ChunJun框架在数据还原上的探索和实践 | Hadoop Meetup精彩回顾
Hadoop是Apache基金会旗下最知名的基础架构开源项目之一。自2006年诞生以来,逐步发展成为海量数据存储、处理最为重要的基础组件,形成了非常丰富的技术生态。
作为国内顶尖的 Hadoop 开源生态技术峰会,第四届 China Apache Hadoop Meetup于 2022年9月24日在上海成功举办。
围绕“云数智聚 砥柱笃行”的主题,来自华为、阿里、网易、字节跳动、bilibili、平安银行、袋鼠云、英特尔、Kyligence、Ampere等多所企业单位,以及来自Spark、Fluid、ChunJun、Kyuubi、Ozone、IoTDB、Linkis、Kylin、Uniffle等开源社区的多位嘉宾均参与了分享讨论。

作为此次Meetup参与社区之一,也是大数据领域的项目,ChunJun也带来了一些新的声音:
ChunJun框架在实时数据采集和还原上的实现和原理是怎样的?这段时间以来,ChunJun有哪些新发展,对于未来发展又有着怎样的新想法?
作为袋鼠云资深大数据引擎开发专家,徐超带来了他的分享,将从一个独特的角度来介绍ChunJun数据集成在数据还原上的探索和实践。

一、ChunJun框架介绍
第一个问题:ChunJun这个框架是什么?能干啥?
ChunJun(原FlinkX) 是袋鼠云基于Flink 基座自研的数据集成框架,经过4年多的迭代,已经成为一个稳定,高效,易用的批流一体的数据集成工具,可实现多种异构数据源高效的数据同步,目前已有3.2K+Star。
开源项目地址:
