数智洞见 | 数据中台架构解析及未来展望
数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx
《数智洞见》
数字化浪潮席卷而来,颠覆性创新正在加速。企业面临着前所未有的挑战和机遇,数字化转型成为其生存与领先发展的关键突破口。据研究数据显示,数字化转型程度高的企业获得快速增长的几率是程度低的企业四倍之多。如何进行数字化转型、如何通过利用大数据,找到新的机遇和价值增长点成为越来越多企业关注的话题。
袋鼠云数栈赋能20+行业,服务3000+客户,是研究数字化转型解决方案的先行者,产品融合了大数据行业云原生、信创、湖仓一体、批流一体、多引擎兼容、跨云能力等多项前沿技术,在金融、政府、教育、军工等众多行业领域积累了丰富的解决方案经验。本次袋鼠云数栈以“数智洞见”专栏为交流窗口,将先进的技术和产品方案经验进行传递、分享,旨在帮助解决数字化转型的痛点与困惑;同时探讨转型思路和机遇,助力更多行业伙伴完成数智化升级、成为数据价值释放的“受益者”。
本专栏每周更新1-2篇,敬请关注。
Vol.开篇
作者|思枢
编辑|雨濛
本文2554字 阅读约8分钟
互联网和移动互联网技术开启了大规模生产、分享和应用数据的大数据时代。面对如此庞大规模的数据,如何存储?如何计算?各大互联网巨头都进行了探索。
一、Hadoop技术生态起源
1.Google三篇论文揭开Hadoop序幕Google的三篇论文 GFS(2003)、MapReduce(2004)、Bigtable(2006)为大数据技术奠定了理论基础。随后,基于这三篇论文的开源实现Hadoop被各个互联网公司广泛使用。在此过程中,无数互联网工程师基于自己的实践,不断完善和丰富Hadoop技术生态。
