大文件上传功能在标签服务的简单应用和代码实现
各位看官大家好,今天给大家分享的又是一篇实战文章,希望大家能够喜欢。
目前「袋鼠云客户数据洞察平台」标签服务的群组按种类划分,可以分为三大类,分别是实时群组、动态群组以及静态群组。如果按创建方式划分则有两种,分别是通过圈群的方式创建以及通过上传本地文件进行维度匹配的方式创建得到本地群组,其中本地群组属于静态群组。
除了本地群组外的其他群组目前都是采用圈群的方式生成匹配 SQL,然后执行相应的 SQL 得到相应查询维度的数据并入库到群组表,这种方式比较方便,可以快速得到一个用户期望的群组。
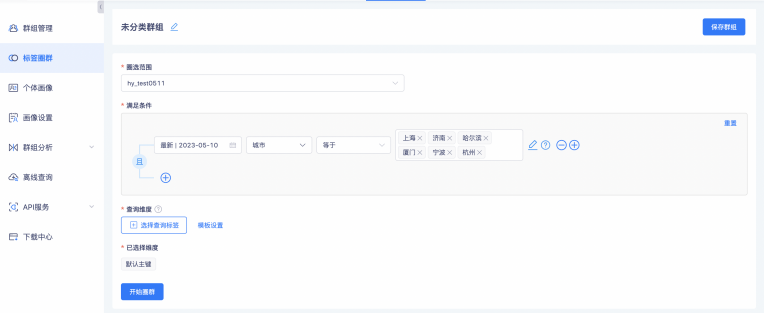
但是有那么一种场景,假设想要设置的条件很分散,通过圈群配置的时候比较复杂,那么只能通过上传文件的方式进行匹配,这就需要用户上传本地文件,通过指定匹配维度的方式来生成本地群组。
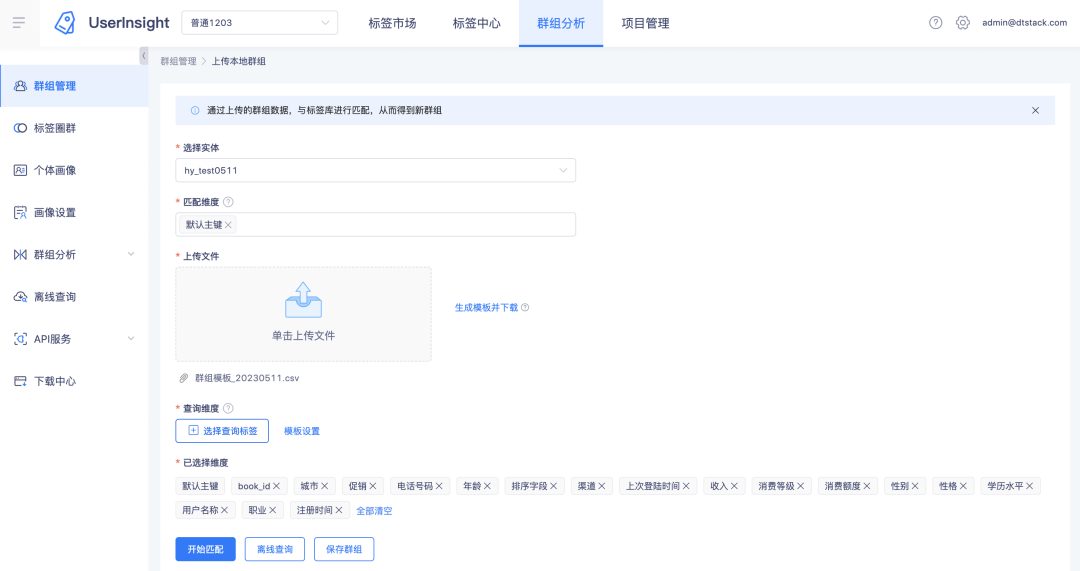
如果用户上传的本地文件很小,那么比较简单,按单个文件直接上传解析即可。如果用户上传的文件很大,有50M,那么就需要采用分片的方式进行上传,本文和大家分享一下这两种文件上传的代码实现。
小文件上传的实现
小文件上传的主要流程包括将文件上传到服务器,并获得文件的编码格式,文件上传完毕后,异步解析文件并得到本地群组。
将文件上传到 HDFS 并保存原始文件到 SFTP,上传到 HDFS 之后,通过 SQL 来与实体对应的大宽表进行数据匹配,最终生成本地群组。

