Transformer
- Transformer本质是将平平无奇的特征变为楞次分明的特征
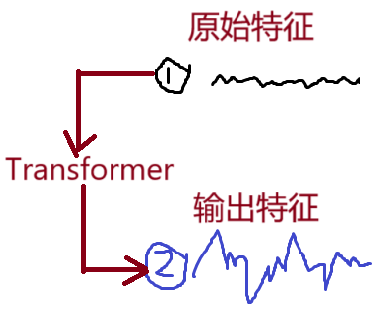
- transformer能够结合上下文语境更新自身特征
整体架构
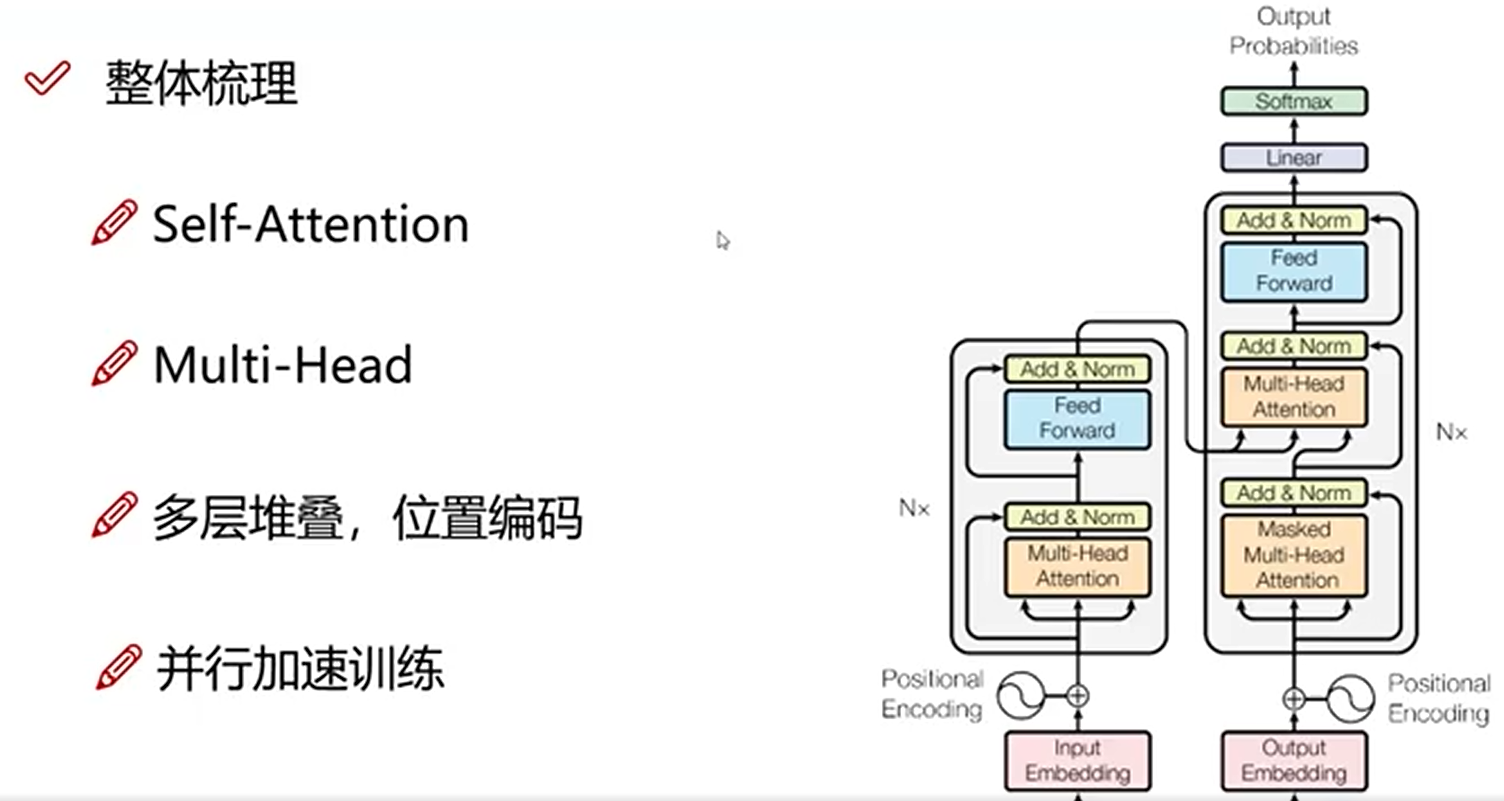
编码层(Encoder)
self-attention是啥意思呢?
