Flinkx Logminer性能探测&优化之路
数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx
前言
FlinkX是袋鼠云自研大数据中间件,主要针对离线同步和实时采集功能进行实现。在实际应用中,这种数据同步采集的逻辑我们最需要关注的就是他的支持能力和采集速度,这些是其最直观的指标。通过对其支持能力的性能测试,找到FlinkX的性能瓶颈,有针对性的进行优化,提高中间件的能力。
本文对于FlinkX中实时采集的功能,Oracle Logminer数据实时采集的逻辑进行性能测试并分析,分享在测试过程中的测试点与测试方法。
1.测试目的
针对FlinkX Logminer的性能测试主要是为了探测FlinkX在Oracle Logminer数据采集到Kafka过程中,各个阶段的性能情况,输出性能测试指标测试数据供后期优化。探测FlinkX的性能瓶颈,指导并逐步提高FlinkX在大数据量或复杂情况下的处理能力。对于大数据中间件的测试,不仅要关注其功能层面,尤其需要关注其性能层面的问题。中间件对于数据处理能力的效率直接影响到了业务的稳定性,可用性,数据的及时性以及客户的体验,是重中之重的关注点。
2. 测试对象介绍
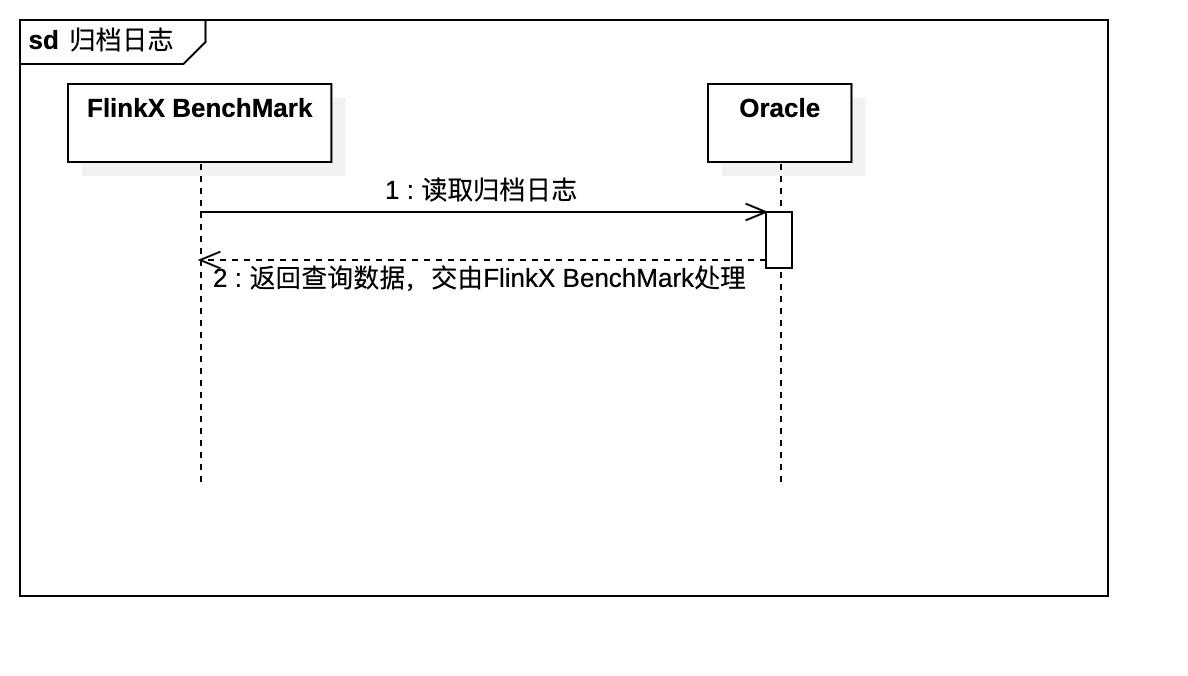
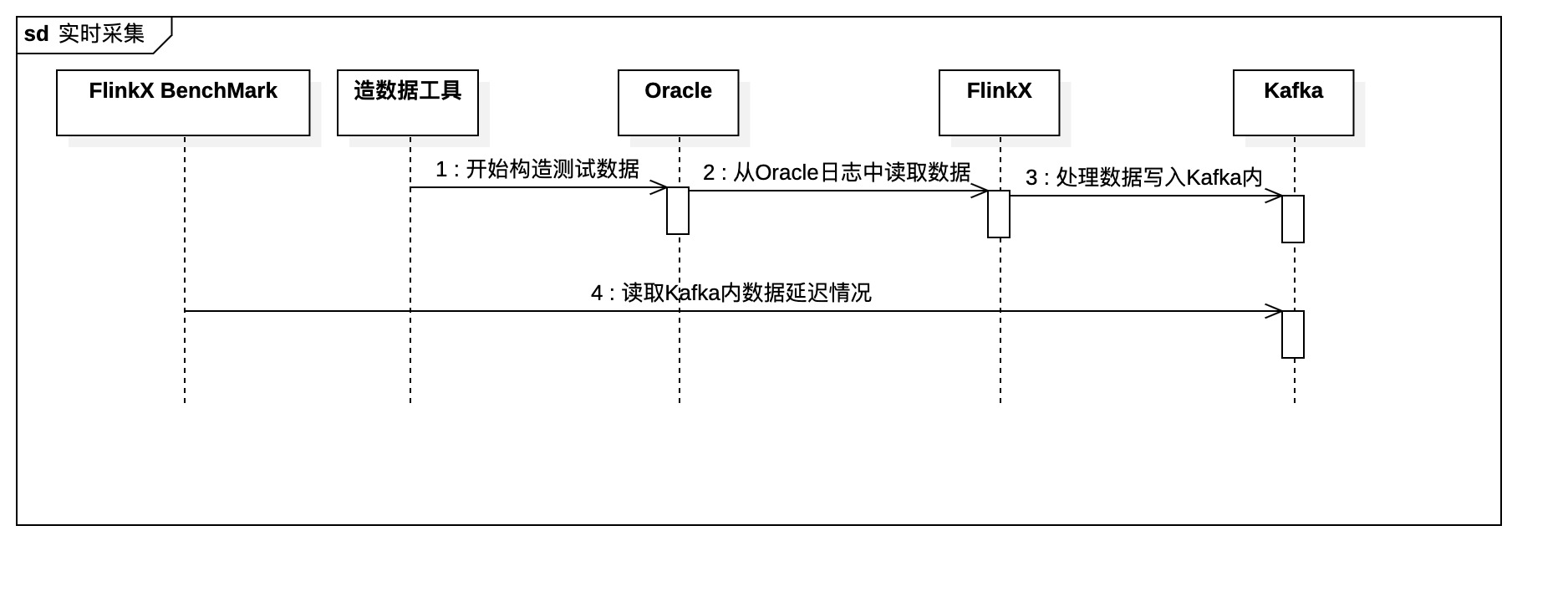
2.1. FlinkX
FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,支持比如MySQL,HDFS等,将数据从数据源A同步到数据源B。也可以采集实时变化的数据,比如MySQL的binlog,Oracle的Logminer,Kafka等。