数据结构及算法基础--归并排序(Merge Sort)
在《algorithm》中,作者单独讲mergesort作为一个小节,可以看出它的重要程度。
首先来看一下归并排序的运用场景是怎样的:将两个已排序列进行排列。
主要的思想便是:比较a[i]和b[j]的大小,若a[i]≤b[j],则将第一个有序表中的元素a[i]复制到r[k]中,并令i和k分别加上1;否则将第二个有序表中的元素b[j]复制到r[k]中,并令j和k分别加上1,如此循环下去,直到其中一个有序表取完,然后再将另一个有序表中剩余的元素复制到r中从下标k到下标t的单元。
这样说太空洞了,我们给出图:

我们实际上是copy了原序列,所以在merge sort,其实是牺牲了空间复杂度来达到时间复杂度的提高。
我们先来看一下整个归并排序最基础的方法:merge:
private static void merge(Comparable[] a,int lo,int mid,int hi){ int i=lo,j=mid+1; aux=new Comparable[a.length]; for(int k=lo;k<a.length;k++){ aux[k]=a[k]; } for(int k=lo;k<=hi;k++){ if(i>mid)a[k]=aux[j++]; else if(j>hi)a[k]=aux[i++]; else if(less(aux[j],aux[i]))a[k]=a[j++]; else a[k]=aux[i++]; } }
这就是简单的将两个已排序列进行归并排序的算法。
但是实际上,我们在运用中是很难有这种巧合的情况的,我们需要处理的仍然是大量的无序序列。这个时候我们有两种方法来完成无序序列的merge sort,一种为Top-down Merge Sort,一种为Button-up Merge Sort;
我们先来说明一下
Top-down Merge Sort:
首先,我不知道怎么翻译这个归并算法的名字,所以我一直用的都是英文,采用的是递归的思想来实现排序的。递归就不需要我多讲解了,这是一个非常好用的办法,但是需要注意的是,一定要在方法或者函数中设置递归的出口判断语句,不然会有异常抛出。Top-down Merge Srot的主要流程如下:

这个图可以很清晰的放映出递归的思想。
我们接下来实现这个排序方法:
private static void TopDownMergeSort(Comparable[] a){ TopDownMergeSort(a,0,a.length-1); } private static void TopDownMergeSort(Comparable[] a,int lo,int hi){ if(hi<=lo)return; int mid=(lo+hi)/2; TopDownMergeSort(a,lo,mid); TopDownMergeSort(a,mid+1,hi); merge(a,lo,mid,hi); }
这个程序完成的流程便是下图:

很简单对吧!
top-down merge sort算法分析
1)算法复杂度
我们通过程序其实可以看见,归并算法没有运用到交换方法(exch)!所以我们这里只考虑比较次数就可以了。
这里给出定理1:
Top-down Merge Sort使用了1/2n*lgn-n*lgn次数的比较。
算法书中也给出了证明,但是书中的证明方法只证明了为什么最多是n*log(n)次比较。这里我给出另外的一个证明,虽然要low很多,但是还是能够清楚的证明这个定理:
归并的基本思想是合并多路有序数组,通常我们考虑两路归并算法。
归并排序是稳定的,这是因为,在进行多路归并时,如果各个序列当前元素均相等,可以令排在前面的子序列的元素先处理,不会打乱相等元素的顺序。
考虑元素比较次数,两个长度分别为m和n的有序数组,每次比较处理一个元素,因而合并的最多比较次数为(m+n-1),最少比较次数为min(m,n)。对于两路归并,序列都是两两合并的。不妨假设元素个数为n=2^h,
第一次归并:合并两个长度为1的数组,总共有n/2个合并,比较次数为n/2。
第二次归并:合并两个长度为2的数组,最少比较次数是2,最多是3,总共有n/4次,比较次数是(2~3)n/4。
第三次归并:合并两个长度为4的数组,最少比较次数是4,最多是7,总共有n/8次合并,比较次数是(4-7)n/8。
第k次归并:合并两个长度为2^(k-1)的数组,最少比较次数是2^(k-1),最多是2^k-1,总共合并n/(2^k)次,比较次数是[2^(k-1)~(2^k-1)](n/2^k)=n/2~n(1-1/2^k)。
按照这样的思路,可以估算比较次数下界为n/2*h=nlg(n)/2。上界为n[h-(1/2+1/4+1/8+...+1/2^h)]=n[h-(1-1/2^h)]=nlog2(n)-n+1。
综上所述,归并排序比较次数为nlgn-n+1~nlog2(n)/2。
归并排序引入了一个与初始序列长度相同的数组来存储合并后的结果,因而不涉及交换。
!至于稳重的最少比较次数的得来,如果当一侧的元素全部小于另一边最小元素或者大于另一边最大元素的时候,这个时候得到的比较次数便是最少的。因为在遍历完该侧的元素,另外一边的元素不需要进行比较直接录入序列则好。!
当然,书中的证明是非常棒的,知识没有这么简单明了:


定理2:
Top-down Merge Sort 最多接触了6n*log(n)次数组(原谅我的语言表达,其实就是array access).
证明其实也很简单:

Button-up Merge Sort
在Top-down Merge Sort 中,我们使用的是递归,主要也就是从最开始的两个序列依次往下,直到序列长度为1的时候。那么一定会有对应的算法,从序列长度为1开始向上进行排序。我们直接给出 Button-up Merge Sort的代码,可以很清晰的明白这个区别:
private static void ButtonUpMergeSort(Comparable[] a){ int N=a.length; aux=new Comparable[N]; for(int sz=0;sz<N;sz=sz+sz){ for(int lo=0;lo<N-sz;lo=sz+sz){ merge(a,lo,lo+sz-1,Math.min(lo+sz+sz-1, N-1)); } } }
Button-up Merge Sort算饭分析
1)算法复杂度:
Button-up Merge Sort的算法复杂度和 Top-down Merge Sort的算法复杂度是一样的。使用的比较次数和array access次数也是一样的。具体的证明可以和Top-down Merge Sort的证明进行参考。
比较:
这两种实现merge sort的算法其实除了运行过程不一样,其他的都是很类似的,其基础都是merge sort。具体的运行区别可以用下图很明确的就展示出来:
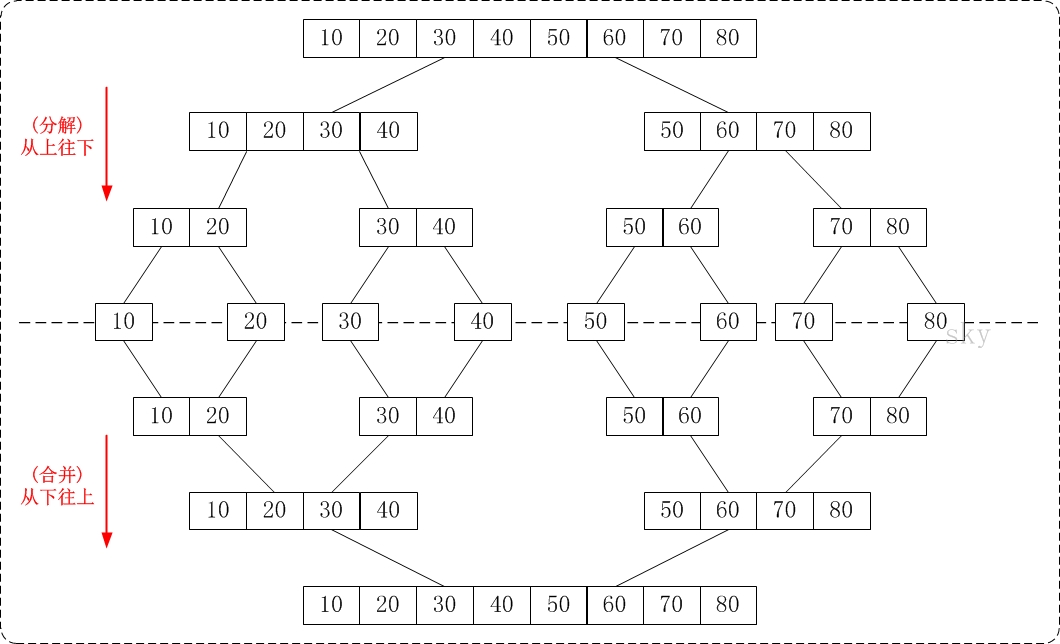
两者总体来说:
1)有一样的比较次数:1/2nlgn~nlgn;
2)一样的赋值操作:2n*lgn;(至于这一步怎么证明的,有兴趣的朋友可以自己通过程序算一下,其实很简单的)
3)一样的array access操作:6nlgn
Merge Sort算法总体分析
1)算法复杂度:算法复杂度其实通过上面的比较次数分析也已经得到了,为O(nlogn);
2) 稳定性:Merge sort是稳定的
3)辅助空间:其实就是空间复杂度,我们可以通过代码得到,mergesort是要新建数组的,我们创建了一个aux数组(注意:不是在每个递归里面都创建了一个,而是我们至始至终只创建了一个aux数组!只是每个迭代内部都对aux进行了复制操作),所以很轻易,我们的空间复杂度(主要是辅助空间)就是O(n);
这里有个非常重要的定理:
任何基于比较的排序算法都不能“保证”对一个N个元素的序列排序的比较次数小于lg(N!)~nlg(n);
这个证明起来就非常的费劲了,我还是将书中的证明过程给出来,相信会基于一些同学一定的帮助:


改进方法:
因为大部分时候我们运用的都是Top-down Merge Sort(虽然 Button-up Merge Sort的代码更简洁,但是易读性完全不如Top-down Merge Sort),所以在改进的时候,我们主要针对Top-down Merge Sort
1)使用插入排序(insertion sort)对很小的子序列:
这个很容易理解,我们减少递归的层数,而使用插入排序在较小的子序列进行排序会提高10%-15%的效率。注意了,这里很多人都在想,归并算法复杂度不是平均比比插入算法复杂度好么?为什么还要使用插入算法,即便在子序列中,感觉也是归并排序更好。这里的原理很深了,并不是这么简单的。这里有篇文章针对这个问题进行了讲解,我们可以看到,这个分析和单独比较插入排序和归并排序是完全不同的,虽然我也还有不太懂的地方,但是不能仅仅提出者两个排序进行单独讨论。文章地址:http://blog.csdn.net/wu_yihao/article/details/8038998
该文章的重点过程如下:
(0) 对每个列表排序的最坏时间是Θ(k2),则n/k个列表需要Θ(nk)的渐进时间。
(1) 合并这些列表需要Θ(nlog(n/k))的时间:最初合并n/k个规模为k的列表需要 cn/k * k = Θ(n),再利用数学归纳法可证每次合并都需要Θ(n),并且需要log(n/k)次合并。或者也可以通过递归树尽心分析。
(2) 总时间为Θ(nk+nlog(n/k)),我们可以利用这个总渐进时间,导出k取值的界
由反证法可以得到,k的阶取值不能大于Θ(logn),并且这个界可以保证插排优化的渐进时间不会慢于原始归并排序。
由于对数函数的增长特点,结合实际排序规模,k得实际取值一般在10~20间。
看不懂也没关系!我们记住,在《algorithm》书中将k的值定位15,并且有效的提高了Top-down Merge Sort的运行时间和效率。
2)判断是否这个array已经排序成功:
当我们判断出a[mid]小于a[mid+1]的时候,如果我们跳过merge()方法,那么,我们对已排序列的运行时间就会降低为线性。这已经是很大的提升了,虽然不是对整体的运行时间进行提高。
3)降低复制到aux数组的次数:
这个就有一点tricky的感觉。我们通过代码可以看到每一次递归,我们都要将数组a复制到aux里面去,但是我们可以将a的功能和aux的功能不断转换,来降低复制带来的时间冗长,很好理解的,我们在比较并复制时,我们第一层递归是将a作为输出,那么下一层,我们可以将aux作为输出。而不是一直将a作为输出,aux作为复制来进行。大大减少了复制带来的运行时间。
三点改进在书中具体的描述为下:

以上就是merge sort的全部内容,有些内容已近远超我们需要掌握的内容,但是我相信了解它们没有坏处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号