-
对于输入的数据,你的关注点是什么?
在逛商场的时候,你可能更加的关注商场里售卖的物品,而不会去关注旋转木马(游乐园才会关注吧_)。而在计算机的世界里也是如此,那么如何才能让计算机关注到这些有价值的信息?
-
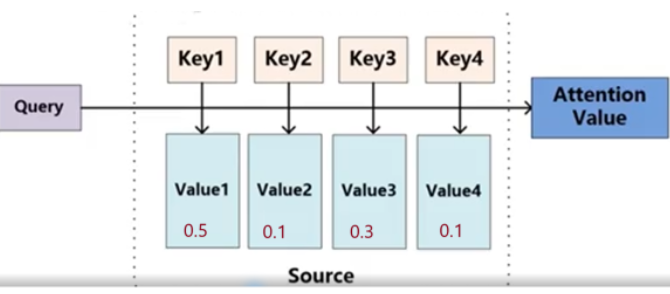
一个简单的例子—“今天晚上吃汉堡”如何更新“今天”这一词向量
结合上下文来更新“今天”这一词向量,我们将“今天”这一词向量的原始特征的50%的信息给新的词向量,将“晚上”词向量的10%的信息给新的词向量,以此类推,将“吃”和“汉堡”的30%和10%的信息给新的词向量。由此我们完成“今天”这一词向量的更新。
类似的方法,完成“晚上”,“吃”和"汉堡"词向量的更新。
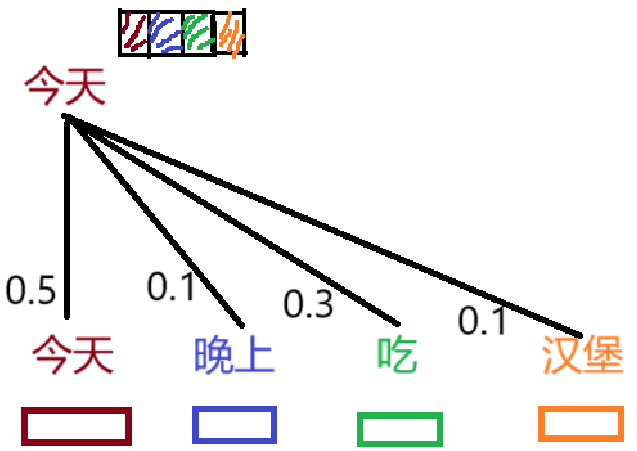
那么,如0.5,0.1,0.3,0.1是如何得来的呢?简单的理解是模型通过训练得到的
self-attention如何计算?
