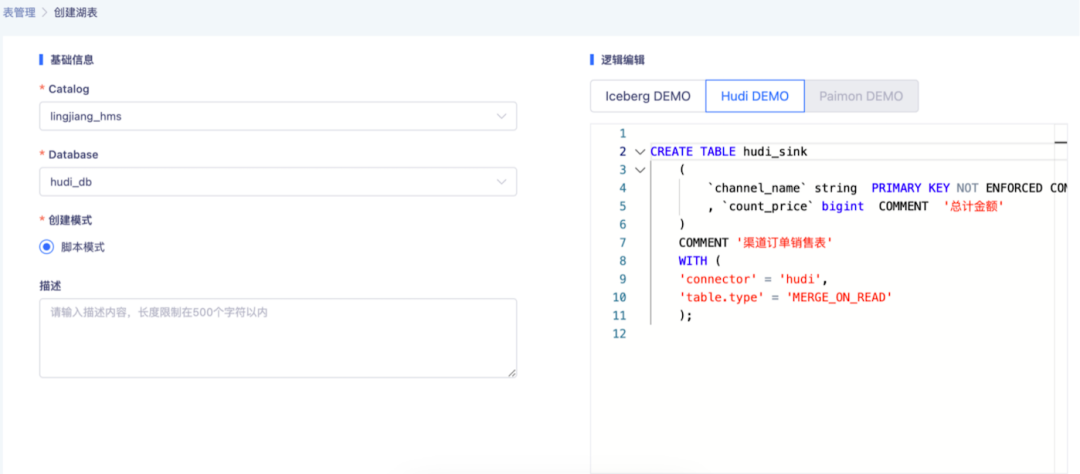
● 创建维表
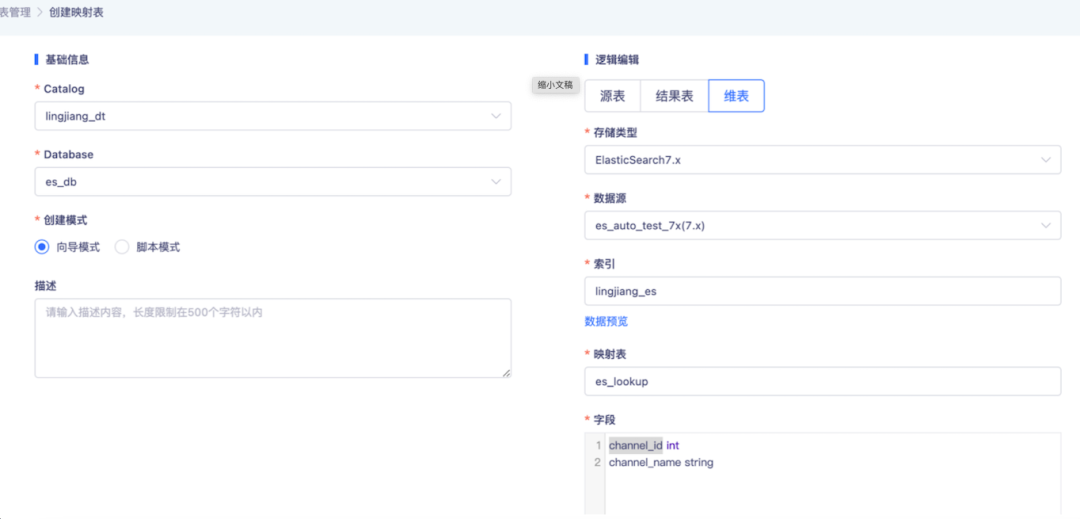
● 实时湖仓开发
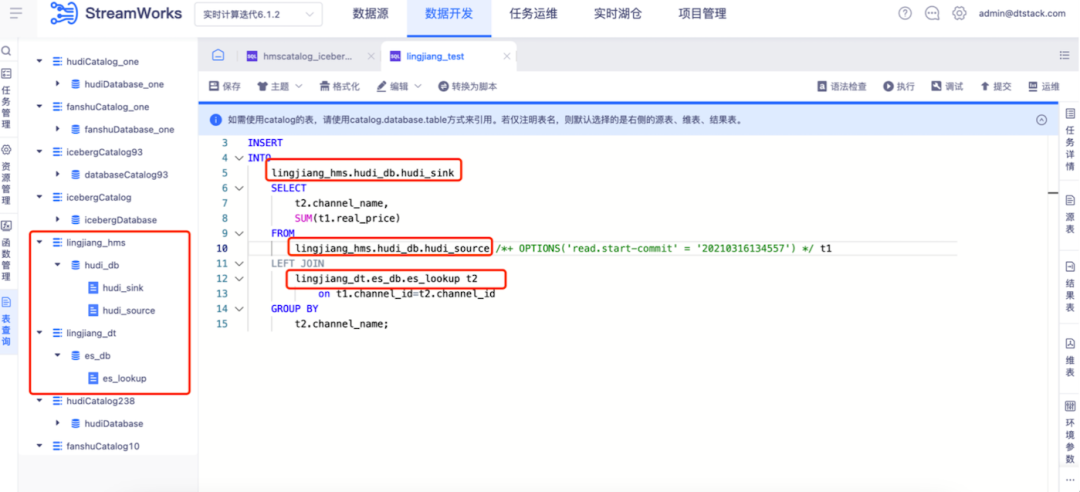
湖仓治理,赋湖表查询和治理能力
● Hive-湖表转表任务创建
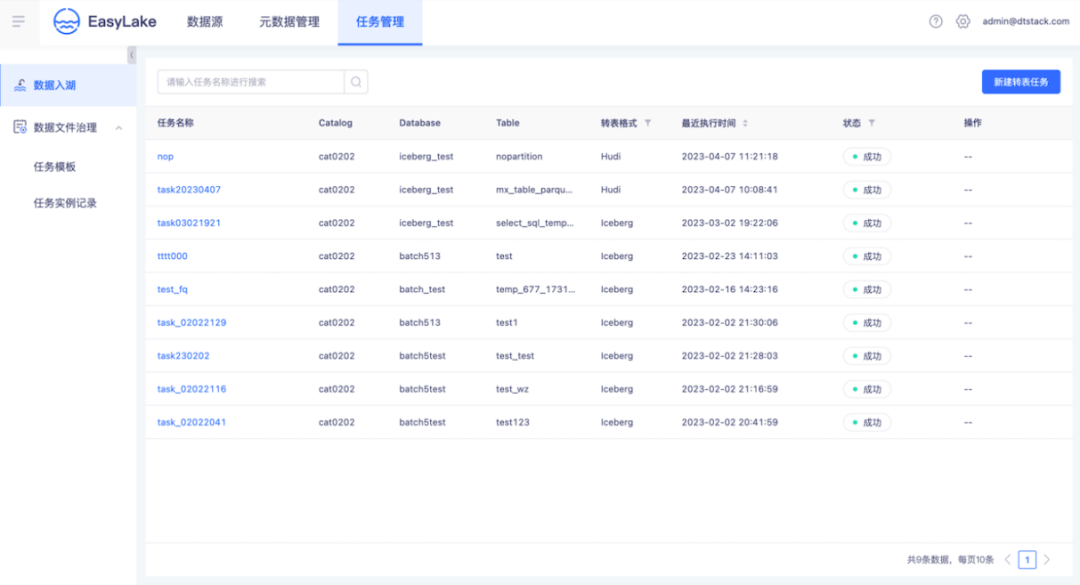
● 湖仓治理任务模板创建
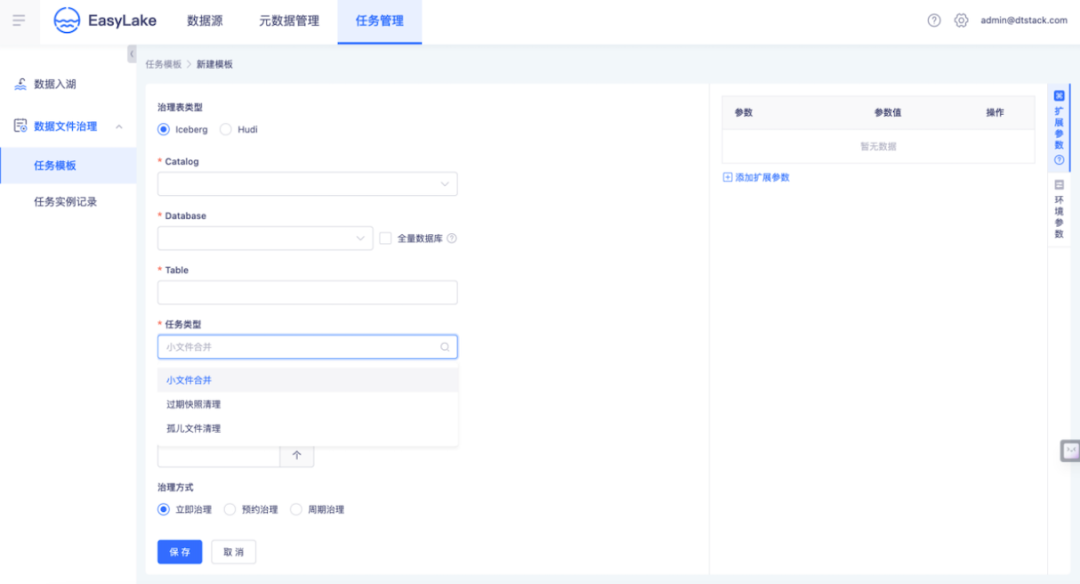
