数栈技术分享:OTS数据迁移——我们不生产数据,我们是大数据的搬运工
数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx
「表格存储」是 NoSQL 的数据存储服务,是基于云计算技术构建的一个分布式结构化和半结构化数据的存储和管理服务。
表格存储的数据模型以「二维表」为中心。
表有行和列的概念,但是与传统数据库不一样,表格存储的表是稀疏的

每一行可以有不同的列,可以动态增加或者减少属性列,建表时不需要为表的属性列定义严格的 schema。
一、概述
OTS的数据迁移可以使用「DataX」完成全量数据迁移。但由于部分数据表的数据量较大,无法在指定的时间窗口内完成全量迁移,且目前DataX只能针对主键值进行范围查询,暂不支持按照属性列范围抽取数据。
所以可以按如下两种方式实现全量+增量的数据迁移:
- 分区键包含范围信息(如时间信息、自增ID),则以指定range为切分点,分批次迁移。
- 分区键不包含范围信息,则可以采用在应用侧双写的模式将数据分批次迁移,写入目标环境同一张业务表。利用OTS的主键唯一性,选择对重复数据执行覆盖原有行的策略来保证数据唯一性。
总而言之,言而总之,我们不生产数据,此刻,我们是大数据的搬运工。
接下来呢,本文就以应用侧调整为双写模式为例,详细说明OTS数据迁移、校验过程。
其中OTS数据迁移流程具体如下图所示:
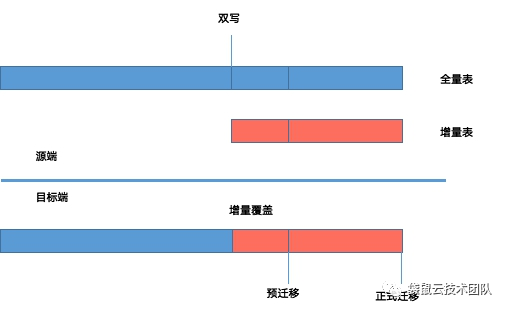
OTS数据迁移之准备工作
- 预迁移阶段:双写模式中的大表全量迁移
- 正式迁移阶段:双写模式中的增量表全量迁移、其余小表的全量迁移

二、预迁移阶段
1、 准备工作
为保证新老环境的数据一致性,需要在开始数据迁移前,对目标环境的OTS数据表进行数据清空操作,Delete操作是通过DataX工具直接删除表内数据,无需重新建表。
具体操作如下:
1) 配置DataX任务
在使用DataX执行数据清空前,需配置对应数据表使用DataX执行Delete任务所需的json文件。在清空数据的配置中,reader与writer均配置目标端的连接信息,且数据写入模式配置DeleteRow即可,具体内容如下:
2 )执行datax任务
- 登录datax所在ECS后,进入datax所在路径
- 在对应的工具机分别执行del_pre.sh脚本,即可开始目标环境对应表的数据清空,具体命令如下:
- del_pre.sh脚本内容如下:
#!/bin/bash
nohup python datax.py del_table_1.json --jvm="-Xms16G -Xmx16G" > del_table_1.log &
2、 数据迁移
在不停服务的情况下把源环境内数据量较大的数据表全部迁移到目标环境内对应的数据表。
1)配置DataX任务
在DataX对数据表配置相应的json文件,迁移配置的具体内容如下:
需注意,由于OTS本身是NoSQL系统,在迁移数据的配置中,必须配置所有的属性列,否则会缺失对应属性列的值。
2) 执行datax任务
- 登录datax所在ECS后,进入datax所在路径
- 在对应的工具机分别执行pre_transfer.sh脚本,即可开始专有域OTS到专有云OTS的数据迁移,具体命令如下:
- pre_transfer.sh脚本内容如下:
呐,此时,万事俱备,数据只待迁移!

