

Daily Report 2012/11/10 陈伯雄(step 10)
昨天提到词频权重等的搜索问题,不能平等对待每一个关键词,为了解决这个问题我需要找到一个较为合理的策略:TF-IDF。
以下资料来源于维基百科:
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。
对于在某一特定文件里的词语 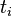 来说,它的重要性可表示为:
来说,它的重要性可表示为:
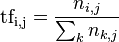
以上式子中  是该词在文件
是该词在文件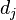 中的出现次数,而分母则是在文件中所有字词的出现次数之和。
中的出现次数,而分母则是在文件中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
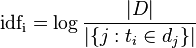
其中
- |D|:语料库中的文件总数
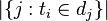 :包含词语的文件数目(即
:包含词语的文件数目(即 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用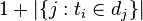
然后

某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
由于现有条件不足,无法得到tf(词频),因此我几天就针对idf(逆向文件频率)对倒排索引的建立进行了修改。增加了idf属性,明天将对search方法进行相应调整,对关键词k1,k2,k3,文档相关性程度=dTF1*IDF1*match(k1) + TF2*IDF2*match(2) + TF3*IDF3*match(k3) +...(TF值暂定为常值1,match函数参见组员刘宇翔Daily Report)。当然这样做也会使匹配的文档相关程度的精度下降(暂时没有找到更好的解决办法)。
TF-IDF其它相关:
TF-IDF的理论依据及不足(http://zh.wikipedia.org/wiki/TF-IDF)
TFIDF算法是建立在这样一个假设之上的:对区别文档最有意义的词语应该是那些在文档中出现频率高,而在整个文档集合的其他文档中出现频率少的词语,所以如果特征空间坐标系取TF词频作为测度,就可以体现同类文本的特点。另外考虑到单词区别不同类别的能力,TFIDF法认为一个单词出现的文本频数越小,它区别不同类别文本的能力就越大。因此引入了逆文本频度IDF的概念,以TF和IDF的乘积作为特征空间坐标系的取值测度,并用它完成对权值TF的调整,调整权值的目的在于突出重要单词,抑制次要单词。但是在本质上IDF是一种试图抑制噪声的加权 ,并且单纯地认为文本频率小的单词就越重要,文本频率大的单词就越无用,显然这并不是完全正确的。IDF的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能,所以TFIDF法的精度并不是很高。
此外,在TFIDF算法中并没有体现出单词的位置信息,对于Web文档而言,权重的计算方法应该体现出HTML的结构特征。特征词在不同的标记符中对文章内容的反映程度不同,其权重的计算方法也应不同。因此应该对于处于网页不同位置的特征词分别赋予不同的系数,然后乘以特征词的词频,以提高文本表示的效果。
