
干货|三个维度详解 Taier 本地调试原理和实践
在平时和开发者们交流的过程中,发现许多开发朋友尤其是新入门 Taier 的开发者,对于本地调试都有着诸多的不理解和问题。本文就大家平时问的最多的三个问题,服务编译,配置&本地运行,如何在 Taier 运行 Flink-standalone,进行简单的介绍,希望和大家共同交流学习。
服务编译
在本章将介绍服务编译中的两大插件 WorkerPlugins 及 DataSourcePlugin,以及 Taier 的前后端 UI & datadevelop 的作用。
WorkerPlugins 的作用
平台通过在 Taier-UI 运行任务之后,在 Taier-data-develop 中通过集群绑定到租户,再通过当前租户绑定集群中的组件类型以及版本号获取到不同的 WorkerPlugin,通过不同组件类型以及版本号进行提交任务。下图为整体的运行架构图:
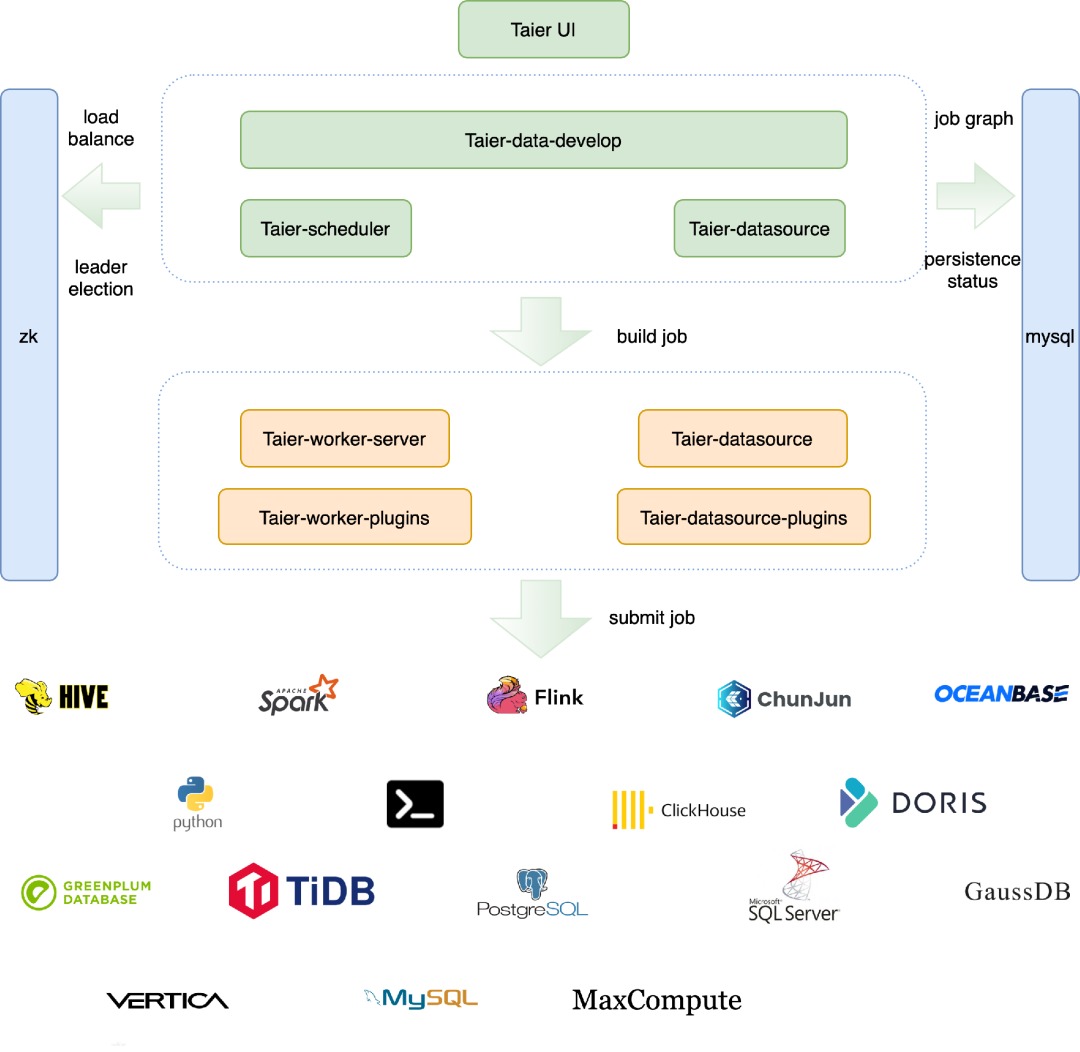
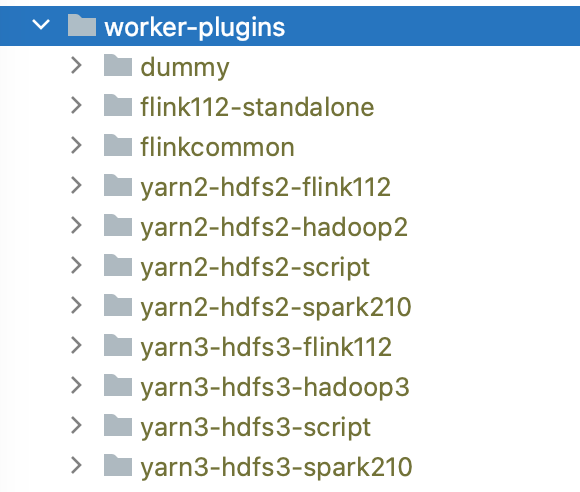
WorkerPlugins 的编译
运行任务时这是一个必要的选项,当我们需要本地调试或者部署运行时,WorkerPlugins 的编译是必须进行的,在编译之后会获取到一个 WorkerPlugins 的目录,具体的编译过程请看文末视频链接中的演示讲解。