在进行采集时,FlinkX分为两部分逻辑,一部分是从原数据源读取的逻辑,例如读取MySQL或者Logminer内的数据,另一部分是将读取到的数据处理后写入对应数据源的逻辑,例如写入HDFS,写入Kafka等。所以对于FlinkX的性能测试,我们往往分两部分进行,一部分是读的测试,一部分是写的测试,因为短板效应,可能在其中一个点的短板导致了整体采集效率低的问题。
2.2. Logminer
Oracle在开启Logminer后,所有对用户数据和数据字典的改变都记录在Oracle的Redo Log中,通过Logminer分析Redo Log,可以获得数据变化的所有内容。分析后可以得到一些可以用于回滚的SQL语句,常用于恢复数据库中某一段的数据变化。
2.3. FlinkX实时采集逻辑
FlinkX常见的实时采集逻辑,都是先从源数据采集,经过数据处理后再写入目标数据源。例如本次测试的FLinkX Logminer,就是FlinkX从Oracle的Logminer中采集日志数据,经过对日志数据的处理后,将处理后的数据写入kafka。FlinkX对于Logminer的日志读取分为归档日志(ARCHIVE)的读取和实时日志(ONLINE)的读取,区别在于Redo Log内的数据是历史写入的归档数据,还是实时写入的实时日志如图1-1。以此区别,我们划分成两大类进行测试,分别是归档数据和实时采集数据。
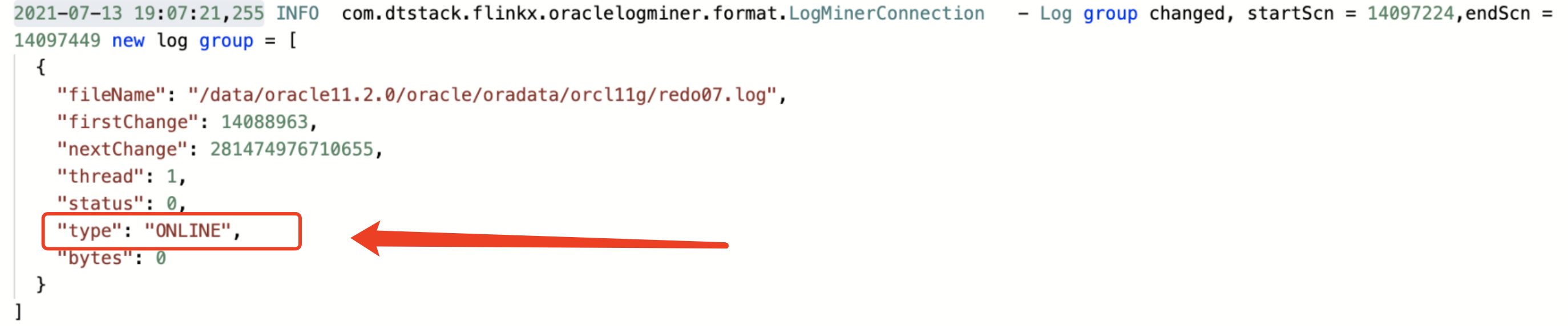

图1-1
3. 测试工具
3.1. 测试工具介绍
3.1.1. Arthas
Arthas 是一款Alibaba开源的Java诊断工具,其查看调用,debug,查看进程线程信息等功能对于开发测试均有巨大的帮助。在本次测试中,主要运用其中的dashboard,thread来查看进程线程状态,以及使用profiler生成调用链路火焰图,定位被测对象运行逻辑中,调用占用资源较多的类或者方法。