在迁移之前,让我们最后再对焦一下数据迁移的目标:

下面,进入正式迁移阶段!
三、正式迁移阶段
1、OTS数据静默
OTS的数据静默主要是通过观察对应表的数据是否存在变化来判断,校验方式主要包括行数统计、内容统计。
1)行数统计
因OTS本身不提供count接口,所以采用在hive创建OTS外部表的方式,读取OTS数据并计算对应数据表的行数,具体操作如下:
- 创建外部表
启动hive,创建上述数据表对应的外部表;为提高统计效率,外部表可以只读取OTS的主键列,建表语句示例如下:
- 进入脚本所在路径
登录Hadoop集群master所在ECS,进入hive所在目录 - 执行行数统计
执行pre_all_count.sh脚本,即可开始源环境内OTS对应表的行数统计
- pre_all_count.sh脚本内容如下:
连续执行两次行数统计,若两次统计结果一致则说明数据已经静默,数据写入以停止。
2)内容统计
由于部分数据表分区键对应的值比较单一,导致数据全部存储在同一个分区。若采用hive统计行数会耗时太久,所以对于这个表使用datax将OTS数据导入oss的方式进行内容统计,具体操作如下:
- 进入脚本所在路径
登录上述表格对应的ECS,进入datax所在路径; - 执行内容校验
a、执行check_table.sh脚本,即可将源环境内OTS数据表导出到OSS;
- check_table.sh脚本内容如下:
b、获取OSS object的ETAG值,写入对应文件table_check01.rs
连续执行两次内容统计,对比两次导出object的ETAG值,若结果一致则说明数据已经静默,数据写入以停止。
2、OTS数据迁移
1)准备工作
为保证迁移后新老环境数据一致,防止目标环境因测试产生遗留脏数据,在进行数据迁移前,需要将目标环境的OTS的其余全量表进行数据清空。

「数据清空方式」主要有Drop、Delete,两者的区别如下:
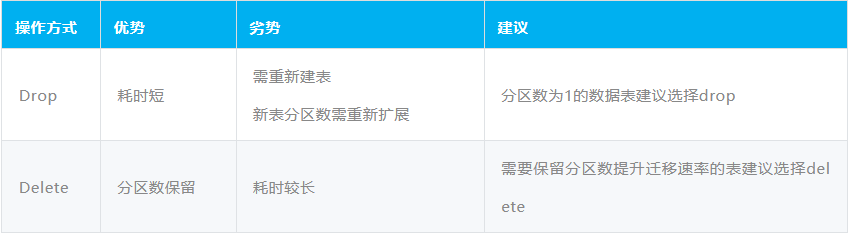
a、Drop表操作
登录OTS图形化客户端所在工具机,使用如下信息连接指定OTS实例,并进行对应表的drop操作;
确认删除后,再在客户端重新创建对应的数据。
b、 Delete表操作
Delete操作是通过DataX工具直接删除表内数据,无需重新建表。DataX所需的配置文件参考2.1.1所示。
- 登录datax所在ECS后,进入datax所在路径
- 在对应的工具机分别执行delete脚本,即可开始目标环境OTS的对应表的数据清空,具体命令如下:
- del_table_01.sh脚本内容如下:
2)数据迁移
在源环境停止服务的情况下把双写模式中的增量表全量迁移以及其余小表全部迁移到目标环境内对应的数据表。
具体操作如下:
a、配置DataX任务
在DataX对上述数据表配置相应的json文件,迁移配置的具体内容参考2.2.1,在迁移数据的配置中,需要列全所有的属性列。
b、执行DataX任务
- 登录DataX所在ECS后,进入DataX所在路径
- 在对应的工具机分别执行transfer.sh脚本,即可开始专有域OTS到专有云OTS的数据迁移,具体命令如下:
- transfer.sh脚本内容如下:

3、OTS数据校验
新老环境OTS的数据校验方式均包括行数统计、内容统计,具体如下:
1)源环境数据统计
源环境OTS数据表的数据量统计依据数据静默期间最后一次的统计结果即可。
2)目标环境数据统计
a、行数统计
因OTS本身不提供count接口,且目标环境ODPS支持创建OTS外部表,所以采用在ODPS创建OTS外部表的方式,读取OTS数据并计算对应数据表的行数,具体操作如下:
- 创建外部表
登录odpscmd,创建上述数据表对应的外部表; - 进入脚本所在路径
登录odpscmd工具所在ECS,进入odps所在路径; - 执行行数统计
执行newots_count.sh脚本,即可进行目标环境内OTS对应表的行数统计;
- newots_count.sh脚本内容如下:
由于源环境的部分数据表采用内容统计的方式进行数据校验,为了方便对比数据是否一致,所以目标环境也采用内容统计的方式,具体操作参考3.1.2。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号