揭秘|来看看袋鼠云数栈内部的资产血缘方案设计与实现
数据资产现在需要接入数栈内部相关应用的时候,支持查看血缘的类型从表、离线任务增加到需要表、离线任务、实时任务、API任务、指标、标签等,需要支持数栈现有的所有应用任务,最终实现在数据资产平台查看任务的完整应用链路。
虽然增加不同的任务,现阶段资产实现的血缘大体上能够满足需求,但是也会出现问题,因此需要进行技术革新。本文将聚焦资产血缘的实现方案,并介绍袋鼠云数栈在数据血缘建设过程中所遇到的挑战和技术实现。
资产血缘的当前问题
现阶段血缘展示内容重复高
在资产的 A 任务血缘链路中,C/D 任务下游均为 E 任务,当我们同时打开了 C/D 任务的下游节点,就会发现大量的重复节点出现,但本质上他们是一模一样的任务节点,如下图。
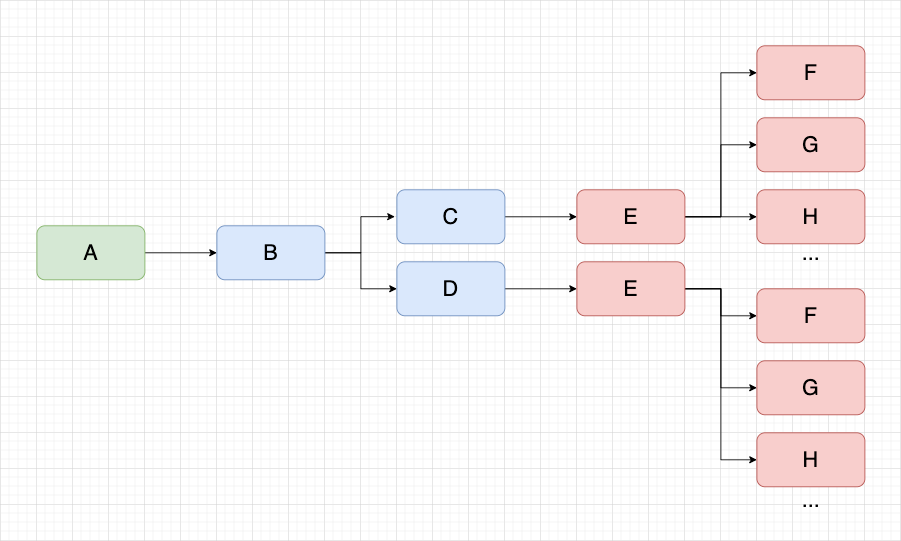
当一条血缘上的任务越多,出现上述问题的概率增大,会导致画布内容显示的都是重复节点,查看血缘关系效率低下。
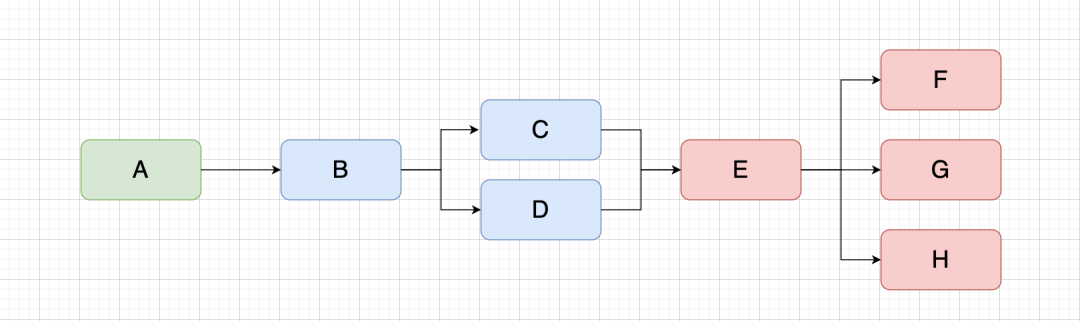
期望能够做到同一个节点只在画布中展示一次,在这个节点存在于画布中时,后续再有相同节点就做共用,如下图。
逆向血缘的展示
先简单介绍一下,何为逆向血缘?用 API 任务举例子来说:
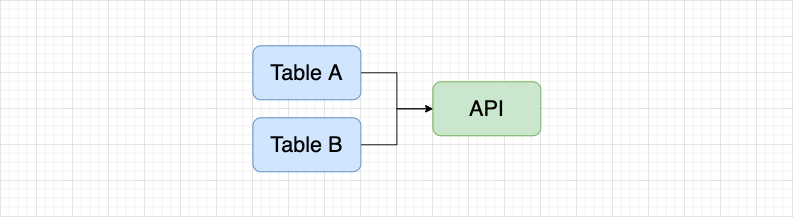
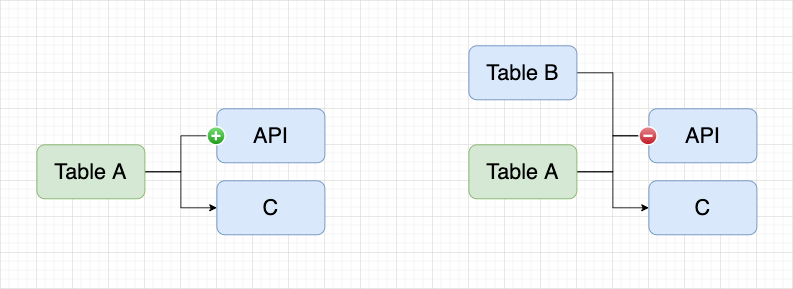
在 API 平台中,通过 DQL 模式使用两张表创建一个 API,在资产平台以 API 任务进入血缘就会展示如下图的血缘关系。如果 Table A 已经同步到了资产平台,以 Table A 表进入血缘,希望展示如下图的血缘关系。
由于 API 是由 Table A/B 共同生成的,因此需要在 API 左侧展示加号,能够将 Table B 加载出来,这就是逆向血缘,也是全链路实现的重要一环。
相似数据源
当同一个数据源被不同的引擎连接之后,会产生不同的数据源A或数据源A1,但是实际上底层是同一个数据源,被我们称之为相似数据源。