3.1.2. Grafana/Prometheus/EasyManager
Grafana是一款优秀的开源数据可视化工具,在测试中常用作数据监控的展示面板工具。Prometheus则是由 SoundCloud 开源监控告警解决方案,用于存储服务器监控数据以及时间序列。二者经常配合在一起使用,通过一些exporter来监控服务器资源或者数据源状态然后将数据存储在Prometheus中,Grafana从Prometheus中获取监控存储的数据通过不同的监控面板展示给用户。方便测试人员更便捷的对被测系统进行系统监控,数据分析,状态分析。
EasyManager是数栈自研的运维利器,用于部署袋鼠云数栈的各种应用,在本次测试中我们主要借用其服务器资源监控的功能,方便我们进行资源数据分析,这个也可以替换运用Grafana进行监控。
3.1.3. jstack
jstack用于生成java虚拟机当前时刻的线程快照。线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。 线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源。
3.1.4. Oracle AWR
AWR 是 Oracle 10g 版本之后推出的新特性, 全称叫Automatic Workload Repository-自动负载信息库。它是一种Oracle提供的性能收集和分析工具,是进行Oracle性能调优的利器。它能提供一个时间段内整个系统资源使用情况的报告。
3.1.5. FlinkX BenchMark
基于JMH BenchMark框架,拆解FlinkX采集过程中的每步动作,基于每一步模仿FlinkX处理逻辑编写的性能测试工具。主要用于本次FlinkX Logminer采集的性能测试执行工具。