2.日臻成熟的大数据技术生态经过十几年的发展,如今的大数据技术生态已相对成熟,很多公司也都选择开源的大数据框架构建自己的大数据平台,如下图:
Hadoop生态的大数据组件很多,每种大数据组件能解决特定场景的业务,所以大数据组件的选型是至关重要;下面通过袋鼠云自研的数据中台产品-数栈的整体架构介绍,来分析一些大数据组件的使用场景。
二、大数据组件使用场景分析
——以袋鼠云数据中台产品数栈为例
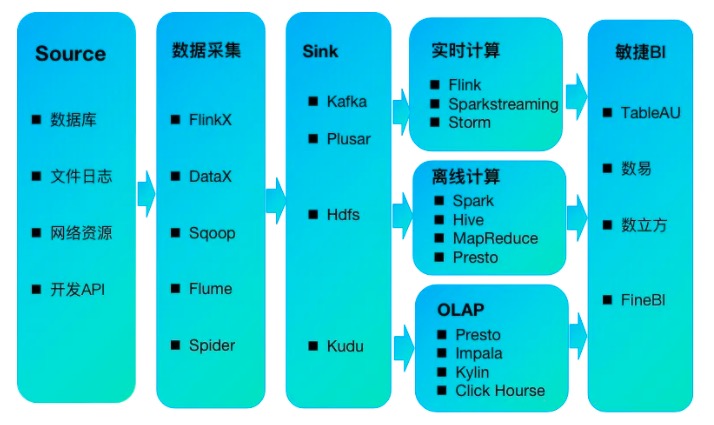
数栈是通用型的数据中台产品,是十分复杂的工程。整体架构主要分五层:一是平台层主要偏业务的上层数据应用;二是任务调度层主要是任务的定时调度和提交,需要远程无状态提交,对计算节点无侵入;三是资源管理层主要是cpu或gpu,内存等资源的动态管理,需要适配不同的资源调度组件;四是计算层主要是数据同步,实时计算,离线计算,算法建模等,需要适配不同的大数据计算组件;四是存储层主要是负责结构化和非结构化数据的的存储,需要适配不同的对象存储和本地存储;五是管控层主要是支撑数栈产品的快速部署,升级和监控。
如下是数栈整体架构图
1.平台层
微服务,单点登录

平台层架构图
平台层主要是偏业务的上层应用,数栈这边实现的有离线平台,实时平台,算法平台,标签引擎,数据资产,数据质量等应用;统一抽象了用户认证中心(UIC),各个平台的用户认证统一跟UIC对接,这样做的好处有两个;一,只要一个应用登录,进入其他应用无需再次登录;二,对接客户侧的用户认证体系,只要UIC对接就可以,各个平台应用无需做改造;业务中心主要是抽象了平台应用一些公共的模块并且提供rest api,例如血缘解析,元数据地图等功能。