此时任务1和任务2并不会有相关联系,但其实它两用的是相同的底层表,展示是不符合期望的,希望能够在血缘展示上将其视为同一张表,相关的任务也能关联展示。
上述问题成为资产实现全链路血缘需要去实现或者优化的当前血缘方案的理由,下文将给出对应问题的解决方案。
资产血缘实现解决方案
前置内容了解
● 任务血缘数据结构
interface ITaskKinShip {
metaId: number; // 元Id
metaType: number; // 元类型
metaDataInfo: object; // 表、api、任务、标签等的元数据信息的元数据信息
lineageTableId: string; // 血缘Id
tableKey: string; // 表key source.db.table
sonIds: number[]; // 子节点血缘定位Id list
fatherIds: number[]; // 父节点血缘定位Id list
sonLineage: ITaskKinShip[]; // 子表级血缘
fatherLineage: ITaskKinShip[]; // 父表级血缘
isOpen: boolean; // 是否存在逆向血缘
}
● 字段血缘数据结构
interface IColumn {
columnId: string; // 字段Id
columnName: string; // 字段类型
columnType: string; // 字段
lineageColumnId: string; // 字段血缘定位Id
withManual: boolean; // 是否手动维护
withMasked: boolean; // 是否脱敏字段
sonIds: number[]; // 子ID
fatherIds: number[]; // 父ID
columnKey: string; // 字段key source.db.table.column
}
interface IColumnKinShip extends ITaskKinShip {