3.2. 测试机器配置
|
CPU |
内存 |
用途 |
|
32C |
64G |
性能测试环境Hadoop集群节点一 |
|
32C |
64G |
性能测试环境Hadoop集群节点二 |
|
32C |
64G |
性能测试环境Hadoop集群节点三 |
|
32C |
64G |
性能测试环境Oracle数据源 |
|
16C |
32G |
性能测试环境执行端 |
4. 测试策略&关注点
本次测试开始前,先将FlinkX的采集逻辑进行梳理,因为FlinkX对于Logminer采集的流程主要是归档日志/实时日志读取,然后数据处理,再将数据写入到不同的数据源,那么我们便将整体的逻辑拆分为归档日志处理(日志读取,数据处理)和实时采集(日志读取,数据处理,写入其他数据源)两块。对于归档日志处理我们划分为归档日志读取,归档数据处理以及整体的端到端(全链路)几个内容,针对几个不同的逻辑分别进行测试,看耗时较长的在哪一步,针对这一步的处理逻辑我们再进行具体分析。对于实时采集部分,我们主要是测试数据从Redo Log中读取到写入kafka的延迟情况,结合归档日志处理部分的测试内容,来分析实时采集的延迟原因,以及延迟情况。
对于以上测试内容,我们在测试过程中需要关注归档日志的读取,处理速度,耗时。实时采集时,数据从写入到Oracle到采集到Kafka的延迟情况。这些是主要产出的测试指标,同时我们也需要关注应用在测试的过程中对于采集端(Oracle)的资源占用,应用本身(FlinkX)的资源占用,线程情况,写入端(Kafka)的监控情况。
对于Oracle端,我们需要关注是否存在慢SQL,因为FlinkX会先执行SQL从Oracle Logminer中获取Redo Log的信息,那么这些SQL是否可以进行优化,是否有耗时过长的情况,这个需要关注。然后是数据库的负载情况,看一下整体Oracle的空闲情况,是否充分利用资源,以及硬解析次数是否过高,是否存在一些阻塞的情况。
