Go语言设计与实现
Go 语言设计与实现
2.1 编译过程
2.1.1 预备知识
抽象语法树
抽象语法树(Abstract Syntax Tree、AST),是源代码语法的结构的一种抽象表示,它用树状的方式表示编程语言的语法结构1。
指令集
x86 是目前比较常见的指令集,除了 x86 之外,还有 arm 等指令集,不同的处理器使用了不同的架构和机器语言,所以很多编程语言为了在不同的机器上运行需要将源代码根据架构翻译成不同的机器代码。
https://blog.csdn.net/chengqiuming/article/details/118784418
2.1.2 编译原理
词法与语法分析
所有的编译过程其实都是从解析代码的源文件开始的,词法分析的作用就是解析源代码文件,它将文件中的字符串序列转换成 Token 序列,方便后面的处理和解析,我们一般会把执行词法分析的程序称为词法解析器(lexer)。Token 到抽象语法树(AST)的转换过程会用到语法解析器,每一个 AST 都对应着一个单独的 Go 语言文件,这个抽象语法树中包括当前文件属于的包名、定义的常量、结构体和函数等。
类型检查
中间代码生成
机器码生成
Go 语言源代码的 src/cmd/compile/internal 目录中包含了很多机器码生成相关的包,不同类型的 CPU 分别使用了不同的包生成机器码,其中包括 amd64、arm、arm64、mips、mips64、ppc64、s390x、x86 和 wasm,其中比较有趣的就是 WebAssembly(Wasm)了。
2.1.3 编译器入口
2.2 词法分析和语法分析
2.2.1 词法分析
2.2.2 语法分析
语法分析是根据某种特定的形式文法(Grammar)对 Token 序列构成的输入文本进行分析并确定其语法结构的过程9。从上面的定义来看,词法分析器输出的结果 — Token 序列是语法分析器的输入。
文法 #
上下文无关文法是用来形式化、精确描述某种编程语言的工具,我们能够通过文法定义一种语言的语法,它主要包含一系列用于转换字符串的生产规则(Production rule)10。上下文无关文法中的每一个生产规则都会将规则左侧的非终结符转换成右侧的字符串,文法都由以下的四个部分组成:
终结符是文法中无法再被展开的符号,而非终结符与之相反,还可以通过生产规则进行展开,例如 “id”、“123” 等标识或者字面量11。
- NN 有限个非终结符的集合;
- ΣΣ 有限个终结符的集合;
- PP 有限个生产规则12的集合;
- SS 非终结符集合中唯一的开始符号;
文法被定义成一个四元组 (N,Σ,P,S)(N,Σ,P,S),这个元组中的几部分是上面提到的四个符号,其中最为重要的就是生产规则,每个生产规则都会包含非终结符、终结符或者开始符号,我们在这里可以举个简单的例子:
- S→aSbS→aSb
- S→abS→ab
- S→ϵS→ϵ
上述规则构成的文法就能够表示 ab、aabb 以及 aaa..bbb 等字符串,编程语言的文法就是由这一系列的生产规则表示的。
分析方法
语法分析的分析方法一般分为自顶向下和自底向上两种,这两种方式会使用不同的方式对输入的 Token 序列进行推导:
- 自顶向下分析:可以被看作找到当前输入流最左推导的过程,对于任意一个输入流,根据当前的输入符号,确定一个生产规则,使用生产规则右侧的符号替代相应的非终结符向下推导15;
- 自底向上分析:语法分析器从输入流开始,每次都尝试重写最右侧的多个符号,这其实是说解析器会从最简单的符号进行推导,在解析的最后合并成开始符号16;
Go 语言的解析器使用了 LALR(1) 的文法来解析词法分析过程中输出的 Token 序列,最右推导加向前查看构成了 Go 语言解析器的最基本原理,也是大多数编程语言的选择。将编程语言的所有生产规则映射到对应的方法上,这些方法构成的树形结构最终会返回一个抽象语法树。
节点
语法分析器最终会使用不同的结构体来构建抽象语法树中的节点
2.3 类型检查
我们在上一节中介绍了 Go 语言编译的第一个阶段 — 通过词法和语法分析器的解析得到了抽象语法树,本节会继续介绍编译器执行的下一个阶段 — 类型检查。
Go 语言的编译器不仅使用静态类型检查来保证程序运行的类型安全,还会在编程期间引入类型信息,让工程师能够使用反射来判断参数和变量的类型。当我们想要将 interface{} 转换成具体类型时会进行动态类型检查,如果无法发生转换就会发生程序崩溃。
2.4 中间代码生成
2.4.1 概述
中间代码是编译器或者虚拟机使用的语言,它可以来帮助我们分析计算机程序。在编译过程中,编译器会在将源代码转换到机器码的过程中,先把源代码转换成一种中间的表示形式,即中间代码1。编译器会将 Go 语言关键字转换成运行时包中的函数,也就是说关键字和内置函数的功能是由编译器和运行时共同完成的。
中间代码的生成过程是从 AST 抽象语法树到 SSA 中间代码的转换过程,在这期间会对语法树中的关键字再进行改写,改写后的语法树会经过多轮处理转变成最后的 SSA 中间代码,相关代码中包括了大量 switch 语句、复杂的函数和调用栈,阅读和分析起来也非常困难。很多 Go 语言中的关键字和内置函数都是在这个阶段被转换成运行时包中方法的,
2.5 机器码生成
机器码的生成过程其实是对 SSA 中间代码的降级(lower)过程,在 SSA 中间代码降级的过程中,编译器将一些值重写成了目标 CPU 架构的特定值,降级的过程处理了所有机器特定的重写规则并对代码进行了一定程度的优化,汇编器对由中间代码生成的汇编代码进行适配不同CPU架构的汇编后生成最终可以在这个CPU架构上直接运行的二进制机器码。
3.1 数组
3.1.1 概述
Go 语言数组在初始化之后大小就无法改变,存储元素类型相同、但是大小不同的数组类型在 Go 语言看来也是完全不同的,只有两个条件都相同才是同一类型。数组是 Go 语言中重要的数据结构,了解它的实现能够帮助我们更好地理解这门语言,通过对其实现的分析,我们知道了对数组的访问和赋值需要同时依赖编译器和运行时,它的大多数操作在编译期间都会转换成直接读写内存,在中间代码生成期间,编译器还会插入运行时方法 runtime.panicIndex 调用防止发生越界错误。
3.2 切片
切片,即动态数组,其长度并不固定,我们可以向切片中追加元素,它会在容量不足时自动扩容。
3.2.1 数据结构
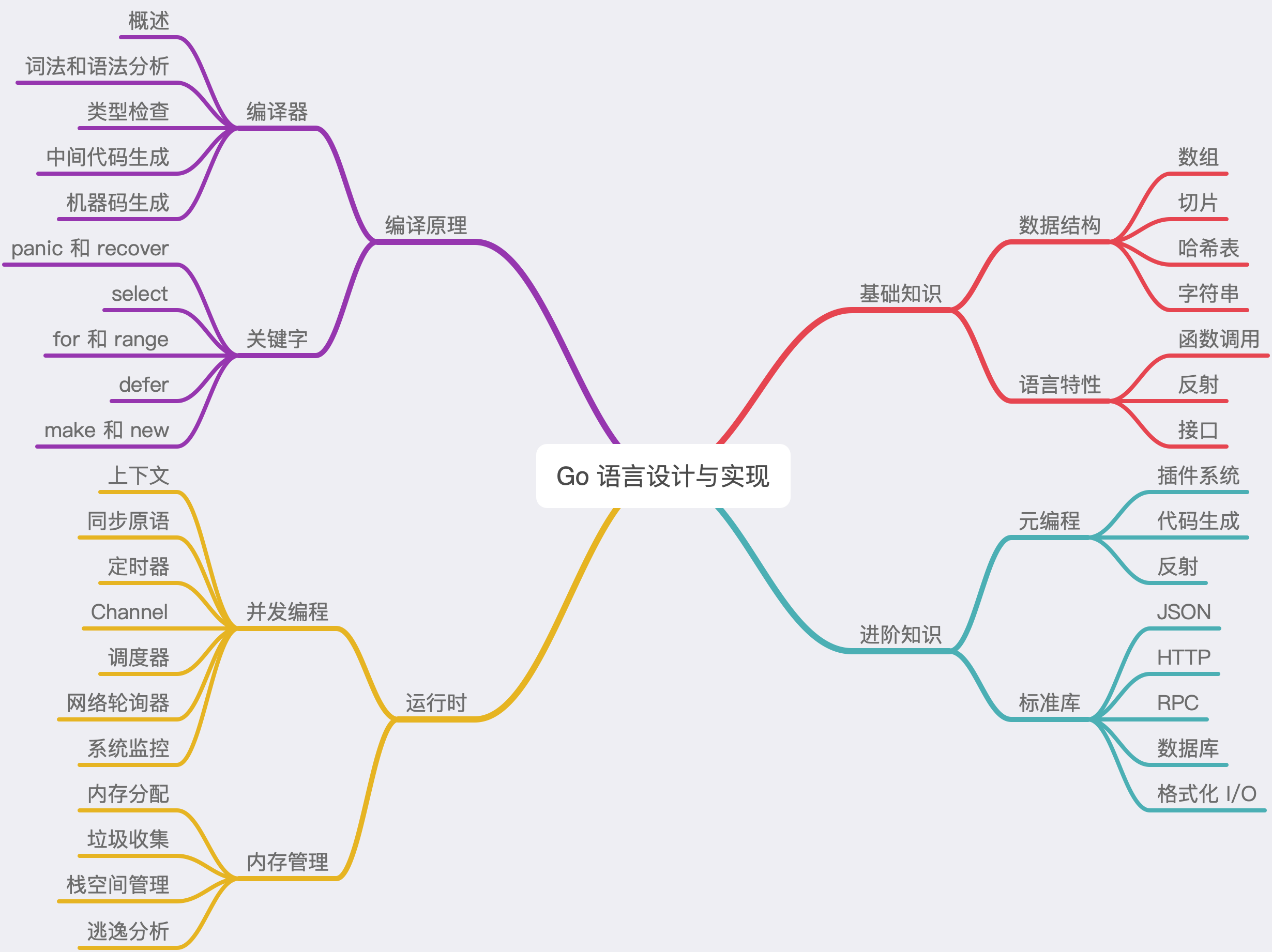
运行时切片可以由如下的 reflect.SliceHeader 结构体表示,其中:
Data是指向数组的指针;Len是当前切片的长度;Cap是当前切片的容量,即Data数组的大小:
Data 是一片连续的内存空间,这片内存空间可以用于存储切片中的全部元素,数组中的元素只是逻辑上的概念,底层存储其实都是连续的,所以我们可以将切片理解成一片连续的内存空间加上长度与容量的标识。当切片底层的数组长度不足时就会触发扩容,切片指向的数组可能会发生变化,不过在上层看来切片是没有变化的,上层只需要与切片打交道不需要关心数组的变化。
当一个对象的指针被多个方法或线程引用时,我们称这个指针发生了逃逸。
更简单来说,逃逸分析决定一个变量是分配在堆上还是分配在栈上。
runtime.makeslice 在最后调用的 runtime.mallocgc 是用于申请内存的函数,这个函数的实现还是比较复杂,如果遇到了比较小的对象会直接初始化在 Go 语言调度器里面的 P 结构中,而大于 32KB 的对象会在堆上初始化
3.2.3 访问元素
切片的操作基本都是在编译期间完成的,访问切片中的字段可能会触发 “decompose builtin” 阶段的优化,len(slice) 或者 cap(slice) 在一些情况下会直接替换成切片的长度或者容量,不需要在运行时获取,访问切片中元素使用的 OINDEX 操作也会在中间代码生成期间转换成对地址的直接访问,编译期间也会将包含 range 关键字的遍历转换成形式更简单的循环。
3.2.4 追加和扩容
append 在不超过容量时会在原先的地址空间上去追加内容,新生成的变量如果不覆盖原来的变量的话,他们会使用同一块内存空间,会相互影响。如果要覆盖的话就是修改原变量的len和数组地址里的内容。
append 如果超过容量时,新生成的变量如果不覆盖原来的内容的话就会使用两个不一样的内存空间,互相不影响。如果覆盖的话相当于把之前的数组指针指向新的地址空间,len和cap值改了,数组地址里的值也对应修改。
当切片的容量不足时,我们会调用 runtime.growslice 函数为切片扩容,扩容是为切片分配新的内存空间并拷贝原切片中元素的过程
在分配内存空间之前需要先确定新的切片容量,运行时根据切片的当前容量选择不同的策略进行扩容:
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果当前切片的长度小于 1024 就会将容量翻倍;
- 如果当前切片的长度大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;
runtime.roundupsize 函数会将待申请的内存向上取整,取整时会使用 runtime.class_to_size 数组,使用该数组中的整数可以提高内存的分配效率并减少碎片。(2的幂次)我们会将目标容量和元素大小相乘得到占用的内存。如果计算新容量时发生了内存溢出或者请求内存超过上限,就会直接崩溃退出程序。
3.3 哈希表
3.3.1 设计原理
哈希函数
如果使用结果分布较为均匀的哈希函数,那么哈希的增删改查的时间复杂度为 O(1)O(1);但是如果哈希函数的结果分布不均匀,那么所有操作的时间复杂度可能会达到 O(n)O(n),由此看来,使用好的哈希函数是至关重要的。
冲突解决
开放寻址法 #
开放寻址法2是一种在哈希表中解决哈希碰撞的方法,这种方法的核心思想是依次探测和比较数组中的元素以判断目标键值对是否存在于哈希表中,如果我们使用开放寻址法来实现哈希表,那么实现哈希表底层的数据结构就是数组,不过因为数组的长度有限,向哈希表写入 (author, draven) 这个键值对时会从如下的索引开始遍历:
当我们向当前哈希表写入新的数据时,如果发生了冲突,就会将键值对写入到下一个索引不为空的位置
拉链法 #
与开放地址法相比,拉链法是哈希表最常见的实现方法,大多数的编程语言都用拉链法实现哈希表,它的实现比较开放地址法稍微复杂一些,但是平均查找的长度也比较短,各个用于存储节点的内存都是动态申请的,可以节省比较多的存储空间。地址冲突时,直接在当前位置拉一个链表存储数据。
3.3.2 数据结构
Go 语言运行时同时使用了多个数据结构组合表示哈希表,其中 runtime.hmap 是最核心的结构体,我们先来了解一下该结构体的内部字段:
count表示当前哈希表中的元素数量;B表示当前哈希表持有的buckets数量,但是因为哈希表中桶的数量都 2 的倍数,所以该字段会存储对数,也就是len(buckets) == 2^B;hash0是哈希的种子,它能为哈希函数的结果引入随机性,这个值在创建哈希表时确定,并在调用哈希函数时作为参数传入;oldbuckets是哈希在扩容时用于保存之前buckets的字段,它的大小是当前buckets的一半;

Go 语言使用拉链法来解决哈希碰撞的问题实现了哈希表,它的访问、写入和删除等操作都在编译期间转换成了运行时的函数或者方法。哈希在每一个桶中存储键对应哈希的前 8 位,当对哈希进行操作时,这些 tophash 就成为可以帮助哈希快速遍历桶中元素的缓存。
哈希表的每个桶都只能存储 8 个键值对,一旦当前哈希的某个桶超出 8 个,新的键值对就会存储到哈希的溢出桶中。随着键值对数量的增加,溢出桶的数量和哈希的装载因子也会逐渐升高,超过一定范围就会触发扩容,扩容会将桶的数量翻倍,元素再分配的过程也是在调用写操作时增量进行的,不会造成性能的瞬时巨大抖动。
3.4 字符串
字符串是由字符组成的数组,C 语言中的字符串使用字符数组 char[] 表示。数组会占用一片连续的内存空间,而内存空间存储的字节共同组成了字符串,Go 语言中的字符串只是一个只读的字节数组,下图展示了 "hello" 字符串在内存中的存储方式:

字符串和 []byte 中的内容虽然一样,但是字符串的内容是只读的,我们不能通过下标或者其他形式改变其中的数据,而 []byte 中的内容是可以读写的。不过无论从哪种类型转换到另一种都需要拷贝数据,而内存拷贝的性能损耗会随着字符串和 []byte 长度的增长而增长。
4.1 函数调用