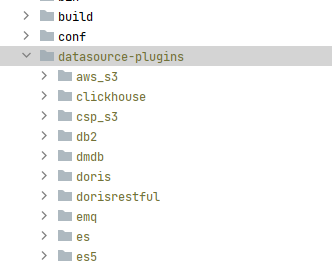
DataSourcePlugin 的作用
介绍完 WorkerPlugins 这个插件之后,来介绍一下另一个插件 DataSourcePlugin。
在 Taier-UI 中我们可以配置诸多不同类型的数据源,如 MySQL,Doris,Oracle 等,这些功能都是依赖着强大的 DataSourcePlugin 来进行实现。同时在使用离线同步中的 GUI 任务配置相关功能时,获取数据库信息也都是依赖 DataSourcePlugin 来完成的。

DataSourcePlugin 的编译
运行任务时这是一个必要的选项,当我们需要本地调试或者部署运行时,DataSourcePlugin 的编译是必须进行的,在编译之后会获取到一个 DataSourcePlugin 的目录,具体的编译过程请看文末视频链接中的演示讲解。
Taier-UI 的作用
在 Taier-UI 中我们可以进行配置不同类型的数据源、创建任务、任务运维、提交调度、集群配置、集群绑定等各种操作。
TaierDataDevelop 的作用
在 Taier- UI 中进行操作的所有后端服务 API 的支持都是来自于 TaierDataDevelop 的支持,该服务主要是与前后端交互。
配置&本地运行
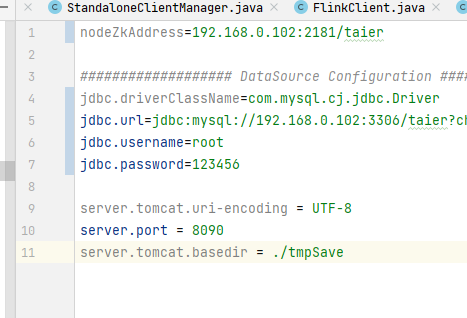
