实战讲解|Trino 在袋鼠云数栈的探索与实践
当前随着企业内外部数据源的不断扩展和积累,数据呈现出大规模、多样化、质量参差不齐等显著特征。如何有效激活这些结构复杂且类型多样的数据资产,挖掘其深层价值,已成为众多企业亟待解决的实际挑战。
袋鼠云数栈作为新一代一站式大数据基础软件,其核心优势在于不仅提供了快速便捷、易于上手的底层数据开发模块,更推出了涵盖质量、标签及指标等上层偏业务功能模块。这些模块旨在实现对数据质量的有效校验、提升数据加工处理效能以及规范检索流程,从而赋能最上层的业务人员进行自主分析与直观展示。
因此,在技术选型过程中,关键一步便是选择一款集数据ETL、联邦比对、Ad-hoc 查询以及报表展示等一系列功能于一体的全能型底层计算引擎,以驱动整个平台高效运作。
袋鼠云数栈经过技术沉淀与实践,探索出以 Trino 作为底层计算引擎的解决方案,并将此回馈给开发者们。
为什么是 Trino?
Trino 是一种分布式 SQL 查询引擎,旨在查询分布在一个或多个异构数据源上的大型数据集。它通过在整个集群的服务器上分配处理任务来实现横向扩展,基于这种架构,Trino 查询引擎可以在集群内的计算节点并行处理海量数据的 SQL 查询。
Trino 作为一个典型的存算分离 OLAP 引擎,采用了经典的 Master-Slave 架构,即 Coordinator+多个 Worker。其中,Coordinator 主要做以下三件事:
· 接收、处理 Client 的请求,返回查询结果给 Client
· 对 SQL 进行词法解析,随后进行语法/语义分析并优化生成执行计划
· 将物理执行计划以 TASK 的方式分发到 Worker 节点去执行并将结果进行汇总
Worker 是实际的执行节点,主要就做一件事情,执行 Coordinator 分发下来的 TASK。
Trino 的前身便是大名鼎鼎的 Presto。Trino 和 PrestoDB 的架构是类似的,在这里附上 PrestoDB 的架构图:
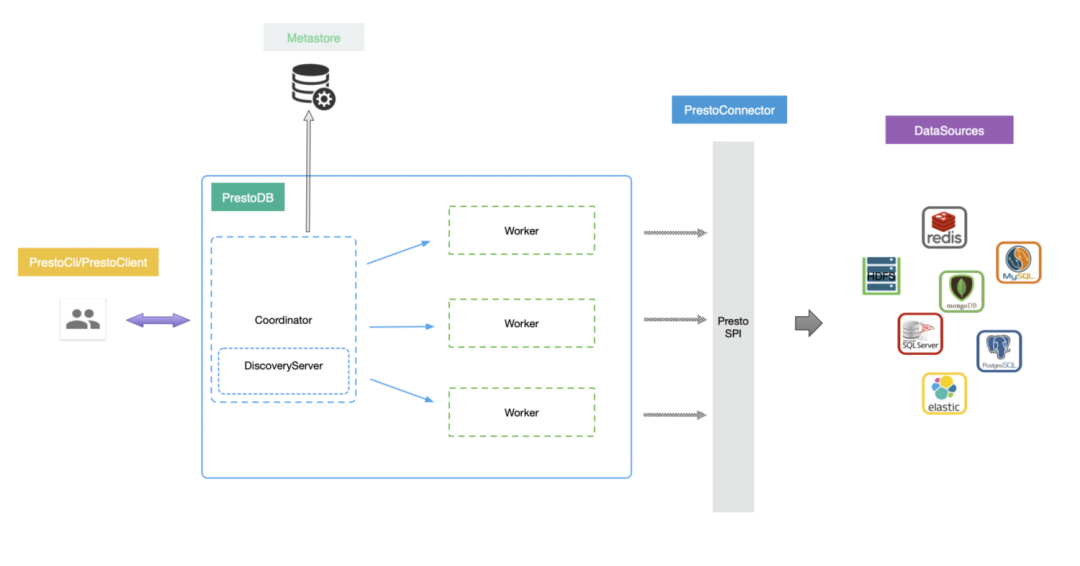
我们对于底层计算引擎的选型同样经历了从 PresotDB 到 Trino 的过程,中间对这两者从功能、性能、社区活跃度几个维度进行过详细的调研。通过对比,我们发现 Trino 相较于 PrestoDB 有以下几个优势:
· 动态过滤优化
· 账号安全认证集成度
· 审计日志集成度
· 更多的 RBO 优化规则
· 享受 Spark 统计信息加成
· 更多的 UDF 函数
· 更多基于 ORC 表格式的查询优化
· 社区的高活跃度,在技术上更加激进
其中,社区的高活跃度、更多的 RBO 优化规则以及享受 Spark 统计信息加成是我们选择 Trino 的根本原因。