columns: IColumn[]; // 字段血缘
}
● 血缘关系图
· 初始化时默认展示3层:即只展示以数据表本节点为中心,上下游分别的一个节点,共3层
· 节点可扩展:点击“+”按钮,在节点前方或后方再展示出3个节点;点击“-”按钮,断开该“-”按钮对应的连线
· 右键:在非中心节点上,添加右键菜单“查看此节点血缘”;鼠标右键可查看当前节点血缘,以该节点为中心的血缘
整体思路
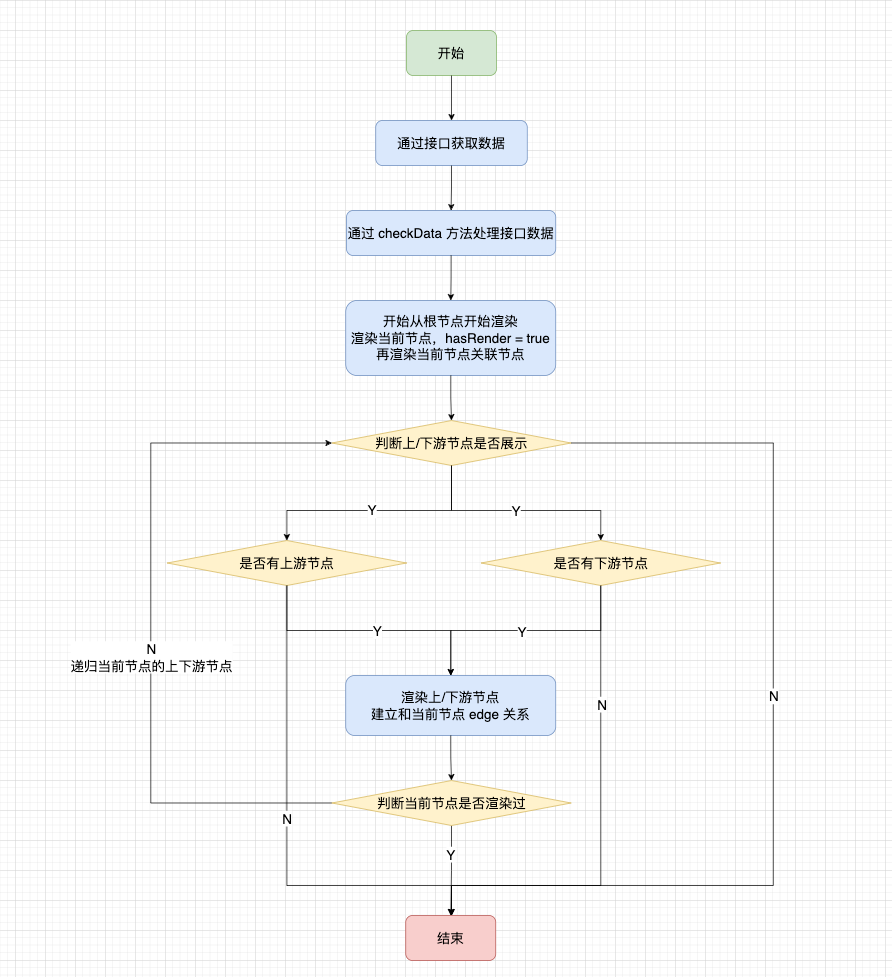
● 实现节点共用
我们想要去实现节点共用,就会去判断当前节点是否已经存在于 graph 中,如果存在我们就不再渲染节点,否则就去渲染节点,这样就可以实现节点只被渲染一次。
对于每一个节点信息来说,tableKey 都是唯一的,因此我们将 tableKey 作为每一个 vertex 的唯一标识,在创建 vertex 时,传入 tableKey 作为唯一标识。
createVertex = (treeData) => {
const { graph, Mx } = this.GraphEditor;
const rootCell = graph.getDefaultParent();
const style = this.GraphEditor.getStyles(treeData);
const doc = Mx.mxUtils.createXmlDocument();
const tableInfo = doc.createElement('table');
const { vertex, fatherLineage, sonLineage, ...newData } = treeData;
tableInfo.setAttribute('data', JSON.stringify(newData));
// 通过 tableKey 在当前 graph 查找 vertex
const cell = graph.getModel().getCell(treeData.tableKey);
// 如果能够找到就不创建新的 vertex,否则创建
