中文拼写检查任务方法初步简单总结
中文拼写检查任务方法初步简单总结 (V1)
一、任务简述
中文拼写检查主要关注与对字或词级别的错误的纠正(并不涉及语法上的错误),任务的初步目标是寻找到出现错误的位置,然后是对错误进行纠正。
同时,为了简化问题,很多测评往往只关注如下情况的任务
- 纠错目标多为音近字(多用于ASR结果的纠正)或者形近字(多用于OCR结果的纠正),不太考虑偶然情况的错误(但也会存在)
- 纠错前后语句长度不会发生变化(即不会发生增删)
举例:

表一 拼写检查任务示例
但是,如果考虑真实数据集,文本纠错任务可能会遇到以下困难:
- 一句文本中可能出现多出错误(此时会出现使用错误的上下文应用在语言模型中就行纠错的情况,增大纠错的难度)
- 常识性错误或命名实体性质的错误(比如“我打算暑假去金字塔旅游”--->“我打算暑假去金字塔旅游”)或者如表一中第四条出现的情况,简单说就是正确的词用在了错误的地方。
- 训练集很难包含所有的可能错误情况,而让模型去纠正没有见过的错误是很困难的
二、数据准备工作
1.目前的开源数据集
(1) SIGHAN 2013-2015数据集
该数据集的预料来源为中国台湾的留学生/中小学生作文,修正语法、语义错误后得到源端文本,再经由人工 对错别字位置、纠正结果进行标注后获得目标端文本。初始数据集为繁体字,可以使用OpenCC等工具转换成简体字数据集(但转换过程中可能会较多的噪声)
同时,该数据集同时开源了一份混淆集,给出了汉字的易混淆字。