2.任务调度层
分布式、水平扩展、插件化
任务调度层架构图
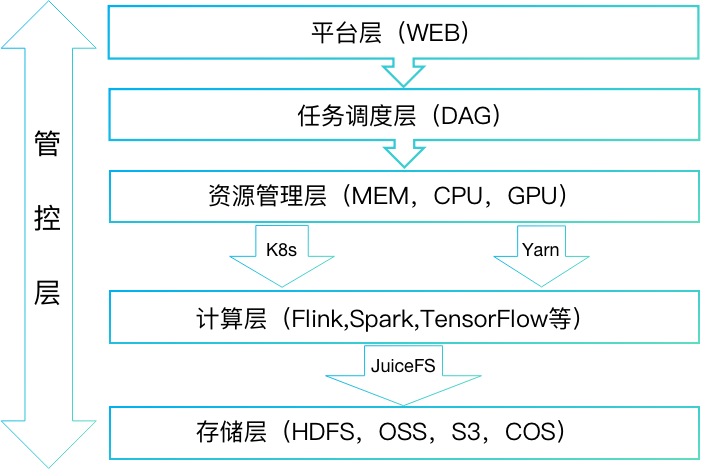
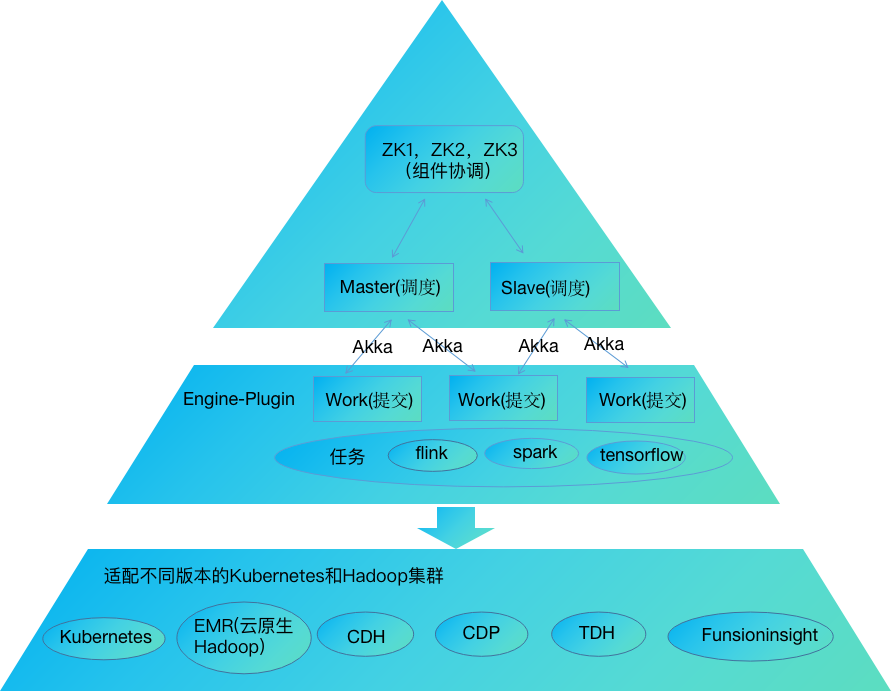
任务调度层是上层平台应用和计算引擎的纽带,所有的任务都要下发到这层,主要功能有两个;一是任务的周期性定时调度和依赖性调度(任务与任务之间有上下游依赖会形成有向无环拓扑图);二是把离线,实时,算法等任务提交到远端计算节点;任务调度层是有袋鼠云自研的框架DAGScheduleX来实现,DAGScheduleX是标准的分布式应用,有Zookeeper来做多节点应用协同,Master节点主要负责任务的调度策略和任务分发,Work节点负责任务提交到远端的计算节点;Master和Work节点通过Akka通信。
Work应用实现了一个Engine-plugin模块,它抽象了提交的接口,在把不同类型任务提交的具体实现以插件化的方式封装成一个个单独的jar包,在以SPI的方式加载,这样就能做到不同任务类型相互不干扰。任务的提交都是对接资源调度组件原生的API方式远程提交,对计算节点无侵入。市面上开源的任务调度主流框架有DolpinScheduler,Azkaban等,如下是DAGScheduleX跟其他框架的对比图。

对比图
3.资源管理层
云原生、插件化
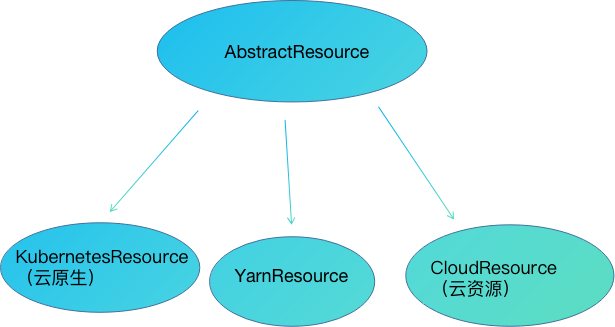