4.1.2 参数传递
Go 语言选择了传值的方式,无论是传递基本类型、结构体还是指针,都会对传递的参数进行拷贝。将指针作为参数传入某个函数时,函数内部会复制指针,也就是会同时出现两个指针指向原有的内存空间,所以 Go 语言中传指针也是传值。在传递数组或者内存占用非常大的结构体时,我们应该尽量使用指针作为参数类型来避免发生数据拷贝进而影响性能。
这一节我们详细分析了 Go 语言的调用惯例,包括传递参数和返回值的过程和原理。Go 通过栈传递函数的参数和返回值,在调用函数之前会在栈上为返回值分配合适的内存空间,随后将入参从右到左按顺序压栈并拷贝参数,返回值会被存储到调用方预留好的栈空间上,我们可以简单总结出以下几条规则:
- 通过堆栈传递参数,入栈的顺序是从右到左,而参数的计算是从左到右;
- 函数返回值通过堆栈传递并由调用者预先分配内存空间;
- 调用函数时都是传值,接收方会对入参进行复制再计算;
Go语言这四种类型传参在不发生扩容时拷贝出来的对象还是指向同一片内存空间,interface、slice、map、chan
4.2 接口
4.2.1 概述
Go 语言中的接口是一种内置的类型,它定义了一组方法的签名。首先,我们简单了解一下在 Go 语言中如何定义接口。定义接口需要使用 interface 关键字,在接口中我们只能定义方法签名,不能包含成员变量。在 Go 中:实现接口的所有方法就隐式地实现了接口;Go 语言只会在传递参数、返回参数以及变量赋值时才会对某个类型是否实现接口进行检查。
类型
Go 语言中有两种略微不同的接口,一种是带有一组方法的接口,另一种是不带任何方法的 interface{}。
Go 语言使用 runtime.iface 表示第一种接口,使用 runtime.eface 表示第二种不包含任何方法的接口 interface{},两种接口虽然都使用 interface 声明,但是由于后者在 Go 语言中很常见,所以在实现时使用了特殊的类型。
需要注意的是,与 C 语言中的 void * 不同,interface{} 类型不是任意类型。如果我们将类型转换成了 interface{} 类型,变量在运行期间的类型也会发生变化,获取变量类型时会得到 interface{}。
指针和接口
现接口的类型和初始化返回的类型两个维度共组成了四种情况,然而这四种情况不是都能通过编译器的检查:
| 结构体实现接口 | 结构体指针实现接口 | |
|---|---|---|
| 结构体初始化变量 | 通过 | 不通过 |
| 结构体指针初始化变量 | 通过 | 通过 |
作为指针的变量能够隐式地获取到指向的结构体,所以能在结构体上调用方法。我们可以将这里的调用理解成 C 语言中的 d->Walk() 和 d->Speak(),它们都会先获取指向的结构体再执行对应的方法。
当我们使用指针实现接口时,只有指针类型的变量才会实现该接口;当我们使用结构体实现接口时,指针类型和结构体类型都会实现该接口。
4.2.2 数据结构
Go 语言根据接口类型是否包含一组方法将接口类型分成了两类:
- 使用
runtime.iface结构体表示包含方法的接口 - 使用
runtime.eface结构体表示不包含任何方法的interface{}类型;
runtime.eface 结构体在 Go 语言中的定义是这样的:
由于 interface{} 类型不包含任何方法,所以它的结构也相对来说比较简单,只包含指向底层数据和类型的两个指针。从上述结构我们也能推断出 — Go 语言的任意类型都可以转换成 interface{}。
另一个用于表示接口的结构体是 runtime.iface,这个结构体中有指向原始数据的指针 data,不过更重要的是 runtime.itab 类型的 tab 字段。
接下来我们将详细分析 Go 语言接口中的这两个类型,即 runtime._type 和 runtime.itab。
Go 语言在 unsafe 包里其实还通过 unsafe.Pointer 提供了通用指针,通过这个通用指针以及 unsafe 包的其他几个功能又让使用者能够绕过 Go 语言的类型系统直接操作内存进行例如:指针类型转换,读写结构体私有成员这样操作。
itab 结构体
runtime.itab 结构体是接口类型的核心组成部分,每一个 runtime.itab 都占 32 字节,我们可以将其看成接口类型和具体类型的组合,它们分别用 inter 和 _type 两个字段表示:
除了 inter 和 _type 两个用于表示类型的字段之外,上述结构体中的另外两个字段也有自己的作用:
hash是对_type.hash的拷贝,当我们想将interface类型转换成具体类型时,可以使用该字段快速判断目标类型和具体类型runtime._type是否一致;fun是一个动态大小的数组,它是一个用于动态派发的虚函数表,存储了一组函数指针。虽然该变量被声明成大小固定的数组,但是在使用时会通过原始指针获取其中的数据,所以fun数组中保存的元素数量是不确定的;
我们会在类型断言中介绍 hash 字段的使用,在动态派发一节中介绍 fun 数组中存储的函数指针是如何被使用的。
4.2.5 动态派发
从上述表格我们可以看到使用结构体实现接口带来的开销会大于使用指针实现,而动态派发在结构体上的表现非常差,这也提醒我们应当尽量避免使用结构体类型实现接口。
使用结构体带来的巨大性能差异不只是接口带来的问题,带来性能问题主要因为 Go 语言在函数调用时是传值的,动态派发的过程只是放大了参数拷贝带来的影响。
4.3 反射
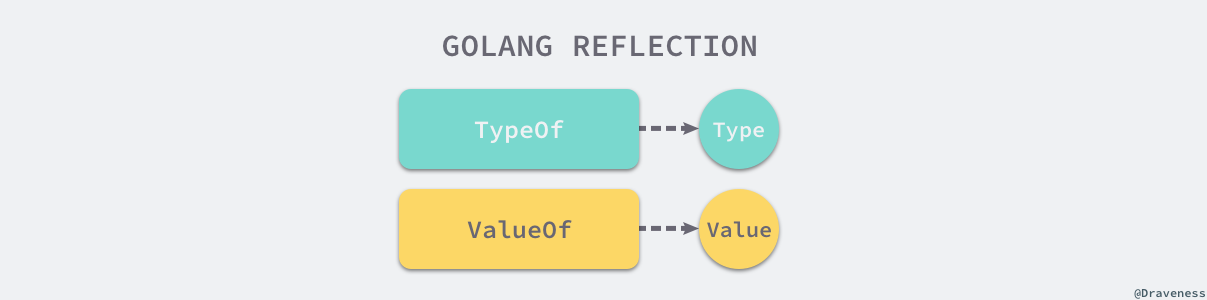
reflect 实现了运行时的反射能力,能够让程序操作不同类型的对象1。反射包中有两对非常重要的函数和类型,两个函数分别是:
reflect.TypeOf能获取类型信息;reflect.ValueOf能获取数据的运行时表示;
两个类型是 reflect.Type 和 reflect.Value,它们与函数是一一对应的关系:
类型 reflect.Type 是反射包定义的一个接口,我们可以使用 reflect.TypeOf 函数获取任意变量的类型,reflect.Type 接口中定义了一些有趣的方法,MethodByName 可以获取当前类型对应方法的引用、Implements 可以判断当前类型是否实现了某个接口:
反射包中 reflect.Value 的类型与 reflect.Type 不同,它被声明成了结构体。这个结构体没有对外暴露的字段,但是提供了获取或者写入数据的方法:
反射包中的所有方法基本都是围绕着 reflect.Type 和 reflect.Value 两个类型设计的。我们通过 reflect.TypeOf、reflect.ValueOf 可以将一个普通的变量转换成反射包中提供的 reflect.Type 和 reflect.Value,随后就可以使用反射包中的方法对它们进行复杂的操作。
4.3.1 三大法则
运行时反射是程序在运行期间检查其自身结构的一种方式。反射带来的灵活性是一把双刃剑,反射作为一种元编程方式可以减少重复代码2,但是过量的使用反射会使我们的程序逻辑变得难以理解并且运行缓慢。我们在这一节中会介绍 Go 语言反射的三大法则3,其中包括:
- 从
interface{}变量可以反射出反射对象; - 从反射对象可以获取
interface{}变量; - 要修改反射对象,其值必须可设置;
第一法则
总而言之,使用 reflect.TypeOf 和 reflect.ValueOf 能够获取 Go 语言中的变量对应的反射对象。一旦获取了反射对象,我们就能得到跟当前类型相关数据和操作,并可以使用这些运行时获取的结构执行方法。
第二法则
反射的第二法则是我们可以从反射对象可以获取 interface{} 变量。既然能够将接口类型的变量转换成反射对象,那么一定需要其他方法将反射对象还原成接口类型的变量,reflect 中的 reflect.Value.Interface 就能完成这项工作
不过调用 reflect.Value.Interface 方法只能获得 interface{} 类型的变量,如果想要将其还原成最原始的状态还需要经过显式类型转换
从反射对象到接口值的过程是从接口值到反射对象的镜面过程,两个过程都需要经历两次转换:
- 从接口值到反射对象:
- 从基本类型到接口类型的类型转换;
- 从接口类型到反射对象的转换;
- 从反射对象到接口值:
- 反射对象转换成接口类型;
- 通过显式类型转换变成原始类型;
第三法则
Go 语言反射的最后一条法则是与值是否可以被更改有关,如果我们想要更新一个 reflect.Value,那么它持有的值一定是可以被更新的
Elem() 作用是解引用?
Go语言程序中对指针获取反射对象时,可以通过 reflect.Elem() 方法获取这个指针指向的元素类型。这个获取过程被称为取元素,等效于对指针类型变量做了一个*操作
4.3.2 类型和值
reflect.TypeOf 的实现原理其实并不复杂,它只是将一个 interface{} 变量转换成了内部的 reflect.emptyInterface 表示,然后从中获取相应的类型信息。
用于获取接口值 reflect.Value 的函数 reflect.ValueOf 实现也非常简单,在该函数中我们先调用了 reflect.escapes 保证当前值逃逸到堆上,然后通过 reflect.unpackEface 从接口中获取 reflect.Value 结构体:
4.3.3 更新变量
当我们想要更新 reflect.Value 时,就需要调用 reflect.Value.Set 更新反射对象,该方法会调用 reflect.flag.mustBeAssignable 和 reflect.flag.mustBeExported 分别检查当前反射对象是否是可以被设置的以及字段是否是对外公开的。在变量更新的过程中,reflect.Value.assignTo 返回的 reflect.Value 中的指针会覆盖当前反射对象中的指针实现变量的更新。
4.3.4 实现协议
reflect 包还为我们提供了 reflect.rtype.Implements 方法可以用于判断某些类型是否遵循特定的接口。在 Go 语言中获取结构体的反射类型 reflect.Type 还是比较容易的,但是想要获得接口类型需要通过以下方式:
4.3.5 方法调用
4.3.6 小结
Go 语言的 reflect 包为我们提供了多种能力,包括如何使用反射来动态修改变量、判断类型是否实现了某些接口以及动态调用方法等功能
5.1 for 和 range
for range mp 顺序不固定
对于所有的 range 循环,Go 语言都会在编译期将原切片或者数组赋值给一个新变量 ha,在赋值的过程中就发生了拷贝,而我们又通过 len 关键字预先获取了切片的长度,所以在循环中追加新的元素也不会改变循环执行的次数。
而遇到这种同时遍历索引和元素的 range 循环时,Go 语言会额外创建一个新的变量存储切片中的元素,循环中使用的这个变量会在每一次迭代被重新赋值而覆盖,赋值时也会触发拷贝。
5.2 select
C 语言的 select 系统调用可以同时监听多个文件描述符的可读或者可写的状态,Go 语言中的 select 也能够让 Goroutine 同时等待多个 Channel 可读或者可写,在多个文件或者 Channel状态改变之前,select 会一直阻塞当前线程或者 Goroutine。
select 是与 switch 相似的控制结构,与 switch 不同的是,select 中虽然也有多个 case,但是这些 case 中的表达式必须都是 Channel 的收发操作。当 select 中的 case 同时被触发时,会随机执行其中的一个。 5.2.1 现象
当我们在 Go 语言中使用 select 控制结构时,会遇到两个有趣的现象:
select能在 Channel 上进行非阻塞的收发操作;即执行defaultselect在遇到多个 Channel 同时响应时,会随机执行一种情况;
非阻塞的收发
随机执行
如果 case 都是同时满足执行条件的,如果我们按照顺序依次判断,那么后面的条件永远都会得不到执行,而随机的引入就是为了避免饥饿问题的发生。5.2.2 数据结构
select 在 Go 语言的源代码中不存在对应的结构体,但是我们使用 runtime.scase 结构体表示 select 控制结构中的 case:
因为非默认的 case 中都与 Channel 的发送和接收有关,所以 runtime.scase 结构体中也包含一个 runtime.hchan 类型的字段存储 case 中使用的 Channel。
5.2.3 实现原理
直接阻塞
select 语句select {}会直接阻塞当前 Goroutine,导致 Goroutine 进入无法被唤醒的永久休眠状态。单一管道
非阻塞操作
常见流程
在默认的情况下,编译器会使用如下的流程处理 select 语句:
- 将所有的
case转换成包含 Channel 以及类型等信息的runtime.scase结构体; - 调用运行时函数
runtime.selectgo从多个准备就绪的 Channel 中选择一个可执行的runtime.scase结构体; - 通过
for循环生成一组if语句,在语句中判断自己是不是被选中的case;
5.2.4 小结
我们简单总结一下 select 结构的执行过程与实现原理,首先在编译期间,Go 语言会对 select 语句进行优化,它会根据 select 中 case 的不同选择不同的优化路径:
- 空的
select语句会被转换成调用runtime.block直接挂起当前 Goroutine; - 如果
select语句中只包含一个case,编译器会将其转换成if ch == nil { block }; n;表达式;- 首先判断操作的 Channel 是不是空的;
- 然后执行
case结构中的内容;
- 如果
select语句中只包含两个case并且其中一个是default,那么会使用runtime.selectnbrecv和runtime.selectnbsend非阻塞地执行收发操作; - 在默认情况下会通过
runtime.selectgo获取执行case的索引,并通过多个if语句执行对应case中的代码;
在编译器已经对 select 语句进行优化之后,Go 语言会在运行时执行编译期间展开的 runtime.selectgo 函数,该函数会按照以下的流程执行:
- 随机生成一个遍历的轮询顺序
pollOrder并根据 Channel 地址生成锁定顺序lockOrder; - 根据
pollOrder遍历所有的case查看是否有可以立刻处理的 Channel;- 如果存在,直接获取
case对应的索引并返回; - 如果不存在,创建
runtime.sudog结构体,将当前 Goroutine 加入到所有相关 Channel 的收发队列,并调用runtime.gopark挂起当前 Goroutine 等待调度器的唤醒;
- 如果存在,直接获取
- 当调度器唤醒当前 Goroutine 时,会再次按照
lockOrder遍历所有的case,从中查找需要被处理的runtime.sudog对应的索引;
select 关键字是 Go 语言特有的控制结构,它的实现原理比较复杂,需要编译器和运行时函数的通力合作。
5.3 defer
defer 会在当前函数返回前执行传入的函数,它会经常被用于关闭文件描述符、关闭数据库连接以及解锁资源。
5.3.1 现象
defer关键字的调用时机以及多次调用defer时执行顺序是如何确定的;defer关键字使用传值的方式传递参数时会进行预计算,导致不符合预期的结果;
调用 defer 关键字会立刻拷贝函数中引用的外部参数,想要解决这个问题的方法非常简单,我们只需要向 defer 关键字传入匿名函数。
虽然调用 defer 关键字时也使用值传递,但是因为拷贝的是函数指针。
5.3.2 数据结构
在介绍 defer 函数的执行过程与实现原理之前,我们首先来了解一下 defer 关键字在 Go 语言源代码中对应的数据结构:
runtime._defer 结构体是延迟调用链表上的一个元素,所有的结构体都会通过 link 字段串联成链表。
defer 关键字的插入顺序是从后向前的,而 defer 关键字执行是从前向后的,这也是为什么后调用的 defer 会优先执行- 后调用的
defer函数会先执行:- 后调用的
defer函数会被追加到 Goroutine_defer链表的最前面; - 运行
runtime._defer时是从前到后依次执行;
- 后调用的
- 函数的参数会被预先计算;
- 调用
runtime.deferproc函数创建新的延迟调用时就会立刻拷贝函数的参数,函数的参数不会等到真正执行时计算;
- 调用
5.4 panic 和 recover
panic能够改变程序的控制流,调用panic后会立刻停止执行当前函数的剩余代码,并在当前 Goroutine 中递归执行所有调用方的defer,直到被recover,或者Goroutine整体崩溃;recover可以中止panic造成的程序崩溃。它是一个只能在defer中发挥作用的函数,在其他作用域中调用不会发挥作用;
5.4.1 现象
panic只会触发当前 Goroutine 的defer;recover只有在defer中调用才会生效;panic允许在defer中嵌套多次调用;
panic 也不会影响 defer 函数的正常执行,所以使用 defer 进行收尾工作一般来说都是安全的。 5.4.2 数据结构
panic 关键字在 Go 语言的源代码是由数据结构 runtime._panic 表示的。每当我们调用 panic 都会创建一个如下所示的数据结构存储相关信息:
argp是指向defer调用时参数的指针;arg是调用panic时传入的参数;link指向了更早调用的runtime._panic结构;recovered表示当前runtime._panic是否被recover恢复;aborted表示当前的panic是否被强行终止;
从数据结构中的 link 字段我们就可以推测出以下的结论:panic 函数可以被连续多次调用,它们之间通过 link 可以组成链表。
5.4.3 程序崩溃
这里先介绍分析 panic 函数是终止程序的实现原理。编译器会将关键字 panic 转换成 runtime.gopanic,该函数的执行过程包含以下几个步骤:
- 创建新的
runtime._panic并添加到所在 Goroutine 的_panic链表的最前面; - 在循环中不断从当前 Goroutine 的
_defer中链表获取runtime._defer并调用runtime.reflectcall运行延迟调用函数; - 调用
runtime.fatalpanic中止整个程序;
5.4.4 崩溃恢复
panic,那么该函数会直接返回 nil,这也是崩溃恢复在非 defer 中调用会失效的原因。在正常情况下,它会修改 runtime._panic 的 recovered 字段,runtime.gorecover 函数中并不包含恢复程序的逻辑,程序的恢复是由 runtime.gopanic 函数负责的:5.4.5 小结
分析程序的崩溃和恢复过程比较棘手,代码不是特别容易理解。我们在本节的最后还是简单总结一下程序崩溃和恢复的过程:
- 编译器会负责做转换关键字的工作;
- 将
panic和recover分别转换成runtime.gopanic和runtime.gorecover; - 将
defer转换成runtime.deferproc函数; - 在调用
defer的函数末尾调用runtime.deferreturn函数;
- 将
- 在运行过程中遇到
runtime.gopanic方法时,会从 Goroutine 的链表依次取出runtime._defer结构体并执行; - 如果调用延迟执行函数时遇到了
runtime.gorecover就会将_panic.recovered标记成 true 并返回panic的参数;- 在这次调用结束之后,
runtime.gopanic会从runtime._defer结构体中取出程序计数器pc和栈指针sp并调用runtime.recovery函数进行恢复程序; runtime.recovery会根据传入的pc和sp跳转回runtime.deferproc;- 编译器自动生成的代码会发现
runtime.deferproc的返回值不为 0,这时会跳回runtime.deferreturn并恢复到正常的执行流程;
- 在这次调用结束之后,
- 如果没有遇到
runtime.gorecover就会依次遍历所有的runtime._defer,并在最后调用runtime.fatalpanic中止程序、打印panic的参数并返回错误码 2;
分析的过程涉及了很多语言底层的知识,源代码阅读起来也比较晦涩,其中充斥着反常规的控制流程,通过程序计数器来回跳转,不过对于我们理解程序的执行流程还是很有帮助。
5.5 make 和 new
6.1 上下文 Context
上下文 context.Context Go 语言中用来设置截止日期、同步信号,传递请求相关值的结构体。上下文与 Goroutine 有比较密切的关系,是 Go 语言中独特的设计,在其他编程语言中我们很少见到类似的概念。
context.Context 是 Go 语言在 1.7 版本中引入标准库的接口1,该接口定义了四个需要实现的方法,其中包括:
Deadline— 返回context.Context被取消的时间,也就是完成工作的截止日期;Done— 返回一个 Channel,这个 Channel 会在当前工作完成或者上下文被取消后关闭,多次调用Done方法会返回同一个 Channel;Err— 返回context.Context结束的原因,它只会在Done方法对应的 Channel 关闭时返回非空的值;- 如果
context.Context被取消,会返回Canceled错误; - 如果
context.Context超时,会返回DeadlineExceeded错误;
- 如果
Value— 从context.Context中获取键对应的值,对于同一个上下文来说,多次调用Value并传入相同的Key会返回相同的结果,该方法可以用来传递请求特定的数据;
6.1.1 设计原理
在 Goroutine 构成的树形结构中对信号进行同步以减少计算资源的浪费是 context.Context 的最大作用。Go 服务的每一个请求都是通过单独的 Goroutine 处理的2,HTTP/RPC 请求的处理器会启动新的 Goroutine 访问数据库和其他服务。接受到一个新的请求就起一个新的 goroutine 。我们可能会创建多个 Goroutine 来处理一次请求,而 context.Context 的作用是在不同 Goroutine 之间同步请求特定数据、取消信号以及处理请求的截止日期。
ctx.Done() 管道中的消息,一旦接收到取消信号就立刻停止当前正在执行的工作。6.1.3 取消信号
context.WithCancel 函数能够从 context.Context 中衍生出一个新的子上下文并返回用于取消该上下文的函数。一旦我们执行返回的取消函数,当前上下文以及它的子上下文都会被取消,所有的 Goroutine 都会同步收到这一取消信号。 我们直接从 context.WithCancel 函数的实现来看它到底做了什么:
context.newCancelCtx将传入的上下文包装成私有结构体context.cancelCtx;context.propagateCancel会构建父子上下文之间的关联,当父上下文被取消时,子上下文也会被取消:
上述函数总共与父上下文相关的三种不同的情况:
- 当
parent.Done() == nil,也就是parent不会触发取消事件时,当前函数会直接返回; - 当
child的继承链包含可以取消的上下文时,会判断parent是否已经触发了取消信号;- 如果已经被取消,
child会立刻被取消; - 如果没有被取消,
child会被加入parent的children列表中,等待parent释放取消信号;
- 如果已经被取消,
- 当父上下文是开发者自定义的类型、实现了
context.Context接口并在Done()方法中返回了非空的管道时;- 运行一个新的 Goroutine 同时监听
parent.Done()和child.Done()两个 Channel; - 在
parent.Done()关闭时调用child.cancel取消子上下文;
- 运行一个新的 Goroutine 同时监听
context.propagateCancel 的作用是在 parent 和 child 之间同步取消和结束的信号,保证在 parent 被取消时,child 也会收到对应的信号,不会出现状态不一致的情况。
context.cancelCtx 实现的几个接口方法也没有太多值得分析的地方,该结构体最重要的方法是 context.cancelCtx.cancel,该方法会关闭上下文中的 Channel 并向所有的子上下文同步取消信号:
除了 context.WithCancel 之外,context 包中的另外两个函数 context.WithDeadline 和 context.WithTimeout 也都能创建可以被取消的计时器上下文 context.timerCtx:
context.WithDeadline 在创建 context.timerCtx 的过程中判断了父上下文的截止日期与当前日期,并通过 time.AfterFunc 创建定时器,当时间超过了截止日期后会调用 context.timerCtx.cancel 同步取消信号。
context.timerCtx 内部不仅通过嵌入 context.cancelCtx 结构体继承了相关的变量和方法,还通过持有的定时器 timer 和截止时间 deadline 实现了定时取消的功能:
context.timerCtx.cancel 方法不仅调用了 context.cancelCtx.cancel,还会停止持有的定时器减少不必要的资源浪费。
6.1.4 传值方法
context.valueCtx 中存储的键值对与 context.valueCtx.Value 方法中传入的参数不匹配,就会从父上下文中查找该键对应的值直到某个父上下文中返回 nil 或者查找到对应的值。6.1.5 小结
Go 语言中的 context.Context 的主要作用还是在多个 Goroutine 组成的树中同步取消信号以减少对资源的消耗和占用,虽然它也有传值的功能,但是这个功能我们还是很少用到。
在真正使用传值的功能时我们也应该非常谨慎,使用 context.Context 传递请求的所有参数一种非常差的设计,比较常见的使用场景是传递请求对应用户的认证令牌以及用于进行分布式追踪的请求 ID。
6.2 同步原语与锁
6.2.1 基本原语
Mutex
Go 语言的 sync.Mutex 由两个字段 state 和 sema 组成。其中 state 表示当前互斥锁的状态,而 sema 是用于控制锁状态的信号量。
上述两个加起来只占 8 字节空间的结构体表示了 Go 语言中的互斥锁。
小结
我们已经从多个方面分析了互斥锁 sync.Mutex 的实现原理,这里我们从加锁和解锁两个方面总结注意事项。
互斥锁的加锁过程比较复杂,它涉及自旋、信号量以及调度等概念:
- 如果互斥锁处于初始化状态,会通过置位
mutexLocked加锁; - 如果互斥锁处于
mutexLocked状态并且在普通模式下工作,会进入自旋,执行 30 次PAUSE指令消耗 CPU 时间等待锁的释放; - 如果当前 Goroutine 等待锁的时间超过了 1ms,互斥锁就会切换到饥饿模式;
- 互斥锁在正常情况下会通过
runtime.sync_runtime_SemacquireMutex将尝试获取锁的 Goroutine 切换至休眠状态,等待锁的持有者唤醒; - 如果当前 Goroutine 是互斥锁上的最后一个等待的协程或者等待的时间小于 1ms,那么它会将互斥锁切换回正常模式;
互斥锁的解锁过程与之相比就比较简单,其代码行数不多、逻辑清晰,也比较容易理解:
- 当互斥锁已经被解锁时,调用
sync.Mutex.Unlock会直接抛出异常; - 当互斥锁处于饥饿模式时,将锁的所有权交给队列中的下一个等待者,等待者会负责设置
mutexLocked标志位; - 当互斥锁处于普通模式时,如果没有 Goroutine 等待锁的释放或者已经有被唤醒的 Goroutine 获得了锁,会直接返回;在其他情况下会通过
sync.runtime_Semrelease唤醒对应的 Goroutine;
RWMutex
读写互斥锁 sync.RWMutex 是细粒度的互斥锁,它不限制资源的并发读,但是读写、写写操作无法并行执行。
| 读 | 写 | |
|---|---|---|
| 读 | Y | N |
| 写 | N | N |
结构体
sync.RWMutex 中总共包含以下 5 个字段:
w— 复用互斥锁提供的能力;writerSem和readerSem— 分别用于写等待读和读等待写:readerCount存储了当前正在执行的读操作数量;readerWait表示当写操作被阻塞时等待的读操作个数;
我们会依次分析获取写锁和读锁的实现原理,其中:
- 写操作使用
sync.RWMutex.Lock和sync.RWMutex.Unlock方法; - 读操作使用
sync.RWMutex.RLock和sync.RWMutex.RUnlock方法;
小结
虽然读写互斥锁 sync.RWMutex 提供的功能比较复杂,但是因为它建立在 sync.Mutex 上,所以实现会简单很多。我们总结一下读锁和写锁的关系:
- 调用
sync.RWMutex.Lock尝试获取写锁时;- 每次
sync.RWMutex.RUnlock都会将readerCount其减一,当它归零时该 Goroutine 会获得写锁; - 将
readerCount减少rwmutexMaxReaders个数以阻塞后续的读操作;
- 每次
- 调用
sync.RWMutex.Unlock释放写锁时,会先通知所有的读操作,然后才会释放持有的互斥锁;
读写互斥锁在互斥锁之上提供了额外的更细粒度的控制,能够在读操作远远多于写操作时提升性能。
WaitGroup
sync.WaitGroup 可以等待一组 Goroutine 的返回,一个比较常见的使用场景是批量发出 RPC 或者 HTTP 请求。我们可以通过 sync.WaitGroup 将原本顺序执行的代码在多个 Goroutine 中并发执行,加快程序处理的速度。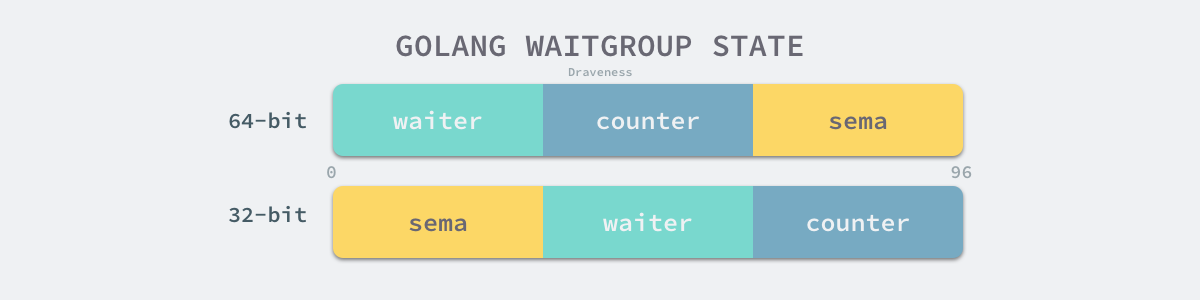
sync.noCopy 是一个特殊的私有结构体,tools/go/analysis/passes/copylock 包中的分析器会在编译期间检查被拷贝的变量中是否包含 sync.noCopy 或者实现了 Lock 和 Unlock 方法,如果包含该结构体或者实现了对应的方法就会报出以下错误接口
sync.WaitGroup.Add 可以更新 sync.WaitGroup 中的计数器 counter。虽然 sync.WaitGroup.Add 方法传入的参数可以为负数,但是计数器只能是非负数,一旦出现负数就会发生程序崩溃。当调用计数器归零,即所有任务都执行完成时,才会通过 sync.runtime_Semrelease 唤醒处于等待状态的 Goroutine。
sync.WaitGroup 的另一个方法 sync.WaitGroup.Wait 会在计数器大于 0 并且不存在等待的 Goroutine 时,调用 runtime.sync_runtime_Semacquire 陷入睡眠。
小结
通过对 sync.WaitGroup 的分析和研究,我们能够得出以下结论:
sync.WaitGroup必须在sync.WaitGroup.Wait方法返回之后才能被重新使用;sync.WaitGroup.Done只是对sync.WaitGroup.Add方法的简单封装,我们可以向sync.WaitGroup.Add方法传入任意负数(需要保证计数器非负)快速将计数器归零以唤醒等待的 Goroutine;- 可以同时有多个 Goroutine 等待当前
sync.WaitGroup计数器的归零,这些 Goroutine 会被同时唤醒;
Once
sync.Once 可以保证在 Go 程序运行期间的某段代码只会执行一次。结构体
每一个 sync.Once 结构体中都只包含一个用于标识代码块是否执行过的 done 以及一个互斥锁 sync.Mutex:
接口
sync.Once.Do 是 sync.Once 结构体对外唯一暴露的方法,该方法会接收一个入参为空的函数:
- 如果传入的函数已经执行过,会直接返回;
- 如果传入的函数没有执行过,会调用
sync.Once.doSlow执行传入的函数:
sync.Once 会通过成员变量 done 确保函数不会执行第二次。
- 为当前 Goroutine 获取互斥锁;
- 执行传入的无入参函数;
- 运行延迟函数调用,将成员变量
done更新成 1;
小结
作为用于保证函数执行次数的 sync.Once 结构体,它使用互斥锁和 sync/atomic 包提供的方法实现了某个函数在程序运行期间只能执行一次的语义。在使用该结构体时,我们也需要注意以下的问题:
sync.Once.Do方法中传入的函数只会被执行一次,哪怕函数中发生了panic;- 两次调用
sync.Once.Do方法传入不同的函数只会执行第一次调传入的函数;
Cond
sync.Cond,它可以让一组的 Goroutine 都在满足特定条件时被唤醒。结构体
sync.Cond 的结构体中包含以下 4 个字段:
noCopy— 用于保证结构体不会在编译期间拷贝;copyChecker— 用于禁止运行期间发生的拷贝;L— 用于保护内部的notify字段,Locker接口类型的变量;notify— 一个 Goroutine 的链表,它是实现同步机制的核心结构;
在 sync.notifyList 结构体中,head 和 tail 分别指向的链表的头和尾,wait 和 notify 分别表示当前正在等待的和已经通知到的 Goroutine 的索引。
接口
sync.Cond 对外暴露的 sync.Cond.Wait 方法会将当前 Goroutine 陷入休眠状态
sync.Cond.Signal方法会唤醒队列最前面的 Goroutine;sync.Cond.Broadcast方法会唤醒队列中全部的 Goroutine;
在一般情况下,我们都会先调用 sync.Cond.Wait 陷入休眠等待满足期望条件,当满足唤醒条件时,就可以选择使用 sync.Cond.Signal 或者 sync.Cond.Broadcast 唤醒一个或者全部的 Goroutine。
小结
sync.Cond 不是一个常用的同步机制,但是在条件长时间无法满足时,与使用 for {} 进行忙碌等待相比,sync.Cond 能够让出处理器的使用权,提高 CPU 的利用率。使用时我们也需要注意以下问题:
sync.Cond.Wait在调用之前一定要使用获取互斥锁,否则会触发程序崩溃;sync.Cond.Signal唤醒的 Goroutine 都是队列最前面、等待最久的 Goroutine;sync.Cond.Broadcast会按照一定顺序广播通知等待的全部 Goroutine;
6.3 计时器
6.3.2 数据结构
runtime.timer 是 Go 语言计时器的内部表示,每一个计时器都存储在对应处理器的最小四叉堆中,下面是运行时计时器对应的结构体:
when— 当前计时器被唤醒的时间;period— 两次被唤醒的间隔;f— 每当计时器被唤醒时都会调用的函数;arg— 计时器被唤醒时调用f传入的参数;nextWhen— 计时器处于timerModifiedXX状态时,用于设置when字段;status— 计时器的状态;
然而这里的 runtime.timer 只是计时器运行时的私有结构体,对外暴露的计时器使用 time.Timer 结体:
time.Timer 计时器必须通过 time.NewTimer、time.AfterFunc 或者 time.After 函数创建。 当计时器失效时,订阅计时器 Channel 的 Goroutine 会收到计时器失效的时间。
6.4 Channel
6.4.1 设计原理
虽然我们在 Go 语言中也能使用共享内存加互斥锁进行通信,但是 Go 语言提供了一种不同的并发模型,即通信顺序进程(Communicating sequential processes,CSP)1。Goroutine 和 Channel 分别对应 CSP 中的实体和传递信息的媒介,Goroutine 之间会通过 Channel 传递数据。
先入先出
目前的 Channel 收发操作均遵循了先进先出的设计,具体规则如下:
- 先从 Channel 读取数据的 Goroutine 会先接收到数据;
- 先向 Channel 发送数据的 Goroutine 会得到先发送数据的权利;
这种 FIFO 的设计是相对好理解的,但是稍早的 Go 语言实现却没有严格遵循这一语义,我们能在 runtime: make sure blocked channels run operations in FIFO order 中找到关于带缓冲区的 Channel 在执行收发操作时没有遵循先进先出的讨论2。