(2) Wang 等人生成的一份伪数据
该数据集是由人民日报和开源的中文演讲数据集加入错误后生成的伪数据集。
(3) 测评开源数据集
-
本次测评开放的训练数据集(目前还未放出)
https://github.com/Arvid-pku/NLPCC2023_Shared_Task8
已开放,多为新闻文本
-
CCL-2022测评任务给出的数据集YACLC-CSC(数据量很小)
数据集整合下载:
https://blog.csdn.net/zhaohongfei_358/article/details/127093838
提供了简体字版的SIGHAN数据集和Wang开源的伪数据集
2.进行数据增强工作
(1)考虑字音相似生成数据
根据文字的拼音,根据声母、韵母的相似度分别生成同声字符集、同韵字符集。再由得到的字符集,随机替换正确文本语录,得到训练用的语料库。
(2)按一定规则根据混淆集随机替换正确语料(或者已有CSC任务语料)得到扩充数据集。(CCL-2022 rank1所使用方法)
具体规则如下:
- 可使用维基百科数据集、微信语料库、新闻语料库等作为原始未标注数据集
- 使用分词算法将原句子进行分词处理。
- 使用序列标注模型对所有词语进行属性标注、
- 对被序列标注模型所标注出的人名,地名类词语(如坸坸酒店,坸坸公司)进行不设错处理, 即不会被替换为错字。同样被过滤的还有非中文词和停用词。
