从5分钟到60秒,袋鼠云数栈在热重启技术上的提效探索之路
更好地提高效率一直以来是袋鼠云数栈产品的主要目标之一。当前数栈客户的实时任务都是基于 Per-Job 模式运行的,客户在进行一些任务参数的修改之后,只能先取消当前任务,再选择 CheckPoint 恢复或者重新运行,整个过程需要3-5分钟,比较浪费时间。为了达到提高效率的目的,我们针对 Per-Job 任务的整体流程分析,进行了相关探索。
下文和大家聊聊数栈在热重启技术方面的探索之路。
热重启是什么?
热重启技术旨在复用当前 Per-Job 集群的相关资源,减少重新创建集群以及申请资源的耗时,同时通过 CheckPoint 机制保障数据的正确性。
Flink 的 Per-Job 模式是指每个任务都会对应一个独立的 Flink 集群。在任务提交的时候,会创建一个 Flink 集群进行任务的运行,整个集群只为这一个任务进行服务。同时 Flink 集群不允许继续提交任务,导致任务修改之后,只能 Cancel 当前任务。重新提交修改后的任务,创建一个新的 Flink 集群进行运行。
经过分析,耗时主要是由于以下两部分原因造成:
• Client 需要在 Yarn 上启动一个 Flink 集群,这一部分是客户端耗时最多的部分,因为这一部分包括上传 jar,上传文件到Hdfs 上,申请资源启动 Flink 集群,都是比较耗时的步骤
• 集群运行的时候需要申请资源等操作也十分耗时
我们思考如果仅仅是一些任务参数或者 Sql 逻辑的修改,而不涉及代码上的修改,那么 PerJob 任务是否可以类似 Session 模式进行改造,支持 JobGraph 的重新提交,解决 Client 需要启动一个 Flink 集群的耗时问题,大大提高提交效率。
同时复用了整个 Flink 集群的资源,如果并行度改变,只需要申请新增加的资源,已有的资源不需要再重复向 Yarn 的 Resourcemanager 申请。
热重启改造后的流程
Flink 中 Per-Job 任务运行的整体流程大概如下所示:
客户端流程
• Client 端创建 JobGraph
• 上传 JobGraph 到 hdfs 里
• 通过 YarnClient 提交一个 YarnApplication,运行一个 Flink 任务
• 获取结果
Flink 集群流程
• 启动 Flink 集群,启动 WebMonitor,ResourceManager,Dispatcher 组件
• Client 端上传到远程文件服务里的 JobGraph 会被反序列出来由 DIspatcher 持有;
• DIspatcher 会根据此 JobGraph 创建 JobManagerRunner 对象进行运行;
• JobManagerRunner 会交由内部的 ScheduleNg 进行调度运行任务:
a.构建 ScheduleNg 时,会将 JobGraph 转为ExecutionGraph
b. ScheduleNg 根据 ExecutionGraph 进行调度,运行任务
• 任务运行,等待任务运行结束,进行相应的回调处理
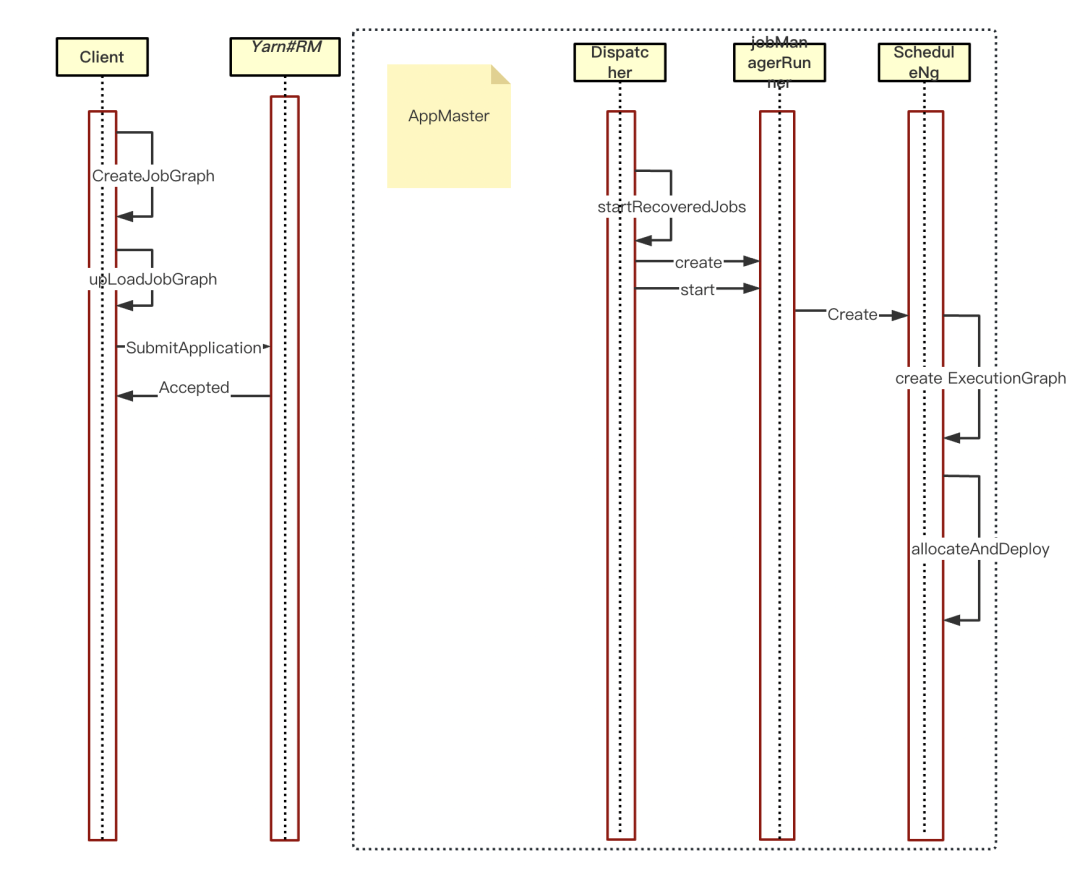