https://github.com/DTStack/chunjun
https://gitee.com/dtstack_dev_0/chunjun
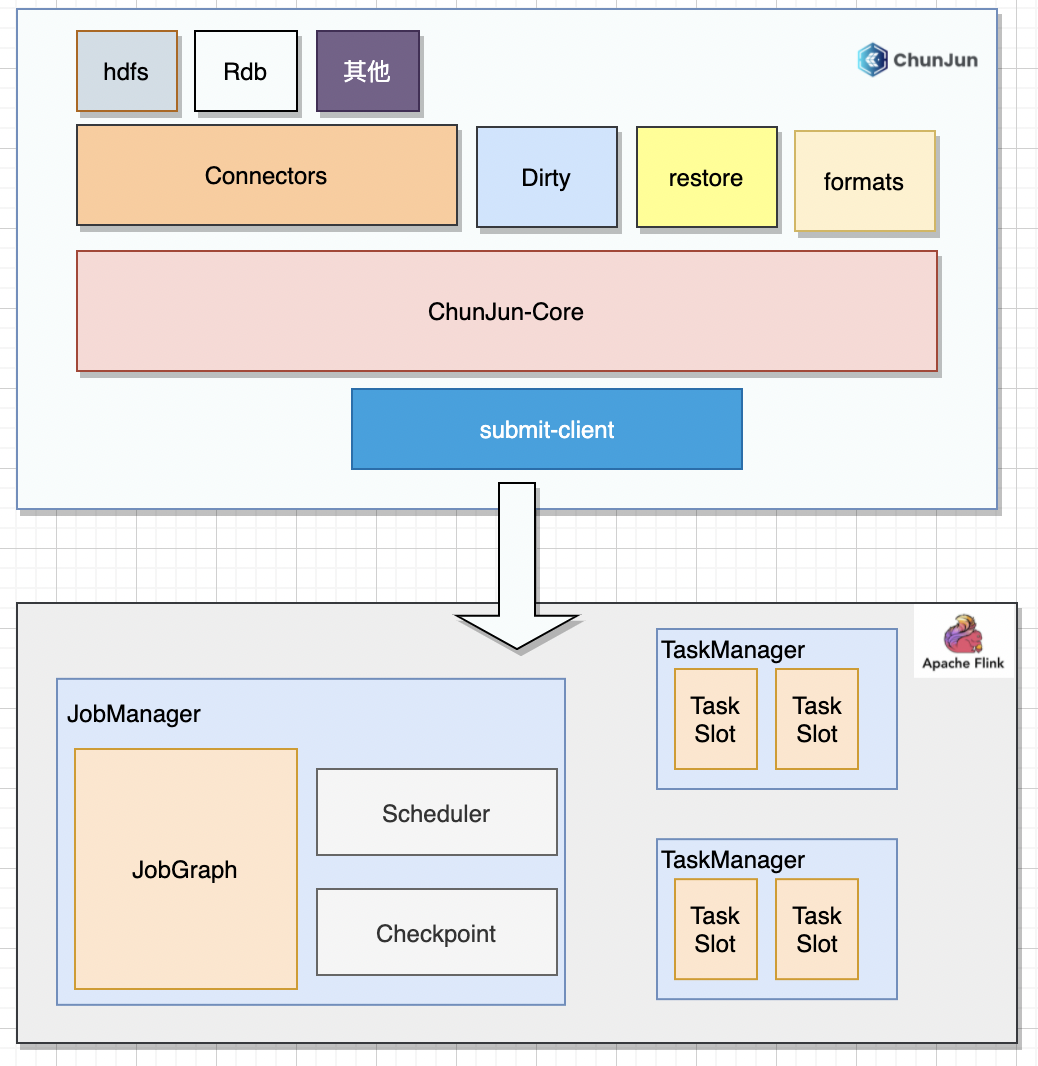
01 ChunJun框架结构
ChunJun 框架基于Flink 进行开发,提供了丰富的插件,同时添加了断点续传、脏数据管理、数据还原等特性。
02 ChunJun批量同步
• 支持增量同步
• 支持断点续传
• 支持多通道&并发
• 支持脏数据(记录和控制)
• 支持限流
• 支持transformer
03 ChunJun离线
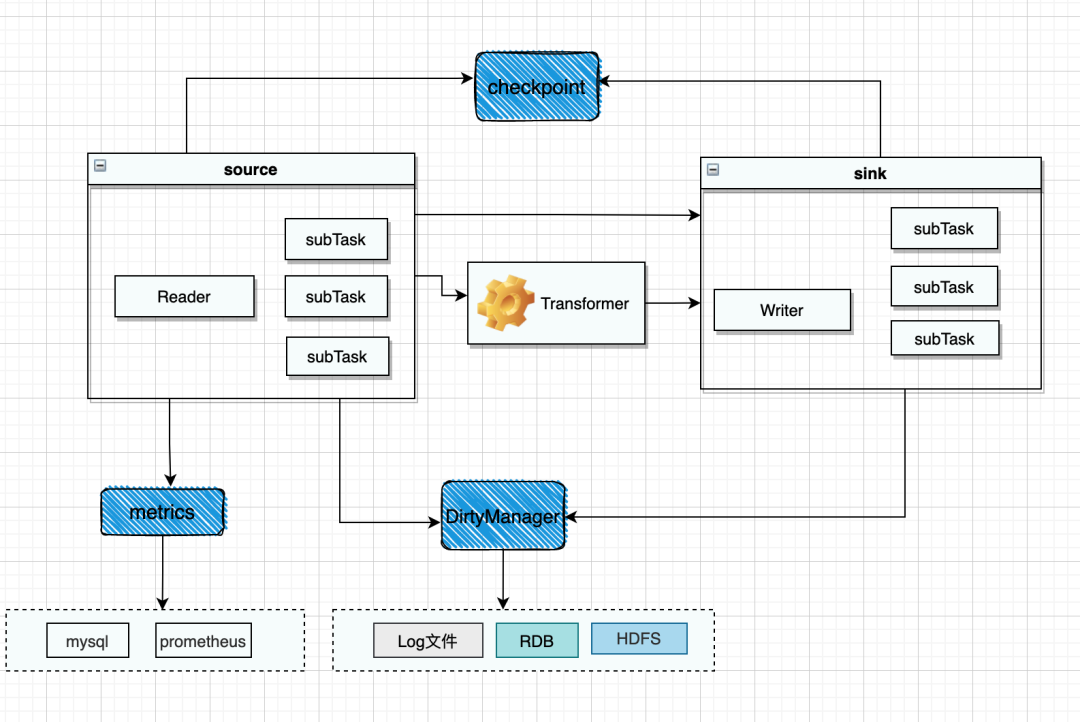
二、实时数据采集上的实现和原理
01 一个样例
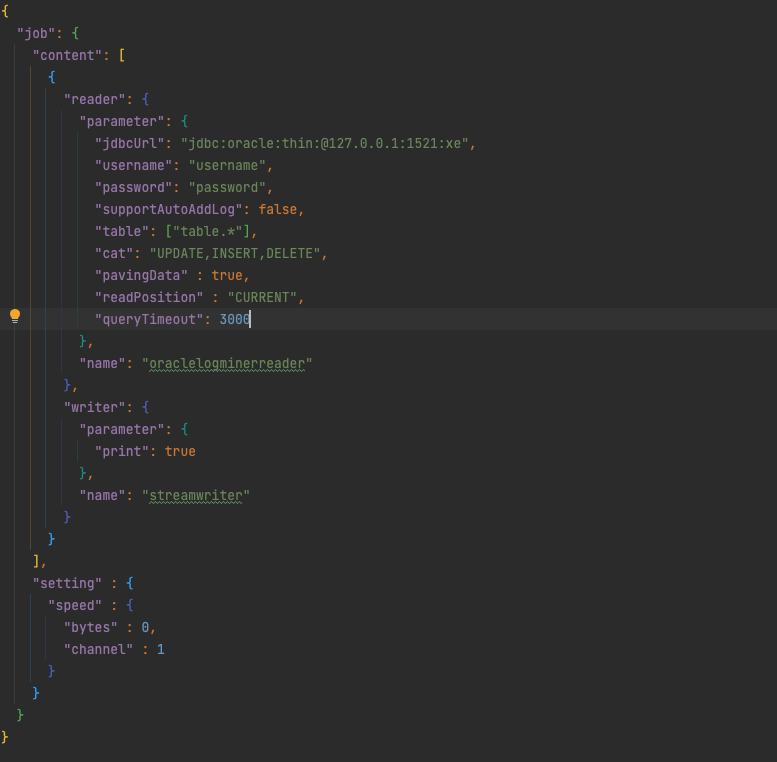
