开源交流丨任务or实例 详解大数据DAG调度系统Taier任务调度
课件获取:关注公众号 “数栈研习社”,后台私信 “Taier” 获得直播课件
视频回放:点击这里
ChunJun 开源项目地址:github 丨 gitee 喜欢我们的项目给我们点个__ STAR!STAR!!STAR!!!(重要的事情说三遍)__
技术交流钉钉 qun:30537511
前言
在分享之前,先为大家介绍一下任务和实例的关系。任务指的是我们在任务开发界面上去创建的任务,比如Spark任务、SparkSQL任务、数据同步任务等,这些任务在开发过程中是静态的脚本,当被提交到计算节点去执行时,被执行的过程我们把它抽象成实例。举一个简单的例子来说明:比如我们写完一个Java的类然后把它打包成Jar包,其实这个Jar包就是一个静态类,当我们执行Jar包时,这个过程我们会把它抽象成一个实例,这就是任务与实例的关系。
Taier实例生成
1、Taier实例类型
首先我们来看一下Taier实例的类型,在Taier中实例主要有3种类型:
-
周期实例:T+1生成,完整依赖
-
补数据实例:立即生成,局部依赖
-
临时运行实例:立即生成,无依赖
● 周期实例
周期实例是指在前一天生成的当天实例(T+1),拥有一个完整独立的实例依赖体系,也就是任务和任务之间形成的完整的DAG图。周期实例实际上指的是离线任务,因为实时任务并无上游依赖关系。
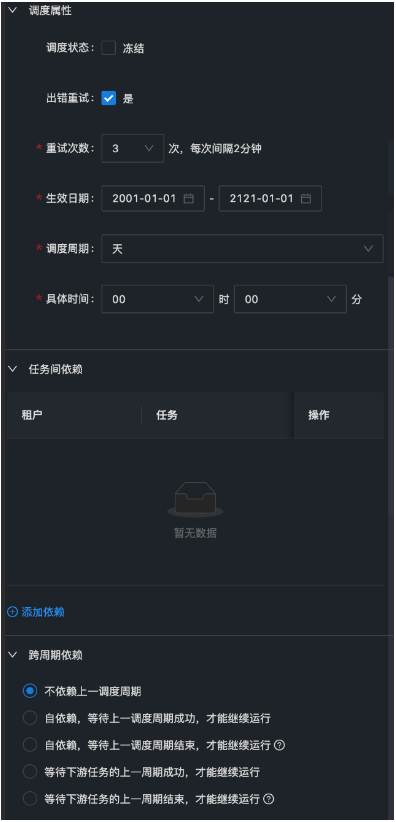
上图就是配置任务之间依赖的地方,任务和任务之间会形成一个完整DAG(Direct Acyclic Graph)图,中文名叫有向无环图,从图中任意一个节点出发,根据方向无法回到原节点的图就叫做有向无环图。
注意: 提交任务的时候回判断是否成环。
而实例依赖可分为两种:父子依赖关系和自依赖关系。
● 父子依赖关系
父子关系可以理解为不同的任务依赖:例如任务A运行需要任务B的运行结果,这个时候任务A就需要依赖任务B,那么B任务就是A任务父任务。
● 自依赖关系
自依赖关系可以理解为相同任务的不同周期依赖:例如 任务A是一个小时任务,0点开始执行,10点结束,每小时运行一次,那么任务A在0点合10点这个时间段上需要执行10次,如果说任务A每次执行都需要上一个周期执行结束,那么任务A就是一个自依赖任务。