const newVertex =
cell ||
graph.insertVertex(
rootCell,
treeData.tableKey,
tableInfo,
20,
20,
VertexSize.width,
VertexSize.height,
style
);
return { rootCell, style, vertex: newVertex };
}
如果我们采用上述的想法,那这个节点可以同时成为中心节点的上游节点和下有节点,甚至就是中心节点。因此我们需要更改我们存储节点的结构,需要存储节点作为上游节点的信息以及作为下有节点的信息。
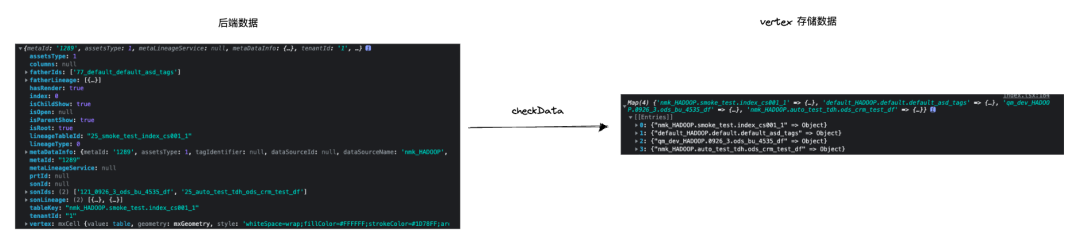
当从后端请求来数据之后,我们需要对数据做一个整理,不再存放在 state 中,而是将其存在以 tableKey 为 key,名为 vertexMap 的 Map 对象中。后续的渲染对象,也根据 vertexMap 去做渲染。
vertexMap 的定义如下,主要用于存储 tableKey 为键值的节点信息。
vertexMap = new Map<
string,
{
rootData?: ITaskKinShip; // 节点作为根节点存储的数据
parentData?: ITaskKinShip; // 节点作为上游节点存储的数据
childData?: ITaskKinShip; // 节点作为下游节点存储的数据
canDeleteData?: any; // 能够被删除的数据,用于删除的时候判断
}
>()
通过 checkData 方法来将后端给的数据处理到 vertexMap 中,重点是需要整合同为上游节点或者同为下游节点的数据。
checkData = (treeData: ITaskKinShip) => {
const {
tableKey,
isRoot = false,
isParent,
sonIds,
fatherIds,
sonLineage,
fatherLineage,
} = treeData;