Trino 在数栈的部署架构
Trino 在袋鼠云数栈落地的探索实践中经历了两种方式的迭代:混合部署方式和资源物理隔离方式。
混合部署方式
在刚刚将 Trino 选定为指标、标签平台底层计算引擎时,考虑到部分企业的业务量以及数据量规模,我们决定采取 Trino Worker 与 HDFS DataNode 混合部署的策略,这样可以避免跨网络节点的数据拉取带来的查询延迟问题。
在企业业务量和数据规模相对较小的情况下,这种混合部署方式确实能够在满足客户业务需求的 SLA 的同时,还能够达到降本增效的效果。但是当客户的业务量以及数据量达到一定规模时,这种混合部署方式也会随之带来一系列资源竞争衍生出的稳定性问题。
具体来说,当数据量不断攀升时,Trino Worker 节点处理每次查询所需内存峰值也会相应增大。当峰值增长太快而 Trino 来不及做内存回撤时,会直接增加 Worker 的堆内存使用,进而影响其他的业务查询。此外,还可能会间接性增加整个 Worker 的堆外内存的使用量,导致 HDFS 的 DataNode 与 Woker 进行资源的抢占,从而降低了两个系统的稳定性。
资源物理隔离方式
为应对大型企业在数栈指标、标签平台每日面临的海量 ETL 处理、Ad-hoc 查询以及 API 报表分析等业务需求,并考虑到 Trino 只能做软性资源隔离的劣势,我们采取了资源物理隔离的解决方案。同时基于客户业务的时效性要求,我们将原来的一个集群划分成了离线集群和 API 集群,以分别高效地处理客户的 ETL 任务和 API 报表分析等业务,同时利用袋鼠云 EMR 运维工具进行集群部署和管理。
针对负责客户 ETL 任务的离线集群,我们采取了降低任务并发、增加任务的容错配置以及写入并发控制等优化策略,从而显著提升 ETL 任务的稳定性;而对于 API 报表分析等业务,则通过适当增加任务并发、算子并行度等手段,来降低客户 API 报表业务的延时性,确保了整体服务性能和用户体验。
挑战、问题及解决方案
在以 Trino 为底层计算引擎,袋鼠云数栈服务企业的过程中,我们也遇到了一些具有代表性的问题以及痛点,在这里分享一部分数栈的解决方案。
任务并发运行数量大带来的任务间稳定性问题
日常情况下,我们同时使用 Trino 的在线用户可能在个位数,运行 SQL 的并发数量屈指可数,因此不会存在用户任务之间资源竞争的问题。但是当我们面临的客户群体规模是「总行+N分行」时,在线用户数和 SQL 执行的并发请求量会显著增加。在这种情况下,受限于当前有限的系统资源,一旦某个分行的任务运行时间较长且占用大量资源,就极有可能导致其他分行的任务响应速度大幅降低,甚至出现任务执行失败的情况。
● 原因分析
Trino 不能够承担很高的并发运行情况,主要在于两点:
· 海量的数据规模导致 Trino 不得不消耗大量的资源去进行快速计算
· TCP 通信的连接数限制会导致大量任务并发运行时 block 或者直接失败掉
● 解决思路
根据当前的 Trino 集群情况,通过配置资源组,合理限制各个分行的任务并发数量,同时限制任务运行的最大执行时长、Memory 大小、CPU 使用时长。这样,既能够保证正在运行的任务稳定性,同时也主动过滤了不合理的任务异常占用资源的情况。更重要的是,通过任务排队的方式,降低任务的失败率,避免影响下游任务的出数。
底层 HiveMetastore 负载过高,任务大量超时失败
数栈客户的主要业务场景之一是通过 Trino 来加速对 Hive 数据的处理以及查询。Trino 与 Hive 的最主要区别是 RunTime 层面不同,一个是基于内存的计算,一个是基于 MR 的计算。本质上 Trino 的 Hive 插件还是依赖 HiveMetastore(下文简称 HMS) 以及 HDFS 做数据的处理以及查询。因此当客户端业务量比较大的情况下,会因为频繁访问 HMS,出现 HMS 内存异常高且访问超时的问题。
● 原因分析
在分析为什么会导致 HMS 负载过高之前,我们得先弄明白 Trino 在哪些步骤会访问 HMS。
通过源码分析发现,Trino 在 SQL 语义分析阶段会通过访问 HMS 来完善每个 Node 的元数据相关信息,后续会借助这些元数据信息生成逻辑执行计划。在对数据进行 DDL 时或者执行 DML 时,也会出现有 HMS 的操作。另外 Trino 基于 Thrift 协议自己实现了一套 HMS 的 Client 端,并实现了失败重试以及高可用功能。
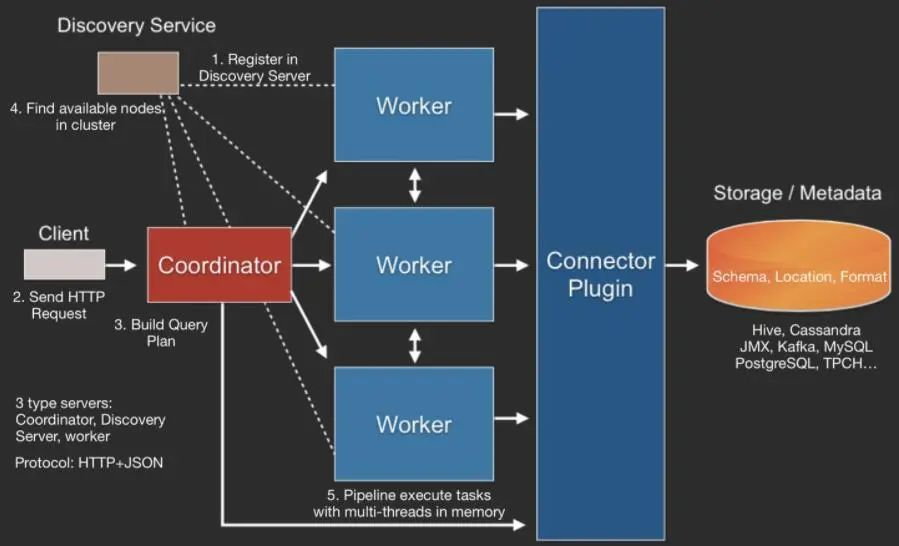
但是我们发现 Trino HMS Client 的失败重试只是针对于连接失败,当一台 HMS 连接不上会去连接另外一台 HMS,而我们现在是 socket read timeout 类的失败。这样的话,即使任务失败了,那么下一次 Trino 还是会连接这台 HMS,从而导致 HMS 持续高负载低响应。其中,由于 Trino 和 PrestoDB 在执行过程上差别不大,在这里附上 PrestoDB 的 SQL 执行过程原理:
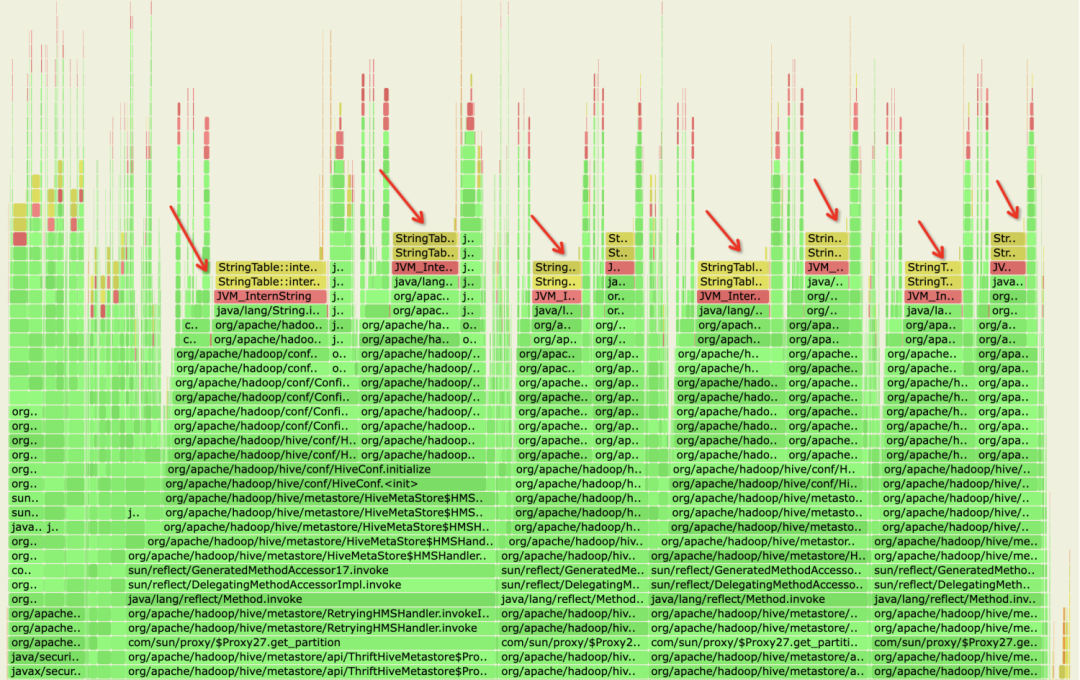
随后我们又基于 HMS 的 gc 日志以及火焰图进行分析,发现平台性能瓶颈都出现在 String.intern() 这个方法上。具体来说,当 String.intern() 被调用后,底层会从一个 hash table 的数据结构中找同名字符串,在数量较大时会导致 hash 碰撞使 CPU 占用升高。