对于FlinkX,我们需要关注应用本身的资源占用情况,通过Arthas分析JVM资源分配是否合理,以及在调用链路中,哪些类、方法占用资源过多,耗时较长。通过jstack对线程进行分析是否存在有堵塞,锁死的情况等。
对于写入端,我们主要关注在不同的条件下,写入速度是否有影响,是否存在高差值的波动。
5. 测试流程
一、首先我们需要开启Oracle Logminer,并设置好日志大小为521M。这里开启Oracle Logminer并设置日志组大小的方法就不赘述了,可自行通过搜索引擎搜索。
二、根据我们的测试用例,分别执行归档日志部分和实时采集部分的测试用例。测试用例如图5-1所示: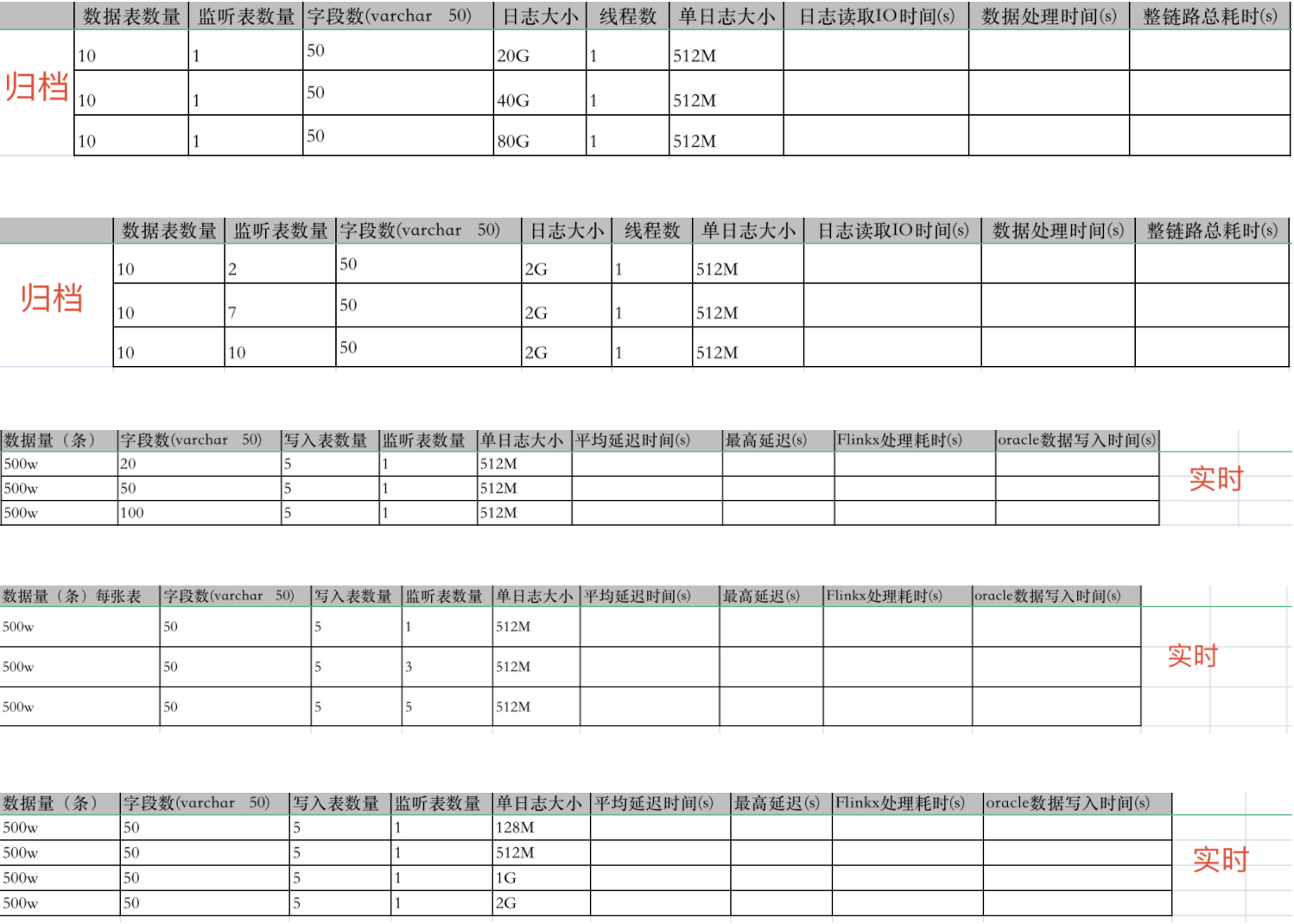
图5-1
性能测试的测试用例设计需要保证单一变量原则,方便进行对比,例如在本次测试中,根据不同的变量,将测试用例分成了不同的类型,分别分析监听表/日志大小/字段数对测试结果的影响。
对于归档日志部分的测试,整体的逻辑是先构造归档日志,然后通过FlinkX BenchMark模拟FlinkX对这部分归档日志进行测试。那么我们需要先通过一些测试造数据的工具,或者存储过程函数来对测试表插入大量测试数据。然后通过SQL查询,关注生成的归档日志大小达到指定数量级。例如我的测试用例中是2G/20G/40G/80G,数据表数量为10,那么我需要在同一个时间内,对10张表进行数据写入,在生成的归档日志达到我需要的大小后,停止数据写入。然后通过FlinkX BenchMark工具,对这些归档日志指定SCN位置进行读取,处理测试,记录测试数据。当然这其中要关注一些监控数据,下文会继续说。