02 ChunJun插件装载逻辑
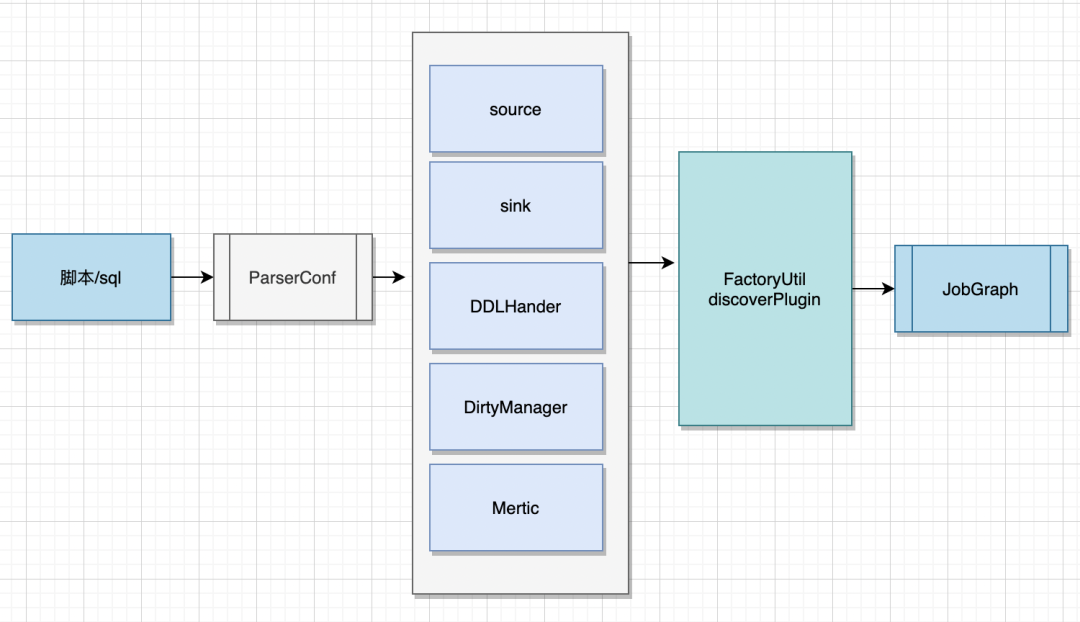
03 ChunJun插件定义
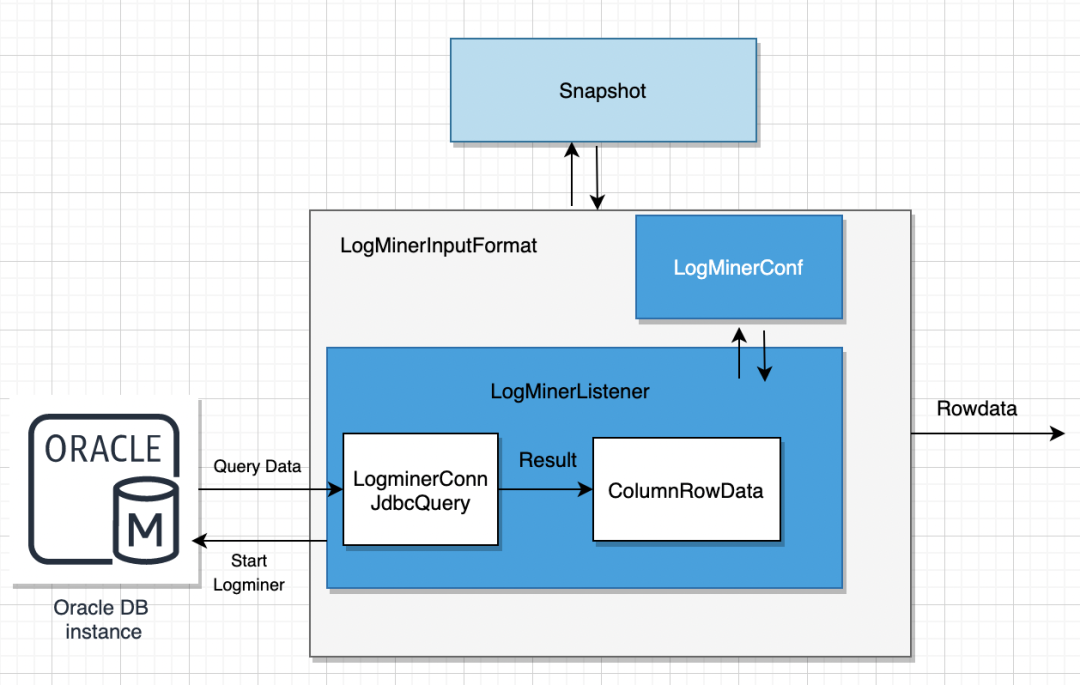
04 ChunJun数据流转
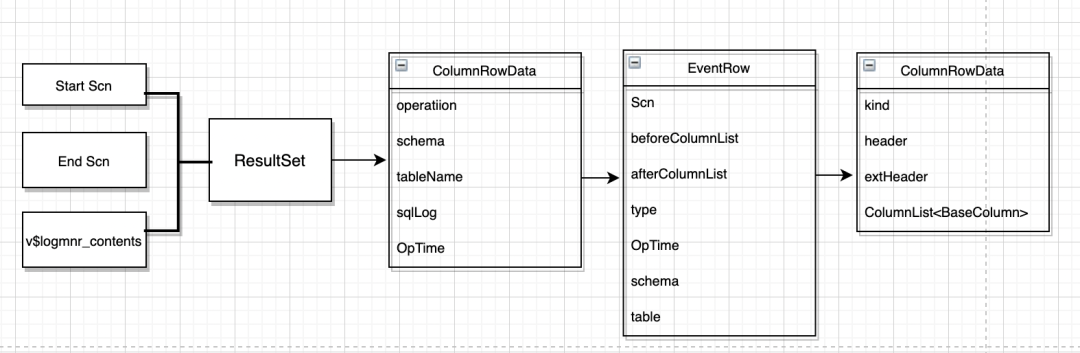
05 ChunJun动态执行
面对监听多个表的情况,包括新添加表的数据,我们如何执行下游的写入:
• 支持Update 转换 before,after
• 添加扩展参数,DB,Schema,Table, ColumnInfo
• 支持动态构建PreparedStatement
06 ChunJun间隔轮询
什么是间隔轮询?我们是如何做的?