- 随机按比例抽取字词进行改动。如该词在混淆集中,15%不改动,15%概率随机改动,70%概率在混淆集中随机抽取改动。如该词不在混淆集中则不改动。
3.辅助数据集
(1)谐音字混淆集
https://github.com/LiangsLi/ChineseHomophones
(2)形近字混淆集
https://github.com/wdimmy/Automatic-Corpus-Generation/blob/master/corpus/confusion.txt
(3)字音字形混淆数据集
https://github.com/FDChongLi/TwoWaysToImproveCSC/tree/main/SoftmaskedBert/save
(4)字音特征
https://github.com/whgaara/tensorflow-faspell/blob/master/data/char_meta.txt
https://link.csdn.net/?target=https%3A%2F%2Funicode.org%2FPublic%2FUNIDATA%2FUnihan.zip
(5)字形特征(拆字)
https://raw.githubusercontent.com/cjkvi/cjkvi-ids/master/ids.txt
注:github上还有其他的开源的混淆集等数据集,同时使用开源工具pypinyin可以得到字符的拼音序列。
三、输入输出与模型
1.输入特征
对于输入,多使用三方面的特征
- 字符序列
- 拼音特征
- 字形特征
(1) 字符特征的编码
将字符序列转化为特征序列后,与其他特征融合,作为输入(一般使用词向量,也有使用编码器,如bert,编码成特征序列)
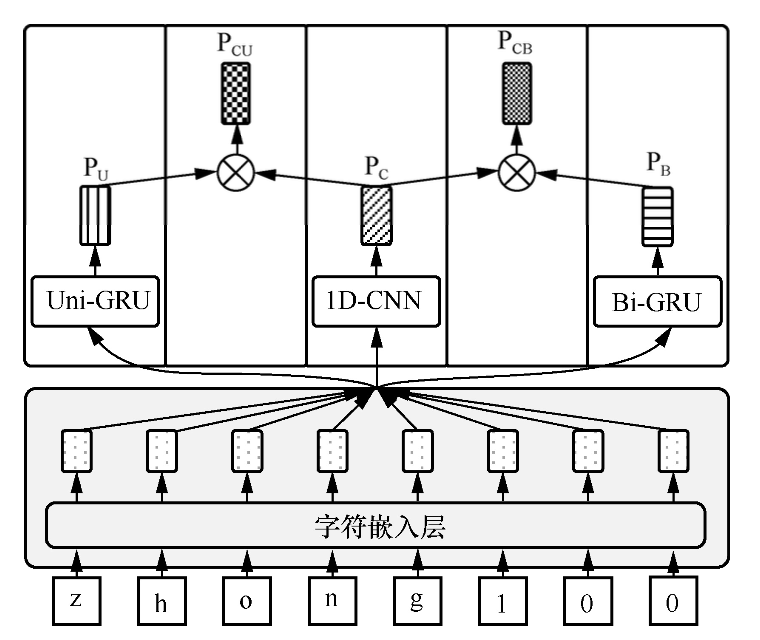
(2) 拼音特征的使用
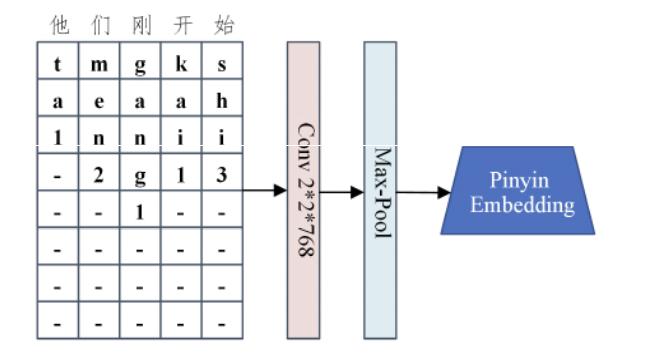
首先,要将拼音序列补齐或截断成相同长度的序列,然后再进行进一步处理
- 使用卷积神经网络提取特征,方法如下图
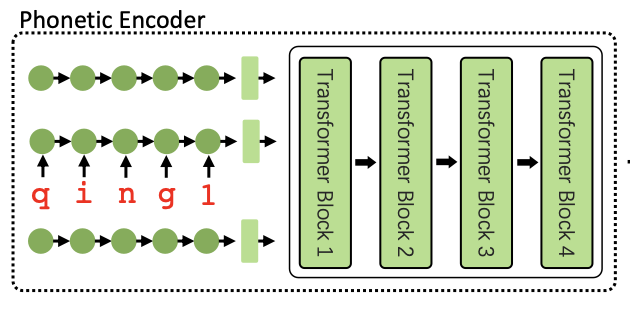
* 使用编码器编码特征
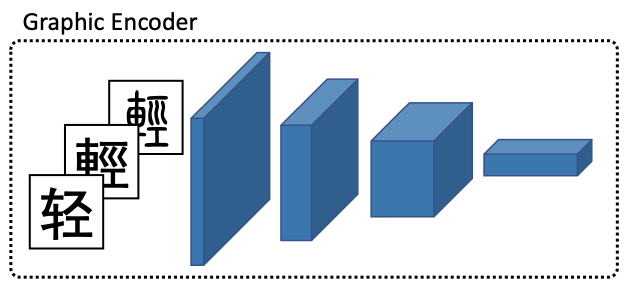
#### (3) 字形特征的使用
- 使用卷积神经网络提取特征
-
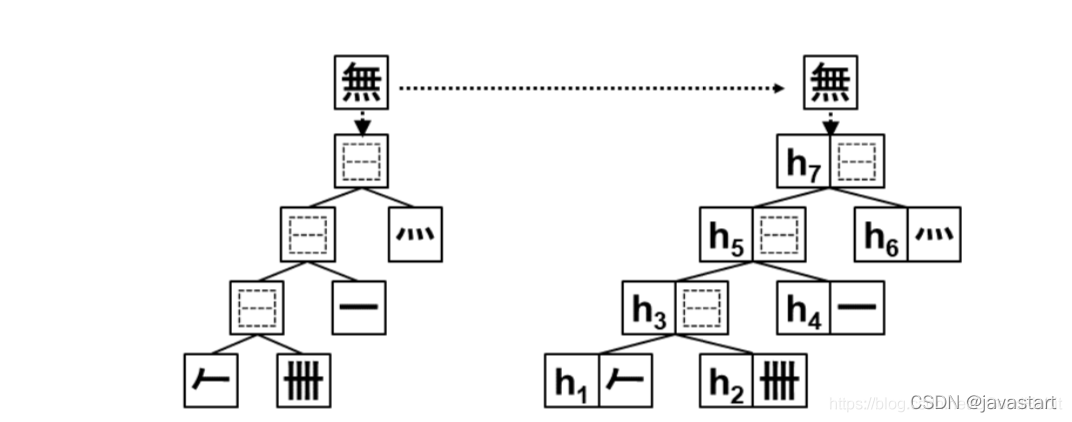
对拆字后对结果进行编码
基于treeLSTM模型结构,用字的IDS拆分结构作为treeLSTM的输入,学习字向量表示
-
字形嵌入
受Glyce的启发,有人使用包含汉字的位图信息的字体文件,例如使用仿宋、行楷和楷书3种中文字体,并将每种字体实例化成大小为24*24的图像,将三种字体的信息通过嵌入层转化成一维表示,再通过全连接层得到字形嵌入。
(4) 特征的融合
-