-
判断x1和x2之间的关系,如下图所示,
- 如果x1和x2它们垂直不相交,说明它们的关系不好;即内积越小,关系越差
- 如果x1和x2相交,并且内积越大,说明它们的关系越好。

-
我们假设x1和x2有关系,通过transformer更新嵌入向量
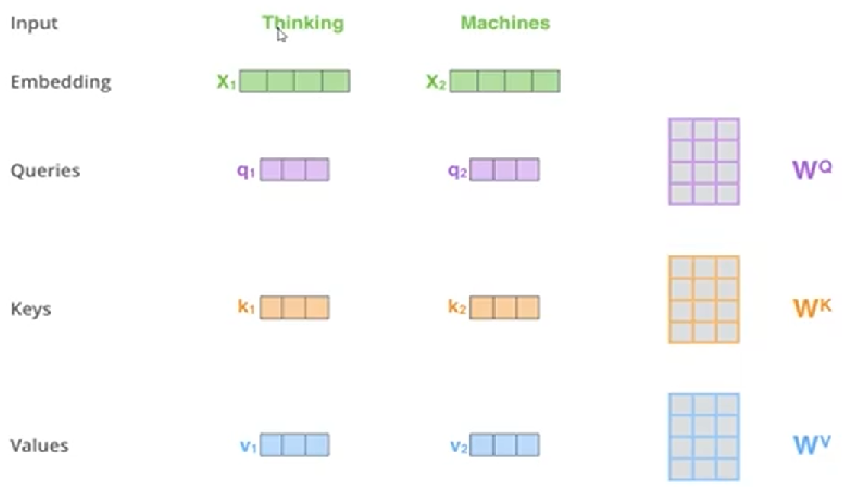
-
stop1 :构造三种辅助向量,分别为Queries,Keys,Values;
-
stop2:x1首先询问自身(q1),x1自身给予反馈(k1);x1再去询问x2(q1),x2给予x1反馈(k2);这里更新谁(x1),谁提供Query向量(q1)
-
以上,我们使用拟人的手法说明了Queries,Keys
-
stop3: q1*k1.T得到x1对自身的关系注意力系数;同理,我们可以得到x2对x1的关系注意力系数;
-
stop4: 有了关系注意力系数,我们再乘以对应的值向量Value,拼接来自x1和x2值向量Value的信息,得到更新后的x1的特征表示。
-
-
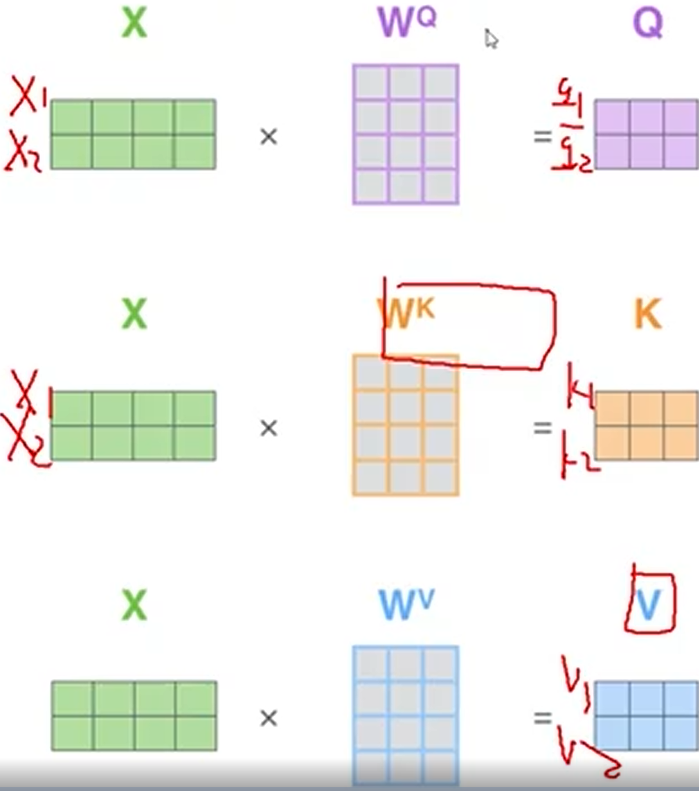
那么Queries,Keys,Values是如何得到的呢?
- 三个需要训练的矩阵
Q: query,要去查询的
K: key,等着被查的
V: value,实际的特征信息 - WQ,WK, W^V是通过全连接层生成的
- 三个需要训练的矩阵
-
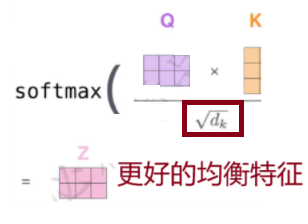
最终的得分值经过softmax就是最终上下文结果
对于同一个特征向量来说,一个是用100维度的特征去衡量重要性,一个使用200维度的特征去衡量重要性,这要的结果大概率是200维度的特征的重要性要大于100维度的特征的重要性,因此我们引入了d_k来均衡特征的重要性。
multi-headed机制
-
一组q,k,v得到了一组当前词的特征表达
-
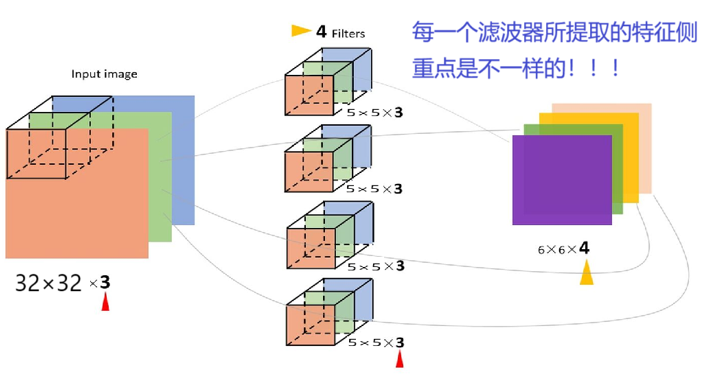
类似卷积神经网络中的滤波器能不能提取多种特征呢?