- 发送方会向缓冲区中写入数据,然后唤醒接收方,多个接收方会尝试从缓冲区中读取数据,如果没有读取到会重新陷入休眠;
- 接收方会从缓冲区中读取数据,然后唤醒发送方,发送方会尝试向缓冲区写入数据,如果缓冲区已满会重新陷入休眠;
这种基于重试的机制会导致 Channel 的处理不会遵循先进先出的原则。经过 runtime: simplify buffered channels 和 runtime: simplify chan ops, take 2 两个提交的修改,带缓冲区和不带缓冲区的 Channel 都会遵循先入先出发送和接收数据3 4。
runtime.hchan,该结构体中包含了用于保护成员变量的互斥锁,从某种程度上说,Channel 是一个用于同步和通信的有锁队列,使用互斥锁解决程序中可能存在的线程竞争问题是很常见的,我们能很容易地实现有锁队列。- 同步 Channel — 不需要缓冲区,发送方会直接将数据交给(Handoff)接收方;
- 异步 Channel — 基于环形缓存的传统生产者消费者模型;
chan struct{}类型的异步 Channel —struct{}类型不占用内存空间,不需要实现缓冲区和直接发送(Handoff)的语义;
6.4.2 数据结构
Go 语言的 Channel 在运行时使用 runtime.hchan 结构体表示。我们在 Go 语言中创建新的 Channel 时,实际上创建的都是如下所示的结构:
runtime.hchan 结构体中的五个字段 qcount、dataqsiz、buf、sendx、recv 构建底层的循环队列:
qcount— Channel 中的元素个数;dataqsiz— Channel 中的循环队列的长度;buf— Channel 的缓冲区数据指针;sendx— Channel 的发送操作处理到的位置;recvx— Channel 的接收操作处理到的位置;
除此之外,elemsize 和 elemtype 分别表示当前 Channel 能够收发的元素类型和大小;sendq 和 recvq 存储了当前 Channel 由于缓冲区空间不足而阻塞的 Goroutine 列表,这些等待队列使用双向链表 runtime.waitq 表示,链表中所有的元素都是 runtime.sudog 结构:
runtime.sudog 表示一个在等待列表中的 Goroutine,该结构中存储了两个分别指向前后 runtime.sudog 的指针以构成链表。
- 当存在等待的接收者时,通过
runtime.send直接将数据发送给阻塞的接收者; - 当缓冲区存在空余空间时,将发送的数据写入 Channel 的缓冲区;
- 当不存在缓冲区或者缓冲区已满时,等待其他 Goroutine 从 Channel 接收数据;
6.4.4 发送数据
直接发送
如果目标 Channel 没有被关闭并且已经有处于读等待的 Goroutine,那么 runtime.chansend 会从接收队列 recvq 中取出最先陷入等待的 Goroutine 并直接向它发送数据
缓冲区
sendx 索引所在的位置并将 sendx 索引加一。因为这里的 buf 是一个循环数组,所以当 sendx 等于 dataqsiz 时会重新回到数组开始的位置。阻塞发送
select 关键字可以向 Channel 非阻塞地发送消息。小结
我们在这里可以简单梳理和总结一下使用 ch <- i 表达式向 Channel 发送数据时遇到的几种情况:
- 如果当前 Channel 的
recvq上存在已经被阻塞的 Goroutine,那么会直接将数据发送给当前 Goroutine 并将其设置成下一个运行的 Goroutine; - 如果 Channel 存在缓冲区并且其中还有空闲的容量,我们会直接将数据存储到缓冲区
sendx所在的位置上; - 如果不满足上面的两种情况,会创建一个
runtime.sudog结构并将其加入 Channel 的sendq队列中,当前 Goroutine 也会陷入阻塞等待其他的协程从 Channel 接收数据;
发送数据的过程中包含几个会触发 Goroutine 调度的时机:
- 发送数据时发现 Channel 上存在等待接收数据的 Goroutine,立刻设置处理器的
runnext属性,但是并不会立刻触发调度; - 发送数据时并没有找到接收方并且缓冲区已经满了,这时会将自己加入 Channel 的
sendq队列并调用runtime.goparkunlock触发 Goroutine 的调度让出处理器的使用权;
6.4.5 接收数据
当我们从一个空 Channel 接收数据时会直接调用 runtime.gopark 让出处理器的使用权。
如果channel关了,这时候还是可以读出缓冲区里的数据
如果当前 Channel 已经被关闭并且缓冲区中不存在任何数据,那么会清除 ep 指针中的数据并立刻返回。
除了上述两种特殊情况,使用 runtime.chanrecv 从 Channel 接收数据时还包含以下三种不同情况:
- 当存在等待的发送者时,通过
runtime.recv从阻塞的发送者或者缓冲区中获取数据; - 当缓冲区存在数据时,从 Channel 的缓冲区中接收数据;
- 当缓冲区中不存在数据时,等待其他 Goroutine 向 Channel 发送数据;
直接接收
sendq 队列中包含处于等待状态的 Goroutine 时,该函数会取出队列头等待的 Goroutine,处理的逻辑和发送时相差无几,只是发送数据时调用的是 runtime.send 函数,而接收数据时使用 runtime.recv该函数会根据缓冲区的大小分别处理不同的情况:
- 如果 Channel 不存在缓冲区;
- 调用
runtime.recvDirect将 Channel 发送队列中 Goroutine 存储的elem数据拷贝到目标内存地址中;
- 调用
- 如果 Channel 存在缓冲区;
- 将队列中的数据拷贝到接收方的内存地址;
- 将发送队列头的数据拷贝到缓冲区中,释放一个阻塞的发送方;
无论发生哪种情况,运行时都会调用 runtime.goready 将当前处理器的 runnext 设置成发送数据的 Goroutine,在调度器下一次调度时将阻塞的发送方唤醒。
runtime.typedmemmove 将缓冲区中的数据拷贝到内存中、清除队列中的数据并完成收尾工作。recvx,一旦发现索引超过了 Channel 的容量时,会将它归零重置循环队列的索引;除此之外,该函数还会减少 qcount 计数器并释放持有 Channel 的锁。阻塞接收
当 Channel 的发送队列中不存在等待的 Goroutine 并且缓冲区中也不存在任何数据时,从管道中接收数据的操作会变成阻塞的,然而不是所有的接收操作都是阻塞的,与 select 语句结合使用时就可能会使用到非阻塞的接收操作
在正常的接收场景中,我们会使用 runtime.sudog 将当前 Goroutine 包装成一个处于等待状态的 Goroutine 并将其加入到接收队列中。
完成入队之后,上述代码还会调用 runtime.goparkunlock 立刻触发 Goroutine 的调度,让出处理器的使用权并等待调度器的调度。
小结
我们梳理一下从 Channel 中接收数据时可能会发生的五种情况:
- 如果 Channel 为空,那么会直接调用
runtime.gopark挂起当前 Goroutine; - 如果 Channel 已经关闭并且缓冲区没有任何数据,
runtime.chanrecv会直接返回; - 如果 Channel 的
sendq队列中存在挂起的 Goroutine,会将recvx索引所在的数据拷贝到接收变量所在的内存空间上并将sendq队列中 Goroutine 的数据拷贝到缓冲区; - 如果 Channel 的缓冲区中包含数据,那么直接读取
recvx索引对应的数据; - 在默认情况下会挂起当前的 Goroutine,将
runtime.sudog结构加入recvq队列并陷入休眠等待调度器的唤醒;
我们总结一下从 Channel 接收数据时,会触发 Goroutine 调度的两个时机:
- 当 Channel 为空时;
- 当缓冲区中不存在数据并且也不存在数据的发送者时;
6.4.6 关闭管道
编译器会将用于关闭管道的 close 关键字转换成 OCLOSE 节点以及 runtime.closechan 函数。
当 Channel 是一个空指针或者已经被关闭时,Go 语言运行时都会直接崩溃并抛出异常
该函数在最后会为所有被阻塞的 Goroutine 调用 runtime.goready 触发调度。
6.5 调度器
Go 语言的调度器通过使用与 CPU 数量相等的线程减少线程频繁切换的内存开销,同时在每一个线程上执行额外开销更低的 Goroutine 来降低操作系统和硬件的负载。
6.5.2 数据结构 #
相信各位读者已经对 Go 语言调度相关的数据结构已经非常熟悉了,但是我们在一些还是要回顾一下运行时调度器的三个重要组成部分 — 线程 M、Goroutine G 和处理器 P:
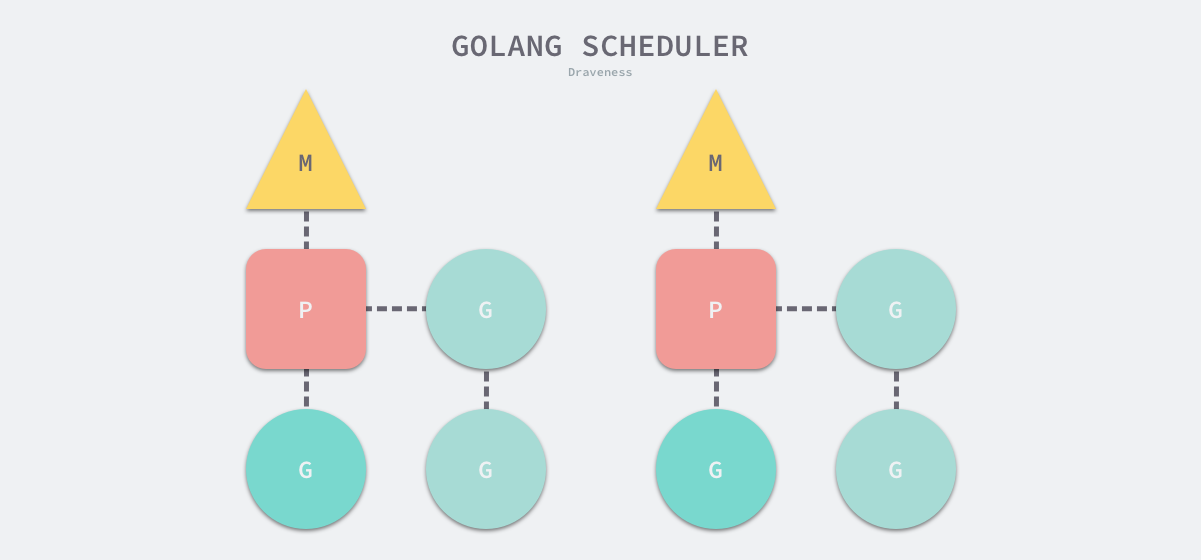
图 6-29 Go 语言调度器
- G — 表示 Goroutine,它是一个待执行的任务;
- M — 表示操作系统的线程,它由操作系统的调度器调度和管理;
- P — 表示处理器,它可以被看做运行在线程上的本地调度器;
G
Goroutine 是 Go 语言调度器中待执行的任务,它在运行时调度器中的地位与线程在操作系统中差不多,但是它占用了更小的内存空间,也降低了上下文切换的开销。
Goroutine 只存在于 Go 语言的运行时,它是 Go 语言在用户态提供的线程,作为一种粒度更细的资源调度单元,如果使用得当能够在高并发的场景下更高效地利用机器的 CPU。
M
Go 语言并发模型中的 M 是操作系统线程。调度器最多可以创建 10000 个线程,但是其中大多数的线程都不会执行用户代码(可能陷入系统调用),最多只会有 GOMAXPROCS 个活跃线程能够正常运行。
在默认情况下,运行时会将 GOMAXPROCS 设置成当前机器的核数,我们也可以在程序中使用 runtime.GOMAXPROCS 来改变最大的活跃线程数。默认的设置不会频繁触发操作系统的线程调度和上下文切换,所有的调度都会发生在用户态,由 Go 语言调度器触发,能够减少很多额外开销。
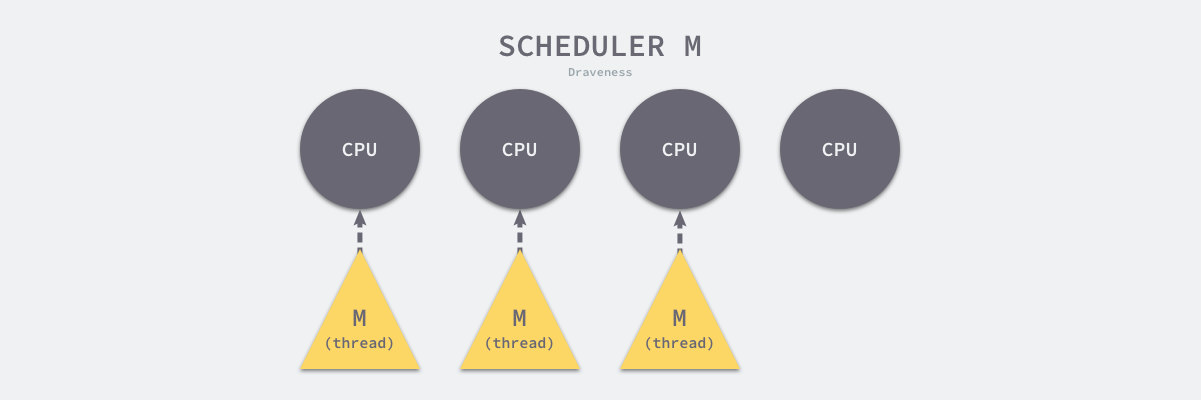
P
调度器中的处理器 P 是线程和 Goroutine 的中间层,它能提供线程需要的上下文环境,也会负责调度线程上的等待队列,通过处理器 P 的调度,每一个内核线程都能够执行多个 Goroutine,它能在 Goroutine 进行一些 I/O 操作时及时让出计算资源,提高线程的利用率。
因为调度器在启动时就会创建 GOMAXPROCS 个处理器,所以 Go 语言程序的处理器数量一定会等于 GOMAXPROCS,这些处理器会绑定到不同的内核线程上。
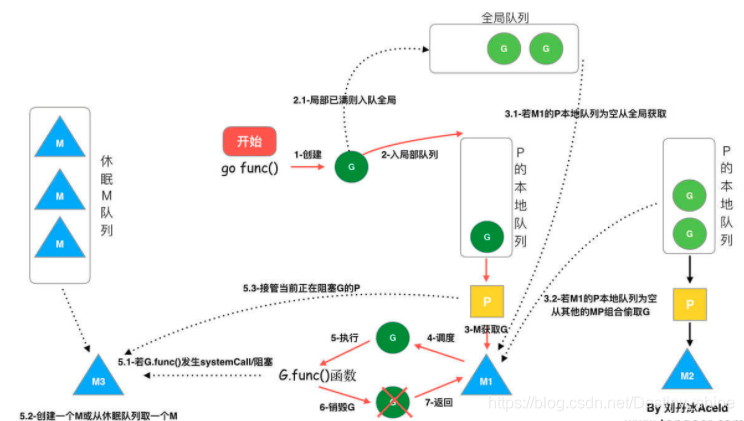
分析上图得出结论:
可以通过 go func () 创建一个 goroutine;
有两个存储 G 的队列,一个是调度器 P 的本地 G 队列、一个是全局 G 队列。新创建的 G 会先保存在 P 的本地队列,如果 P 的本地队列已满就会保存在全局的队列里;
G 只能运行在 M 中,一个 M 必须持有一个 P,M 与 P 是 1:1 的关系。M 会从 P 的本地队列弹出一个可执行状态的 G 来执行,如果 P 的本地队列为空,就会从其他 MP 组合偷取一个可执行的 G 来执行;
一个 M 调度 G 执行的过程是一个循环机制;
当 M 执行某一个 G 时候如果发生了 syscall(系统调用) 等操作,M 会阻塞,如果当前正好有一些 G 在执行,runtime 会把这个线程 M 从 P 中摘除,然后再创建一个新的操作系统的线程 (如果有空闲的线程可用就复用空闲线程) 来服务于这个 P;
当 M 系统调用结束时,这个 G 会尝试获取一个空闲的 P 执行,并放入到这个 P 的本地队列。如果获取不到 P,那么这个线程 M 变成休眠状态, 加入到空闲线程中,然后这个 G 会被放入全局队列中。
6.6 网络轮询器
6.6.1 设计原理
I/O 模型 #
操作系统中包含阻塞 I/O、非阻塞 I/O、信号驱动 I/O 与异步 I/O 以及 I/O 多路复用五种 I/O 模型。我们在本节中会介绍上述五种模型中的三种:
- 阻塞 I/O 模型;
- 非阻塞 I/O 模型;
- I/O 多路复用模型;
在 Unix 和类 Unix 操作系统中,文件描述符(File descriptor,FD)是用于访问文件或者其他 I/O 资源的抽象句柄,例如:管道或者网络套接字1。而不同的 I/O 模型会使用不同的方式操作文件描述符。
阻塞 I/O #
阻塞 I/O 是最常见的 I/O 模型,在默认情况下,当我们通过 read 或者 write 等系统调用读写文件或者网络时,应用程序会被阻塞:
如下图所示,当我们执行 read 系统调用时,应用程序会从用户态陷入内核态,内核会检查文件描述符是否可读;当文件描述符中存在数据时,操作系统内核会将准备好的数据拷贝给应用程序并交回控制权。
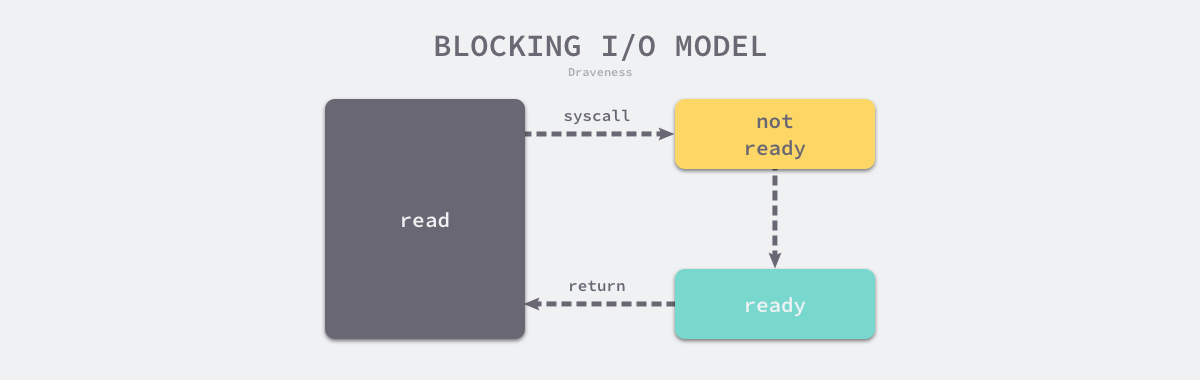
图 6-39 阻塞 I/O 模型
操作系统中多数的 I/O 操作都是如上所示的阻塞请求,一旦执行 I/O 操作,应用程序会陷入阻塞等待 I/O 操作的结束。
非阻塞 I/O #
当进程把一个文件描述符设置成非阻塞时,执行 read 和 write 等 I/O 操作会立刻返回。在 C 语言中,我们可以使用如下所示的代码片段将一个文件描述符设置成非阻塞的:
在上述代码中,最关键的就是系统调用 fcntl 和参数 O_NONBLOCK,fcntl 为我们提供了操作文件描述符的能力,我们可以通过它修改文件描述符的特性。当我们将文件描述符修改成非阻塞后,读写文件会经历以下流程:
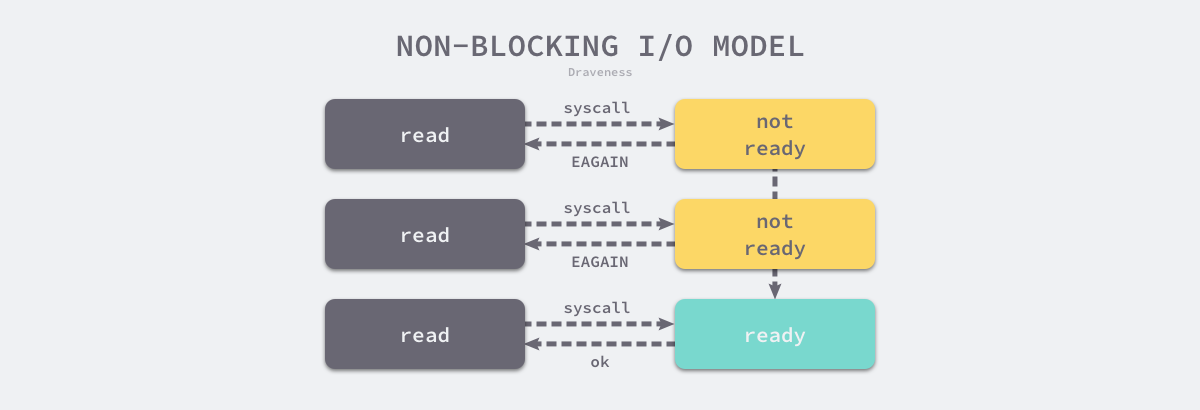
图 6-40 非阻塞 I/O 模型
第一次从文件描述符中读取数据会触发系统调用并返回 EAGAIN 错误,EAGAIN 意味着该文件描述符还在等待缓冲区中的数据;随后,应用程序会不断轮询调用 read 直到它的返回值大于 0,这时应用程序就可以对读取操作系统缓冲区中的数据并进行操作。进程使用非阻塞的 I/O 操作时,可以在等待过程中执行其他任务,提高 CPU 的利用率。
I/O 多路复用 #
I/O 多路复用被用来处理同一个事件循环中的多个 I/O 事件。I/O 多路复用需要使用特定的系统调用,最常见的系统调用是 select,该函数可以同时监听最多 1024 个文件描述符的可读或者可写状态:
除了标准的 select 之外,操作系统中还提供了一个比较相似的 poll 函数,它使用链表存储文件描述符,摆脱了 1024 的数量上限。
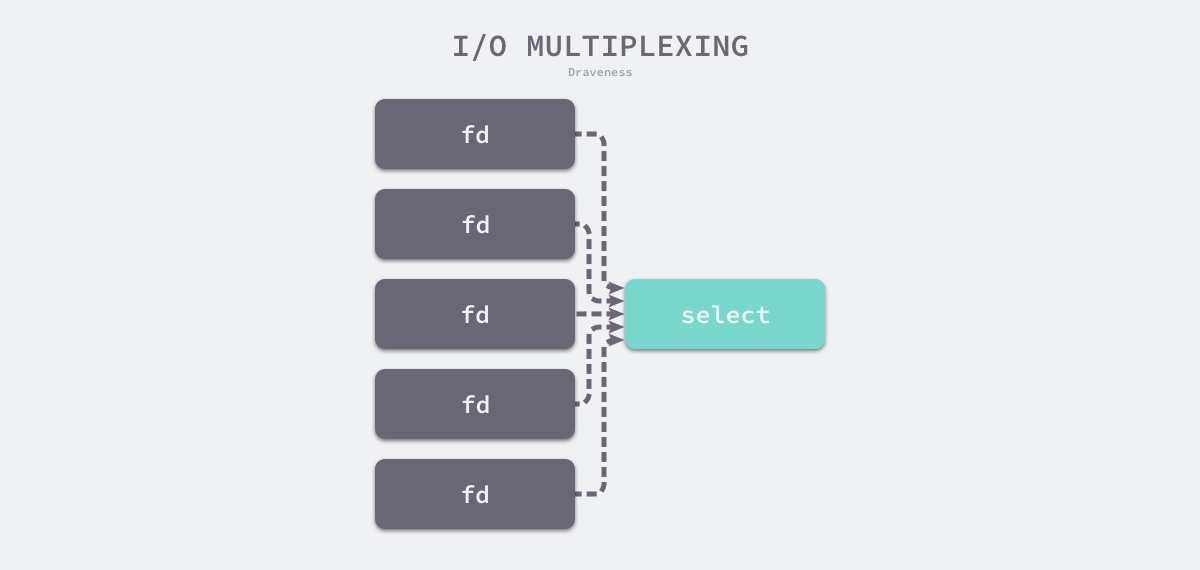
图 6-41 I/O 多路复用函数监听文件描述符
多路复用函数会阻塞的监听一组文件描述符,当文件描述符的状态转变为可读或者可写时,select 会返回可读或者可写事件的个数,应用程序可以在输入的文件描述符中查找哪些可读或者可写,然后执行相应的操作。
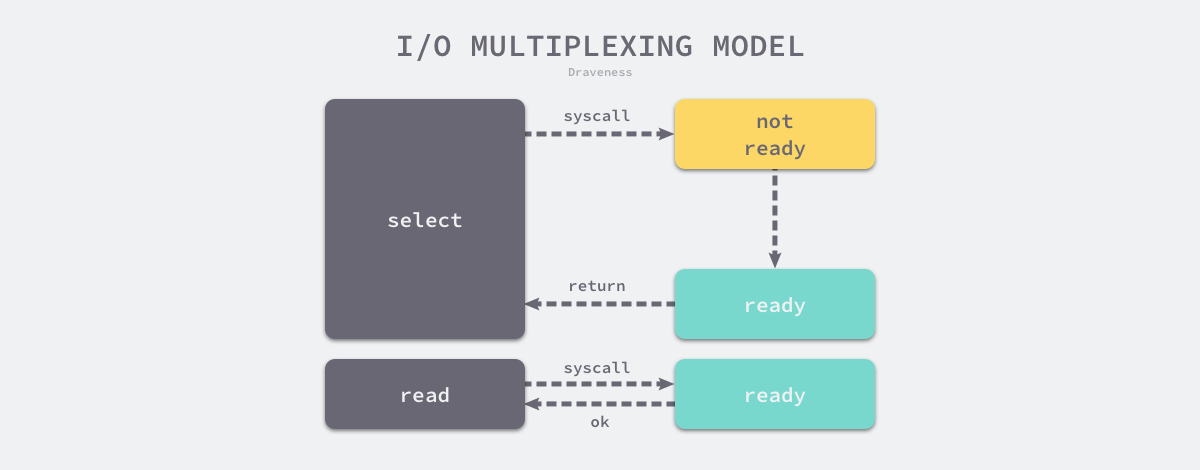
图 6-42 I/O 多路复用模型
I/O 多路复用模型是效率较高的 I/O 模型,它可以同时阻塞监听了一组文件描述符的状态。很多高性能的服务和应用程序都会使用这一模型来处理 I/O 操作,例如:Redis 和 Nginx 等。
多模块
Go 语言在网络轮询器中使用 I/O 多路复用模型处理 I/O 操作,但是他没有选择最常见的系统调用 select2。虽然 select 也可以提供 I/O 多路复用的能力,但是使用它有比较多的限制:
- 监听能力有限 — 最多只能监听 1024 个文件描述符;
- 内存拷贝开销大 — 需要维护一个较大的数据结构存储文件描述符,该结构需要拷贝到内核中;
- 时间复杂度 O(n)O(n) — 返回准备就绪的事件个数后,需要遍历所有的文件描述符;
为了提高 I/O 多路复用的性能,不同的操作系统也都实现了自己的 I/O 多路复用函数,例如:epoll、kqueue 和 evport 等。Go 语言为了提高在不同操作系统上的 I/O 操作性能,使用平台特定的函数实现了多个版本的网络轮询模块:
src/runtime/netpoll_epoll.gosrc/runtime/netpoll_kqueue.gosrc/runtime/netpoll_solaris.gosrc/runtime/netpoll_windows.gosrc/runtime/netpoll_aix.gosrc/runtime/netpoll_fake.go
这些模块在不同平台上实现了相同的功能,构成了一个常见的树形结构。编译器在编译 Go 语言程序时,会根据目标平台选择树中特定的分支进行编译:
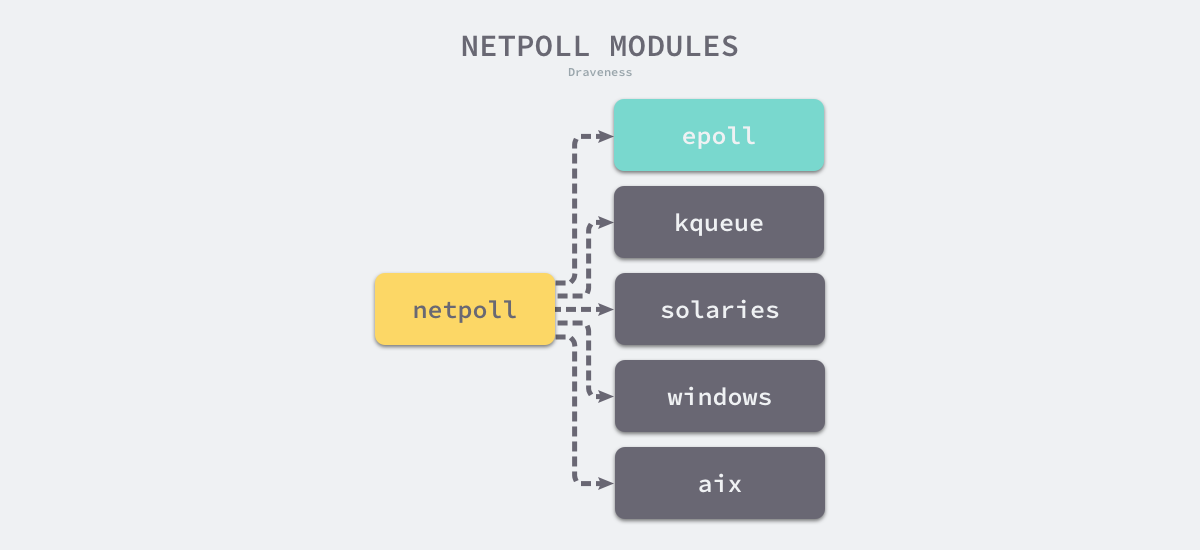
图 6-43 多模块网络轮询器
如果目标平台是 Linux,那么就会根据文件中的 // +build linux 编译指令选择 src/runtime/netpoll_epoll.go 并使用 epoll 函数处理用户的 I/O 操作。
6.6.4 小结
网络轮询器并不是由运行时中的某一个线程独立运行的,运行时的调度器和系统调用都会通过 runtime.netpoll 与网络轮询器交换消息,获取待执行的 Goroutine 列表,并将待执行的 Goroutine 加入运行队列等待处理。
所有的文件 I/O、网络 I/O 和计时器都是由网络轮询器管理的,它是 Go 语言运行时重要的组成部分。
6.7 系统监控
6.7.3 小结
运行时通过系统监控来触发线程的抢占、网络的轮询和垃圾回收,保证 Go 语言运行时的可用性。系统监控能够很好地解决尾延迟的问题,减少调度器调度 Goroutine 的饥饿问题并保证计时器在尽可能准确的时间触发。
7.1 内存分配器
程序中的数据和变量都会被分配到程序所在的虚拟内存中,内存空间包含两个重要区域:栈区(Stack)和堆区(Heap)。函数调用的参数、返回值以及局部变量大都会被分配到栈上,这部分内存会由编译器进行管理;不同编程语言使用不同的方法管理堆区的内存,C++ 等编程语言会由工程师主动申请和释放内存,Go 以及 Java 等编程语言会由工程师和编译器共同管理,堆中的对象由内存分配器分配并由垃圾收集器回收。
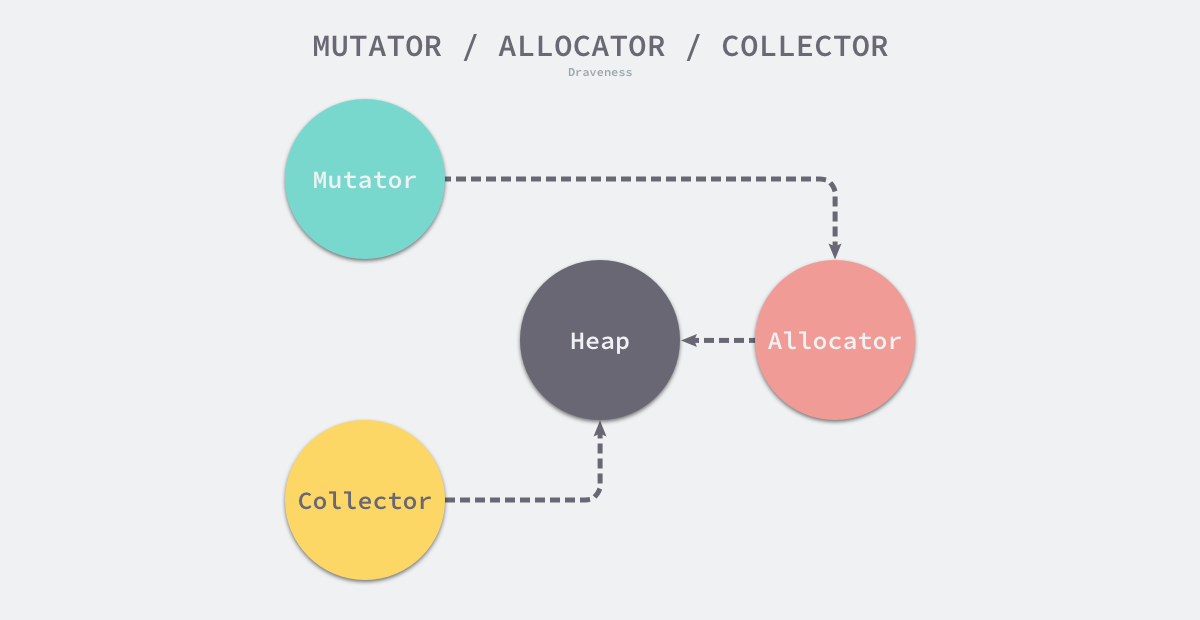
7.1.1 设计原理
内存管理一般包含三个不同的组件,分别是用户程序(Mutator)、分配器(Allocator)和收集器(Collector)1,当用户程序申请内存时,它会通过内存分配器申请新内存,而分配器会负责从堆中初始化相应的内存区域。
分配方法 #
编程语言的内存分配器一般包含两种分配方法,一种是线性分配器(Sequential Allocator,Bump Allocator),另一种是空闲链表分配器(Free-List Allocator),这两种分配方法有着不同的实现机制和特性,本节会依次介绍它们的分配过程。
线性分配器 #
线性分配(Bump Allocator)是一种高效的内存分配方法,但是有较大的局限性。当我们使用线性分配器时,只需要在内存中维护一个指向内存特定位置的指针,如果用户程序向分配器申请内存,分配器只需要检查剩余的空闲内存、返回分配的内存区域并修改指针在内存中的位置,即移动下图中的指针:
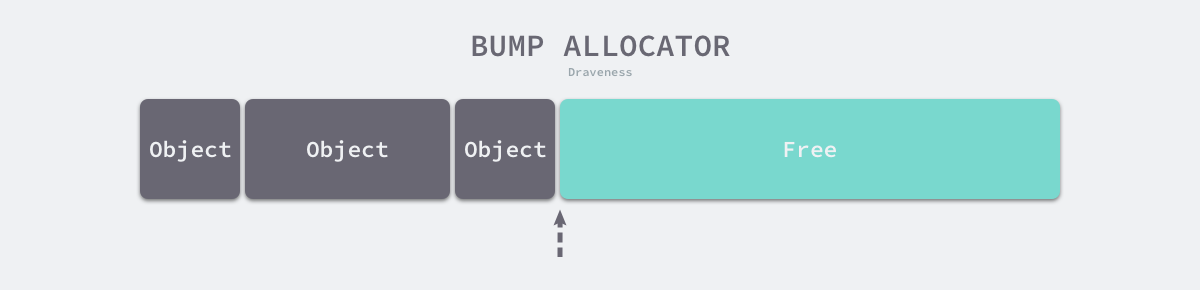
图 7-2 线性分配器
虽然线性分配器实现为它带来了较快的执行速度以及较低的实现复杂度,但是线性分配器无法在内存被释放时重用内存。如下图所示,如果已经分配的内存被回收,线性分配器无法重新利用红色的内存:
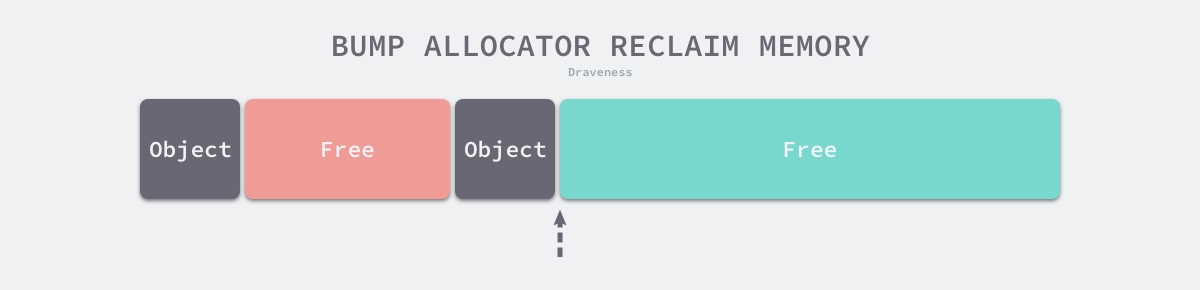
图 7-3 线性分配器回收内存
因为线性分配器具有上述特性,所以需要与合适的垃圾回收算法配合使用,例如:标记压缩(Mark-Compact)、复制回收(Copying GC)和分代回收(Generational GC)等算法,它们可以通过拷贝的方式整理存活对象的碎片,将空闲内存定期合并,这样就能利用线性分配器的效率提升内存分配器的性能了。
因为线性分配器需要与具有拷贝特性的垃圾回收算法配合,所以 C 和 C++ 等需要直接对外暴露指针的语言就无法使用该策略,我们会在下一节详细介绍常见垃圾回收算法的设计原理。
空闲链表分配器 #
空闲链表分配器(Free-List Allocator)可以重用已经被释放的内存,它在内部会维护一个类似链表的数据结构。当用户程序申请内存时,空闲链表分配器会依次遍历空闲的内存块,找到足够大的内存,然后申请新的资源并修改链表:
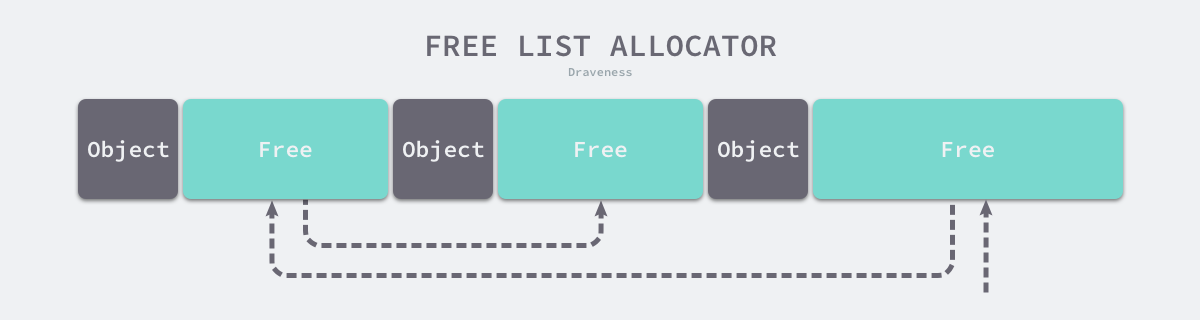
图 7-4 空闲链表分配器
因为不同的内存块通过指针构成了链表,所以使用这种方式的分配器可以重新利用回收的资源,但是因为分配内存时需要遍历链表,所以它的时间复杂度是 O(n)。空闲链表分配器可以选择不同的策略在链表中的内存块中进行选择,最常见的是以下四种:
- 首次适应(First-Fit)— 从链表头开始遍历,选择第一个大小大于申请内存的内存块;
- 循环首次适应(Next-Fit)— 从上次遍历的结束位置开始遍历,选择第一个大小大于申请内存的内存块;
- 最优适应(Best-Fit)— 从链表头遍历整个链表,选择最合适的内存块;
- 隔离适应(Segregated-Fit)— 将内存分割成多个链表,每个链表中的内存块大小相同,申请内存时先找到满足条件的链表,再从链表中选择合适的内存块;
上述四种策略的前三种就不过多介绍了,Go 语言使用的内存分配策略与第四种策略有些相似,我们通过下图了解该策略的原理:
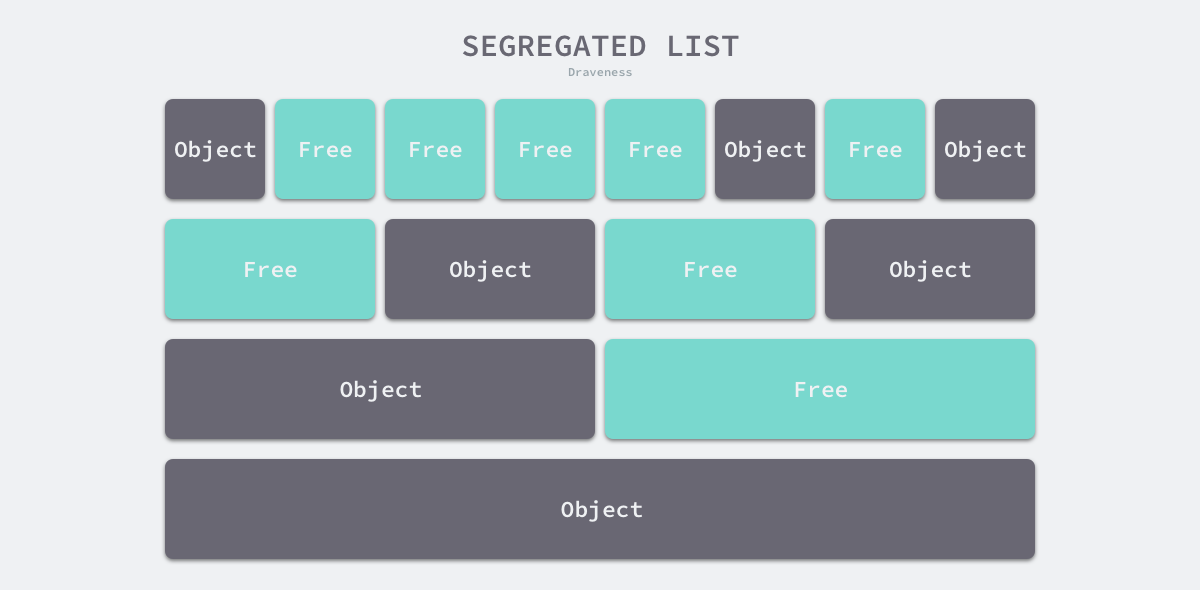
图 7-5 隔离适应策略
如上图所示,该策略会将内存分割成由 4、8、16、32 字节的内存块组成的链表,当我们向内存分配器申请 8 字节的内存时,它会在上图中找到满足条件的空闲内存块并返回。隔离适应的分配策略减少了需要遍历的内存块数量,提高了内存分配的效率。
分级分配 #
线程缓存分配(Thread-Caching Malloc,TCMalloc)是用于分配内存的机制,它比 glibc 中的 malloc 还要快很多2。Go 语言的内存分配器就借鉴了 TCMalloc 的设计实现高速的内存分配,它的核心理念是使用多级缓存将对象根据大小分类,并按照类别实施不同的分配策略。
对象大小 #
Go 语言的内存分配器会根据申请分配的内存大小选择不同的处理逻辑,运行时根据对象的大小将对象分成微对象、小对象和大对象三种:
| 类别 | 大小 |
|---|---|
| 微对象 | (0, 16B) |
| 小对象 | [16B, 32KB] |
| 大对象 | (32KB, +∞) |
表 7-1 对象的类别和大小
因为程序中的绝大多数对象的大小都在 32KB 以下,而申请的内存大小影响 Go 语言运行时分配内存的过程和开销,所以分别处理大对象和小对象有利于提高内存分配器的性能。
多级缓存 #
内存分配器不仅会区别对待大小不同的对象,还会将内存分成不同的级别分别管理,TCMalloc 和 Go 运行时分配器都会引入线程缓存(Thread Cache)、中心缓存(Central Cache)和页堆(Page Heap)三个组件分级管理内存:
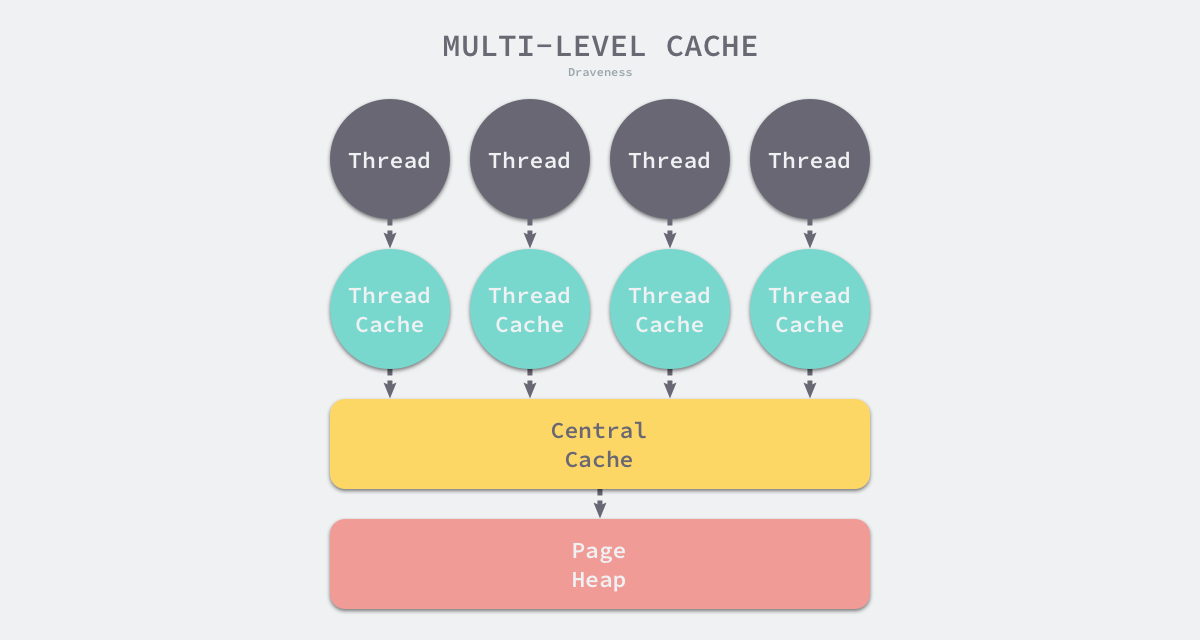
图 7-6 多级缓存内存分配
线程缓存属于每一个独立的线程,它能够满足线程上绝大多数的内存分配需求,因为不涉及多线程,所以也不需要使用互斥锁来保护内存,这能够减少锁竞争带来的性能损耗。当线程缓存不能满足需求时,运行时会使用中心缓存作为补充解决小对象的内存分配,在遇到 32KB 以上的对象时,内存分配器会选择页堆直接分配大内存。
这种多层级的内存分配设计与计算机操作系统中的多级缓存有些类似,因为多数的对象都是小对象,我们可以通过线程缓存和中心缓存提供足够的内存空间,发现资源不足时从上一级组件中获取更多的内存资源。
虚拟内存布局 #
这里会介绍 Go 语言堆区内存地址空间的设计以及演进过程,在 Go 语言 1.10 以前的版本,堆区的内存空间都是连续的;但是在 1.11 版本,Go 团队使用稀疏的堆内存空间替代了连续的内存,解决了连续内存带来的限制以及在特殊场景下可能出现的问题。
7.1.2 内存管理组件