• 校验轮询字段类型,如果不是数值类型且source并行度大于1,报错不支持
• 创建三个数据分片,startlocation为null或者配置的值,mod分别为0,1,2
• 构造SQL:不同SQL的取余函数不同,各自插件实现
select id,name,age from table where (id > ? and ) mod(id, 3) = 0 order by id;
select id,name,age from table where (id > ? and ) mod(id, 3) = 1 order by id;
select id,name,age from table where (id > ? and ) mod(id, 3) = 2 order by id;
• 执行SQL,查询并更新lastRow
• 第一次result查询完后,若脚本中没有配置startlocation,则之前的查询SQL为:
select id,name,age from table where mod(id, 3) = 1 order by id;
将其更新为:
select id,name,age from table where id > ? and mod(id, 3) = 1 order by id;
• CP时获取lastRow中的id值,保存到state中
三、实时数据还原上的实现和原理
01 数据还原介绍
数据还原基于对应的数据库的CDC采集功能,比如上面提到的Oracle Logminer,MySQL binglog,支持将捕获到的数据完整的还原到下游,所以不仅仅包括DML,而且也需要对DDL进行监听,将上游数据源的所有变更行为发送到下游数据库的还原。
难点
· DDL,DML 如何有序的发送到下游
· DDL 语句如何根据下游数据源的特性进行对应的操作(异构数据源间DML 的转换)
· DML 语句中的insert update, delete 如何进行处理
02 一个样例

03 整体流程
数据从上游的数据源获取之后经过一些列的算子的处理之后按数据在原始表中的顺序准确的还原到目标数据源,完成数据的实时获取链路。
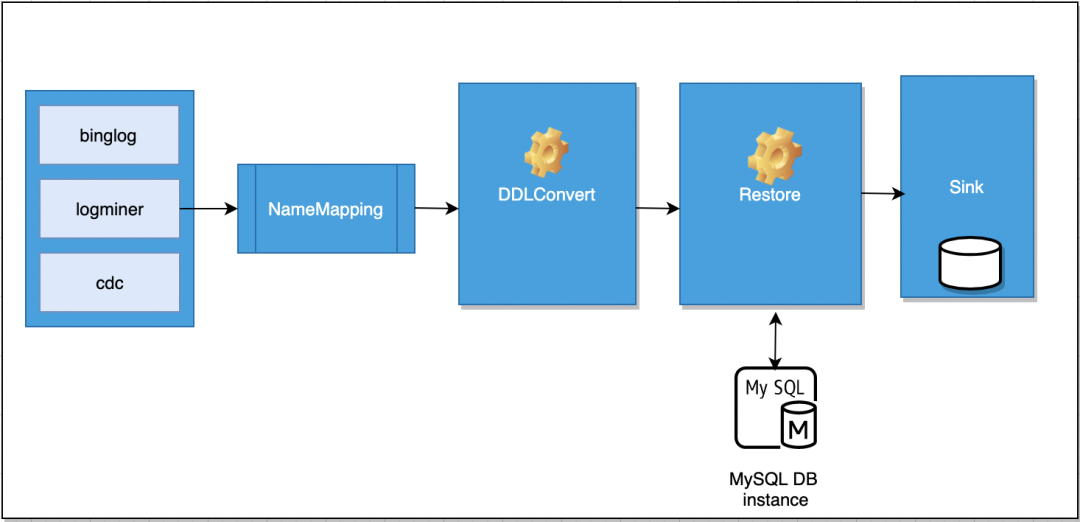
04 DDL解析

数据还原- DDL转换
· 基于Calcite解析数据源DdlSql转为SqlNode
· SqlNode转为中间数据DdlData
· ddlData转为sql:不同语法之间互相转换;不同数据源字段类型互相转换
05 名字映射
