

先给出github上的代码链接以及项目需求
1. 项目简介
这个项目的需求可以概括为:对程序设计语言源文件统计字符数、单词数、行数,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。我个人对C++比较熟悉,各种文件输入输出流也会用,所以选择使用C++完成。当然C++也有它的缺陷,比如所有的字符串都要规定一个最大长度(可以选择用string,但我对于string的拼接,以及逐字符操作不是很熟悉,只好含泪用char[])。
这个项目其实也算是个小项目,一开始我觉得450分钟内肯定完成,就是一整天的事情。结果最后我实际上用了两天。两个原因吧,一个是我低估了这个项目的代码量。把这个项目的功能从基本功能到扩展功能实现了一遍,居然写了我五百多行代码(主要是有限状态机模型不会用,就自己按照逻辑硬刚下来了,功能倒是实现了)。第二个是连续工作实在太累了,到最后专注度直线下降,基本上有效编码时间只有百分之五十了。不过最后还是刚下来了,一定要找时间犒劳一下自己,吃顿好的。
项目的开发过程严格遵照软件工程的要求,从需求分析,到最后的测试,一个不落。这种开发方式,起步的速度会慢一些,不过写出来的代码非常好看,也易于修改。下面附上一张PSP表格。
PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟)|| PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟)
- | - | - | - | - | - | - | - | -
Planning | 计划 | 10 | 2||Development | 开发 | 340 | 597
· Estimate | · 估计这个任务需要多少时间 | 10 | 2 ||· Analysis|· 需求分析 (包括学习新技术)| 30 | 32
| | | | ||· Design Spec|· 生成设计文档| 60 | 60
Reporting | 报告 | 100 | 95 ||· Design Review|· 设计复审 (和同事审核设计文档)| 20 | 30
· Test Report | · 测试报告 | 60 | 60 ||· Coding Standard|· 代码规范 (为目前的开发制定合适的规范)| 20 | 5
· Size Measurement | · 计算工作量 | 10 | 5 ||· Design|· 具体设计| 60 | 45
· Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 ||· Coding|· 具体编码| 60 | 335
| | | | ||· Code Review|· 代码复审| 30 | 15
| | | | ||· Test|· 测试(自我测试,修改代码,提交修改)| 60 | 75
| | | | |||| |
| | | | |||合计| 450 | 694
2. 大体思路
这个项目的大体思路还是很明确的,我也在github上传了相关的设计文档。
我把这个项目分为六个模块:主函数、指令解析、递归搜索文件、统计准备工作、统计、结果输出。
主函数
主函数可以从控制台接收用户输入的指令,然后将这些指令拼接成一个完整的字符串并交给其它函数处理。
指令解析
指令解析可以提取用户输入的指令中的有效信息,从而决定了之后程序该执行哪些功能。尽管用户的指令可能是各种顺序的组合(比如,同一个指令,他既可以写成-w stoptest.c -e stoplist.txt,又可以写成 stoptest.c -e stoplist.txt -e),但是我们仍然可以找到一种简单的解析方式,可以处理各种形式下的有效命令。
我们顺序地去遍历存储了用户指令的字符串。如果遇到 '-' ,那么我们就知道它将会和下一个字符一起构成一个操作指令,那么我就立即检测下一个字符。如果下一个字符是 'e' 或 'o' ,那么我们还会知道,它接下来会紧跟着一个文件路径。当然,如果我们遇到的是 '-' 以外的可显示字符,那么它也将会是一个文件路径的首字符,只不过这个路径是待统计文件的所在路径。
从用户指令中提取路径相对简单,既然我们已经找到了路径的首字符,我们就可以顺序遍历,直到遇见一个不可显示字符位置,中间的一段就构成了我们要提取的路径。
递归搜索文件
解析了用户指令以后,我们这里将面临第一个分支。如果用户指令中没有出现 "-s",那么问题变得很简单,用户给出的文件路径对应的就是我们唯一要统计的那个文件;但是如果用户指令中出现了 "-s" ,那么我们就需要得到用户指定路径下所有符合条件的文件名。