const mapData = this.vertexMap.get(tableKey);
// 标识为根结点
if (mapData?.rootData) return true;
// 判断是上游节点还是下游节点
const newKey = isRoot ? 'rootData' : isParent ? 'parentData' : 'childData';
// 如果不存在上游节点/下有节点的数据直接赋值
if (!mapData?.[newKey])
return this.vertexMap.set(tableKey, { ...mapData, [newKey]: treeData });
// 否则,需要整合相同节点的 sonIds/fatherIds sonLineage/fatherLineage,为后续的判断提供依据
const nodeData = mapData[newKey];
const {
sonIds: exitSonIds,
fatherIds: exitFatherIds,
fatherLineage: exitFatherLineage,
sonLineage: exitSonLineage,
} = nodeDat
nodeData.sonIds = [...new Set(sonIds.concat(exitSonIds).filter((id) => id !== 'exist'))];
nodeData.fatherIds = [
...new Set(fatherIds.concat(exitFatherIds).filter((id) => id !== 'exist')),
];
nodeData.sonLineage = [...new Set(sonLineage.concat(exitSonLineage))];
nodeData.fatherLineage = [...new Set(fatherLineage.concat(exitFatherLineage))];
nodeData.isChildShow = nodeData.isChildShow || treeData.isChildShow;