对于实时采集部分的测试,整体的逻辑是FlinkX从Logminer实时采集数据,Oracle在实时的写入数据,FlinkX在处理后写入Kafka,测试写入Oracle的数据和写入Kafka的数据延迟时间。我的逻辑是,创建一个Oracle Logminer到Kafka实时采集的FlinkX任务并运行,同时使用造数据工具同时对Oracle写入数据,这样就完成了前半部分,一边写一边读,然后实时采集任务将数据写入Kafka后,因为Kafka在写入数据时会带有时间戳,通过FlinkX BenchMark去Kafka内取数据的时间标记,计算数据的延迟时间。
三、在测试过程中,需要关注各项监控数据,例如服务器的资源,应用的线程情况,数据源的监控信息。如果出现异常情况,例如抖动较大的CPU占用,一直处于等待状态的线程,数据源的读取写入异常等等情况,要及时排查,通过jstack捞一下堆栈的快照信息,分析是否存在问题等。同时在测试过程中,需要使用Arthas生成稳定运行期间的火焰图,方便后续进行数据分析。
四、测试数据分析,通过在测试过程中的数据监控情况,测试结果,各条测试用例对比,分析本次测试中,性能问题所在位置,以及优化方案等。
五、输出测试报告与开发核对,确定后续优化方向及优化方案。
接下来我们拿具体用例具体流程分析。
6. 数据分析
借用归档日志部分的测试用例我们来看整个过程,本篇文章采用归档日志20G大小,监听1张表这一条来分析。
首先在执行测试的过程中,对于拆分后的每一部分(日志读取/数据处理/整链路)我们都需要观察测试执行端(FlinkX BenchMark)的资源占用情况。这里我取整链路的监控情况来分析,优先查看CPU和内存的使用情况。从图6-1中我们可以发现,整体资源占用较为稳定,没有异常的陡增陡降发生,基本是在一定的区间内来回小幅度抖动。这种情况一般是没什么异常的,但是如果有差距较大的波峰波谷时,这种需要看一下是否存在问题。