Go 语言的内存分配器包含内存管理单元、线程缓存、中心缓存和页堆几个重要组件,本节将介绍这几种最重要组件对应的数据结构 runtime.mspan、runtime.mcache、runtime.mcentral 和 runtime.mheap,我们会详细介绍它们在内存分配器中的作用以及实现。
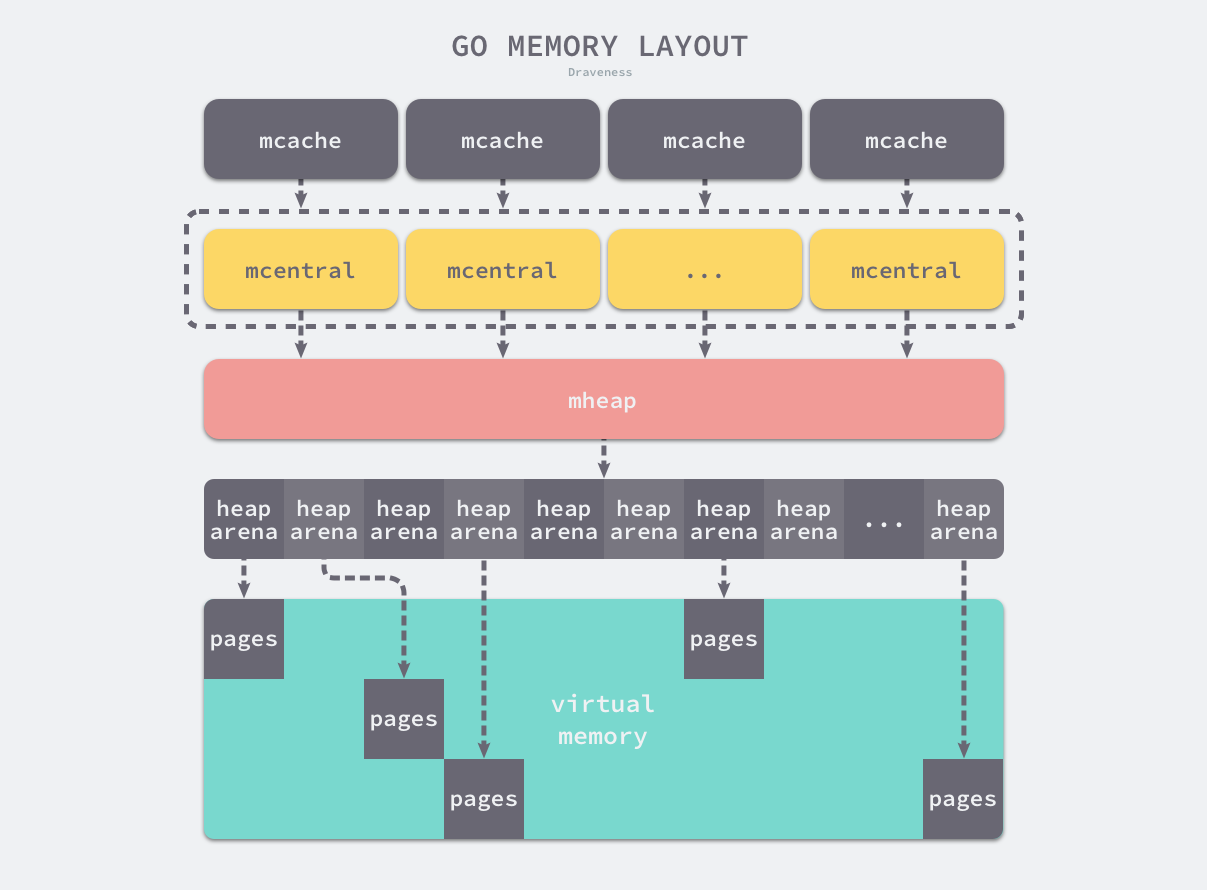
图 7-10 Go 程序的内存布局
线程缓存
runtime.mcache 是 Go 语言中的线程缓存,它会与线程上的处理器一一绑定,主要用来缓存用户程序申请的微小对象。每一个线程缓存都持有 68 * 2 个 runtime.mspan,这些内存管理单元都存储在结构体的 alloc 字段中:
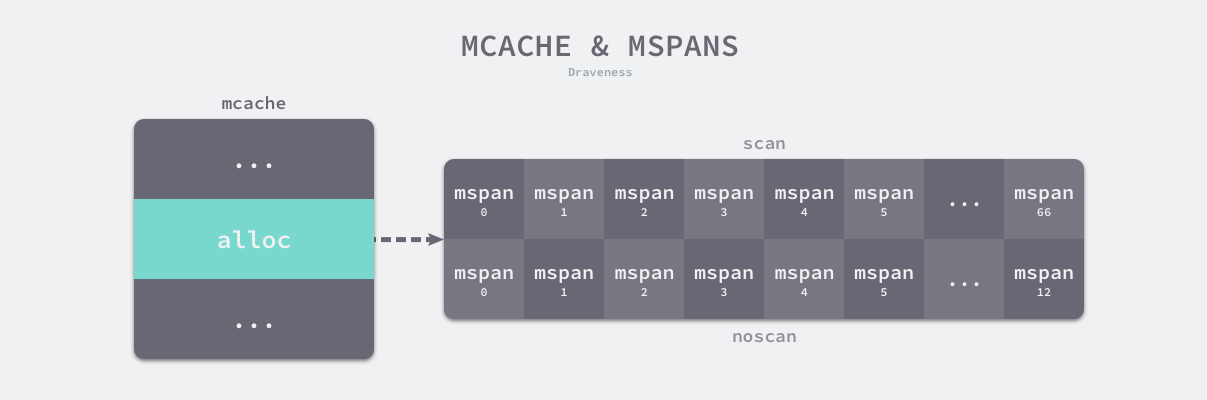
图 7-15 线程缓存与内存管理单元
线程缓存在刚刚被初始化时是不包含 runtime.mspan 的,只有当用户程序申请内存时才会从上一级组件获取新的 runtime.mspan 满足内存分配的需求。
中心缓存 #
runtime.mcentral 是内存分配器的中心缓存,与线程缓存不同,访问中心缓存中的内存管理单元需要使用互斥锁:
每个中心缓存都会管理某个跨度类的内存管理单元,它会同时持有两个 runtime.spanSet,分别存储包含空闲对象和不包含空闲对象的内存管理单元。
7.1.3 内存分配
runtime.newobject 函数分配内存,该函数会调用 runtime.mallocgc 分配指定大小的内存空间,这也是用户程序向堆上申请内存空间的必经函数 上述代码使用 runtime.gomcache 获取线程缓存并判断申请内存的类型是否为指针。我们从这个代码片段可以看出 runtime.mallocgc 会根据对象的大小执行不同的分配逻辑,在前面的章节也曾经介绍过运行时根据对象大小将它们分成微对象、小对象和大对象,这里会根据大小选择不同的分配逻辑:
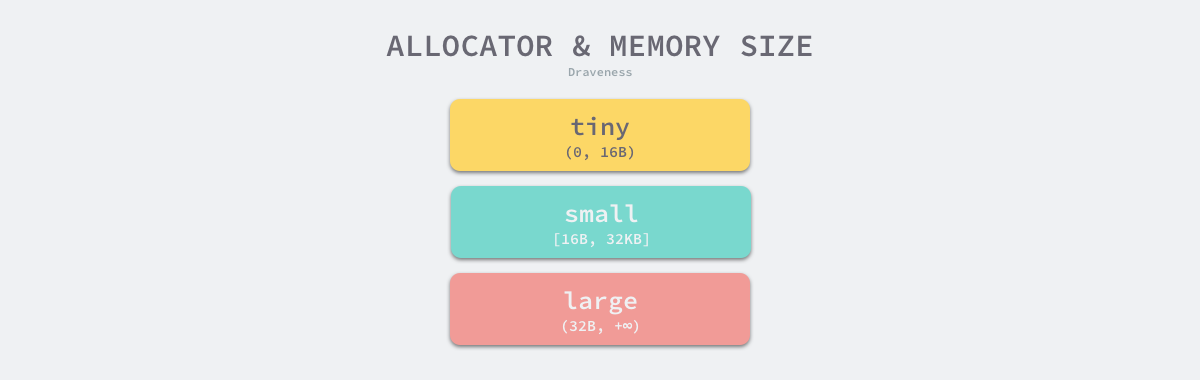
图 7-19 三种对象
- 微对象
(0, 16B)— 先使用微型分配器,再依次尝试线程缓存、中心缓存和堆分配内存; - 小对象
[16B, 32KB]— 依次尝试使用线程缓存、中心缓存和堆分配内存; - 大对象
(32KB, +∞)— 直接在堆上分配内存;
我们会依次介绍运行时分配微对象、小对象和大对象的过程,梳理内存分配的核心执行流程。
微对象 #
Go 语言运行时将小于 16 字节的对象划分为微对象,它会使用线程缓存上的微分配器提高微对象分配的性能,我们主要使用它来分配较小的字符串以及逃逸的临时变量。微分配器可以将多个较小的内存分配请求合入同一个内存块中,只有当内存块中的所有对象都需要被回收时,整片内存才可能被回收。
小对象 #
小对象是指大小为 16 字节到 32,768 字节的对象以及所有小于 16 字节的指针类型的对象,小对象的分配可以被分成以下的三个步骤:
- 确定分配对象的大小以及跨度类
runtime.spanClass; - 从线程缓存、中心缓存或者堆中获取内存管理单元并从内存管理单元找到空闲的内存空间;
- 调用
runtime.memclrNoHeapPointers清空空闲内存中的所有数据;
大对象 #
运行时对于大于 32KB 的大对象会单独处理,我们不会从线程缓存或者中心缓存中获取内存管理单元,而是直接调用 runtime.mcache.allocLarge 分配大片内存。runtime.mcache.allocLarge 会计算分配该对象所需要的页数,它按照 8KB 的倍数在堆上申请内存
7.1.4 小结 #
内存分配是 Go 语言运行时内存管理的核心逻辑,运行时的内存分配器使用类似 TCMalloc 的分配策略将对象根据大小分类,并设计多层级的组件提高内存分配器的性能。
7.2 垃圾收集器
7.2.1 设计原理
标记清除 #
标记清除(Mark-Sweep)算法是最常见的垃圾收集算法,标记清除收集器是跟踪式垃圾收集器,其执行过程可以分成标记(Mark)和清除(Sweep)两个阶段:
- 标记阶段 — 从根对象出发查找并标记堆中所有存活的对象;
- 清除阶段 — 遍历堆中的全部对象,回收未被标记的垃圾对象并将回收的内存加入空闲链表;
如下图所示,内存空间中包含多个对象,我们从根对象出发依次遍历对象的子对象并将从根节点可达的对象都标记成存活状态,即 A、C 和 D 三个对象,剩余的 B、E 和 F 三个对象因为从根节点不可达,所以会被当做垃圾:
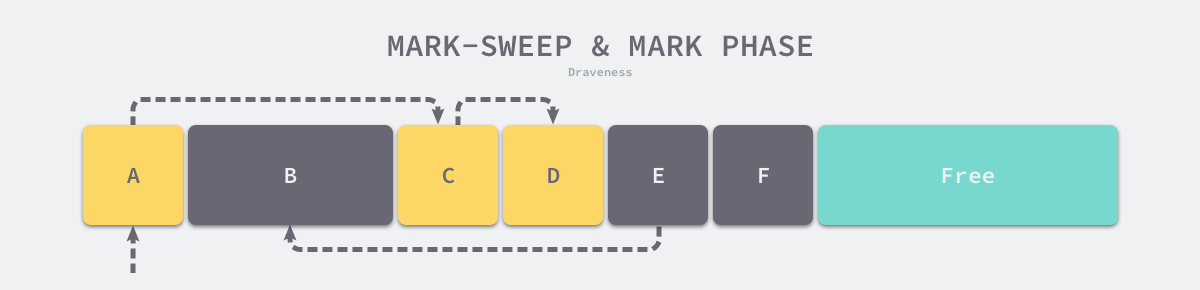
图 7-22 标记清除的标记阶段
标记阶段结束后会进入清除阶段,在该阶段中收集器会依次遍历堆中的所有对象,释放其中没有被标记的 B、E 和 F 三个对象并将新的空闲内存空间以链表的结构串联起来,方便内存分配器的使用。
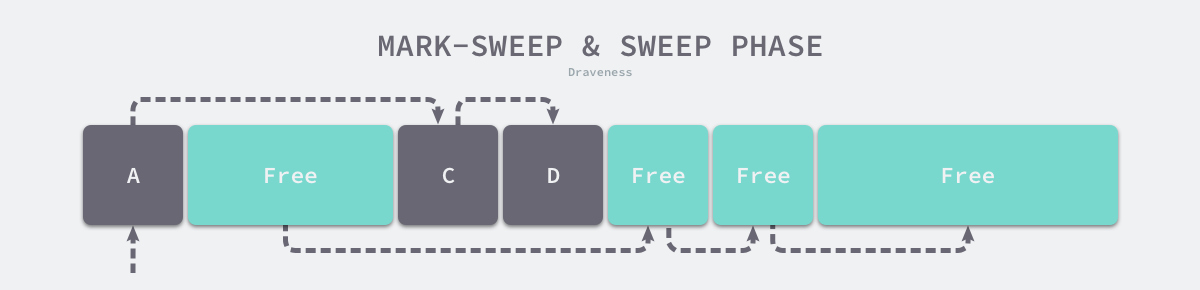
图 7-23 标记清除的清除阶段
这里介绍的是最传统的标记清除算法,垃圾收集器从垃圾收集的根对象出发,递归遍历这些对象指向的子对象并将所有可达的对象标记成存活;标记阶段结束后,垃圾收集器会依次遍历堆中的对象并清除其中的垃圾,整个过程需要标记对象的存活状态,用户程序在垃圾收集的过程中也不能执行,我们需要用到更复杂的机制来解决 STW 的问题。
三色抽象 #
为了解决原始标记清除算法带来的长时间 STW,多数现代的追踪式垃圾收集器都会实现三色标记算法的变种以缩短 STW 的时间。三色标记算法将程序中的对象分成白色、黑色和灰色三类4:
- 白色对象 — 潜在的垃圾,其内存可能会被垃圾收集器回收;
- 黑色对象 — 活跃的对象,包括不存在任何引用外部指针的对象以及从根对象可达的对象;
- 灰色对象 — 活跃的对象,因为存在指向白色对象的外部指针,垃圾收集器会扫描这些对象的子对象;
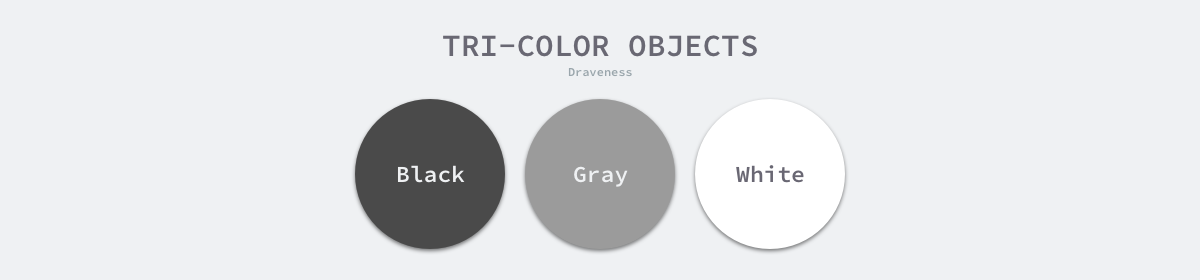
图 7-24 三色的对象
在垃圾收集器开始工作时,程序中不存在任何的黑色对象,垃圾收集的根对象会被标记成灰色,垃圾收集器只会从灰色对象集合中取出对象开始扫描,当灰色集合中不存在任何对象时,标记阶段就会结束。
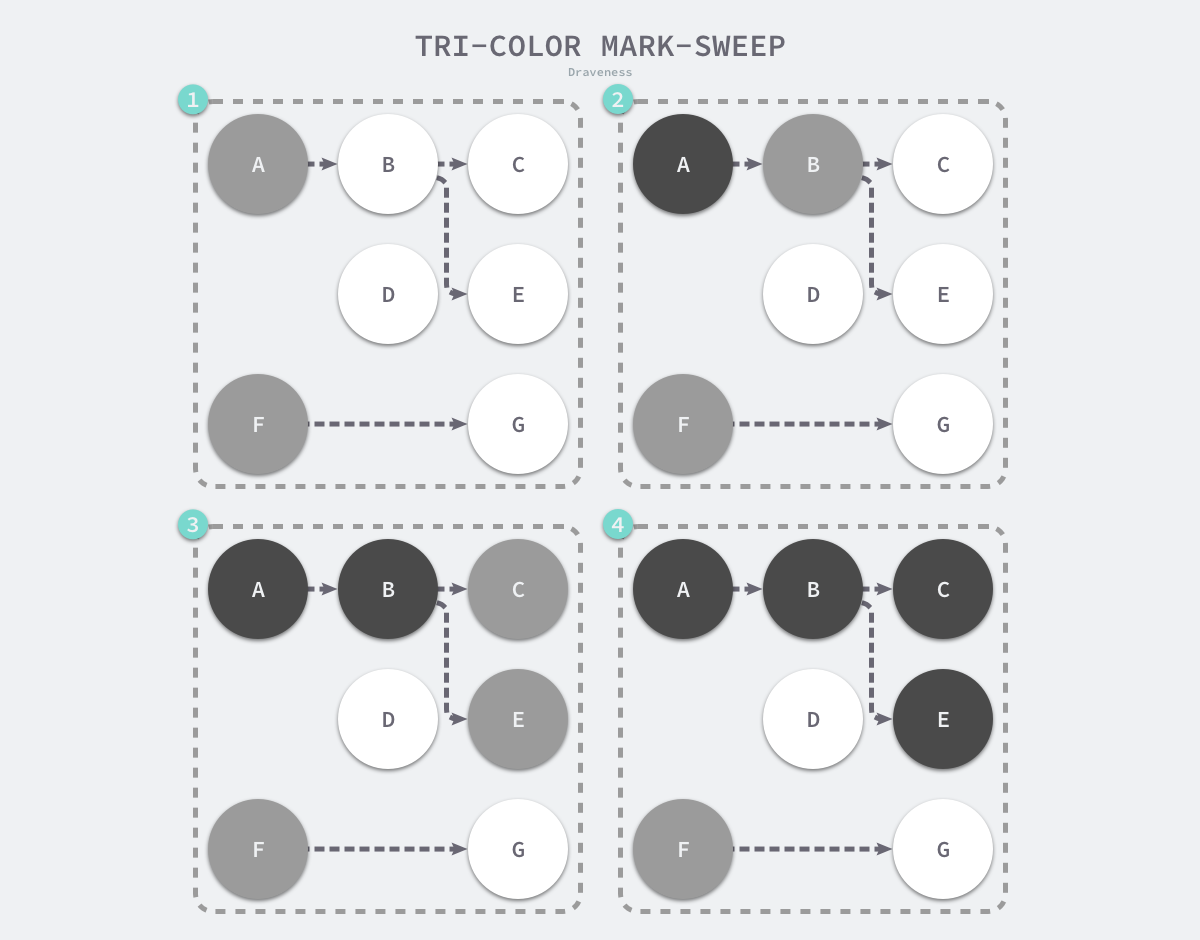
图 7-25 三色标记垃圾收集器的执行过程
三色标记垃圾收集器的工作原理很简单,我们可以将其归纳成以下几个步骤:
- 从灰色对象的集合中选择一个灰色对象并将其标记成黑色;
- 将黑色对象指向的所有对象都标记成灰色,保证该对象和被该对象引用的对象都不会被回收;
- 重复上述两个步骤直到对象图中不存在灰色对象;
当三色的标记清除的标记阶段结束之后,应用程序的堆中就不存在任何的灰色对象,我们只能看到黑色的存活对象以及白色的垃圾对象,垃圾收集器可以回收这些白色的垃圾,下面是使用三色标记垃圾收集器执行标记后的堆内存,堆中只有对象 D 为待回收的垃圾:
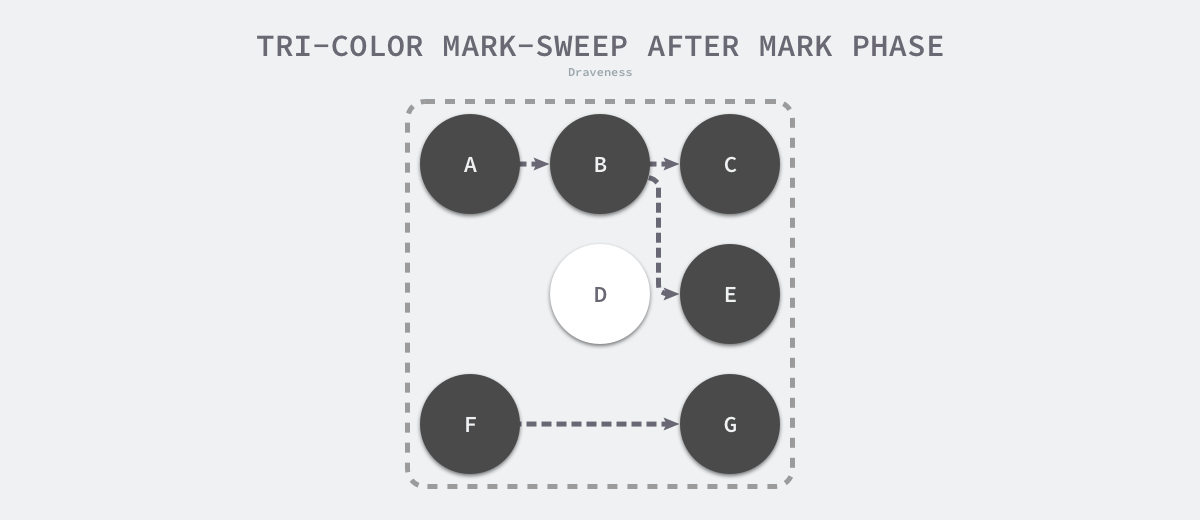
图 7-26 三色标记后的堆
因为用户程序可能在标记执行的过程中修改对象的指针,所以三色标记清除算法本身是不可以并发或者增量执行的,它仍然需要 STW,在如下所示的三色标记过程中,用户程序建立了从 A 对象到 D 对象的引用,但是因为程序中已经不存在灰色对象了,所以 D 对象会被垃圾收集器错误地回收。
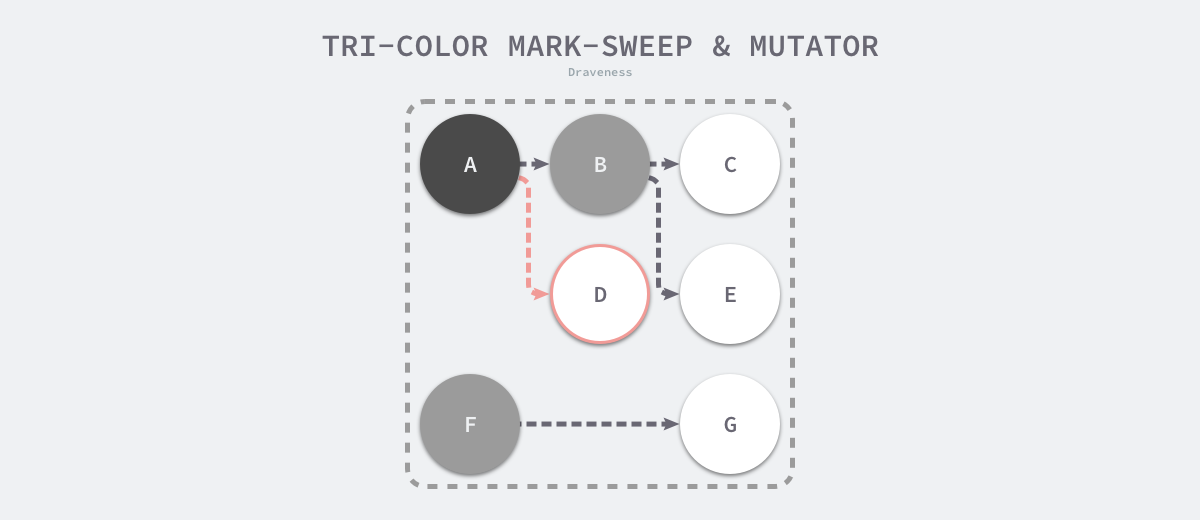
图 7-27 三色标记与用户程序
本来不应该被回收的对象却被回收了,这在内存管理中是非常严重的错误,我们将这种错误称为悬挂指针,即指针没有指向特定类型的合法对象,影响了内存的安全性5,想要并发或者增量地标记对象还是需要使用屏障技术。
屏障技术 #
内存屏障技术是一种屏障指令,它可以让 CPU 或者编译器在执行内存相关操作时遵循特定的约束,目前多数的现代处理器都会乱序执行指令以最大化性能,但是该技术能够保证内存操作的顺序性,在内存屏障前执行的操作一定会先于内存屏障后执行的操作6。
想要在并发或者增量的标记算法中保证正确性,我们需要达成以下两种三色不变性(Tri-color invariant)中的一种:
- 强三色不变性 — 黑色对象不会指向白色对象,只会指向灰色对象或者黑色对象;
- 弱三色不变性 — 黑色对象指向的白色对象必须包含一条从灰色对象经由多个白色对象的可达路径7;
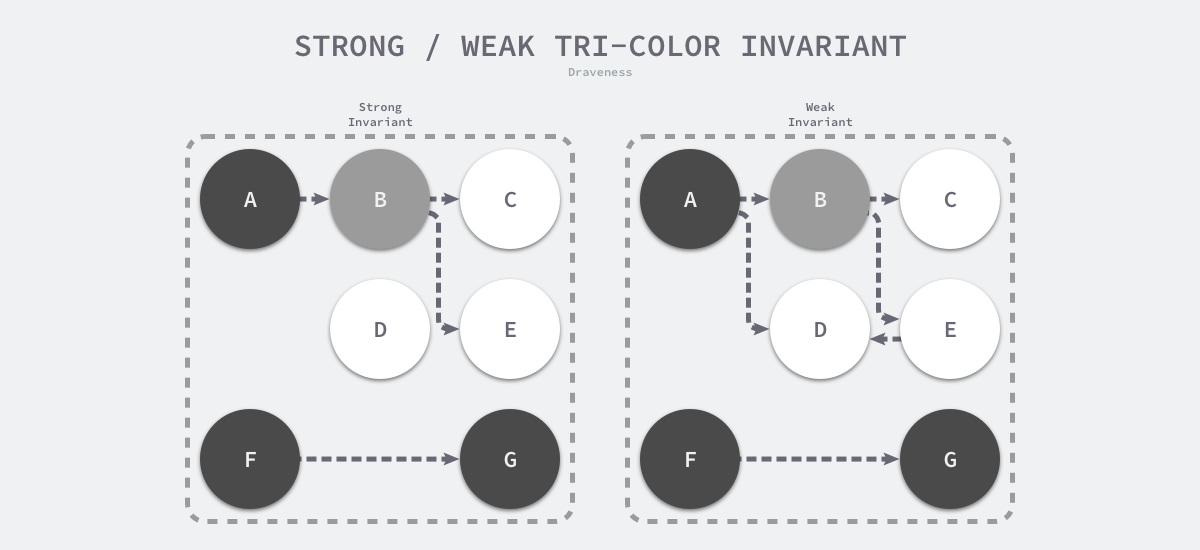
图 7-28 三色不变性
上图分别展示了遵循强三色不变性和弱三色不变性的堆内存,遵循上述两个不变性中的任意一个,我们都能保证垃圾收集算法的正确性,而屏障技术就是在并发或者增量标记过程中保证三色不变性的重要技术。
垃圾收集中的屏障技术更像是一个钩子方法,它是在用户程序读取对象、创建新对象以及更新对象指针时执行的一段代码,根据操作类型的不同,我们可以将它们分成读屏障(Read barrier)和写屏障(Write barrier)两种,因为读屏障需要在读操作中加入代码片段,对用户程序的性能影响很大,所以编程语言往往都会采用写屏障保证三色不变性。
我们在这里想要介绍的是 Go 语言中使用的两种写屏障技术,分别是 Dijkstra 提出的插入写屏障8和 Yuasa 提出的删除写屏障9,这里会分析它们如何保证三色不变性和垃圾收集器的正确性。
插入写屏障 #(指向的元素变灰)
Dijkstra 在 1978 年提出了插入写屏障,通过如下所示的写屏障,用户程序和垃圾收集器可以在交替工作的情况下保证程序执行的正确性:
上述插入写屏障的伪代码非常好理解,每当执行类似 *slot = ptr 的表达式时,我们会执行上述写屏障通过 shade 函数尝试改变指针的颜色。如果 ptr 指针是白色的,那么该函数会将该对象设置成灰色,其他情况则保持不变。
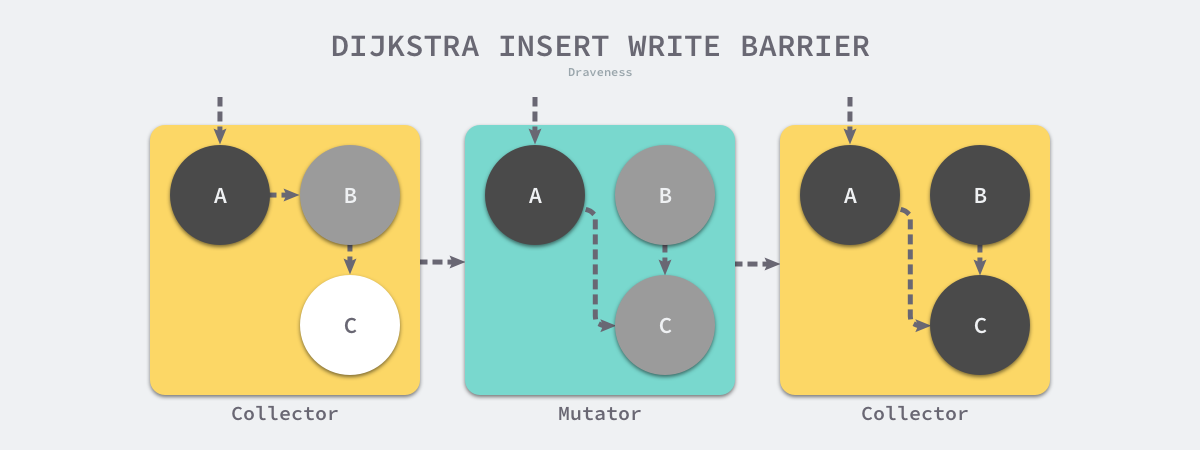
图 7-29 Dijkstra 插入写屏障
假设我们在应用程序中使用 Dijkstra 提出的插入写屏障,在一个垃圾收集器和用户程序交替运行的场景中会出现如上图所示的标记过程:
- 垃圾收集器将根对象指向 A 对象标记成黑色并将 A 对象指向的对象 B 标记成灰色;
- 用户程序修改 A 对象的指针,将原本指向 B 对象的指针指向 C 对象,这时触发写屏障将 C 对象标记成灰色;
- 垃圾收集器依次遍历程序中的其他灰色对象,将它们分别标记成黑色;
Dijkstra 的插入写屏障是一种相对保守的屏障技术,它会将有存活可能的对象都标记成灰色以满足强三色不变性。在如上所示的垃圾收集过程中,实际上不再存活的 B 对象最后没有被回收;而如果我们在第二和第三步之间将指向 C 对象的指针改回指向 B,垃圾收集器仍然认为 C 对象是存活的,这些被错误标记的垃圾对象只有在下一个循环才会被回收。
插入式的 Dijkstra 写屏障虽然实现非常简单并且也能保证强三色不变性,但是它也有明显的缺点。因为栈上的对象在垃圾收集中也会被认为是根对象,所以为了保证内存的安全,Dijkstra 必须为栈上的对象增加写屏障或者在标记阶段完成重新对栈上的对象进行扫描,这两种方法各有各的缺点,前者会大幅度增加写入指针的额外开销,后者重新扫描栈对象时需要暂停程序,垃圾收集算法的设计者需要在这两者之间做出权衡。
根对象在垃圾回收的术语中又叫做根集合,它是垃圾回收器在标记过程时最先检查的对象,包括:
-
全局变量:程序在编译期就能确定的那些存在于程序整个生命周期的变量。
-
执行栈:每个 goroutine 都包含自己的执行栈,这些执行栈上包含栈上的变量及指向分配的堆内存区块的指针。
-
寄存器:寄存器的值可能表示一个指针,参与计算的这些指针可能指向某些赋值器分配的堆内存区块。
删除写屏障 #(删除指向a的引用&&a为白则把a置为灰)
Yuasa 在 1990 年的论文 Real-time garbage collection on general-purpose machines 中提出了删除写屏障,因为一旦该写屏障开始工作,它会保证开启写屏障时堆上所有对象的可达,所以也被称作快照垃圾收集(Snapshot GC)10:
This guarantees that no objects will become unreachable to the garbage collector traversal all objects which are live at the beginning of garbage collection will be reached even if the pointers to them are overwritten.