资源管理层管理的资源现在有3种,Memory(内存),CPU或GPU;数栈这边适配资源组件有3种,Kubernetes,Yarn,云资源列如阿里的MaxComputer;Kubernetes更适合云原生场景,计算存储分离架构;Yarn适合本地化私有云部署。
4.计算层
数据采集批流一体化、插件化
计算层任务主要有数据采集任务、实时任务、离线任务、算法任务等。
数据采集任务:“巧妇难为无米之炊”,没有数据也就没有后面的一切,数据采集作为基础至关重要;所以一套数据采集框架对数据的准确性、稳定性,数据源的自定义扩展等都有较高的要求;市面开源的框架很难都满足。
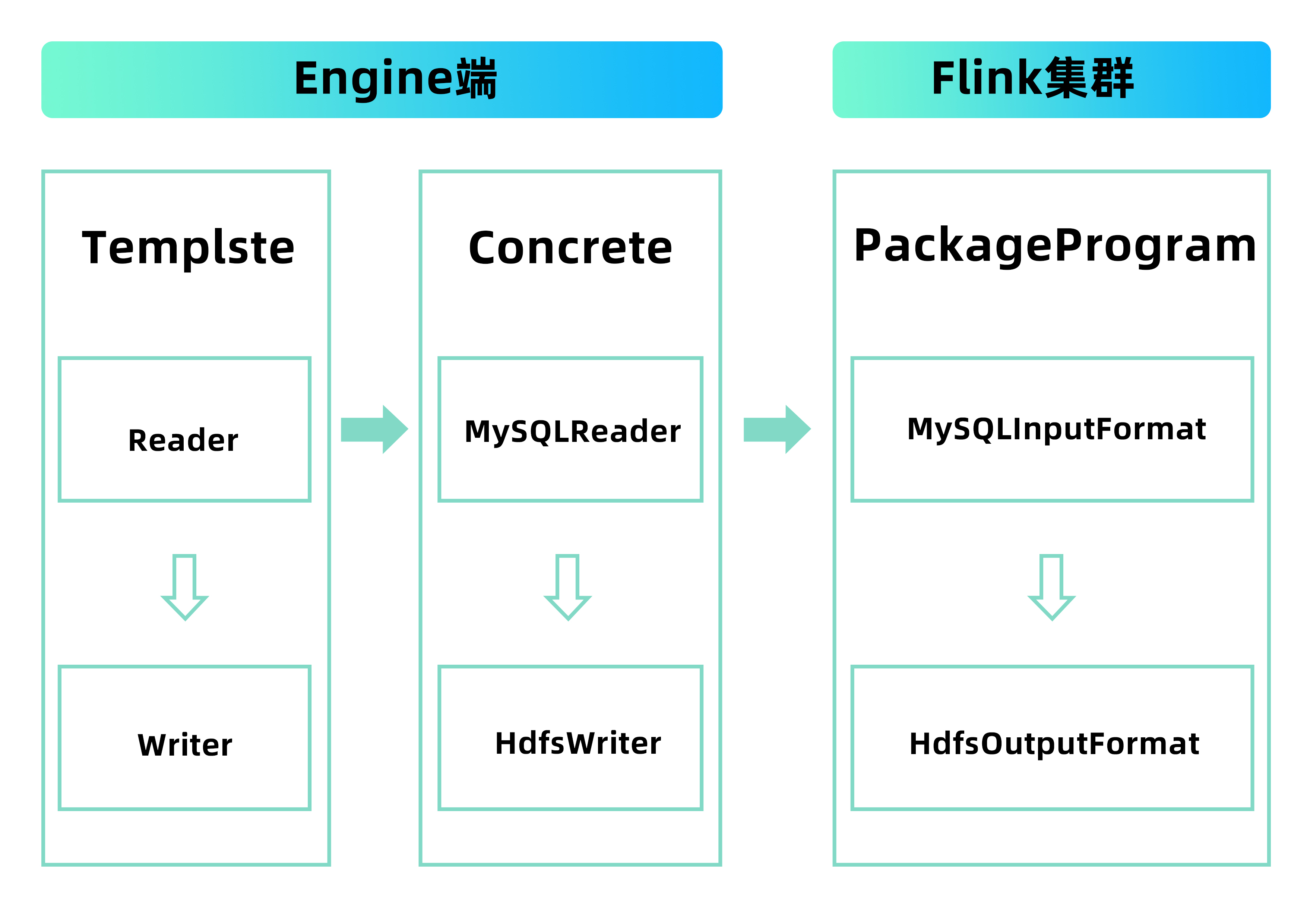
所以数栈自研了数据同步框架FlinkX;FlinkX是基于Flink实现的分布式同步框架,并且实现了离线同步和实时同步一体化;如下是FlinkX架构图。
如下是跟其他数据同步框架对比图:
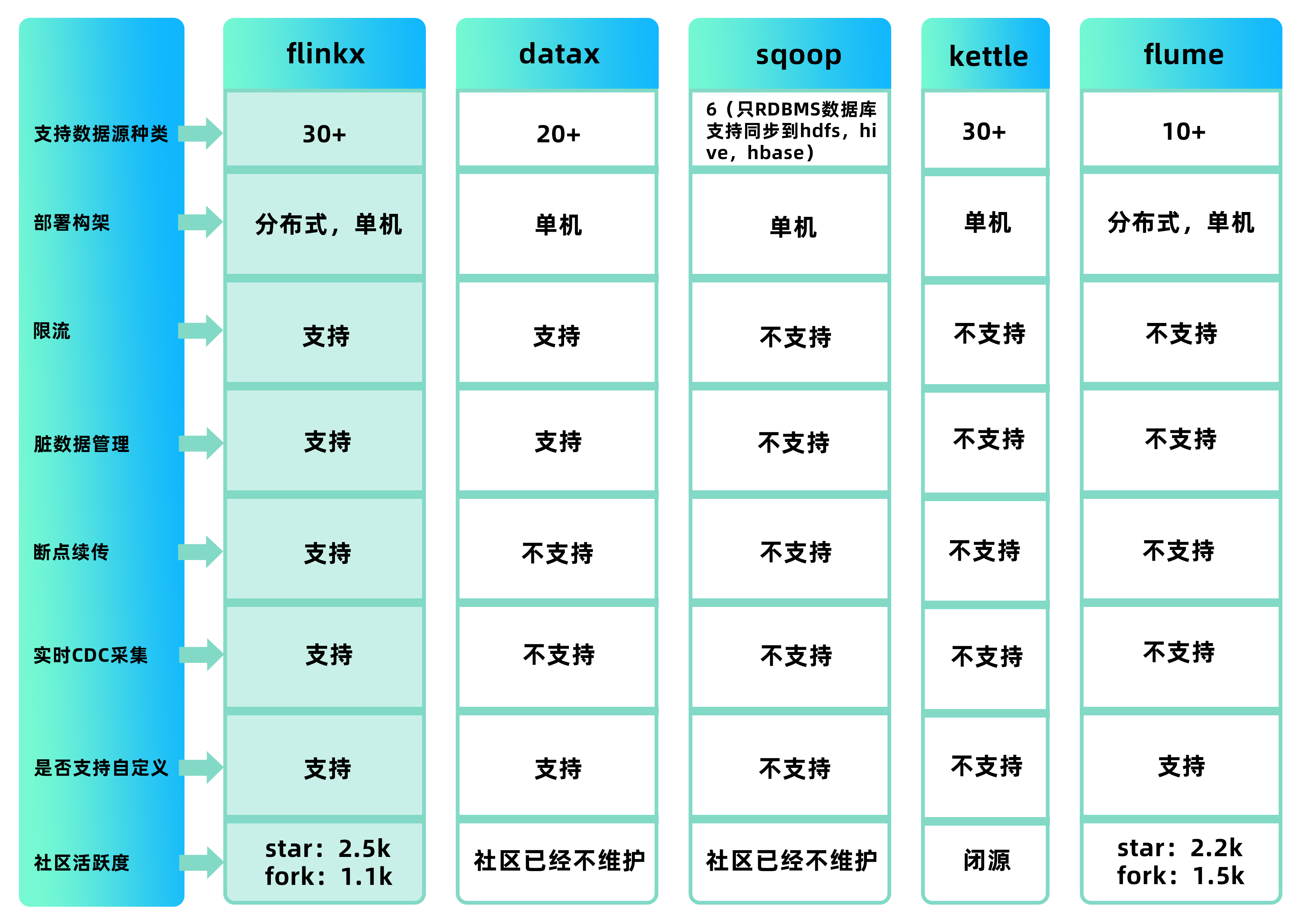
对比图
实时任务:现在主流的实时计算框架有Flink,Sparkstreaming,Storm;数栈选择用Flink构建了自己的实时计算平台。Flink是目前发展比较火的一个流系统,采用原生的流处理系统,保证了低延迟性,在API和容错上也是做的比较完善,使用起来相对来说也是比较简单的,部署容易,而且发展势头也越来越好,相信后面社区问题的响应速度应该也是比较快的。个人对Flink是比较看好的,因为原生的流处理理念,在保证了低延迟的前提下,性能还是比较好的,且越来越易用,社区也在不断发展。
如下是三个框架的对比:
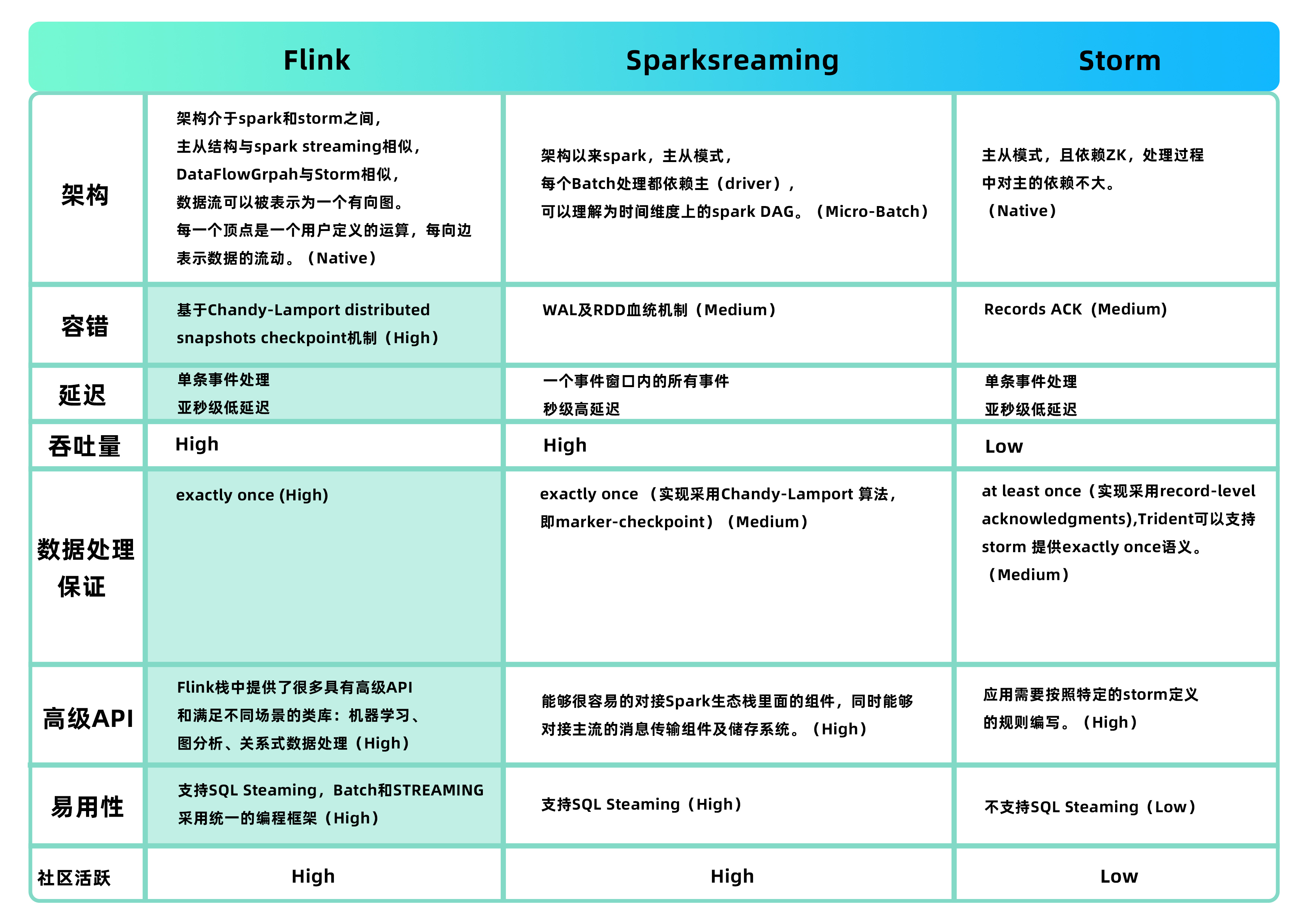
对比图
离线任务:离线计算现在主流的框架有Spark,Hive,MapReduce等,每个框架使用要看具体的业务场景;Spark是内存计算,所以耗内存,计算效率高,并且支持SQL,使用门槛较低;MapReduce中间数据可以落盘,所以内存要求较低,但是计算效率会慢,不支持SQL,有一定的使用门槛;Hive有两种模式 on Spark 或者 on Mapreduce,支持SQL,统一的元数据管理,适合构建数据仓库;数栈是都适配了这三种计算框架,根据客户不同的业务场景和机器资源配置来选择。
5.存储层
计算存储分离,多种存储引擎兼容
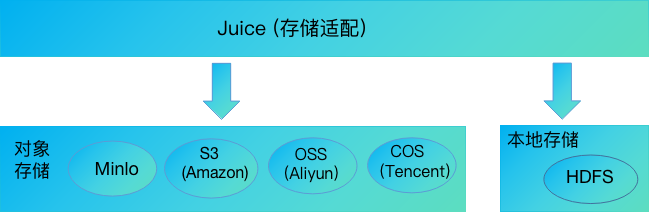
数栈引入JuiceFS框架做存储的适配层来屏蔽底层的存储设备,这样就能灵活的适配各种存储,对上层应用和计算引擎不需要做额外的代码开发。JuiceFS 是一款高性能 POSIX文件系统,针对云原生环境特别优化设计,所以更适合云原生架构,让计算和存储松耦合,真正做到计算存储分离。
6.管控层
一键可视化、自动化、全域
管控层主要的职责是是对整个数据中台应用做一键可视化部署、升级、监控;因为整个数据中台涉及的组件是很多的。有上层的平台应用,还有底层的大数据组件,这些应用有十几种,后续随着业务的升入涉及的组件会更多。所以,靠人肉写脚本的方式很难在段时间的完成部署升级;市面上主流的框架类似CDH、HDH、TDH等都能做到大数据组件的部署和管控;但是他们只能对大数据组件,不支持自定义的应用程序。所以袋鼠云自研了EasyManager应用来全域的管控业务应用和大数据组件,并且能快速支持一个新的组件无论是自研的还是开源的。