从上图我们可以看出,一个 Per-Job 任务的运行主要包括两部分:一部分是客户端上传文件 jar 等操作后,直接上传任务到 Yarn 上进行 Flink 任务的启动,第二部分是Flink集群的启动,然后对客户端上传到远程文件的 JobGraph 进行处理。因此为了优化 Per-Job 下的效率,我们对这两部分进行了改造。
想法逻辑是,集群首先改造支持 JobGraph 的重新提交,然后 DIspatcher 处理 JobGraph 的时候,不会创建新的 JobMaster ,而是将当前现有的 JobGraph 里的一些信息填充到新的 JobGraph 里,比如当前任务的 CheckPoint 信息等。任务最终的调度运行是 JobMaster 里的 ScheduleNg 对象。因此我们认为只需要将 ScheduleNg 重新构建,其余的组件都可以复用。
下图即为我们热重启技术改造后的一个大致流程:
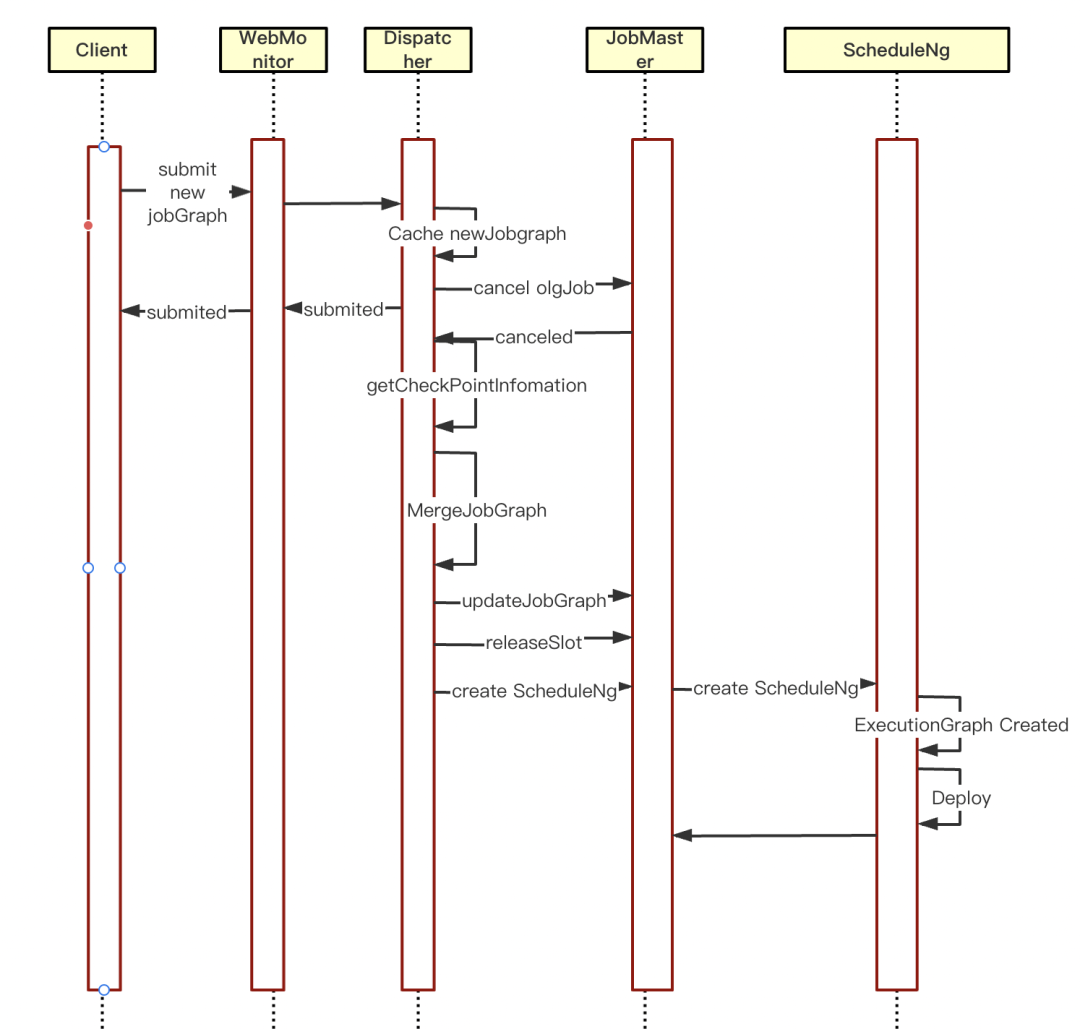
热重启技术改造后流程
• WebMonitor 支持任务的提交
• DIspatcher 将新的 JobGraph 缓存
• 取消当前任务,等待异步回调
• 返回结果给客户端
• 在任务取消的异步回调里主要是热重启的重点改造部分:
a.判断当前是否有新的 JobGraph 缓存,有的话进入热重启逻辑,无则走当前现有逻辑
b.获取取消任务的 CheckPoint 信息,填充到新的 JobGraph 里
c.将 jobGrap 更新到 JobMaster 里,清理以前 JobGraph 的缓存信息
d.把 JobMaster 里 SlotPool 管理的资源释放掉
e.JobMaster 重新创建 ScheduleNg 并调度运行,至此新的 JobGraph 就被成功调度运行了
热重启改造部分详解
JobGraph 介绍
在上述流程中,JobGraph 是整体流转的主要对象,后续的一切操作都是围绕着 JobGraph 进行处理,所以这里先对 JobGraph 进行介绍。
JobGraph 是 Flink 作业的内部表示,是一个有向无环图(DAG),主要是将一些可以优化的算子节点合并为一个节点。从下图可知,一个完整的 JobGraph 图包含了 Source Sink Transform 节点,以及节点的输出 IntermrdiateDataset 和输入边 JobEdge 。在除了 Application 模式外,其余的提交模式下,JobGraph 是在 Client 创建的,然后通过 Rest 请求提交给 Flink 集群进行处理。

看完 JobGraph 此类结构,可以得出以下这些信息:
· taskVertices:上图中的每个顶点对应一个 jobVertex,taskVertices 维护了 jobGraph 图里的各个 jobVertex
· snapshotSettings:checkponit 相关的配置信息,如 CheckPoint 的间隔时间等
· savepointRestoreSettings:任务恢复的 checkpoint 文件信息,热重启中,新的 jobGraph 会将上一个任务的 checkPoint 位点信息填充到这个参数里,新的任务会在 CheckPoint 位点处进行恢复运行