nodeData.isParentShow = nodeData.isParentShow || treeData.isParentShow;
this.vertexMap.set(tableKey, { ...mapData, [newKey]: nodeData });
};
上述是对血缘数据的处理,对于整个血缘图节点如下图:
● 如何控制节点扩展
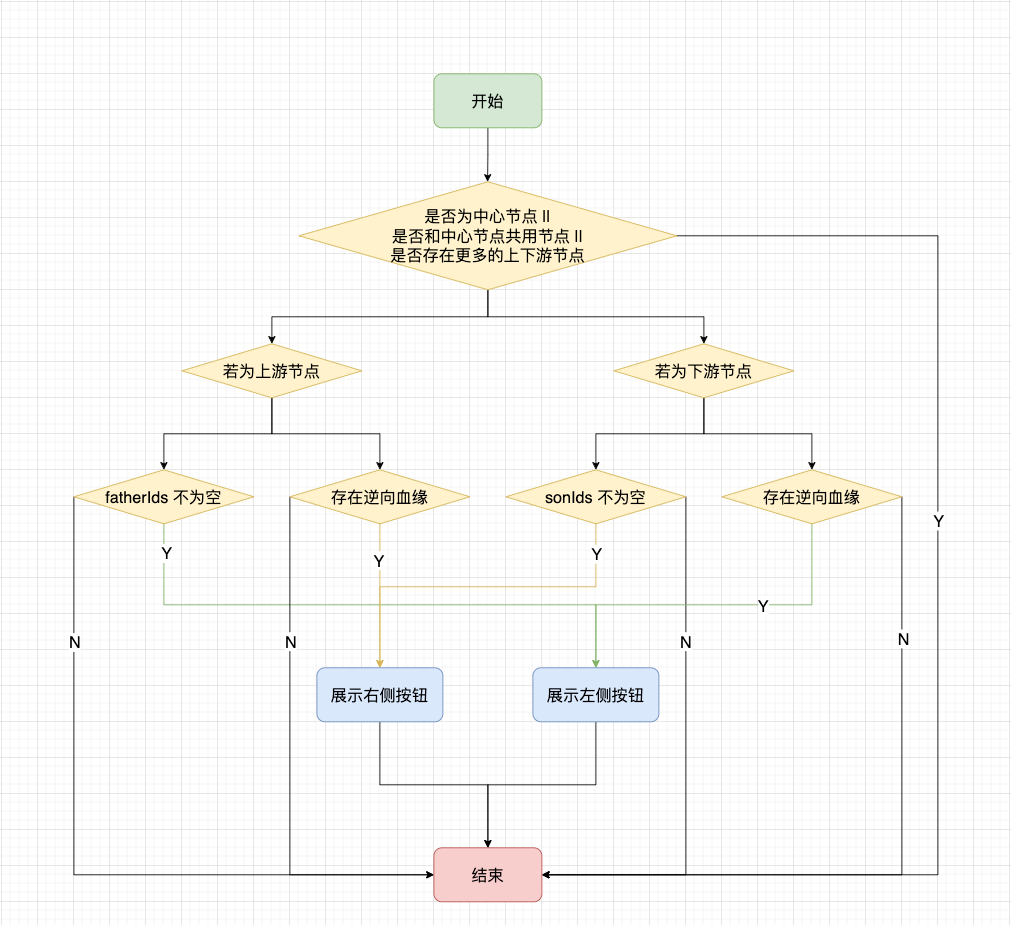
当我们的每一个节点被渲染出来的时候,可能会存在按钮,可以展开上下三层的更多节点。由于节点共用以及需要支持逆向血缘的需求,因此按钮的状态会发生变化:
· 中心节点不会有按钮
· 中心节点下游节点有下游血缘时,有右侧按钮;存在逆向血缘时,有左侧按钮
· 中心节点上游节点有上游血缘时,有左侧按钮;存在逆向血缘时,有右侧按钮
注意是否存在逆向血缘,通过后端接口的 isOpen 标识来做判断。
对于普通的 + 号来说,点击 + 号时,一次性会请求三层数据;对于逆向血缘的 + 号来说,一次性请求一层数据;点击 - 号来说,会将其后续的节点都收起来。
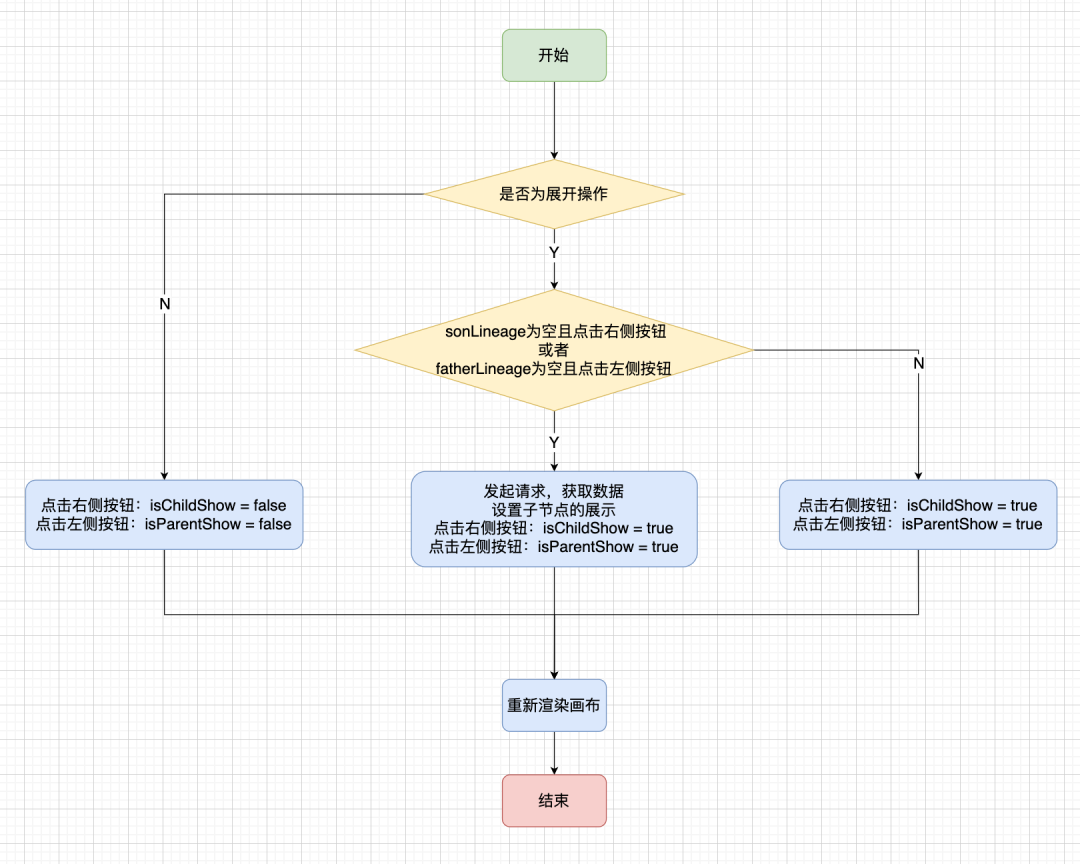
对于每一个节点来说,我们会添加 isParentShow/isChildShow 来表示当前节点上下游是否展开。
· 收起操作:如果点击的按钮处于展开状态,则将相关联节点收起。点击右边按钮时,对当前节点设置 isChildShow = false;点击左边按钮时,对当前节点设置isParentShow = false。
· 展开操作:如果点击的按钮处于收起状态,则将相关联节点展开。点击右边按钮时,如果不存在 sonLineage 说明尚未获取过血缘节点信息,向后端发起请求;否则对当前节点设置isChildShow = true。对于左边按钮也是如此。
相关的判断流程如下图:
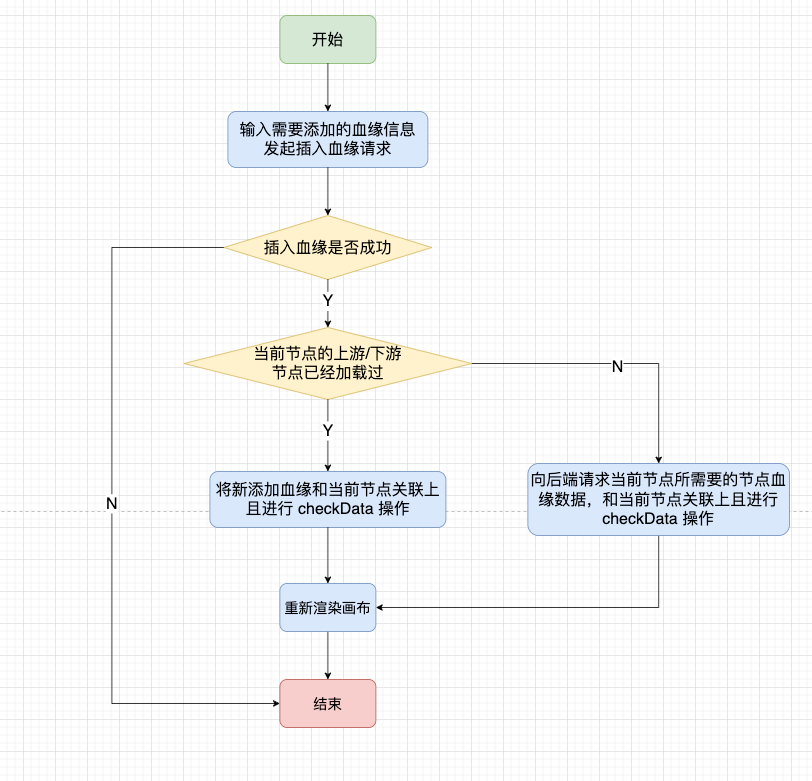
● 如何处理增加/删除节点