该节内容主要介绍 TaierDataDevelop 的配置,在此进行后端服务的端口 ZK、WorkerPlugins、DataSourcePlugin 数据库等相关配置,前后端的启动,以及集群配置(Flink-standalone)和绑定。
具体的代码流程请看文末视频链接中的演示讲解。
运行 Flink-Standalone 实践
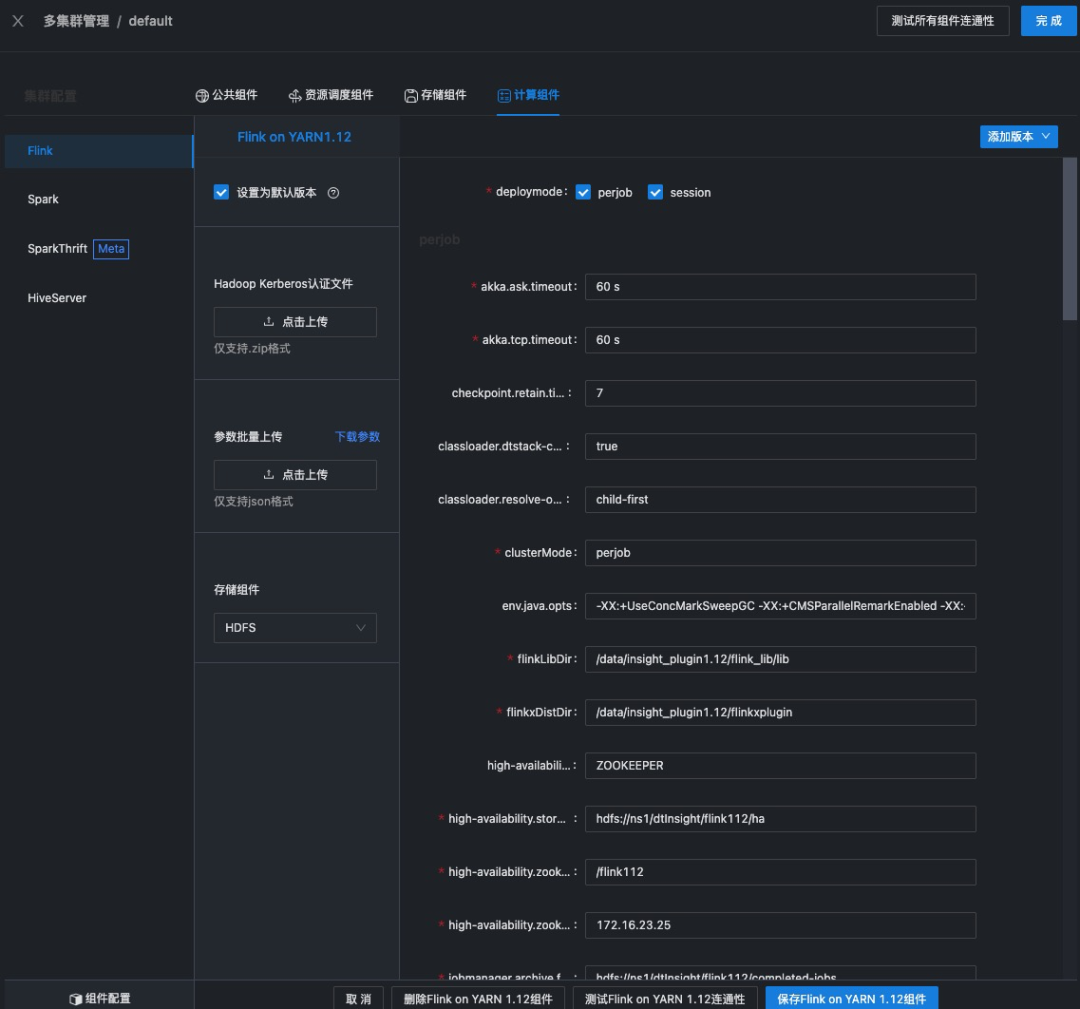
配置集群
在任务运行时,通过配置的 CDH 集群,使用配置 YARN 组装任务,通过 ChunJun 或直接提交任务至 Flink、Doris、Spark 等计算引擎中。
配置&运行任务
通过任务 GUI 组装任务配置,包括数据来源和去向,通过字段映射、任务自定义参数等相关配置从而进行任务配置。
视频课程&PPT获取
视频课程:
https://www.bilibili.com/video/BV19M411L7f2/?spm_id_from=333.999.0.0
课件获取:
https://www.dtstack.com/resources/1031
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack

 浙公网安备 33010602011771号
浙公网安备 33010602011771号