除了上述两种依赖任务,还有跨周期依赖,不同周期任务的父子依赖关系:子任务会找到父任务最近的执行的一个周期实例依赖。
● 补数据实例
补数据实例是用户通过页面或者调用接口触发生成实例,仅有局部的依赖关系且和周期实例的依赖关系相互独立互不影响,实例依赖关系和周期实例一致。
注意:补数据是生成局部的DAG图,例如 1、2、3任务关系是 1->2->3,在页面上选择1和3任务进行补数据,那么1,2,3任务都会生成,但是最终结果只会运行1和3任务,2任务不运行。
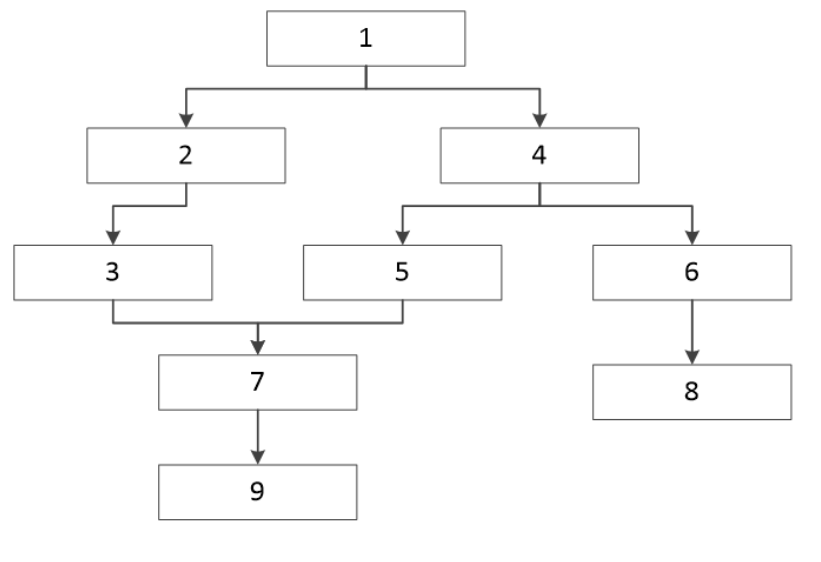
● 临时运行实例
临时运行实例可以分成两种离线和实时。
离线任务:用户可以直接运行任务生成实例,实例没有依赖关系。
实时任务:实时任务没有周期,上下游依赖这一概念,所以所以的实时实例都是临时运行的。
Taier周期实例生成
接下来我们来看一下Taier周期实例的生成。
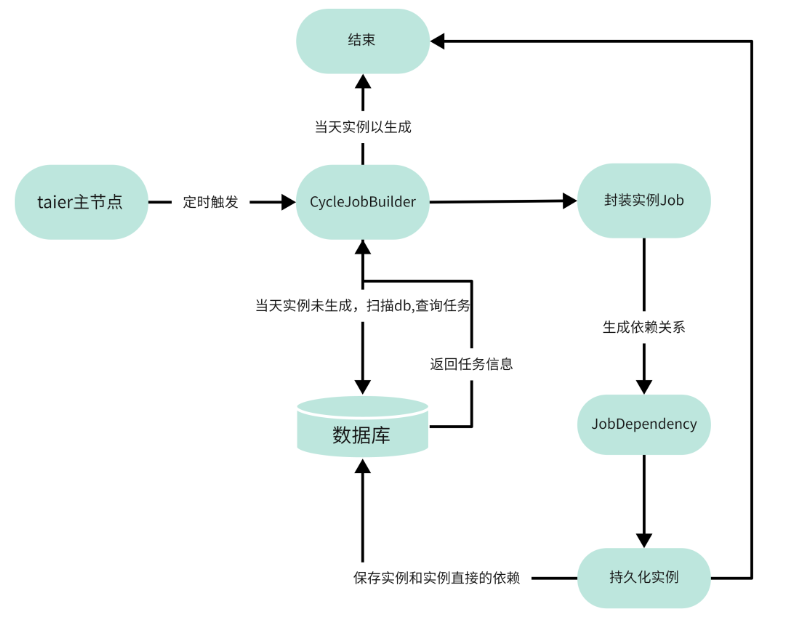
上图为Taier实例的整体生成图,Taier主节点在启动的时候会开启一个定时器,定时器会不停的去判断当日的实例是否已经生成,如果没有生成就会触发事件给CycleJobBuilder生成实例,再通过JobDependency封装实例之间的依赖关系。
其中CycleJobBuilder是指用于生成周期实例,扫描数据
库任务表并且获取zk上所有的taier节点,把封装后的实
例分配到每一台Taier节点上;JobDependency是用于生成job之间的依赖关系。
接下来为大家介绍下Taier的主从选举。
在application.properties文件中配置zk:
nodeZkAddress=${ZK_HOST}😒{ZK_PORT}/taier
● Taier服务注册
每一台Taier服务都会去把自己的地址注册到zk上/taier/brokers下,在生成实例的时候,主节点就是从/taier/brokers获取所有注册在zk的Taier节点信息。
每一台Taier服务和zk会维持一个心跳,并保存在/taier/brokers/ip:port/heart节点下。

● 主节点选举
Taier的主从选举是基于LeaderLatch来实现的,在启动Taier后,Taier会尝试去抢占/taier/masterLatchLock这边锁,抢到锁的节点就是主节点,没有抢到锁的节点就是从节点。