-
通过多组q,k,v的到多个当前词向量的特征表达
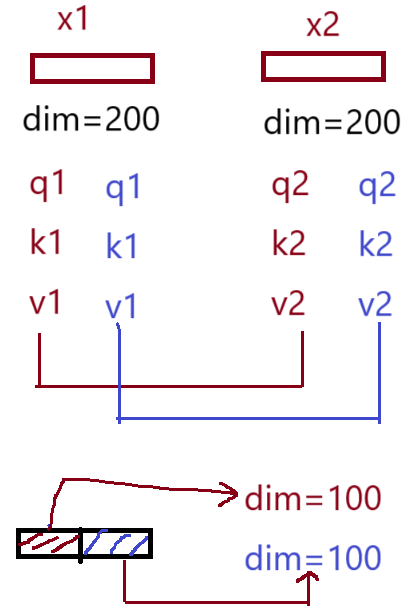
如下图所示,我们的x1原始特征的维度为200,采用多头的方式,类似于两组q,k,v分工协作,每组更新x1的100个维度的信息,最终更新得到的结果拼接起来得到x1更新后的维度仍然是200。
假设两个施工队共同承包了一项工程,即建设200米的大桥,则两个施工队每队负责100米。
-
思考:

- “我”这个词向量是一样的吗?
- 结合语境这样做合理吗?
-
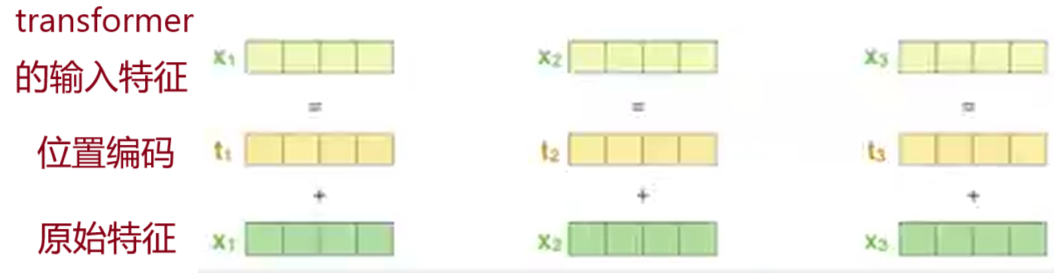
在self-attention中每个词都会考虑整个序列的加权,所以其出现位置并不会对结果产生什么影响,相当于放哪都无所谓,但是这跟实际就有些不符合了,我们希望模型能对位置有额外的认识。
堆叠多层
