数据湖选型指南|Hudi vs Iceberg 数据更新能力深度对比
数据湖作为新一代大数据基础设施,近年来持续火热,许多前线的同学都在讨论数据湖应该怎么建,许多企业也都在构建或者计划构建自己的数据湖。基于此,自然引发了许多关于数据湖选型的讨论和探究。但是经过搜索之后我们发现,网上现存的很多内容都是基于较早之前的开源信息做出的结论,在企业调研初期容易造成不准确的印象和理解。
因此带着这样的问题,我们计划推出数据湖选型系列文章,基于最新的开源信息,从升级数据湖架构的几个重要纬度帮助大家进行深度对比。希望能抛砖引玉,引起大家一些思考和共鸣,欢迎同学们一起探讨。
实践过程中我们发现,在计划升级数据湖架构的客户中,支持数据的事务更新通常是大家的第一基础诉求。因此,该系列的第一篇内容我们将从需求的诞生背景,以及不同数据湖架构在数据事务上的能力对比,两个方面帮助大家在数据湖选型之路上做出更好的决定。
需求背景
在传统的 Hive 离线数仓架构下,数据更新的成本是非常大的,更新一条数据需要重写整个分区甚至整张表。因此在真实业务场景中,出于开发成本、数据风险等方面的考虑,大家都不会在 Hive 数仓中更新数据。
不过随着 Hive 3.0 的推出,Hive 表在事务能力上也向前迈了一大步,官方在推出 3.0 时也重点宣传了它的事务能力。不过在实际应用中仍然存在非常大的限制,真实投产的用户寥寥无几。(仅支持ORC事务内表,这意味着像Spark这类计算引擎,无法直接在Hive事务表上进行ETL/ELT开发,包括像CDH、袋鼠云公司都在Spark兼容上做过投入,但是效果不佳,远达不到生产级的应用预期)
因此,在数据湖选型过程中,高效的并发更新能力就显得尤为重要。它能够改变我们在 Hive 数仓中遇到的数据更新成本高的问题,支持对海量的离线数据做更新删除。
数据更新实现的选型
目前市面上核心的数据湖开源产品大致有这么几个:Apache Iceberg、Apache Hudi和 Delta。
本文将为大家重点介绍 Hudi 和 Iceberg 在数据更新实现方面的表现。
Hudi 的数据更新实现
Hudi(Hadoop Update Delete Incremental),从这个名称可以看出,它的诞生就是为了解决 Hadoop 体系内数据更新和增量查询的问题。要想弄明白 Hudi 是如何在 HDFS 这类文件系统上实现快速 update 操作的,我们需要先了解 Hudi 的几个特性:
· Hudi 表的文件组织形式:在每个分区(Partition)内,数据文件被切分组织成一个个文件组(FileGroup),每个文件组都已 FileID 进行唯一标识。
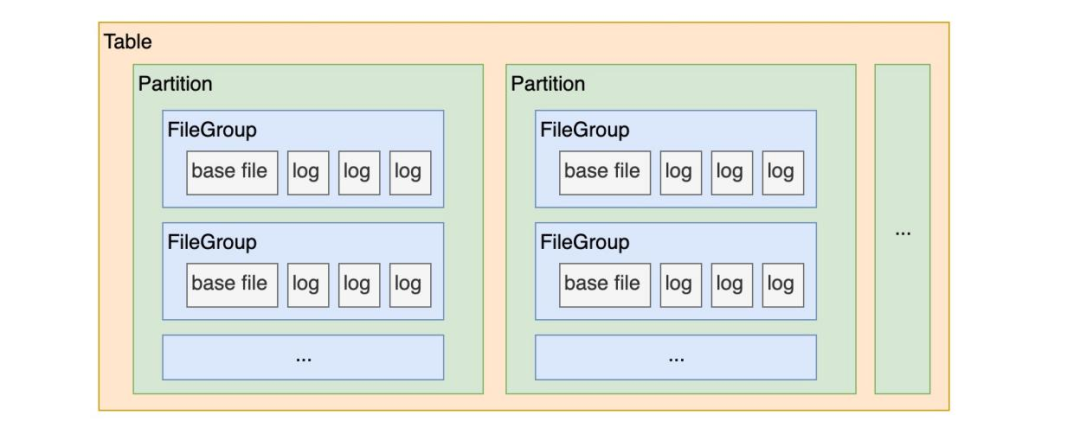
· Hudi 表是有主键设计的,每条数据都已主键进行唯一标识。
· Hudi 表是有索引设计的。
结合上面的三个特性可以得出,Hudi 表的索引可以帮助我们快速地定位到某一条数据存在于某个分区的某个文件组中,然后对其进行 Update 操作,即重写这部分文件组。
Iceberg 的数据更新实现
Iceberg 的官方定位是「面向海量数据分析场景的高效存储格式」。所以它没有像 Hudi 一样模拟业务数据库的设计模式(主键+索引)来实现数据更新,而是设计了更强大的文件组织形式来实现数据的 update 操作,详见下图:
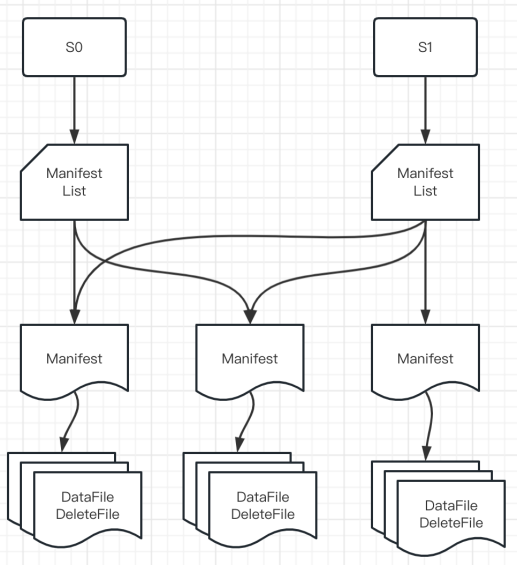
• Snapshot:用户的每次 commit 会产生一个新的 snapshot
• Manifest List:维护当前 snapshot 中所有的 manifest
• Manifest:维护当前 Manifest 下所有的 data files 和 delete files
• Data File:存储数据的文件
• Delete File:存储「删除的数据」的文件
在上面的文件组织基础上,我们可以看出,Iceberg 实现 update 的大致逻辑是:
· 先将要删除的数据写入 Delete File;
· 然后将「Data File」 JOIN 「Delete File」进行数据比对,实现数据更新。
当然,实现这两步有很多技术细节:比如利用 Sequence Number 保障事务顺序;Delete File 根据删除时的文件状态判断是走 position delete 还是 equality delete 逻辑;引入 equality_ids 概念模拟主键等。
如何选择
单纯从数据更新能力这个角度来看:
· Hudi 凭借文件组+索引+主键的设计模式,能够有效减少数据文件的冗余更新,提高数据更新效率。
· Iceberg 通过文件组织设计也能达到数据更新效果,但是每一次的 commit 都会产生新的文件,如果写入/更新频繁,小文件问题会比较严重。(虽然官方也配套提供了小文件治理能力,但是这部分的资源消耗、治理难度相对 Hudi 来说会比较大)
如何实践应用
当我们确定了数据湖选型后,如何在生产环境中进行实践应用就成为了下一个问题。
这里就需要提前了解表类型这个概念,同一种数据湖表格式也有不同的类型区别,分别适用不同的场景:
• COW(Copy On Write):写时复制表。在数据写入/更新时,立即重写原有数据文件,生成一份新的数据文件。
• MOR(Merge On Read):读时合并表。在数据写入/更新时,不修改原有文件,写入新的日志/文件,在之后数据被读取到的时候,重写数据文件。
基于这两种表类型的特性差异,我们给出如下建议:
· 如果你的湖表写入/更新不频繁,主要用于支撑数据查询/分析场景,那建议使用 COW 表。
· 如果你的湖表写入/更新频繁(甚至是用于实时开发场景的写入),那建议使用 MOR 表。
总结
没有最好的技术架构,只有最适合当前业务的技术架构。
关于数据湖的选型当然也不能简单从数据更新能力这一单一纬度做出判断。后续我们将继续推出不同数据湖架构在 Schema 管理、查询加速、批流一体等更多纬度的对比内容。欢迎大家和我们一起探讨交流。
同时,袋鼠云也有自己的数据湖仓一体化构建平台 EasyLake,提供面向湖仓一体的数据湖管理分析服务,基于统一的元数据抽象构建一致性的数据访问,提供海量数据的存储管理和实时分析处理能力。
《数据治理行业实践白皮书》下载地址:https://fs80.cn/380a4b
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack

 浙公网安备 33010602011771号
浙公网安备 33010602011771号