SpellGCN 提出使用图神经网络对字音和字形结构关系进行学习,并且将这种字音字形的向量融入到字的embedding中,在纠错分类的时候,纠错更倾向于预测为混淆集里的字。
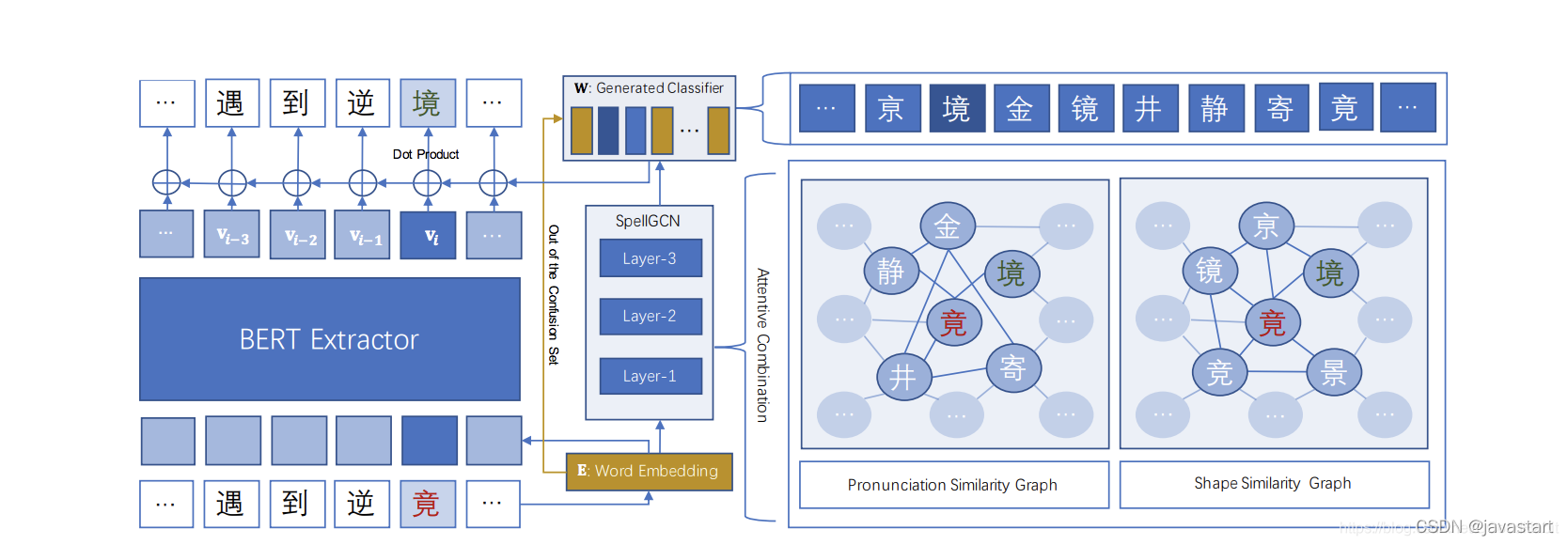
-
使用全连接层融合特征
-
基于错误概率的特征融合
其中pi是检错网络计算出的每个字的错误概率,ei为词嵌入特征,efi为语音和字形特征
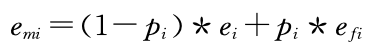
2.常用的模型
(1) 编码器解码器结构
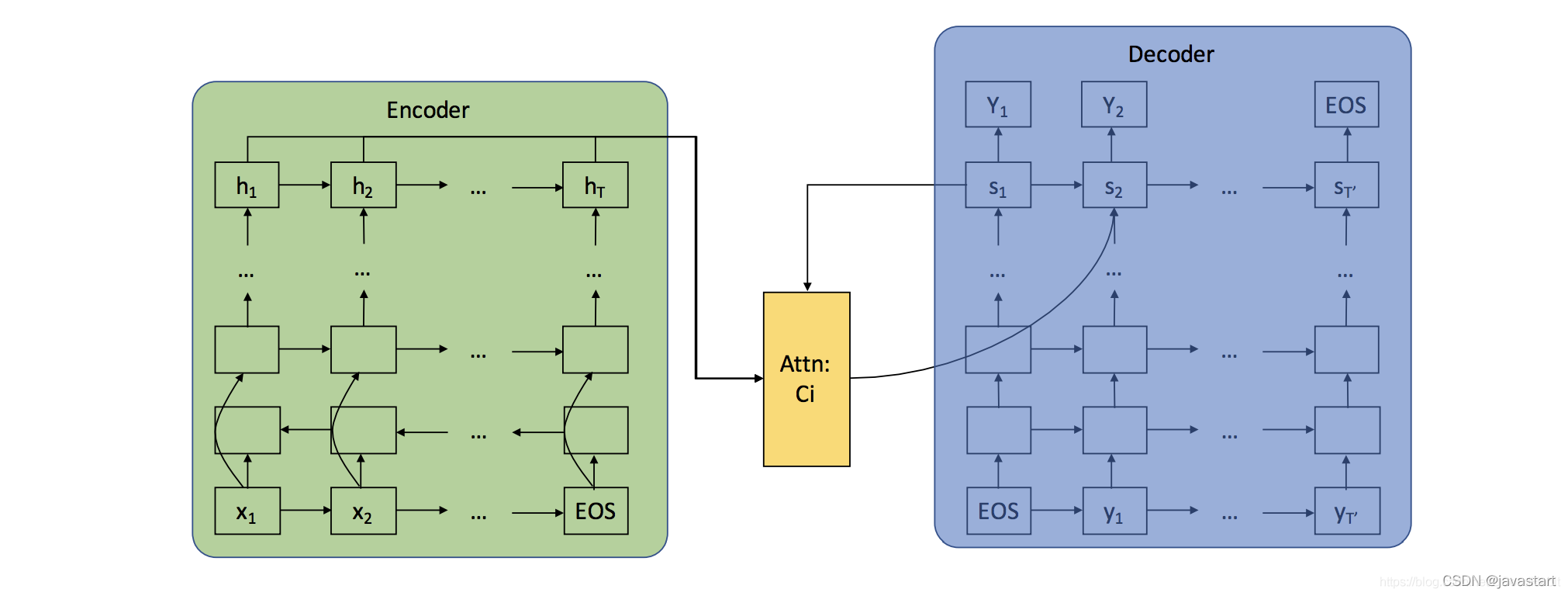
编码器解码器结构的文本纠错
如图所示,把文本拼写检查纠正任务当作文本翻译任务,编码器编码待纠错文本,解码器解码得到纠正后的文本。
(2) 基于bert的结构
由bert生成候选集,再经过过滤网络从后续集中挑选合适的纠正结果(比如:选bert生成概率前k个概率中,包含在混淆集中且最大的概率,若前k个中不存在有在混淆集中的,则不进行纠错)
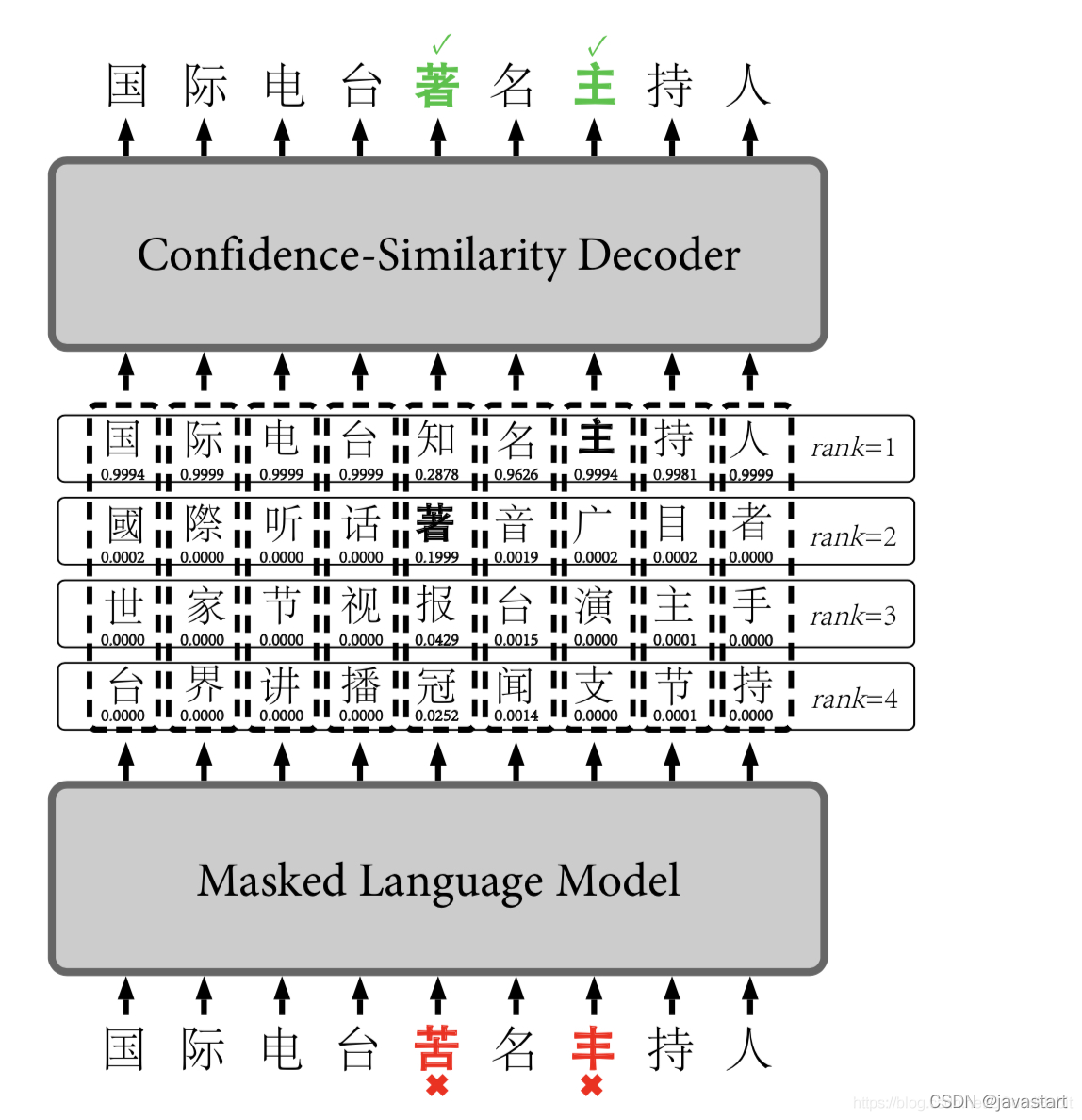
基于bert+置信度相似度解码
(3) 分为检错网络和纠错网络
举例1:
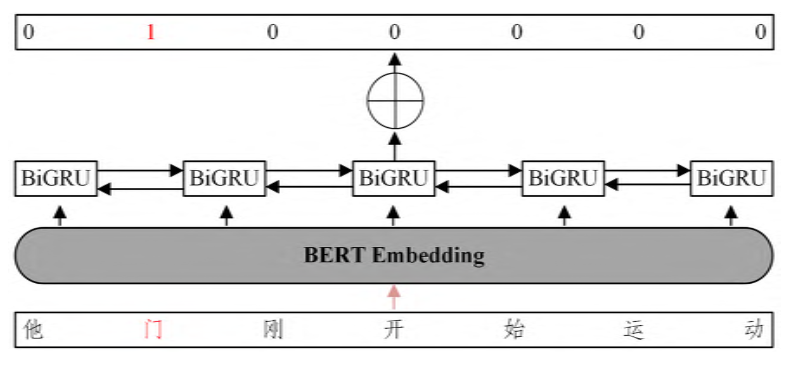
检错网络
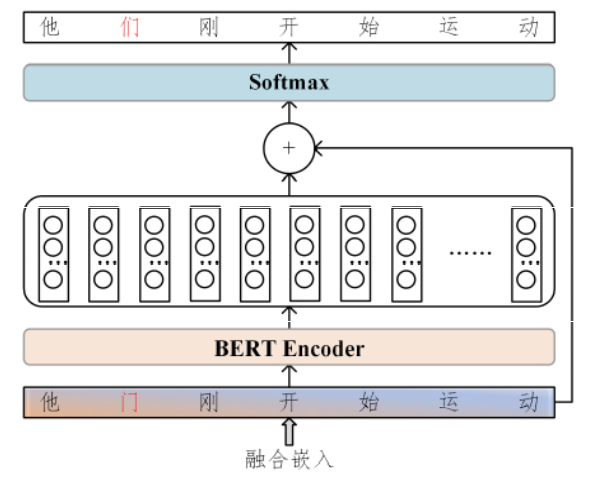
纠错网络
举例2:
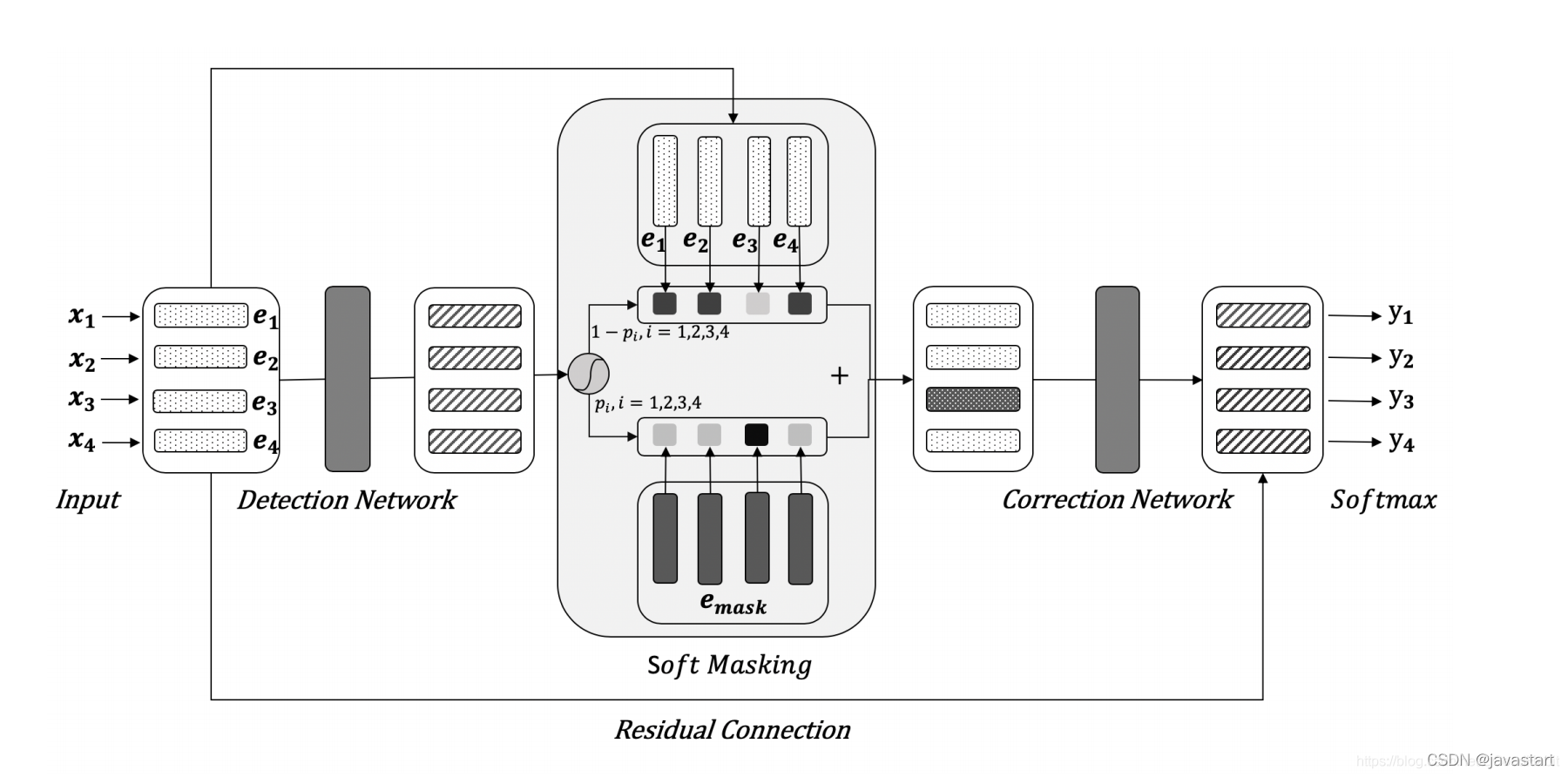