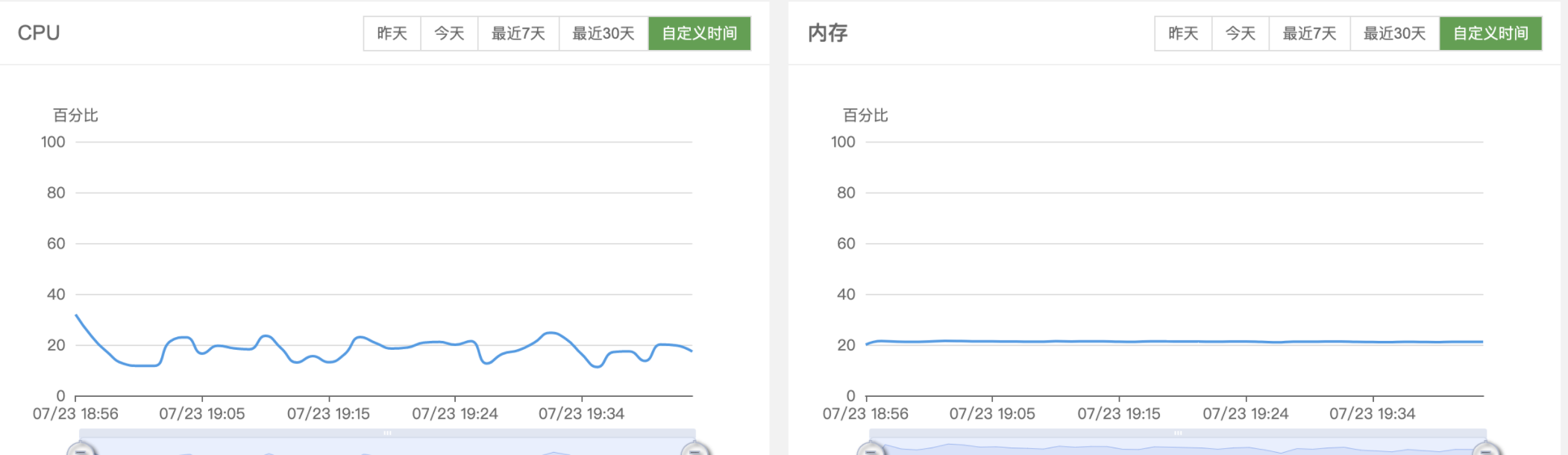
图6-1
测试执行机总共是16C32G的配置,从图6-2来看Java进程占用资源也并不多,并且没有CPU资源占用不均的情况,那么我们暂时推测问题不大,没有异常情况。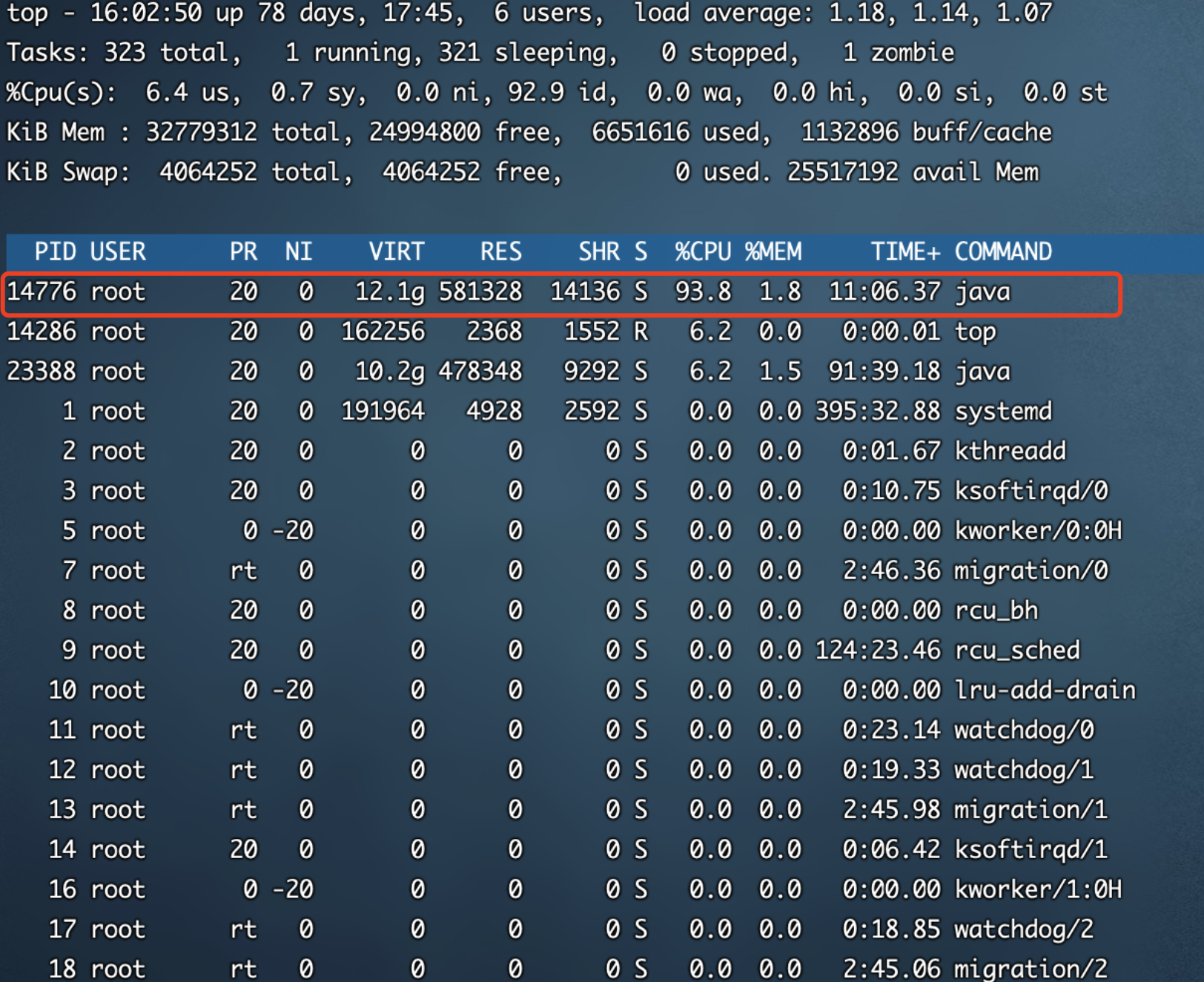
图6-2
然后我们去看Oracle数据源的监控情况,如图6-3,数据源的机器系统资源占用也不多,但是有很明显的波峰波谷差,判断可能存在一些耗资源较多的SQL,在执行时对资源占用较多,执行之后资源释放。这种SQL就有可能是慢SQL,我们需要捞出来看一下的。
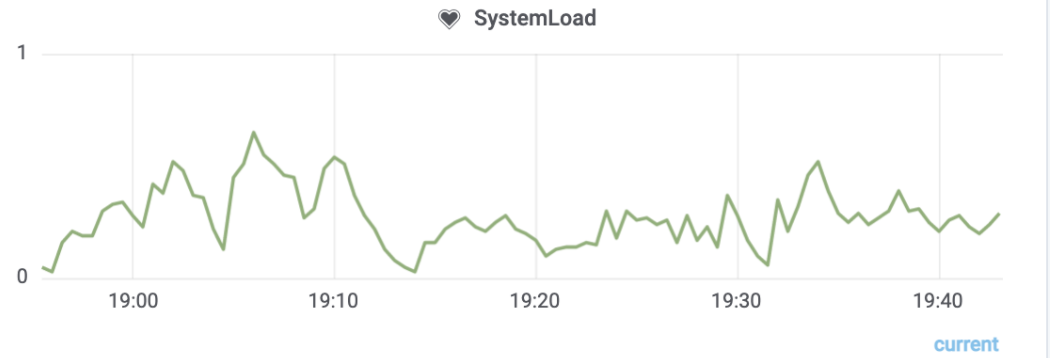
图6-3
通过top命令,如图6-4,我们也可以看到oracle占用资源较多,我们捞一下占CPU较多的执行SQL
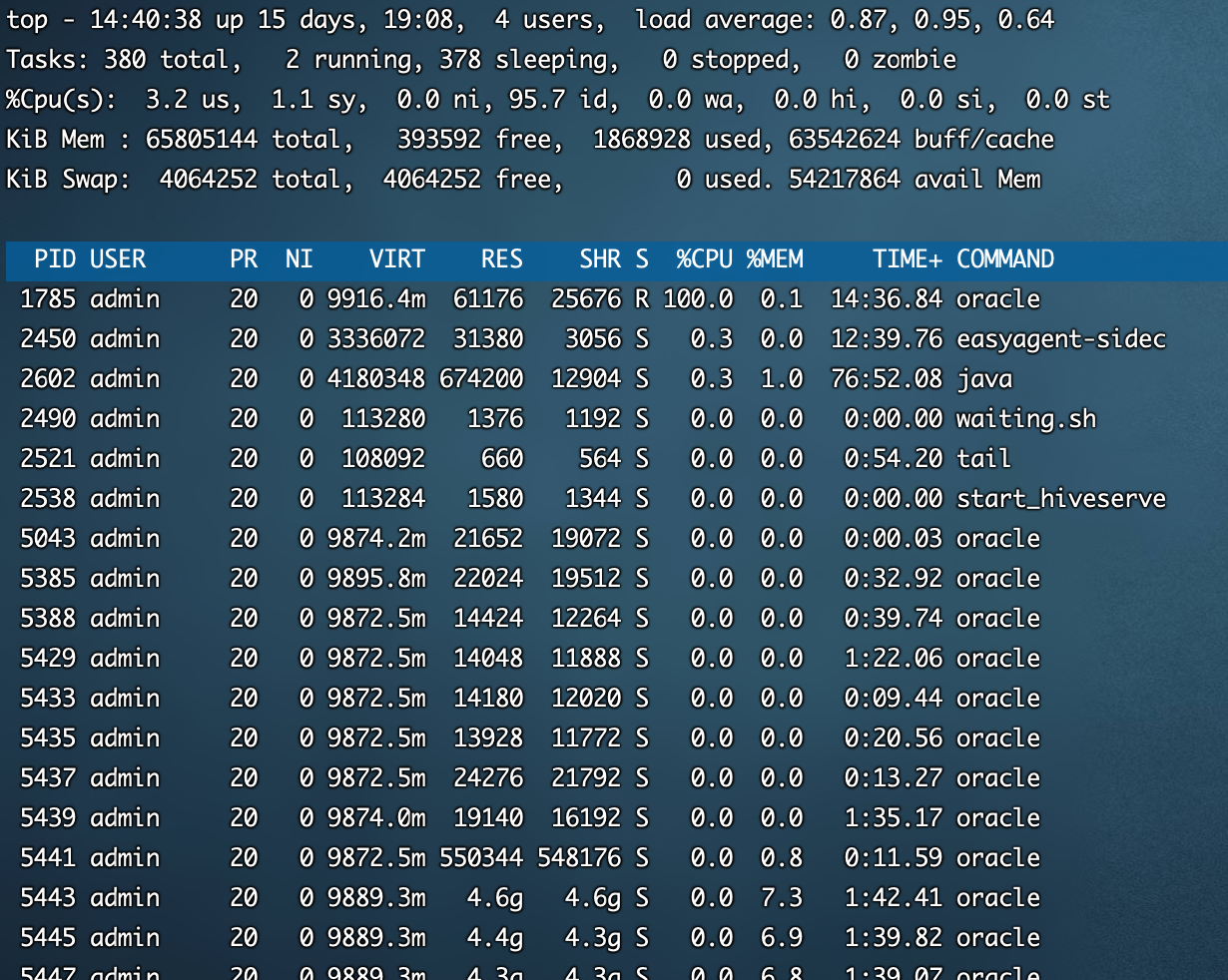
图6-4
SELECT scn, timestamp, operation, operation_code
, seg_owner, table_name, sql_redo, sql_undo,
xidusn, xidslt, xidsqn, row_id, rollback, c
sf FROM v$logmnr_contents WHERE scn > :1 AND scn <
:2 and ( ((SEG_OWNER='ORACLE' and TABLE_NAME='YUNCHUAN_LOGMI
NER01')) and OPERATION_CODE in ('1','3','2') or OPERATION_CODE
= 7 )
分析这段SQL,我们可以发现,这其实是一段捞Redo Log日志的SQL,那么其耗CPU较多,就可以理解了,属于正常SQL,但是这个SQL有没有优化的空间我们可以后续再看看。