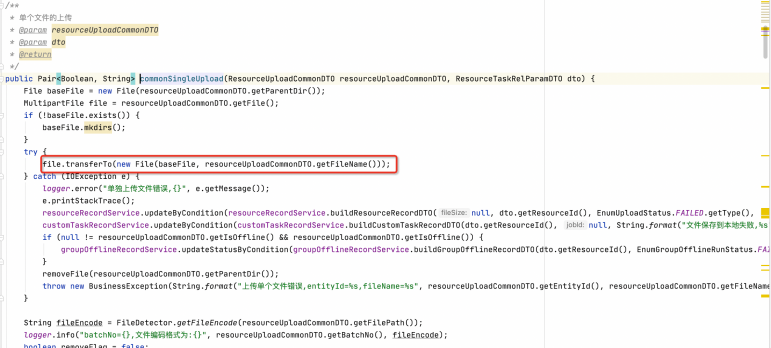
小文件直接上传即可,代码如下,上传完成后,获取文件的编码格式,用于后续的文件解析。
大文件上传的实现
前端将大文件按指定大小分片,并计算原始文件的 md5 和每个分片文件的 md5,分别用于文件校验以及分片文件断点续传。接口入参代码设计如下:

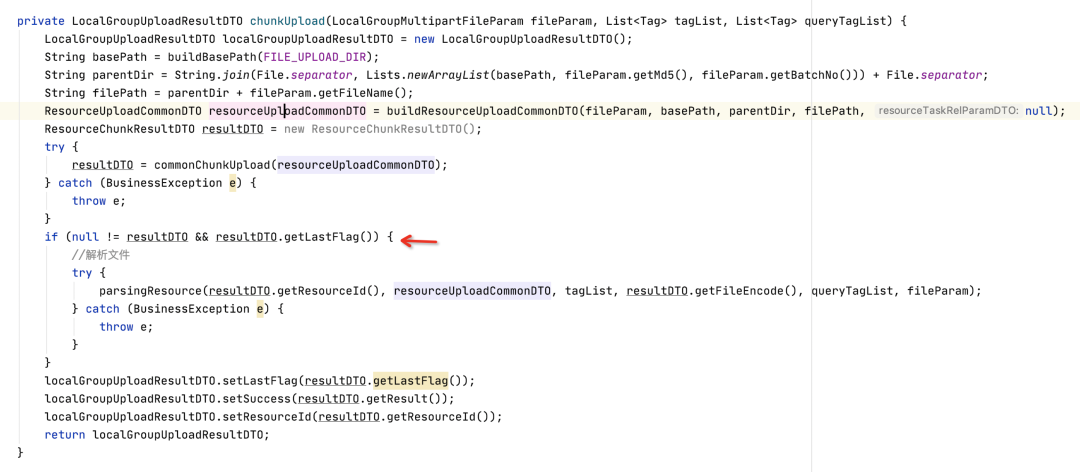
大文件分片实现部分核心代码如下:
分片文件重新在服务器整合为一个大文件的整体代码如下:
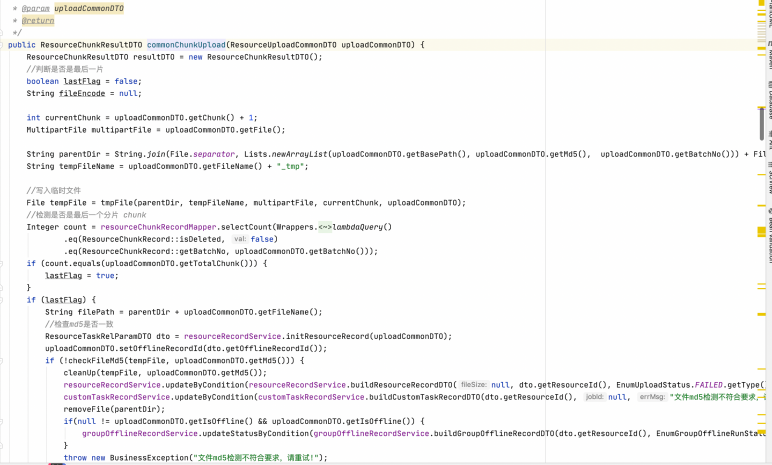

单个分片的数据接收并写入代码如下:

当检测到上传的文件是最后一个分片文件的时候,待分片数据写入完成后,需要对服务器上的文件进行 md5 校验来保证文件数据的一致性。
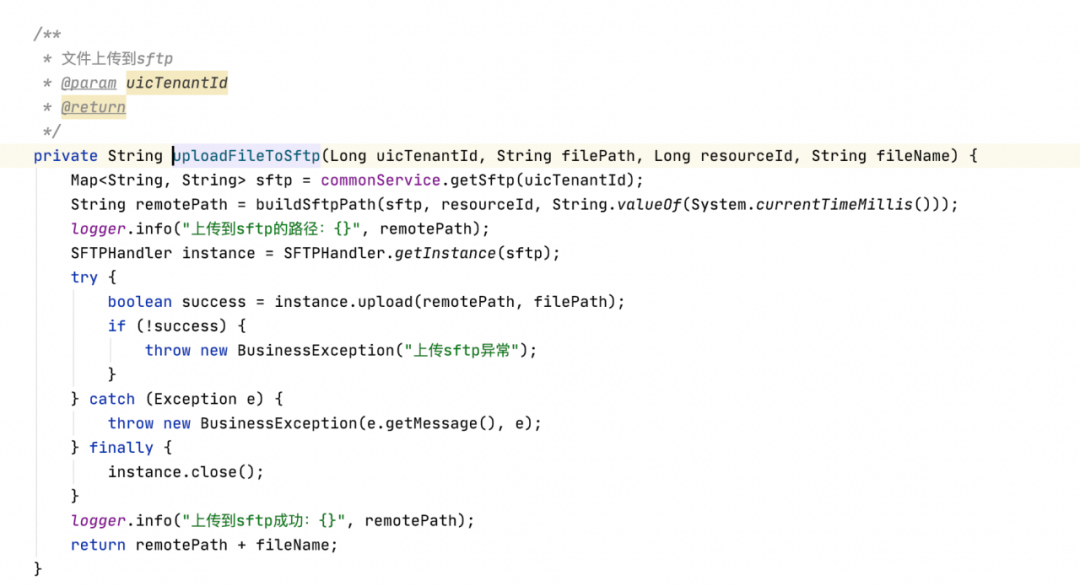
当文件上传到服务器完成后,需要将文件上传到 HDFS 以及SFTP,代码如下:

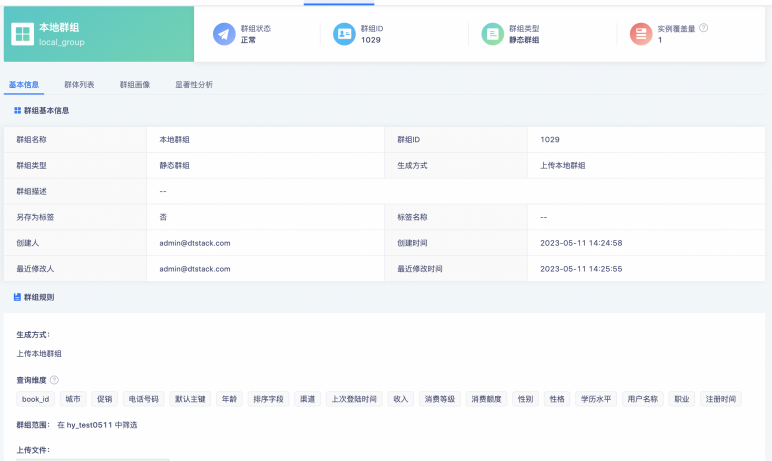
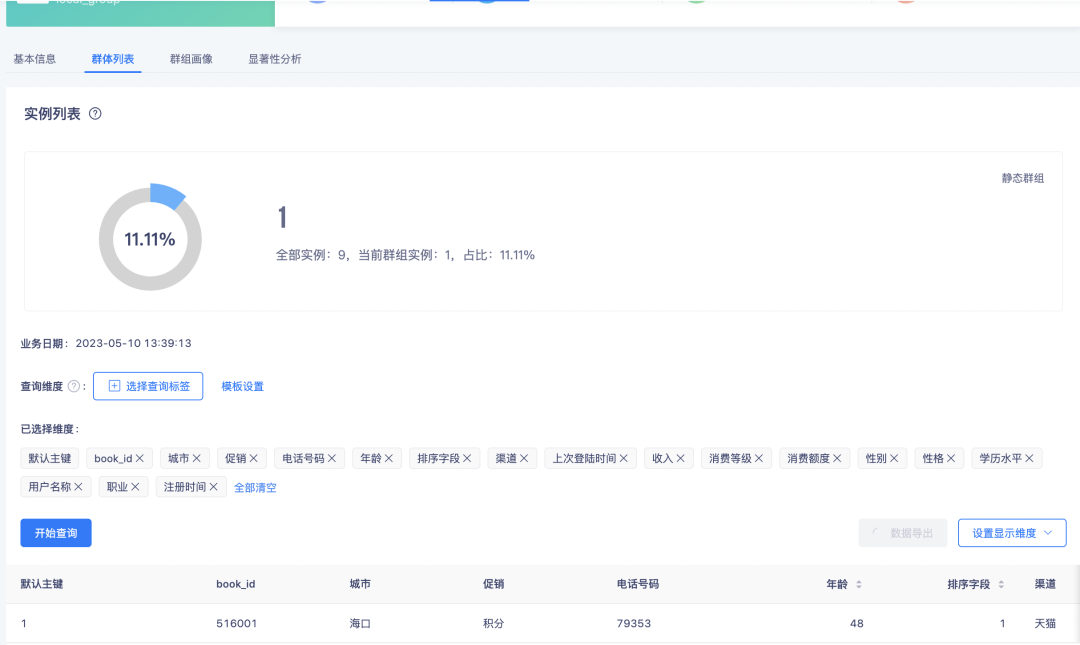
最终得到的本地群组如下:
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack

 浙公网安备 33010602011771号
浙公网安备 33010602011771号