Taier实例调度
接下来为大家介绍下Taier实例调度,首先为大家介绍下调度流程。
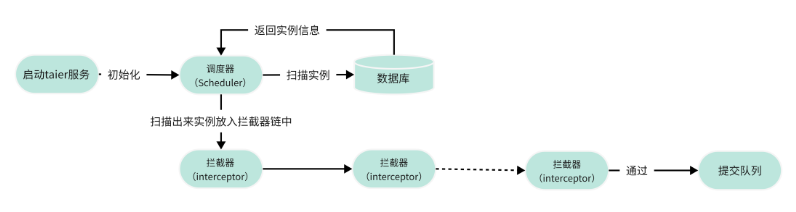
上图就是Taier实例调度的整体流程,在启动Taier服务时,会启动配置的所有调度器,并且开始扫描实例,并提交。
● 调度器
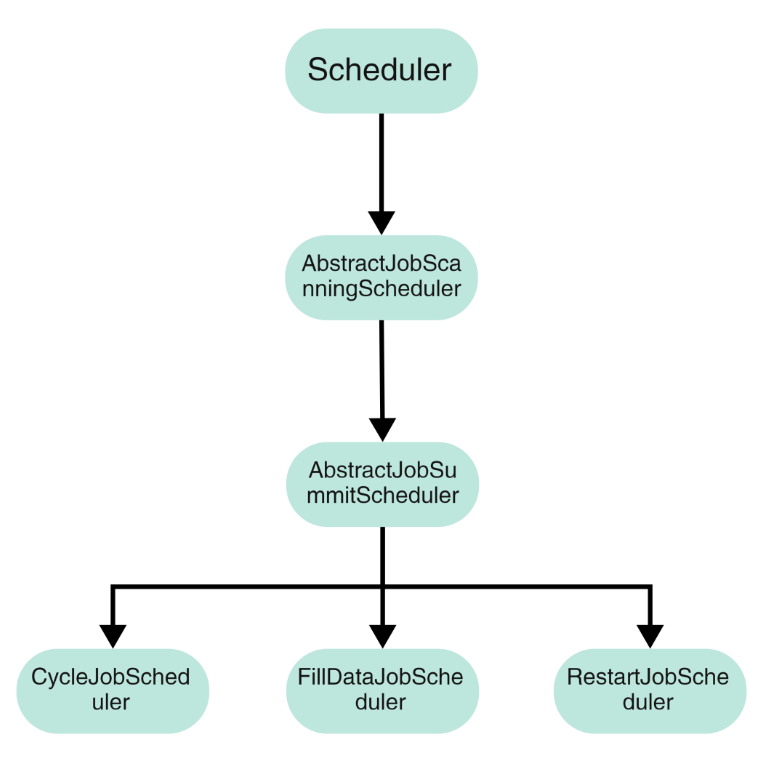
由于实例类型的不同,我们需要的调度器也会不同,但是他们都有一个父类(Scheduler)。
例如CycleJobScheduler专门负责周期实例的调度,而FillDataJobScheduler是负责补数据实例的调度。
不同的调度器,提交的条件也不一定,例如CycleJobScheduler只会扫描2天内的周期实例,而RestartJobScheduler是没有时间限制的,而且每一个调度器的拦截器链也会不一样。
● 拦截器
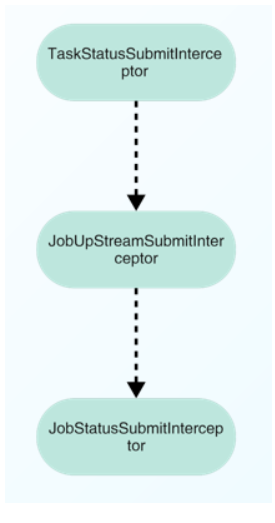
拦截器是用于负责检查实例是否到达提交条件,多个拦截器会形成拦截器链。当实例通过拦截器链时,说明实例到达提交状态,所以实例会被放入到提交队列中,等待提交。
默认提供的拦截器:
1.JobStatusSubmitInterceptor:用于判断实例状态。
2.JobUpStreamSubmitInterceptor:用于判断实例上游是否运行完成。注意,该上游实例不仅仅是上游任务实例,还有可能是自依赖实例。
3.TaskStatusSubmitInterceptor:用于判断任务状态是否正常。
每个调度器内装载的拦截器可以不同。
Taier实例提交
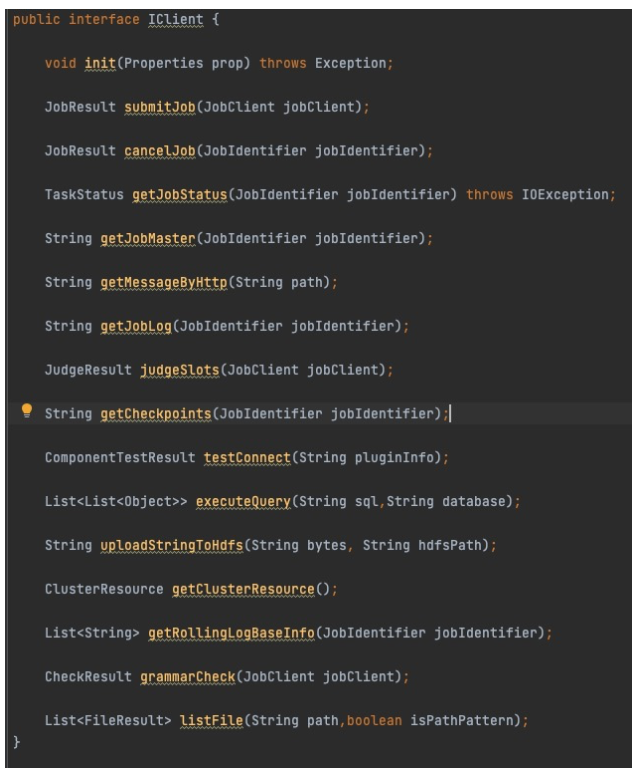
最后为大家介绍下Taier实例的提交,因为任务类型的不同,所以实例提交置计算节点的逻辑也不同,为了能有更好的扩展性,Taier实现类插件化的处理。
袋鼠云开源框架钉钉技术交流qun(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack

 浙公网安备 33010602011771号
浙公网安备 33010602011771号