经过上面的简单分析,我们基本可以得出在运行过程中,FlinkX是没有什么明显影响性能的异常情况存在的。那么我们就需要进一步对逻辑进行分析,看一下具体的线程情况,这时候就需要用到jstack和Arthas了。
我们通过jstack和Arthas将运行过程中,执行端的调用堆栈信息抓取出来进行分析,这里涉及到一些敏感信息就不上图了。通过jstack和Arthas抓取火焰图我们可以分析出整体调用中,FlinkX在日志读取后的数据处理部分耗时较多,梳理出来具体的类后就可以提给开发作为优化方向了。配合火焰图和堆栈信息,也能更快的帮助开发定位具体问题点。
到此,单个用例执行的分析就到此为止了,接下来就需要完成其他测试用例,然后进行对比分析,看不同的变量间是否存在关系。我们把测试完后不同日志大小的数据处理时间拿出来,画成折线图,如图6-5,会发现整体的耗时随日志大小的增加几乎呈线性关系,数据越大,耗时越长,跟我们之前的分析是一致的。
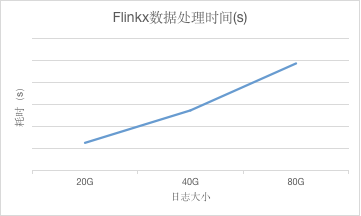
图6-5
7. 收益
在以往的功能测试中,测试人员很少关注组件性能方面的情况,基本上保证功能可用就算ok了。但是这一次针对FlinkX Logminer实时采集的性能测试,让我们分析出了FlinkX在实时采集中的性能瓶颈,FlinkX在性能方面还存在有优化的空间,我们将具体需要优化的方向同步到开发,排进迭代进行优化。在之后开发在针对性能瓶颈点有方向的优化,我们回测可以发现,经过本次的优化提升了FlinkX实时采集性能的20%,几乎缩短原先同步所花费一半的时间,可以说在业务的稳定性,可用性,数据的及时性上跨进了一大步,整体是十分有意义的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号