我们可以采用右键去插入血缘表或者插入影响表。当我们去做插入血缘操作的时候,也分为两种情况,判断当前节点是否已经加载过上游、下游节点,如果加载过,直接把新血缘数据添加到 vertexMap 中;否则,向后端发起请求,获取当前节点的血缘数据。
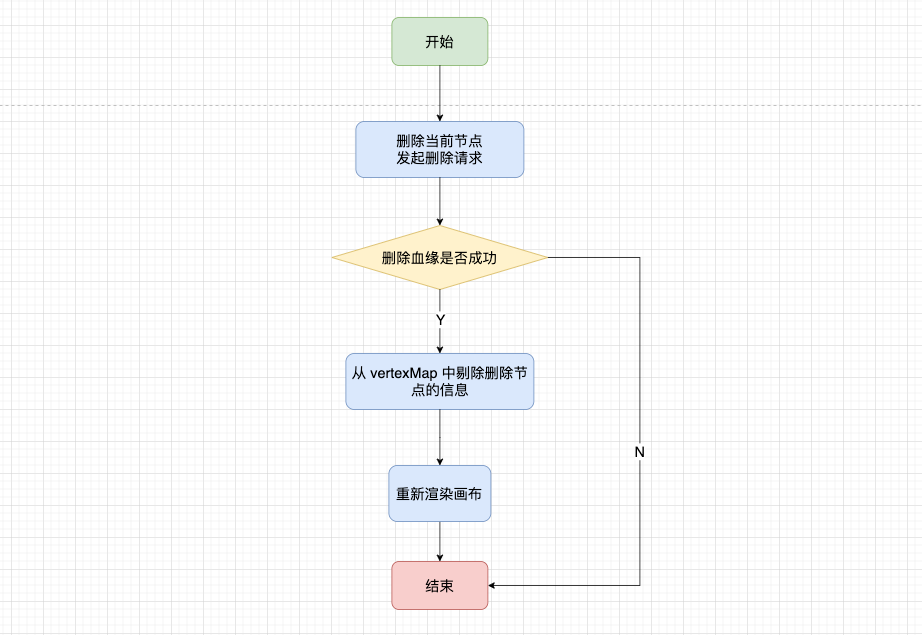
对于删除节点来说,不能够再像之前那样找到其父级节点删除对应节点之后再重新渲染画布,对于节点共用来说,这会出现问题。在资产平台来说,血缘节点分为两种,一种是通过 sqlParser 解析出来的,不能够进行手动删除;另一种是我们通过右键手动添加的,是可以删除的。
当我们遇到手动添加和解析出来的节点共用时,我们进行删除就需要特殊处理,将解析出来节点的相关信息保留下来。
在我们插入节点的时候,我们会根据后端标识位 withManual 得知是解析还是手动添加的,使用 canDeleteData 维护手动添加的节点父级信息。
if (withManual) {
canDeleteData.push({
lineageTableId: obj.lineageTableId,
parentTableKey: obj.tableKey,
});
}
在最开始我们实现节点共用的时候,我们将同一个节点的 sonIds/sonLineage 等信息通过 checkData 方法整合在一起,删除的时候应该配合 canDeleteData 把对应的数据一同清理掉。
删除操作的大致流程如下图:
● 处理特殊的类型节点
由于承接了各个应用的血缘展示,不乏一些特殊的节点,常规的方案无法满足节点展示需求,因此需要做特殊处理。
对于实时的 FlinkSQL 就是需要特殊处理的,虚线框中的是 FlinkSQL 的相关内容,和映射源表、映射结果表连接的节点需要用虚线连接。
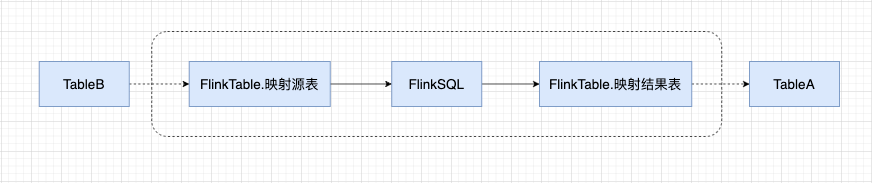
对于 FlinkSQL 的相关数据后端存放于 metaDataInfo 中,parentFlinkInfos 表示映射源表,sonFlinkInfos 表示映射结果表。