在实时还原中,当前上下游表字段对应关系必须是相同的,即上游的database schema table 对应的表只能写入下游database schema table相同的表,同时字段名称也必须是相同的。本次迭代将针对表路径可以进行一个自定义映射以及字段类型进行自定义映射。
• db or schema 转换
• 表名称转换
• 字段名(提供大小写转换),类型隐式转换
06 中间数据缓存
数据(不论ddl还是dml数据)下发到对应表名下的unblock队列中,worker在轮询过程中,处理unblock数据队列中的数据,在遇到ddl数据之后,将数据队列置为block状态,并将队列引用交给store处理。
store在拿到队列引用之后,将队列头部的ddl数据下发到外部存储中,并监听外部存储对ddl的反馈情况(监听工作由store中额外的线程来执行),此时,队列仍然处于block状态。
在收到外部存储的反馈之后,将数据队列头部的ddl数据移除,同时将队列状态回归为unblock状态,队列引用还给worker。
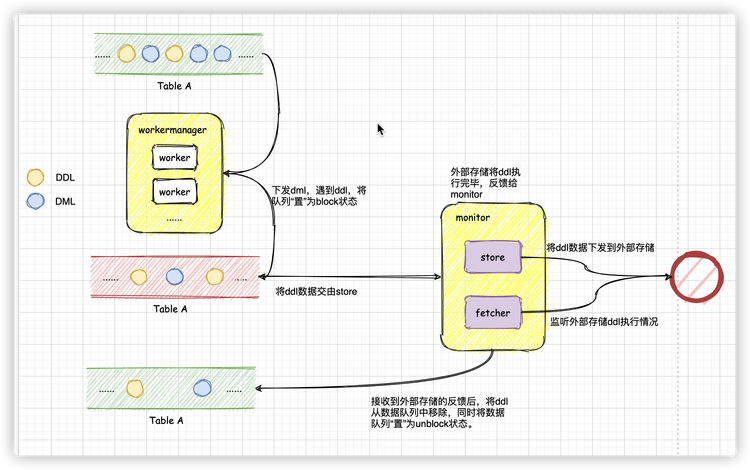
07 目标端接收数据
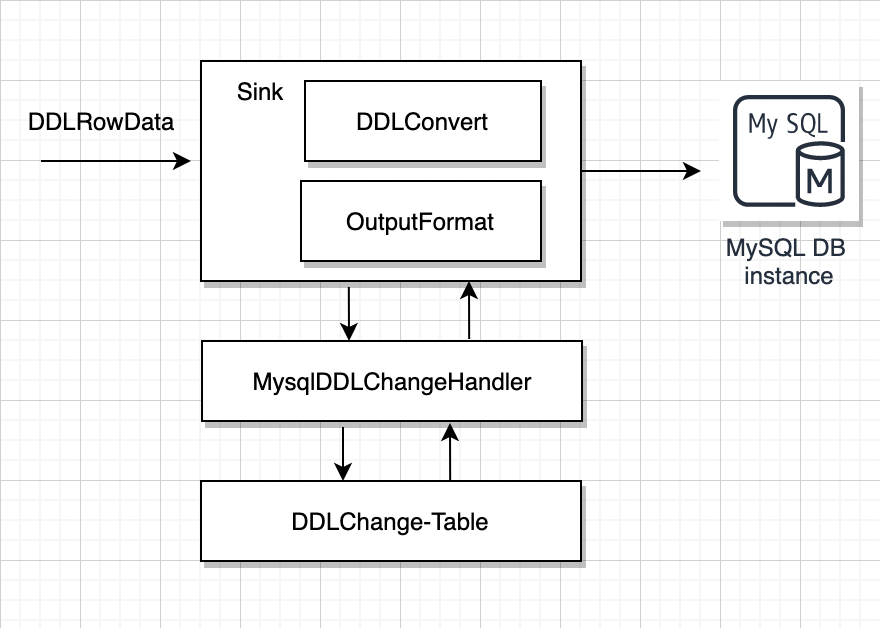
• 获取到DdlOperator 对象
• 根据目标数据源对应的DDLConvertImpl解析器转换为目标数据源sql
• 执行对应的sql,比如删除表
• 触发调整DDLChange 表,修改对应的DDL 状态
• 中间存储Restore算子,监听状态变更,执行后续数据下发操作
四、ChunJun未来规划
• 提供对Session 进行管理
• 提供restful 服务,ChunJun 本身作为一个服务,便于外围系统进行集成
• 对实时数据还原进行加强,包括扩展支持更多的数据源的DDL 解析
此外,本次分享的全文视频内容也可以随时观看,如果您有兴趣,欢迎前往袋鼠云B站平台观看。
Apache Hadoop Meetup 2022
ChunJun视频回顾:
https://www.bilibili.com/video/BV1sN4y1P7qk/?spm_id_from=333.337.search-card.all.click
袋鼠云开源框架钉钉技术交流qun(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack/Taier

 浙公网安备 33010602011771号
浙公网安备 33010602011771号