self-attention可以堆叠多层,常规的是输入维度和输出维度不变,只有值是不变的。
Add与Normalize
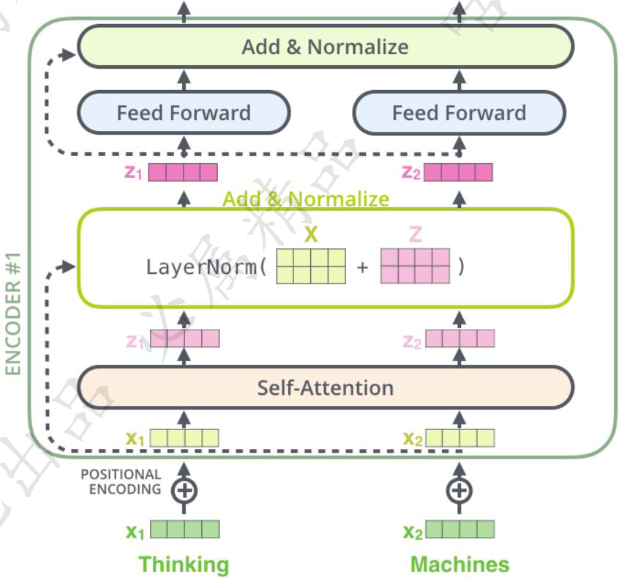
- 归一化(Normalize)
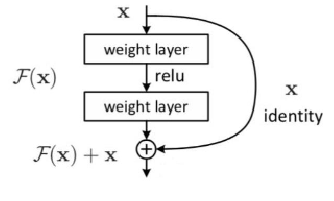
- 连接:基本的残差连接方式
解码层(Decoder)
看看输出结果,比如手写数字集,,输出10分类结果,解码层往往是全连接层
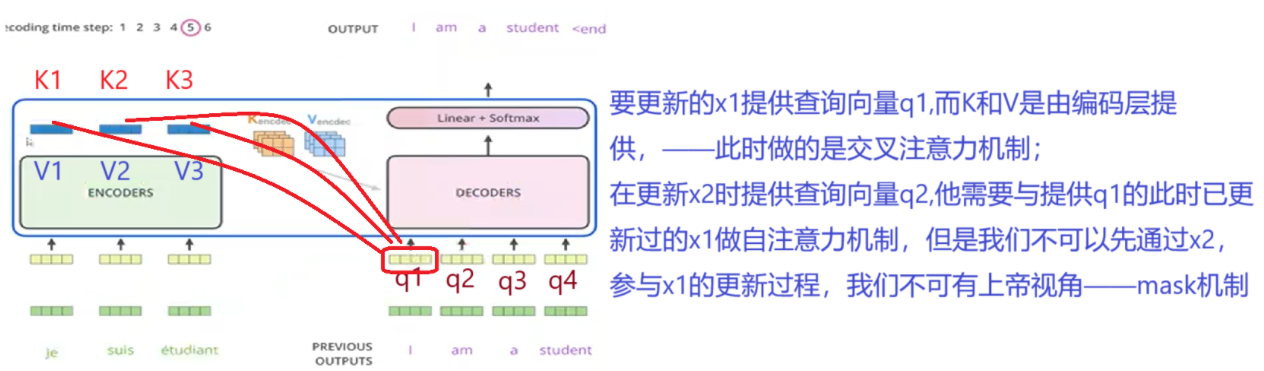
- Attention计算不同
- 加入了MASK机制
最终输出结果
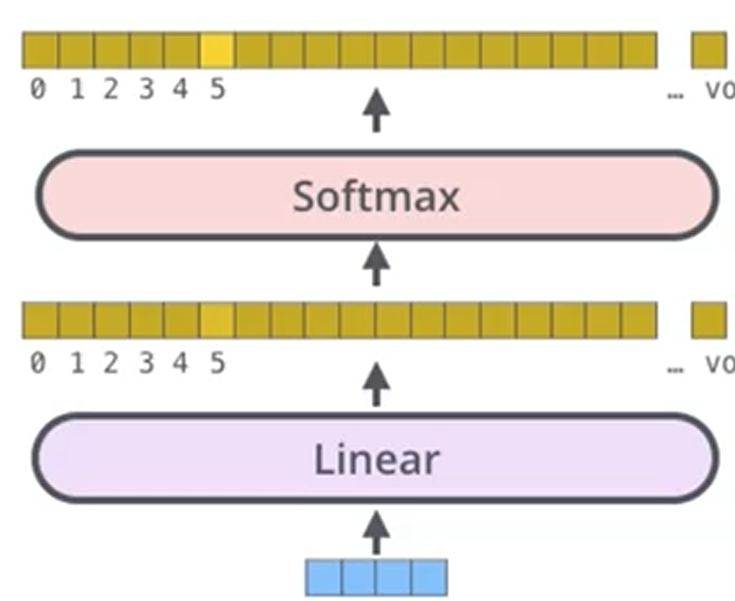
- 得出最终预测结果
- 损失函数 cross-entropy即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号