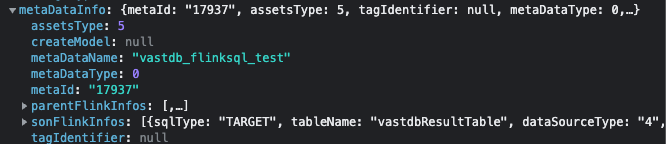
因此根据 FlinkSQL 所处的位置不同,会有不同的渲染逻辑:
· 中心节点
渲染 parentFlinkInfos 创建 parentFlinkTableNode 与 FlinkSQL 节点实线连接,parentFlinkTableNode 再和上游节点使用虚线连接;渲染 sonFlinkInfos 创建 sonFlinkTableNode 与 FlinkSQL 节点实线连接,创建的 sonFlinkTableNode 再和下游节点使用虚线连接。
· 上游节点
渲染 sonFlinkInfos 创建 sonFlinkTableNode 与当前节点虚线连接,渲染 FlinkSQL 节点和 sonFlinkTableNode 实线连接,渲染 parentFlinkInfos 创建 parentFlinkTableNode 与 FlinkSQL 节点实线连接,parentFlinkTableNode 再去和别的上游节点使用虚线连接。
· 下游节点
渲染 parentFlinkInfos 创建 parentFlinkTableNode 与当前节点虚线连接,渲染 FlinkSQL 节点和 parentFlinkTableNode 实线连接,渲染 sonFlinkInfos 创建 sonFlinkTableNode 与 FlinkSQL 节点实线连接,sonFlinkTableNode 再去和别的下游节点使用虚线连接。
● 相似数据源
在相似数据源上,前端并没有对其做过的处理,均为后端判断为相似数据源给到前端做相关展示。
● 字段级血缘
上述讲的都是表级血缘的实现,字段级血缘也实现了节点共用等功能,整体思路和表级血缘一致。唯一需要注意的是实时的字段血缘,如果存在两个结果表时,会存在多个中心节点,所以需要遍历,渲染两个中心节点。
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack

 浙公网安备 33010602011771号
浙公网安备 33010602011771号