除此之外,我们从 HMS 的元信息数据库 MySQL 中看到表数量和分区数分别达到了十万级别跟百万级别。
● 解决思路
基于上述分析,我们决定从 HMS 和 Trino 两方面入手。
在 HMS 层面,我们调整了 JVM 参数:
-XX:StringTableSize=20000000
但是好景不长,半个月左右问题再次复现,鉴于此,我们开始质疑问题可能并非仅局限于 StringTable 本身,而是怀疑是 StringTable 中的数据没有释放。
在网上搜索“G1 CMS StringTable”关键字查找到 JDK 的一个相关 bug:https://bugs.openjdk.org/browse/JDK-8180048
G1 垃圾回收器在回收 StringTable 上存在问题,效率不及 CMS。最后通过将 Hive MetaStore 的垃圾回收器由 G1 调整为 CMS,问题得以解决。
在 Trino 层面,我们开启了 Metastore 的缓存,考虑到 Coorinator 内存的限制,我们设置了缓存的最大数量。其配置如下:
hive.metastore-cache-ttl=2h
hive.metastore-refresh-interval=1h
hive.metastore-cache-maximum-size=5000000
hive.metastore-refresh-max-threads=30
hive.metastore-cache.cache-partitions=true
另外,基于客户当前的数据量规模,我们发现在某些特殊的场景下 HMS 接口调用20s的超时时间是远远不够的,而 Hive 社区在0.14版本就已经将 HMS 20s的超时时间调整到600s来提高稳定性,因此我们也将 Trino HMS 超时时间调整到了600s:
hive.metastore-timeout=600s
最后,我们优化了 Trino HMS 的访问策略,增加了 RoundRobin 模式,来对 HMS 的请求做负载均衡,避免单台 HMS 的请求负载过高。其配置如下:
hive.metastore.round-robin=true
● 实际使用效果
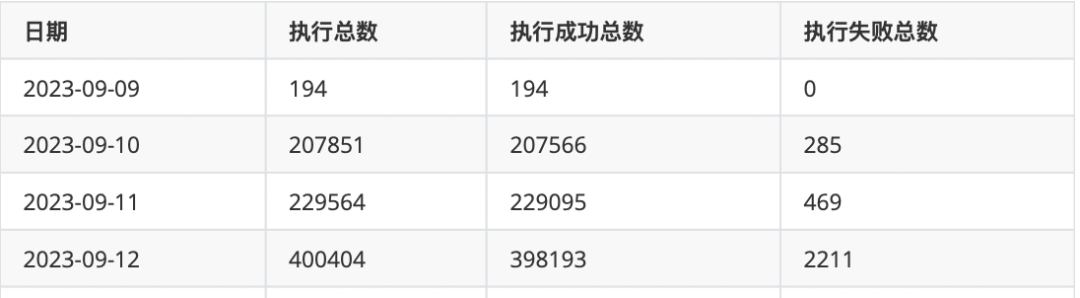
通过上述的调整之后,数栈的 Trino 集群基本上能够满足日均10w+ETL 任务的快速稳定运行。在这里附上内部离线集群部分日均调用情况:
Catalog 配置后冷重启导致业务中断
在客户使用数栈时,经常有很多需要跨数据源的联邦查询场景,因此不得不频繁对 Trino 配置静态 Catalog 文件并进行重启,这样就会影响当前正在运行的任务。因此,我们开始思考如何实现 Catalog 的动态添加与注册。
● 解决思路
如何持久化 Catalog 元数据?