这个模块需要用到递归查找文件夹里所有文件的算法和含有通配符的字符串匹配算法。有了这两个武器,我们就可以先找到一个目录下的所有文件,然后再逐一和用户给定的文件名进行匹配,然后把匹配成功的文件名、文件路径存放在一个文件链表中。
令我头痛的是,用户给出的路径通常都是 "F:\codes\java\try\src*.c" 这种形式。也就是说,文件夹的路径和文件名存储在同一个字符串里。我需要把他们分开。这里我从字符串最后一个字符逆序遍历,找到第一个 '\' 字符后,它的左边就是文件夹路径,它的右边是文件名,分别拷贝到两个字符串,就完成了路径的分割。
统计准备工作
在这一步中,我们需要得到打开停用词文件,读取其中所有的停用词,然后建立一个链表去存储这些停用词。我们不用管到底用户有没有要求启用停用词,反正我们知道,只要用户没有给出停用词文件所在路径,我们就找不到这些停用词。具体的文件读取策略,我使用的是逐行读取,逐词读取。
接下来,我们只要利用停用词表和待统计文件的路径信息,就能得到统计结果了。
统计
这个模块就是项目的核心了。一开始我觉得很简单,因为字符统计、单词统计、行统计是C语言最基本的算法之一,基本上就是逐字符读取一遍文件,每次读取,字符数+1;字符由可显示字符变为不可显示字符,单词数+1;读到 '\n' ,行数+1。
然而坑的是那些扩展功能,也就是对于代码行、注释行、空行的判断。这里我建立了一个状态模型。现在,每次读取一个字符之后,根据字符类型(是否可显示,是否是换行符,是否是 ' / ' 或者 ' * ' )状态就会进行迁移。当遇到换行符时,就会根据当前所处的状态进行结算。举个例子:如果当前处于代码行状态,那么代码行就会+1;如果当前处于临界行1状态,那么还要判断这一行是否已经经历过临界行1(因为 "/" 和 "{/**/}" 这两行最终都会停留在临界行1,但前者是空行,后者是代码行)。
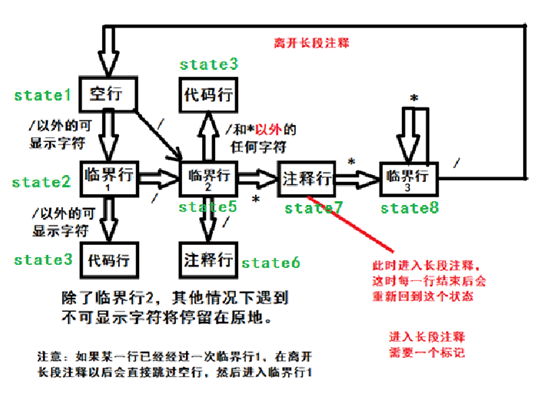
这个状态迁移模型被我搞得相当繁琐,很多地方的判断不能单单根据当前所处的状态判断。如果你选择直接使用我这一段代码,我不保证会不会出现一些诡异的情况(不过应对正常的用例还是绰绰有余的),我还是建议你自己写一个。也许你可以设置多一些状态,我之所以只设置了这么几个状态,是因为我觉得用画图软件画状态图是在太蠢了,最后实在画不下去了,就草草收手。总之,如果你有更好的状态模型,欢迎在下面评论区提出来。
结果输出
结果输出相对是一个比较温柔的模块(当然没有主循环那么温柔),唯一的分支是查看一下用户是否给出了 "-o" 指令,如果有,我们需要改变默认的结果文件输出路径。最后的输出需要用到一些重定向的知识,不过这个并不难。最后按照需求中规定的顺序,把用户想要的统计量输出就大功告成了。
具体的定义
上述所有模块涉及到的函数头和结构体的定义在下面给出。
//这个结构体用于记录指令解析的结果
struct Command {
bool _c; //是否统计字符数
bool _w; //否统计单词总数
bool _l; //是否统计总行数
bool _o; //是否将结果输出到指定文件
bool _s; //是否递归处理目录下符合条件的所有文件
bool _a; //是否统计代码行/空行/注释行
bool _e; //是否开启停用词表
char filePath[MAX_PATH_LENGTH]; //文件路径
char outFile[MAX_PATH_LENGTH]; //输出结果路径
char stopFile[MAX_PATH_LENGTH]; //停用词路径
};
//这个链表用于记录所有要进行统计的文件信息,当然如果用户没有输入-s指令,那么这个链表就只有一个节点了
struct SourceFile {
char filePath[MAX_PATH_LENGTH]; //路径用于寻找文件、输出最后的文件名
char fileName[MAX_PATH_LENGTH]; //文件名用于进行通配符匹配
int charNum;
int wordNum;
int lineNum;
int blankLineNum;
int codeLineNum;
int noteLineNum;
SourceFile *next;
};
//这个链表用于记录所有的停用词
struct StopWord {
char word[MAX_STOPWORD_LENGTH];
StopWord *next;
};
void mainLoop(); //程序主循环
void analyseCommand(char commandStr[], Command &command); //解析用户指令
