数栈技术分享:产品经理在线官方解答数栈小知识
使用袋鼠云数栈的某教育行业客户,在之前的信息化过程中建设了多个系统,已经意识到自身数据孤立的现状,面对TB级的数据量,需要更高效的方式进行数据治理和分析,为业务方提供高质量数据。
其实,数据治理不仅仅是教育行业用户的痛点,同样也是其他行业进行大数据平台建设和数据应用,最亟需解决的难题。
针对这一问题,袋鼠云数栈基于十年实践经验沉淀的多种校验规则,打造了完整的全流程数据质量闭环管理机制,同时支持数据迁移&逻辑变更的双表逐行校验场景。
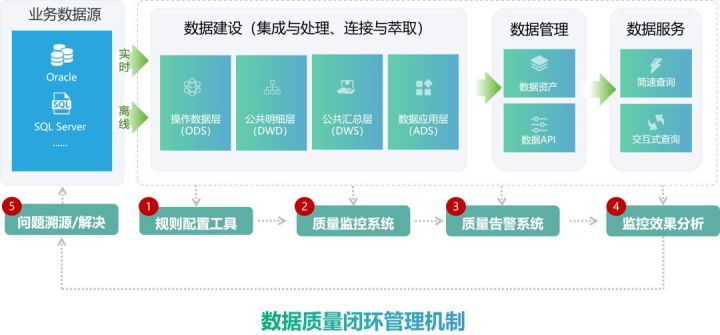
类似以下问题,袋鼠云数栈都能统统搞定!
Q1:
有很多ETL任务,任务运行正常,由于数据源有变动,或开发修改了代码,测试不充分,导致数据经常出问题。最后还是业务方发现后,才反馈给开发排查原因。
An:
使用数栈可对关键任务配置数据质量校验规则,任务跑完产出数据,并经过质量校验通过后,才流入到下游,给到数据需求方。
Q2:
开发人员维护ETL任务,由于业务规则的变更或者新需求的迭代,需要经常修改ETL任务逻辑。每次修改后比对数据,耗费大量的时间。
An:
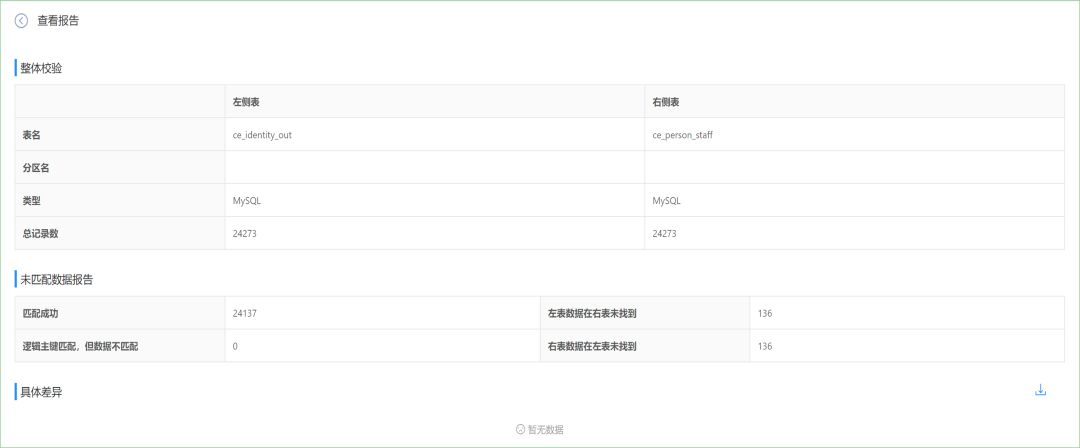
使用数栈通过数据质量产品的双表校验功能,自动比对修改前,修改后的数据,输出比对结果,无需人工干预。
Q3:
需要把在某平台运行的任务迁移到另外一个平台,同时保证迁移前后数据的一致性。以往则需要人工或写程序进行校验,真的是费时费力。
An:
使用数栈通过数据质量产品的双表校验功能,自动比对迁移前后的两个平台的数据,输出比对结果。
Q4:
在数据抽取的过程中,数栈能否对数据的正确性进行判断?