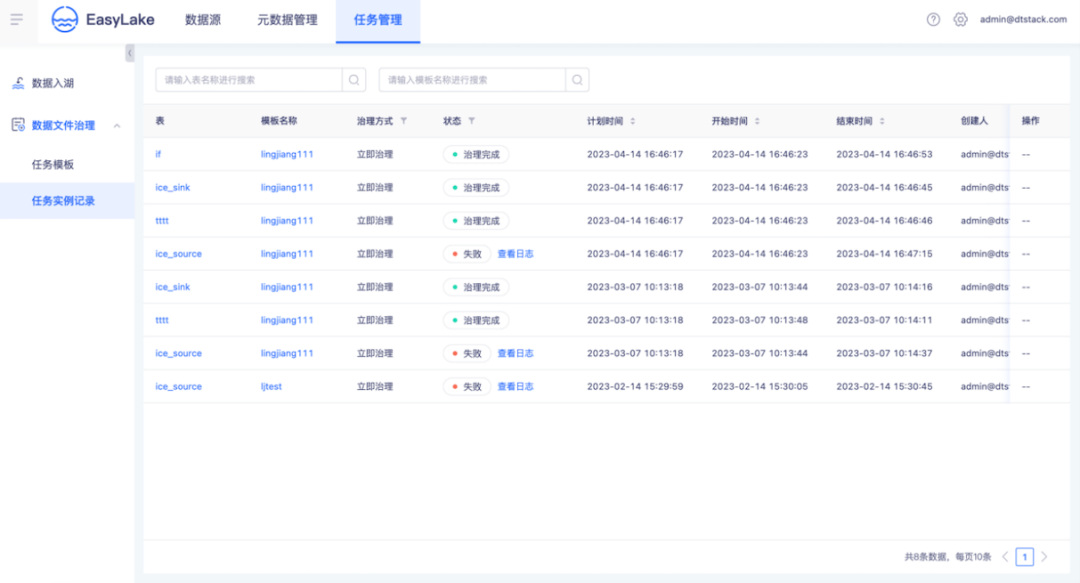
● 湖仓治理任务实例运维
湖仓治理,赋查询和文件治理能力
● 湖仓治理任务模板创建
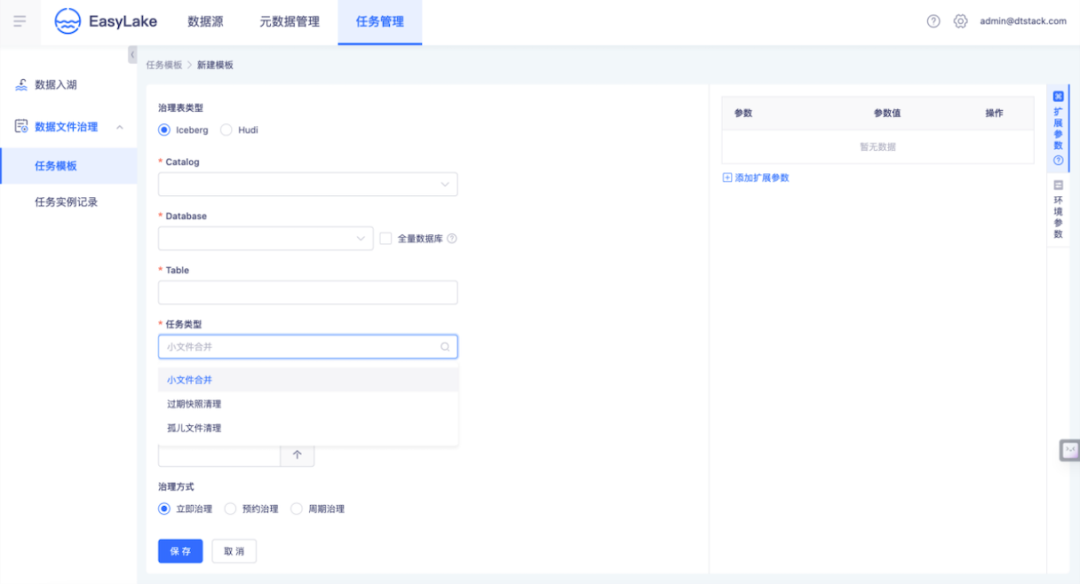
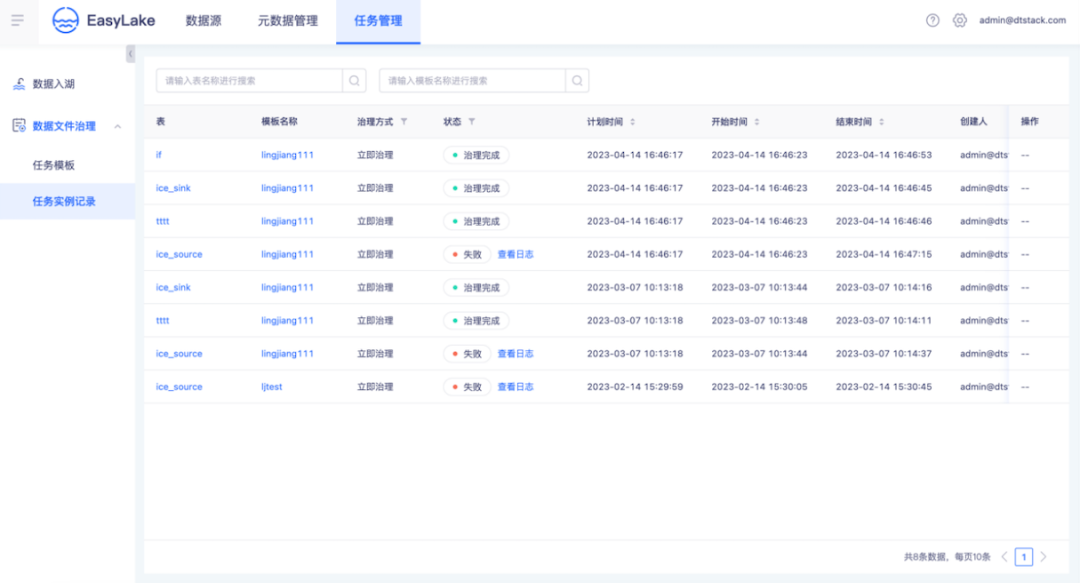
● 湖仓治理任务实例运维
主要特色
袋鼠云实时湖仓产品解决方案以低耦合度为主要特色,提供全方位、端到端的湖仓构建与赋能服务。该方案具备开箱即用和简易部署的特点,通过模块化设计的湖仓功能体系,以及低感知的湖仓构建能力,极大地简化了实施过程。
易用性也是其中的一大特色,旨在释放技术生产力。采用统一封装方式,界面友好直观,不仅支持低代码湖仓搭建,还实现了一站式的数据开发与治理体系,使得用户在操作过程中更为便捷高效。
此外,该方案还具备足够的开放性。它能灵活对接并自由选择各种服务,全面兼容主流数据湖架构及大数据生态系统,并已适配国产化信创环境,确保在多元化的业务场景和个性化需求中都能游刃有余。这种高度开放性和适应性赋予了袋鼠云实时湖仓产品解决方案广泛的适用性和强大的生命力。
本文根据《实时湖仓实践五讲第五期》直播内容总结而来,感兴趣的朋友们可点击链接观看直播回放视频及免费获取直播课件。
直播课件(点击文末阅读原文可直接跳转):
https://www.dtstack.com/resources/1056?src=szsm
直播视频:
https://www.bilibili.com/video/BV1N64y1W73k/?spm_id_from=333.999.0.0
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky

 浙公网安备 33010602011771号
浙公网安备 33010602011771号