void getFileName(char path[], SourceFile *head); //递归得到目录下所有文件
void wordCount(SourceFile *head, char stopPath[]); //单词统计的预备工作
void wordCount(SourceFile *sourceFile, StopWord *head); //单词统计
void outPut(SourceFile *head, Command &command); //向文本输出
////////////////////////////////////////////////////////////////////////////////////////////////////////////
//本段为递归查找目录函数
#include<io.h>
void getFiles(string path, string path2, SourceFile *head, char* pattern);
////////////////////////////////////////////////////////////////////////////////////////////////////////////
//本段为引用的字符串匹配(带通配符)函数
#include <ctype.h>
int WildCharMatch(char *src, char *pattern, int ignore_case);
////////////////////////////////////////////////////////////////////////////////////////////////////////////
3. 部分代码分析
主函数函数main(int argc, char *argv[])是组织程序按顺序执行的核心。它对于你理解程序的架构很有帮助,尽管它很简单,但是我还是把它放在这里,也便于以对照着去理解上下文。
int main(int argc, char *argv[]) {
char commandStr[MAX_COM_LENGTH] = "";
for(int i=1;i<argc;i++){ //将用户输入的指令拼接成一个完整的字符串传给程序
strcat(commandStr, argv[i]);
strcat(commandStr, " ");
}
Command command;
analyseCommand(commandStr, command); //解析用户指令
SourceFile *head = new SourceFile();
if (command._s) getFileName(command.filePath, head); //递归寻找目录下的文件
else { //否则直接利用相对路径查找文件
SourceFile *p = new SourceFile();
p->next = head->next;
head->next = p;
strcpy(p->fileName, command.filePath);
strcpy(p->filePath, command.filePath);
}
wordCount(head, command.stopFile); //统计单词数
outPut(head, command); //结果输出到文件
delete head;
return 0;
}
还有一个重要的事情我们前面没有提到,那就是在文件统计时,一般来说我们习惯于使用下面这样的代码来结束我们的逐字读取:
if((c = in.get() == EOF)) break;
它表示当我们读到文件结束标志时,就跳出循环。但是这里存在着一个问题,前面我们提到过,“字符由可显示字符变为不可显示字符,单词数+1。”在这里,字符也可能是由可显示字符变为不可显示字符,但是我们的循环直接结束了,也就是说,这个单词没有统计到!同样,在统计行数时,我们也是仅在遇到 '\n' 时才会进行行数的结算,那这里也会造成遗漏。所以我们将这里进行了扩写:
c = in.get();
if (c == EOF) {
//在文件结尾处,还要对单词数、行数等进行最后的结算
if (wordFlag) {
sourceFile->wordNum++;
}
if (state == 1) {//这里是对行数进行结算,仍然是根据状态迁移模型
if (hasPassState2) sourceFile->noteLineNum++;
else sourceFile->blankLineNum++;
}
if (state == 2) {