An:
对这个问题,数栈可以提供2个解决方法:一种是在数据同步环节就进行脏数据相关的配置;还有一种是在数据加工全流程环节进行数据质量监控的配置;
也就是说,从数据的同步到整个数据加工全流程,袋鼠云数栈都非常重视数据质量和数据治理,保障用户数字化建设过程数据资产的高质量。
解法一:脏数据配置
在数据同步执行的过程中可能会出现因主键冲突、格式转换错误等各种原因造成部分数据无法正常写入,不能被正常写入的数据即被视为“脏数据”。
脏数据配置在数据同步配置模块中,在数据同步任务的通道控制步骤中,可配置是否需要记录脏数据,并可指定存储脏数据的表名、生命周期。
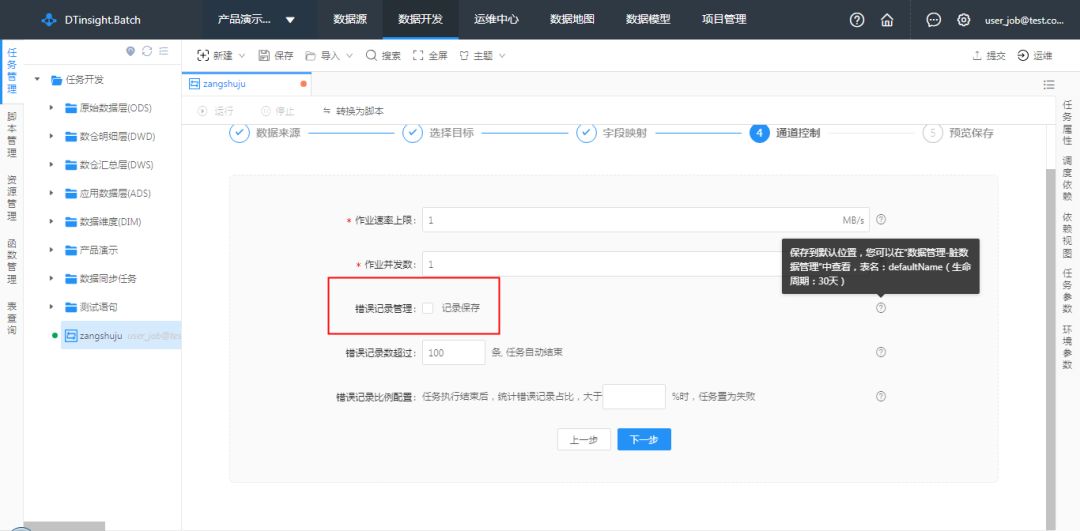
那么如何查看脏数据,对数据质量做到心中有数?