· jobConfiguration:整个 job 的相关配置信息
· userJars & calsspath:任务运行过程中需要的一些 jar 以及 classpath 相关信息
其中 JobVertex 是 jobGraph 里非常重要的对象,再看下此类结构:JobVertex 主要存储了JobEdge以及 IntermediateDataSet 和并行度等相关信息。对于一个 JobVertex 来说,IntermediateDataSet 是作为 JobVertex 的输出,而 JobEdge 是其输入。

WebMonitor 改造
WebMonitor 组件是 Flink 的 Web 端点,可以通过 Rest Api 进行 Flink 集群的状态、任务、指标等信息的查询,同时支持任务的提交、取消、触发 SavePoint 等操作。
Per-Job 模式下 Flink 集群是不支持客户端继续提交任务运行的,因此需要对 WebMonitor 进行改造,类似 Session 下支持同一个 Flink 集群能继续提交 JobGraph 并运行。
从下图可以看出 WebMonitor 组件启动时,其本质是 Netty 为核心的一个 Web 端点。启动时的主要流程如下:
• 创建 Router,管理 http 请求和处理器 handler 的映射关系
• initializeHandlers 初始化所有的 handler,不同的集群对应的 WebMonitor 提供的 API 功能不同,所以 handlers 也是不同的
• 将 handlers 注册到 router,完成 URL 以及请求方式(GET,POST,DELETE,PUT)和 Handler 的映射关系
• 创建一个 Netty 的 handler,包装下 router,然后注册到 Netty 的 pipeline 里

WebMonitor 支持的各种 Rest 请求其实最终是交给一个个的 handler 进行处理,通过 Router 对这些 handler 进行维护,其内部维护了一个 url 以及 Rest 请求方式与 handler 的映射关系。接收 Client 端的 Rest 请求之后,Router 找到对应的处理器 handler,交由 handler 进行最终的处理并返回结果。
因为 Per-job 集群是不支持 Client 端继续提交任务的,所以其 initializeHandlers 方法初始化出的 handlers 不包含处理任务提交的 handler,导致 router 找不到对应的 handler 报错,因此需要在 initializeHandlers 里将处理任务提交的 handler 注册进去 。
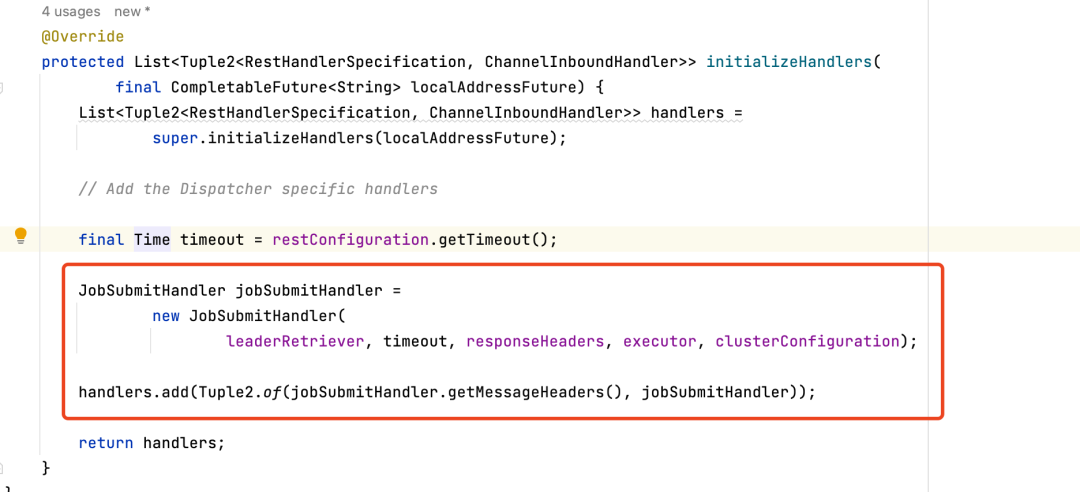
JobSubmitHandler 处理请求的主要逻辑如下图所示。核心是从 Rest 请求的 Body 里反序列化得到 JobGraph,反序列化获取的 Jobgraph 通过 DIspatcherGateway 发送给 Dispatcher 进行后续提交处理。

这样 Client 端只需要重新生成 JobGraph 然后提交即可,避免了重新上传 jar 到 hdfs,以及避免浪费重新向 yarn 集群申请资源启动 AppMaster 的时间。