Soft-Mask BERT (字节跳动)
在错误检测部分,通过BiGRU模型对每个输入字符进行错误检测,得到每个输入字符的错误概率值参与计算soft-masked embedding作为纠错部分的输入向量,一定程度减少了bert模型的过纠问题,提高纠错准确率。
四、CCL-2022 前三方案
1. rank1 方案

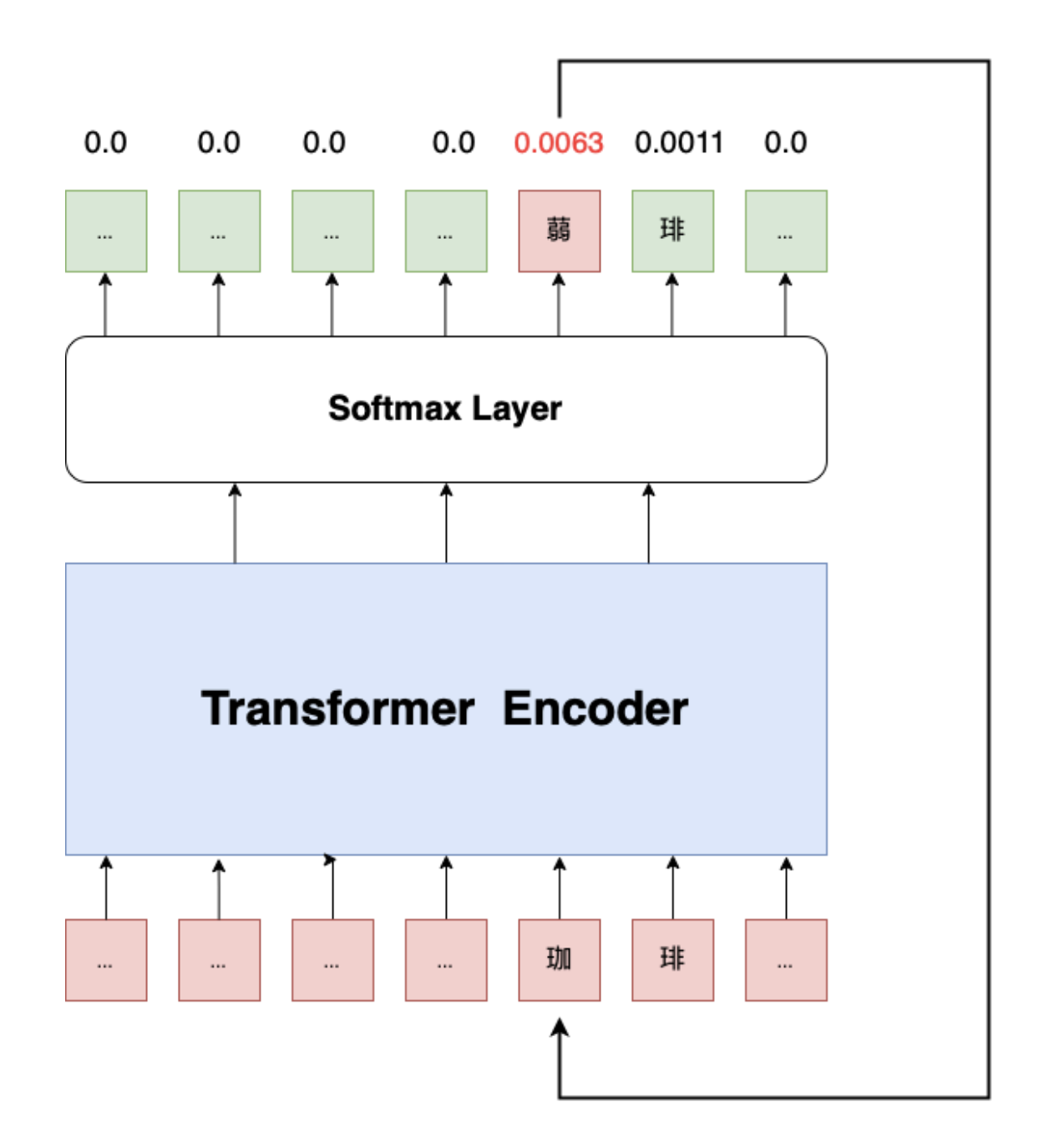
模型结构
主要使用了以下方法:
(1)结合拼音特征和字符序列特征
(2)基本使用base-bert模型
(3)为了解决一句话中存在多处错误的问题,采用多轮纠错的方法,每次只纠正一个错误。
(4)为了解决“用正确的字替换正确的字”的情况,通过计算修改前后的困惑度来减少误召回情况
(5)为了解决命名实体的纠正问题,训练了一个基于bert+crf的序列标准模型
(6)最后训练了一个严格的n-gram模型,来进行最后的纠正
2. rank2 方案
(1)该方案主要尝试了ReaLiSe (Xu et al., 2021)、CRASpell (Liu et al., 2022)、Macbert4csc (Cui et al., 2020)、SpellGCN (Cheng et al., 2020)、ReaLiSe算法等多个模型,并对结果进行了融合。