在数栈-任务管理-脏数据管理模块中可以查看脏数据的产生趋势、产生脏数据最多的任务,以及每一张产生脏数据表的情况:
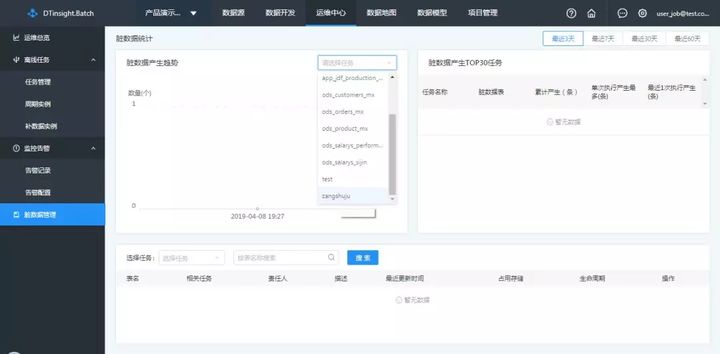
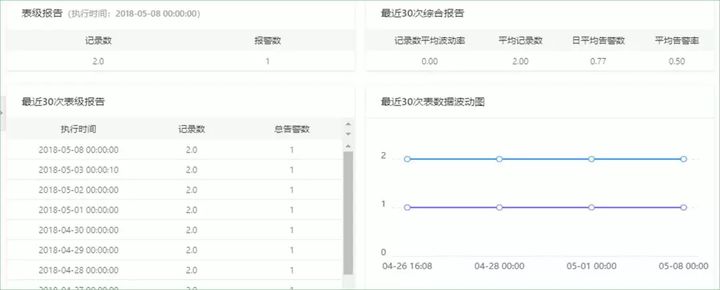
脏数据产生趋势
选中某个任务后,可以查看此任务在最近一段时间产生脏数据的数量,支持最近3天、7天、30天、60天的数据查看。
脏数据产生TOP30任务
通过观察产生脏数据数量较大的任务,可以针对性的排查此任务的配置信息、源数据库的数据质量等问题,及时解决问题。
解法二:数据质量配置
作为数据资产管理的一部分,数据质量的保障与提升是一个大数据平台所需的必备功能。通常含义的数据质量包括及时性、完整性、一致性、有效性、准确性。
数据质量模块可以根据不同的业务场景,针对数据表提供表行数、空值数、空值率、重复数、重复率等二十余种统计函数,校验方法支持固定值检测、1天波动检测、7天波动值变化检测、30天波动值检测、7天平均波动检测、30天平均波动检测,告警阀值支持灵活的自定义。
那么如何使用数栈创建质量监控任务?
创建质量监控任务分为以下3个步骤:
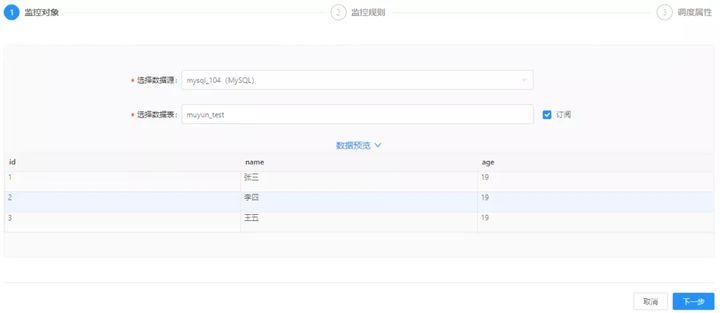
Step1:选择数据源,选择需要校验的表
点击顶部菜单的规则配置-新建监控规则,进入配置页面,选择需要进行检测的数据表(表名为 muyun_test),点击下一步。
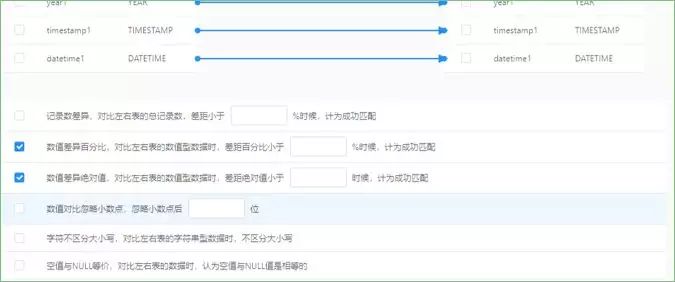
Step2:针对全表、每个字段配置校验规则
进入监控规则步骤,点击添加字段规则,并选中id字段,统计函数选择空值数,校验方法为固定值,阈值配置为=0,点击保存,并点击下一步。
Step3:调度周期配置
选择调度周期为天,其他参数无需修改,点击新建,即可完成配置。
数栈数据质量模块支持MySQL,Oracle,SQL Server,PostgreSQL,Hive,MaxCompute等多种数据源,满足大多数场景下的质量校验需求。
基于阿里数据生产的实战经验,数栈内置20余种校验规则,支持表级、字段级2类规则,并提供字段级、表级校验报告,具备历史数据统计功能,辅助用户定位数据质量的问题根源。
数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号