EasyManager是用go技术栈开发,核心是schema文件,里面描述了组件相关的信息和各个组件的依赖关系;EasyManager主要分两层,一是matrix server;二是agent server;matrix负责schema文件的解析并把相应的参数和指令下发到agent,有agent负责应用的启动,停止等动作;还引入了Grafana和Promethus,做应用监控数据的收集和展示;EasyManager现在能支持基于物理机,虚拟机,Kubernutes的部署; 如下是EasyManager架构图:
EasyManager架构图 以上是数栈整体架构介绍;但是随着数据的不断增长,客户的业务复杂度的增加,技术架构也会随之升级来迎接未来的挑战。
三、未来展望
大数据技术迭代更新很快,一些新的大数据理念也层出不穷,数栈也会随着迭代更新和架构升级;数栈近期主要在做批流一体和湖仓一体的研发;批流一体主要解决的是以相同的处理引擎来处理实时事件和历史回放事件,保证有无故障情况下计算结果完全相同。湖仓一体主要做的是统一元数据管理并能同时支持结构化和非结构化数据存储和分析;对外能提供存储层批流统一接口。 数栈整体架构中使用很多组件大部分都来自开源社区,我们在平时的开发中也沉淀和抽象出一些框架并且已经回馈给社区比如FlinkX,Easyagent等,还有即将开源的任务调度框架DAGScheduleX。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号