(2)融合方法:把各个模型的纠错结果加入候选集,通过计算每个候选词的得分,从而得到最优结果。通过调研,决定采用N-gram计算替换每个候选词后句子的困惑度得分来决定选择最终结果。分别训练了字级别的5-gram模型和词级别 的3-gram模型。在句子的困惑度的得分计算时,综合考虑字级别和词级别的得分,以此提高结 果的可信度。
(2)将传统CSC任务的Detection阶段单独拆出来做一个简单的判断句子中每个位置 对错的二分类任务,以此来提高模型的检错性能,尽可能的把所有的错误位置都检查出来。 在纠错阶段我们结合N-gram计算困惑度进行纠错,同时设置了一些过滤规则,这样引入了 一些额外知识保证纠错阶段的可控性,也使得纠错阶段的性能得以提高
3. rank3 方案
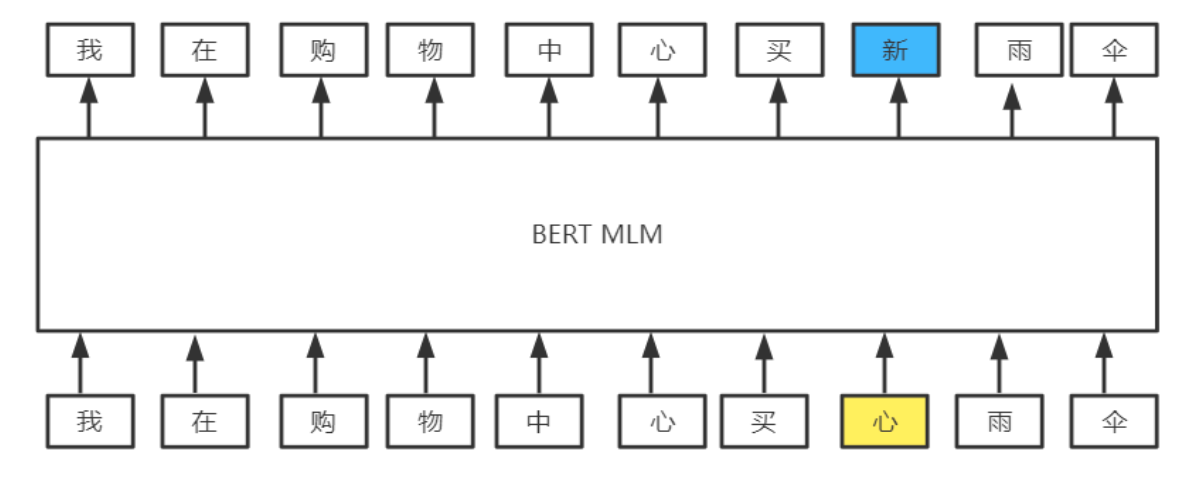
模型结构
(1) 在使用bert的同时,将预训练时mlm任务的全连接层参数也作为初始化参数
(2) 使用多个模型,多个模型的词表保持一致,将全连接层输 出的概率进行平均
(3) 设置规则,对非音近,形近的修改,更加严格。
四、baseline
在ccl-track1任务中,提供了一份基于base-bert实现的baseline,该代码直接是使用了预训练的bert模型,将编码结果经过全连接层并softmax后的输出作为概率,进行输出。
项目结构:
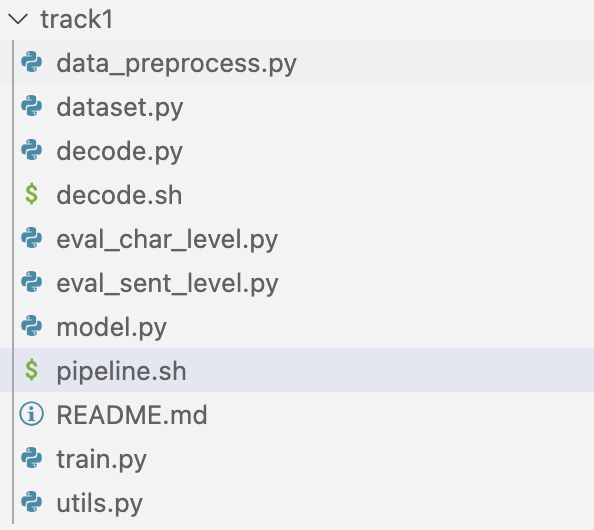
项目结构
其中,data_preprocess.py负责处理原始数据,train.py负责训练,decode.py负责预测。
todo-list:
目前nlpcc-task8已经开放了原始训练数据,但是原始数据无法直接用于该baseline。需要做一下两个工作:
- 将训练数据拆解成src tgt两份文件,并标注id
- 生成一份文件,内容为纠正错误的位置已经纠正前后的内容
五、相关链接
- nlpcc-task8 数据集
https://github.com/Arvid-pku/NLPCC2023_Shared_Task8 - 文本纠错资源集
https://github.com/destwang/CTCResources#chinese-spelling-check-csc - CTC-2021比赛
https://github.com/destwang/CTC2021 - CCL-2022测评报告
https://blcuicall.org/CCL2022-CLTC/report/ - 中文纠错(Chinese Spelling Correct) 最新技术方案总结
https://blog.csdn.net/javastart/article/details/122511809 - 基于BERT和多特征融合嵌入的中文拼写检查
https://www.jsjkx.com/CN/10.11896/jsjkx.220100104

 浙公网安备 33010602011771号
浙公网安备 33010602011771号