Dispatcher 改造
DisPatcher 顾名思义是一个分发器,其主要功能是 Flink 集群接收到关于 Job 的提交、取消、触发 SavePoint 等操作,分发到对应的各个 JobMaster 进行处理,或者创建新的 JobMaster 进行任务的运行。
DisPatcher 处理任务提交的核心流程是根据 JobGraph 创建一个 JobManagerRunner 对象并启动,然后将其包装成一个 DispatcherJob 缓存在内部。任务的具体调度执行交由创建的 JobManagerRunner 进行异步处理。
JobManagerRunner 其内部的具体操作其实是 JobMasterService,主要实现类就是 JobMaster。JobMaster 内部有两个主要对象分别是:
· ScheduleNg: 负责 JobGraph 转为 ExecutionGraph,然后对 Job 进行调度运行
· SlotPool:负责 Slot 资源的申请以及管理
以上便是 Dispatcher 处理的主要流程。当前改造之后只是支持了任务的重新提交运行,但是新的任务仍然是对应一个新的 JobMaster,其实就是一个类似 Session 的处理,所以为了达到热重启的效果,需要进行以下的改造。
主流程的改造逻辑如下:
• 增加了一个 hotRestartJobGraph 字段,将新的 JobGraph 对象赋予此字段
• Dispatcher 将缓存的正在运行的任务 cancel,对异步返回结果进行回调处理
• 直接返回 Client 结果
因为 Flink 整体是异步处理的,源码里充满了大量的 CompletableFuture 回调的处理,主流程仅仅对提交的 JobGraph 进行了一个缓存处理,热重启的主要步骤在任务取消的回调里进行处理:
• 判断 hotRestartJobGraph 是否为空,如果不为空则进行热重启处理,为空则用以前的逻辑,整个 Per-job 集群关闭
• 获取取消任务的最后一个 CheckPoint 位点
• 将 CheckPoint 位点信息填充到新的 Jobgraph 里
• 反射将上一个 Jobgraph 生成的 JobManagerRunner 和 jobMaster 两个对象的JobGraph 字段用新的 JobGraph 替换掉
• jobMaster 对象根据 jobGraph 重新生成 scheduleNg 进行调度运行
• jobMaster 的 slotPool 在心跳周期内,会缓存已经释放掉的 slot,需要把这部分缓存清空
• MiniDispatcher 的 close 方法修改下,如果 hotRestartJobGraph 不为空则不进行集群的关闭
• hotRestartJobGraph 置空
注意上述只是主要的一些改造地方,其余一些边缘的细节处理就不再进行赘述。
所以在热重启中,DIspatcher 是不会对每一个 JobGraph 创建新的 JobMaster 对象。通过将新的 JobGraph 更新到 JobMaster 里,内部仅仅 ScheduleNg 进行了重新构建,其余的组件都进行了复用,比如 SlotPool。