该算法会使用如下所示的写屏障保证增量或者并发执行垃圾收集时程序的正确性:
上述代码会在老对象的引用被删除时,将白色的老对象涂成灰色,这样删除写屏障就可以保证弱三色不变性,老对象引用的下游对象一定可以被灰色对象引用。
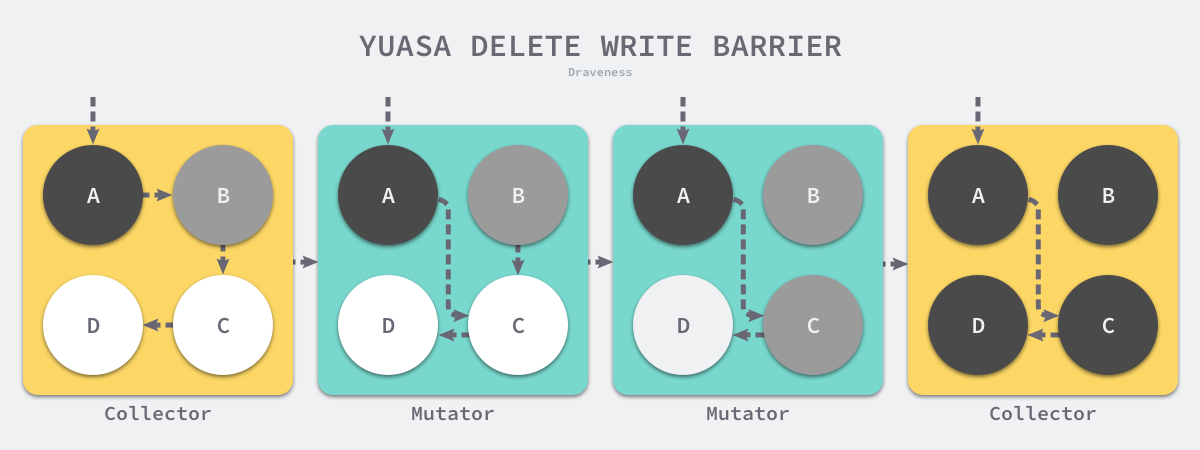
图 7-29 Yuasa 删除写屏障
假设我们在应用程序中使用 Yuasa 提出的删除写屏障,在一个垃圾收集器和用户程序交替运行的场景中会出现如上图所示的标记过程:
- 垃圾收集器将根对象指向 A 对象标记成黑色并将 A 对象指向的对象 B 标记成灰色;
- 用户程序将 A 对象原本指向 B 的指针指向 C,触发删除写屏障,但是因为 B 对象已经是灰色的,所以不做改变;
- 用户程序将 B 对象原本指向 C 的指针删除,触发删除写屏障,白色的 C 对象被涂成灰色;
- 垃圾收集器依次遍历程序中的其他灰色对象,将它们分别标记成黑色;
上述过程中的第三步触发了 Yuasa 删除写屏障的着色,因为用户程序删除了 B 指向 C 对象的指针,所以 C 和 D 两个对象会分别违反强三色不变性和弱三色不变性:
- 强三色不变性 — 黑色的 A 对象直接指向白色的 C 对象;
- 弱三色不变性 — 垃圾收集器无法从某个灰色对象出发,经过几个连续的白色对象访问白色的 C 和 D 两个对象;
Yuasa 删除写屏障通过对 C 对象的着色,保证了 C 对象和下游的 D 对象能够在这一次垃圾收集的循环中存活,避免发生悬挂指针以保证用户程序的正确性。
增量和并发 #
传统的垃圾收集算法会在垃圾收集的执行期间暂停应用程序,一旦触发垃圾收集,垃圾收集器会抢占 CPU 的使用权占据大量的计算资源以完成标记和清除工作,然而很多追求实时的应用程序无法接受长时间的 STW。
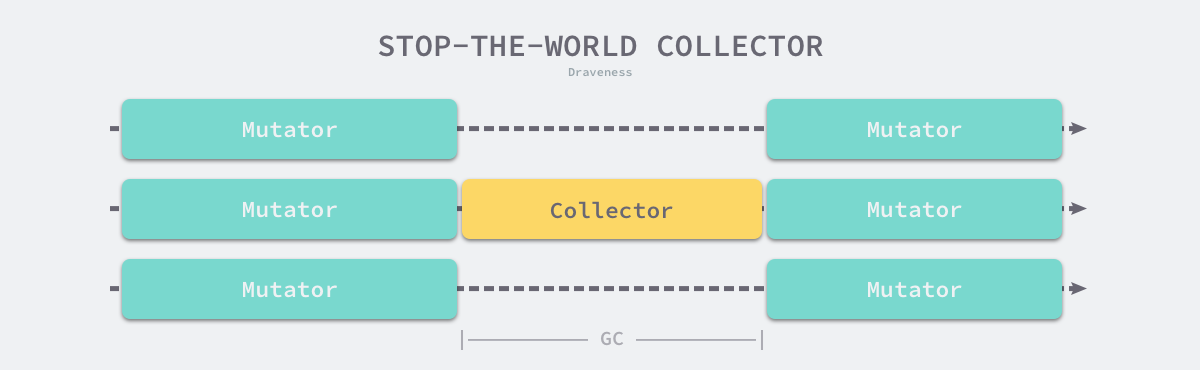
图 7-30 垃圾收集与暂停程序
远古时代的计算资源还没有今天这么丰富,今天的计算机往往都是多核的处理器,垃圾收集器一旦开始执行就会浪费大量的计算资源,为了减少应用程序暂停的最长时间和垃圾收集的总暂停时间,我们会使用下面的策略优化现代的垃圾收集器:
- 增量垃圾收集 — 增量地标记和清除垃圾,降低应用程序暂停的最长时间;
- 并发垃圾收集 — 利用多核的计算资源,在用户程序执行时并发标记和清除垃圾;
因为增量和并发两种方式都可以与用户程序交替运行,所以我们需要使用屏障技术保证垃圾收集的正确性;与此同时,应用程序也不能等到内存溢出时触发垃圾收集,因为当内存不足时,应用程序已经无法分配内存,这与直接暂停程序没有什么区别,增量和并发的垃圾收集需要提前触发并在内存不足前完成整个循环,避免程序的长时间暂停。
增量收集器 #
增量式(Incremental)的垃圾收集是减少程序最长暂停时间的一种方案,它可以将原本时间较长的暂停时间切分成多个更小的 GC 时间片,虽然从垃圾收集开始到结束的时间更长了,但是这也减少了应用程序暂停的最大时间:

图 7-31 增量垃圾收集器
需要注意的是,增量式的垃圾收集需要与三色标记法一起使用,为了保证垃圾收集的正确性,我们需要在垃圾收集开始前打开写屏障,这样用户程序修改内存都会先经过写屏障的处理,保证了堆内存中对象关系的强三色不变性或者弱三色不变性。虽然增量式的垃圾收集能够减少最大的程序暂停时间,但是增量式收集也会增加一次 GC 循环的总时间,在垃圾收集期间,因为写屏障的影响用户程序也需要承担额外的计算开销,所以增量式的垃圾收集也不是只带来好处的,但是总体来说还是利大于弊。
并发收集器 #
并发(Concurrent)的垃圾收集不仅能够减少程序的最长暂停时间,还能减少整个垃圾收集阶段的时间,通过开启读写屏障、利用多核优势与用户程序并行执行,并发垃圾收集器确实能够减少垃圾收集对应用程序的影响:
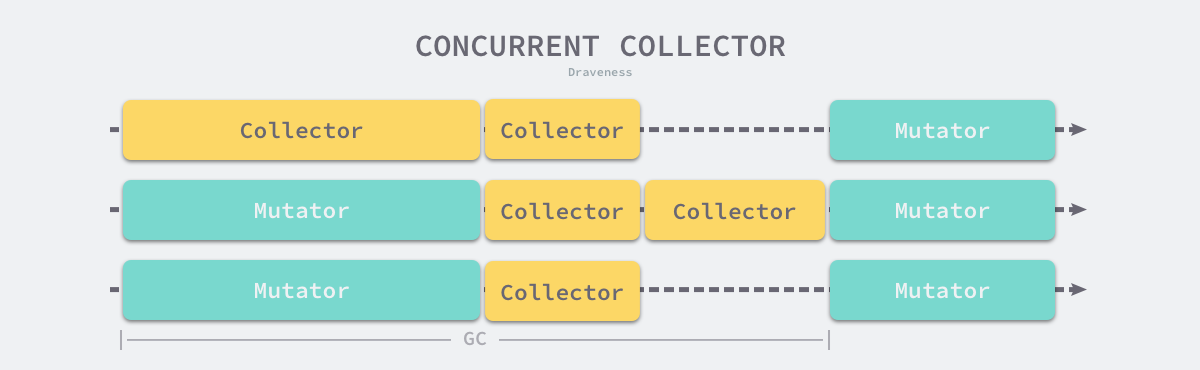
图 7-31 并发垃圾收集器
虽然并发收集器能够与用户程序一起运行,但是并不是所有阶段都可以与用户程序一起运行,部分阶段还是需要暂停用户程序的,不过与传统的算法相比,并发的垃圾收集可以将能够并发执行的工作尽量并发执行;当然,因为读写屏障的引入,并发的垃圾收集器也一定会带来额外开销,不仅会增加垃圾收集的总时间,还会影响用户程序,这是我们在设计垃圾收集策略时必须要注意的。
并发垃圾收集 #
Go 语言在 v1.5 中引入了并发的垃圾收集器,该垃圾收集器使用了我们上面提到的三色抽象和写屏障技术保证垃圾收集器执行的正确性。
混合写屏障
在 Go 语言 v1.7 版本之前,运行时会使用 Dijkstra 插入写屏障保证强三色不变性,但是运行时并没有在所有的垃圾收集根对象上开启插入写屏障。因为应用程序可能包含成百上千的 Goroutine,而垃圾收集的根对象一般包括全局变量和栈对象,如果运行时需要在几百个 Goroutine 的栈上都开启写屏障,会带来巨大的额外开销,所以 Go 团队在实现上选择了在标记阶段完成时暂停程序、将所有栈对象标记为灰色并重新扫描,在活跃 Goroutine 非常多的程序中,重新扫描的过程需要占用 10 ~ 100ms 的时间。
插入写屏障和删除写屏障的短板:
- 插入写屏障:结束时需要STW来重新扫描栈,标记栈上引用的白色对象的存活;
- 删除写屏障:回收精度低,GC开始时STW扫描堆栈来记录初始快照,这个过程会保护开始时刻的所有存活对象。
golang 1.5 之后已经实现了插入写屏障,但是由于栈对象赋值无法 hook 的原因,导致扫描完之后还有一次 STW 重新扫描栈的整机停顿,混合写屏障就是解决这个问题的。
Go 语言在 v1.8 组合 Dijkstra 插入写屏障和 Yuasa 删除写屏障构成了如下所示的混合写屏障,该写屏障会将被覆盖的对象标记成灰色并在当前栈没有扫描时将新对象也标记成灰色:
1、GC开始将栈上的对象全部扫描并标记为黑色(之后不再进行第二次重复扫描,无需STW),
2、GC期间,任何在栈上创建的新对象,均为黑色。
3、被删除的对象标记为灰色。
4、被添加的对象标记为灰色。
为了移除栈的重扫描过程,除了引入混合写屏障之外,在垃圾收集的标记阶段,我们还需要将创建的所有新对象都标记成黑色,防止新分配的栈内存和堆内存中的对象被错误地回收,因为栈内存在标记阶段最终都会变为黑色,所以不再需要重新扫描栈空间。
总结:
混合写屏障继承了插入写屏障的优点,起始无需 STW 打快照,直接并发扫描垃圾即可;混合写屏障继承了删除写屏障的优点,赋值器是黑色赋值器,扫描过一次就不需要扫描了,这样就消除了插入写屏障时期最后 STW 的重新扫描栈;混合写屏障扫描精度继承了删除写屏障,比插入写屏障更低,随着带来的是 GC 过程全程无 STW;混合写屏障扫描栈虽然没有 STW,但是扫描某一个具体的栈的时候,还是要停止这个 goroutine 赋值器的工作的哈(针对一个 goroutine 栈来说,是暂停扫的,要么全灰,要么全黑哈,原子状态切换);
混合写屏障机制
GC刚开始的时候,会将栈上的可达对象全部标记为黑色。
GC期间,任何在栈上新创建的对象,均为黑色。
上面两点只有一个目的,将栈上的可达对象全部标黑,最后无需对栈进行STW,就可以保证栈上的对象不会丢失。有人说,一直是黑色的对象,那么不就永远清除不掉了么,这里强调一下,标记为黑色的是可达对象,不可达的对象一直会是白色,直到最后被回收。
堆上被删除的对象标记为灰色
堆上新添加的对象标记为灰色
万一栈上的对象1引用了堆上的对象8,由于不触发混合写屏障机制,那对象8一直是白色的,最后不就被垃圾回收走了么,谁来保护它?这个情况是不会发生的,因为一个对象之所以可以引用另外一个对象,它的前提是需要另外一个对象可达,所以不会出现这种情况。
触发GC有俩个条件,一是堆内存的分配达到控制器计算的触发堆大小,初始大小环境变量GOGC,之后堆内存达到上一次垃圾收集的 2 倍时才会触发GC。二是如果一定时间内没有触发,就会触发新的循环,该触发条件由runtime.forcegcperiod变量控制,默认为 2 分钟。
总结
Golang v1.3之前采用传统采取标记-清除法,需要STW,暂停整个程序的运行。
在v1.5版本中,引入了三色标记法和插入写屏障机制,其中插入写屏障机制只在堆内存中生效。但在标记过程中,最后需要对栈进行STW。
在v1.8版本中结合删除写屏障机制,推出了混合屏障机制,屏障限制只在堆内存中生效。避免了最后节点对栈进行STW的问题,提升了GC效率
7.3 栈空间管理
7.3.1 设计原理
栈区的内存一般由编译器自动分配和释放,其中存储着函数的入参以及局部变量,这些参数会随着函数的创建而创建,函数的返回而消亡,一般不会在程序中长期存在,这种线性的内存分配策略有着极高地效率,但是工程师也往往不能控制栈内存的分配,这部分工作基本都是由编译器完成的。
寄存器
线程栈
逃逸分析
在编译器优化中,逃逸分析是用来决定指针动态作用域的方法5。Go 语言的编译器使用逃逸分析决定哪些变量应该在栈上分配,哪些变量应该在堆上分配,其中包括使用 new、make 和字面量等方法隐式分配的内存,Go 语言的逃逸分析遵循以下两个不变性:
- 指向栈对象的指针不能存在于堆中;
- 指向栈对象的指针不能在栈对象回收后存活;
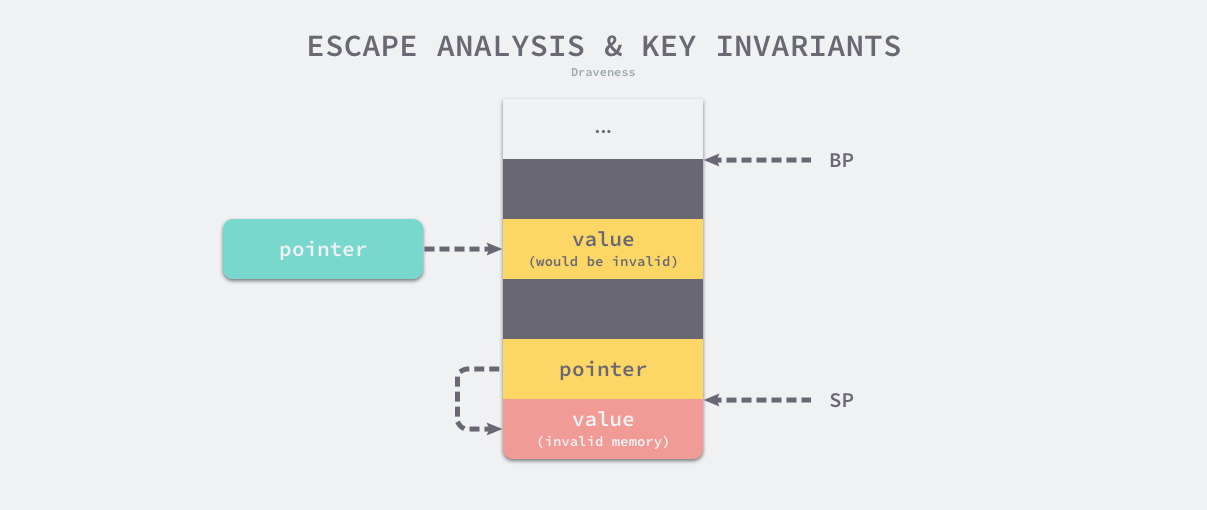
检查变量的生命周期是否是完全可知的,如果通过检查,则可以在栈上分配。否则,就是所谓的逃逸,必须在堆上进行分配。
Go语言虽然没有明确说明逃逸分析规则,但是有以下几点准则,是可以参考的。
逃逸分析是在编译器完成的,这是不同于jvm的运行时逃逸分析;
如果变量在函数外部没有引用,则优先放到栈中;
如果变量在函数外部存在引用,则必定放在堆中;
7.3.3 小结
栈内存是应用程序中重要的内存空间,它能够支持本地的局部变量和函数调用,栈空间中的变量会与栈一同创建和销毁,这部分内存空间不需要工程师过多的干预和管理,现代的编程语言通过逃逸分析减少了我们的工作量,理解栈空间的分配对于理解 Go 语言的运行时有很大的帮助。
8.1 插件系统
8.1.1 设计原理
Go 语言的插件系统基于 C 语言动态库实现的,所以它也继承了 C 语言动态库的优点和缺点,我们在本节中会对比 Linux 中的静态库和动态库,分析它们各自的特点和优势。
插件系统
8.2 代码生成
8.2.1 设计原理
Go 语言作为编译型的编程语言,它提供了比较有限的运行时元编程能力,例如:反射特性,然而由于性能的问题,反射在很多场景下都不被推荐使用。当然除了反射之外,Go 语言还提供了另一种编译期间的代码生成机制 — go generate,它可以在代码编译之前根据源代码生成代码。
8.2.2 代码生成
go generate 不会被 go build 等命令自动执行,该命令需要显式的触发,手动执行该命令时会在文件中扫描上述形式的注释并执行后面的执行命令,需要注意的是 go:generate 和前面的 // 之间没有空格,这种不包含空格的注释一般是 Go 语言的编译器指令,而我们在代码中的正常注释都应该保留这个空格4。
- 扫描 Go 语言源文件,查找待执行的
//go:generate预编译指令; - 执行预编译指令,再次扫描源文件并根据源文件中的代码生成代码;
整个生成代码的过程就是使用编译器提供的库解析源文件并按照已有的模板生成新的代码,这与 Web 服务中利用模板生成 HTML 文件没有太多的区别,只是生成文件的用途稍微有一些不同,
9.1 JSON
接口 #
JSON 标准库中提供了 encoding/json.Marshaler 和 encoding/json.Unmarshaler 两个接口分别可以影响 JSON 的序列化和反序列化结果:
在 JSON 序列化和反序列化的过程中,它会使用反射判断结构体类型是否实现了上述接口,如果实现了上述接口就会优先使用对应的方法进行编码和解码操作,除了这两个方法之外,Go 语言其实还提供了另外两个用于控制编解码结果的方法,即 encoding.TextMarshaler 和 encoding.TextUnmarshaler:
一旦发现 JSON 相关的序列化方法没有被实现,上述两个方法会作为候选方法被 JSON 标准库调用并参与编解码的过程。总的来说,我们可以在任意类型上实现上述这四个方法自定义最终的结果,后面的两个方法的适用范围更广,但是不会被 JSON 标准库优先调用。
标签 #
Go 语言的结构体标签也是一个比较有趣的功能,在默认情况下,当我们在序列化和反序列化结构体时,标准库都会认为字段名和 JSON 中的键具有一一对应的关系,然而 Go 语言的字段一般都是驼峰命名法,JSON 中下划线的命名方式相对比较常见,所以使用标签这一特性直接建立键与字段之间的映射关系是一个非常方便的设计。标签名和字段名会建立一一对应的关系,后面的标签选项也会影响编解码的过程
9.2 HTTP
9.3 数据库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号