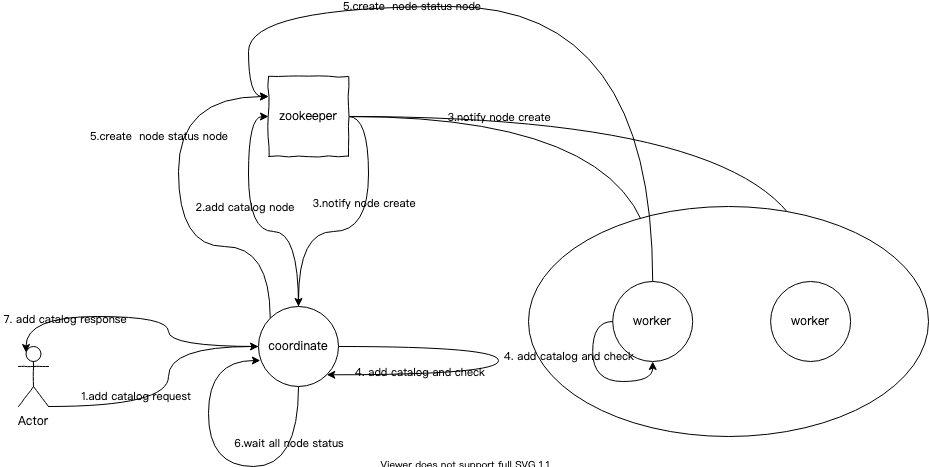
在早期的动态配置 Catalog 方案中,我们选择将 Catalog 元数据保存在 zookeeper 上,默认路径为 /trino/catalog/meta,每一个 Catalog 都会在保存路径下创建一个节点并写入 Catalog 元数据信息。在相应的 Catalog 节点下会存在若干子节点,每个节点代表 Trino 中的一个 Node,节点内容为该 Node 上的该 Catalog 状态信息,该状态信息由各个 Node 定时检测并汇报。
如何操作管理 Catalog?
· 在 Coordinator 中提供出管理 Catalog 的 rest 接口进行访问
· Coordinator 收到请求后会往 zk 上的元数据保存路径下新增一个 Catalog 节点并将 Catalog 元数据信息写入 Catalog 节点
· 随后各个 Node(包含 Coordinator 和 Worker)内的监听线程根据元数据保存路径下的节点事件来通过 CatalogManager 进行操作
· Coordinator 节点在操作完 Catalog 并汇报操作结果后会等待所有节点的操作结果,若在超时时间内获取 Node 的操作结果且都操作成功,那么则认为此次 Catalog 操作成功,否则会认为失败
· 若 Catalog 操作失败,Coorinator 节点会进行事务回滚操作,删除 zk 上的 Catalog 节点以及所有子节点
下图为 Trino 添加 Catalog 的原理图:
● 实际使用效果
从客户使用层面来讲,通过在页面动态配置 Trino Catalog,大幅度提升了客户使用平台的效率,同时降低了客户运维侧的成本。
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky

 浙公网安备 33010602011771号
浙公网安备 33010602011771号