ScheduleNg 之所以需要重新构建是因为 JobGraph 转为 ExecutionGraph 是需要 ScheduleNg 在构建的时候创建的,因此需要重新构建一个 ScheduleNg 进行任务的调度执行,这样达到了整个资源的复用性,大大提升了效率。
Slot 资源的复用
Flink 中对于资源的抽象主要是 Slot,其各个组件对 Slot 的管理是由不同的组件处理的:
· Flink 的 ResourceManager 里是 SlotManager 管理,主要是任务的资源申请以及管理
· JobMaster 里管理 Slot 是 SlotPool ,主要是对当前任务申请的 slot 进行管理
· TaskExecutor 里则是S lotTable 对 Slot 进行管理,维护 JobId 和 Slot 的关系
在热重启中,上一个任务取消之后,JobMaster 里 SlotPool 管理的 Slot 状态由已分配改为可用。这样在 JobMaster 通过新的 ScheduleNg 进行重新调度,会复用 SlotPool 里缓存的 Slot,这个时候其实是有问题的。在 TaskExecutor 接收到任务的时候会报错,在其内部的 JobTable 里找不到新任务的 JobId,因为此时 TaskExecutor 维护的 Jobid 还是上一个任务的。
所以 JobMaster 的 SlotPool 需要释放掉其内部缓存信息,注意只是清理内部缓存,此时 TaskManager 的 Slot 槽资源还没被释放,仍然被 Resourcemanager 的 SlotManager 管理着。这样 SlotPool 发现内部没可用的 Slot 槽就会和 ResourceManager 的 SlotManager 申请资源,SlotManager 就仍然复用了以前的 Slot 槽并且将新的 JobGraph 的 jobId 通过 rpc 请求注册进了 TaskExecutor。从而达到了 slot 槽资源的复用,减少了 Flink 集群的 ResourceManager 重新向 Yarn 的 ResourceManager 申请资源。
总结
数栈在 Per-job 模式下,为了尽快看到任务修改后的效果,在业务允许情况下,通过热重启技术复用相关资源,减少了大量时间,极大地提高了效率。在开发验证中,以前一个任务等待任务结束以及重新提交运行总流程超过4分钟,但是在热重启情况下控制在1分钟以内就已经可以进行调度执行。
未来我们将会把热重启的场景进一步丰富,支持更多场景下的热重启技术,如 jar 的代码修改,如何更新环境里的 jar,支持 k8s 场景等。
袋鼠云一直以来高度重视产品升级和用户体验,用诚心倾听用户需求,新的一年我们将继续保持产品升级节奏,以提效为目标满足不同行业用户的更多需求。为了更好的产品,更佳的用户体验,数栈一直在路上。
《数据治理行业实践白皮书》下载地址:https://fs80.cn/380a4b
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack

 浙公网安备 33010602011771号
浙公网安备 33010602011771号