if (hasPassState2) sourceFile->noteLineNum++;
else sourceFile->blankLineNum++;
}
if (state == 3) sourceFile->codeLineNum++;
if (state == 5) {
if (hasPassState2) sourceFile->codeLineNum++;
else sourceFile->blankLineNum++;
}
if (state == 6 || state == 7 || state == 8) sourceFile->noteLineNum++;
if (strcmp(currentWord, "") != 0) {//不要忘了对于停用词表也要重新结算
StopWord *pH = head->next;
while (pH != NULL) {
if (strcmp(currentWord, pH->word) == 0) {
sourceFile->wordNum--;
break;
}
pH = pH->next;
}
}
break;
}
由于这段代码没有给出上下文,所以理解起来有些麻烦(主要还是我的状态迁移模型写得太差了),我的建议还是详细地在github上通读整个代码。
4. 测试设计
根据用户可能输入的各种不同指令,我们将可能的分支用流程图来表示。

显然,可以看出它的环复杂度为8。于是,首先我设计了8个相互独立的测试用例。
测试编号 | 测试内容 | 用户指令
- | - | - | -
1|基本字符测试|–c char.c
2|不可显示字符测试|-c charwithspace.c
3|单词和行数测试|-w -l wordtest.c
4|扩展行数测试|-a atest.c
5|停用词测试|-w stoptest.c -e stoplist.txt
6|文件夹遍历测试|-s -w -a C:\Users\Star\Desktop\SoftTest*.c
7|输出测试|-s -a -w -c -l C:\Users\Star\Desktop\SoftTest*.c -o output.txt
8|全套测试|-s -a -w -c -l C:\Users\Star\Desktop\SoftTest*.c -o output.txt -e stoplist.txt
全套测试是为了查看,如果将程序里支持的所有功能都同时使用会不会得出正确结果。我们期望的结果是像这样,得到一个详细的文档,里面记录了给定路径下所有形如 "*.c" 的文件中,字符数、单词数、行数和特殊行数:

然而实际的输出却很惨——目标文件并未出现任何字符。
经过了一番断点调试,我终于找到了原因。由于指令过长,没有设置足够的数组长度来存储指令,导致解析失败。之后,我将指令最大长度设置为150,这下得到了正确结果。
这些测试用例都以及相应的测试结果可以在我给出的github链接中找到。
当然,我并不认为通过了这八个互相独立的测试用例,就能确保程序正确。于是我又补充了两个测试用例,他们十分特殊,跟之前八个都不一样。
测试编号 | 测试内容 | 用户指令
- | - | - | -
9|错误指令测试|-c -d char.c charwithspace.c
10|错误指令测试|-e -c char.c
错误指令测试是想看看如果用户输入了错误的指令,程序会不会崩溃。事实证明,程序可以一定程度上地分析出用户指令,虽然不会得出用户期望的输出,但是至少它不会崩溃,我们认为这是程序健壮性良好的一个体现。
具体的测试方法,就是在编译环境里给程序入口传递参数,然后编译器就可以正确地将我们预设的指令传给程序。我们只需要在目标输出文件内找到实际输出,和我们的期望输出进行比对即可。

当然,也可以使用测试脚本来测试,测试脚本十分方便,可以让系统批处理地执行exe文件,并且自动传参。它的部分代码看上去是这样的:
start wc.exe wc.exe -s -w -a C:\Users\Star\Desktop\SoftTest\*.c
start wc.exe wc.exe -s -a -w -c -l C:\Users\Star\Desktop\SoftTest\*.c -o output.txt
总结
总体来说,由于这次的项目相对简单,而且又严格遵照了软件工程的开发要求,等所有模块的思路都清晰了以后再开始编码,所以测试过程十分愉快,基本上除了一些很容易改正的粗心问题,没有别的思路上或者结构上的问题。
可怜的是我这么一个美好的周末就这样废了:(


 浙公网安备 33010602011771号
浙公网安备 33010602011771号