
数据分析之数据质量分析和数据特征分析
1.数据质量分析
数据质量分析是数据挖掘中数据准备过程的重要一环,是数据预处理的前提,也是数据挖掘分析结论有效性和准确性的基础,没有可信的数据,数据挖掘构建的模型将是空中楼阁。
数据质量分析的主要任务是检查原始数据中是否存在脏数据,脏数据一般是指不符合要求,以及不能直接进行相应分析的数据。在常见的数据挖掘工作中,脏数据包括:
(1)缺失值;
(2)异常值;
(3)不一致的值;
(4)重复数据及含有特殊符号(如#、¥、*)的数据。
1.1缺失值分析
数据的缺失主要包括记录的缺失和记录中某个字段信息的缺失,两者都会造成分析结果的不准确,以下从缺失值产生的原因及影响等方面展开分析。
(1)缺失值产生的原因
1)有些信息暂时无法获取,或者获取信息的代价太大。
2)有些信息是被遗漏的。可能是因为输入时认为不重要、忘记填写或对数据理解错误等一些人为因素而遗漏,也可能是由于数据采集设备的故障、存储介质的故障、传输媒体的故障等非人为原因而丢失。
3)属性值不存在。在某些情况下,缺失值并不意味着数据有错误。对一些对象来说某些属性值是不存在的,如一个未婚者的配偶姓名、一个儿童的固定收入等。
(2)缺失值的影响
1)数据挖掘建模将丢失大量的有用信息。
2)数据挖掘模型所表现出的不确定性更加显著,模型中蕴含的规律更难把握。
3)包含空值的数据会使建模过程陷入混乱,导致不可靠的输出。
(3)缺失值的分析
使用简单的统计分析,可以得到含有缺失值的属性的个数,以及每个属性的未缺失数、缺失数与缺失率等。
1.2异常值分析
异常值分析是检验数据是否有录入错误以及含有不合常理的数据。忽视异常值的存在是十分危险的,不加剔除地把异常值包括进数据的计算分析过程中,会给结果带来不良影响;重视异常值的出现,分析其产生的原因,常常成为发现问题进而改进决策的契机。异常值是指样本中的个别值,其数值明显偏离其余的观测值。异常值也称为离群点,异常值的分析也称为离群点分析。
(1)简单统计量分析
可以先对变量做一个描述性统计,进而查看哪些数据是不合理的。最常用的统计量是最大值和最小值,用来判断这个变量的取值是否超出了合理的范围。例如,客户年龄的最大值为199岁,则该变量的取值存在异常。
(2)3σ原则
如果数据服从正态分布,在3σ原则下,异常值被定义为一组测定值中与平均值的偏差超过三倍标准差的值。在正态分布的假设下,距离平均值3σ之外的值出现的概率为P(|x-μ|>3σ)≤0.003,属于极个别的小概率事件。如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。
(3)箱形图分析
箱形图提供了识别异常值的一个标准:异常值通常被定义为小于QL-1.5IQR或大于QU+1.5IQR的值。QL称为下四分位数,表示全部观察值中有四分之一的数据取值比它小;QU称为上四分位数,表示全部观察值中有四分之一的数据取值比它大;IQR称为四分位数间距,是上四分位数QU与下四分位数QL之差,其间包含了全部观察值的一半。箱形图判断异常值的标准以四分位数和四分位距为基础,四分位数具有一定的鲁棒性:多达25%的数据可以变得任意远而不会很大地扰动四分位数,所以异常值不能对这个标准施加影响。由此可见,箱形图识别异常值的结果比较客观,在识别异常值方面有一定的优越性,如图所示。

在平常的数据分析过程中可以发现,可能其中有部分数据是缺失的,但是如果数据记录和属性较多,使用人工分辨的方法就很不切合实际,所以这里需要编写程序来检测出含有缺失值的记录和属性以及缺失率个数和缺失率等。同时,也可使用箱形图来检测异常值。R语言检测代码如下所示。
# 设置工作空间
# 把“数据及程序”文件夹拷贝到F盘下,再用setwd设置工作空间
setwd("F:/数据及程序/chapter3/示例程序")
# 读入数据
saledata <- read.csv(file = "./data/catering_sale.csv", header = TRUE)
# 缺失值检测 并打印结果,由于R把TRUE和FALSE分别当作1、0,可以用sum()和mean()函数来分别获取缺失样本数、缺失比例
sum(complete.cases(saledata))
sum(!complete.cases(saledata))
mean(!complete.cases(saledata))
saledata[!complete.cases(saledata), ]
# 异常值检测箱线图
sp <- boxplot(saledata$"销量", boxwex = 0.7)
title("销量异常值检测箱线图")
xi <- 1.1
sd.s <- sd(saledata[complete.cases(saledata), ]$"销量")
mn.s <- mean(saledata[complete.cases(saledata), ]$"销量")
points(xi, mn.s, col = "red", pch = 18)
arrows(xi, mn.s - sd.s, xi, mn.s + sd.s, code = 3, col = "pink", angle = 75, length = .1)
text(rep(c(1.05, 1.05, 0.95, 0.95), length = length(sp$out)),
labels = sp$out[order(sp$out)], sp$out[order(sp$out)] +
rep(c(150, -150, 150, -150), length = length(sp$out)), col = "red")
该代码以某餐厅的日销量额数据作为样本数据,数据示例如下:
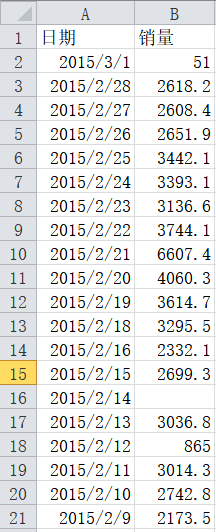
运行上面的程序,得到以下结果:


可以看到缺失值个数输出结果为“1”,占样本总量的0.497%,缺失值位于第15行,2015年2月14日销量缺失。分析箱形图可以看出,箭头所示的是一个标准差的区间。可以看出箱形图中超过上下界的8个销售额数据可能为异常值。结合具体业务可以把865、4060.3、4065.2归为正常值,将60、22、51、6607.4、9106.44归为异常值。
1.3一致性分析
数据不一致性是指数据的矛盾性、不相容性。直接对不一致的数据进行挖掘,可能会产生与实际相违背的挖掘结果。在数据挖掘过程中,不一致数据的产生主要发生在数据集成的过程中,可能是由被挖掘数据来自于不同的数据源、对于重复存放的数据未能进行一致性更新造成的。例如,两张表中都存储了用户的电话号码,但在用户的电话号码发生改变时只更新了一张表中的数据,那么这两张表中就有了不一致的数据。
2.数据特征分析
对数据进行质量分析以后,接下来可通过绘制图表、计算某些特征量等手段进行数据的特征分析。
2.1分布分析
分布分析能揭示数据的分布特征和分布类型。对于定量数据,欲了解其分布形式是对称的还是非对称的、发现某些特大或特小的可疑值,可做出频率分布表、绘制频率分布直方图、绘制茎叶图进行直观地分析;对于定性数据,可用饼形图和条形图直观地显示分布情况。
2.1.1.定量数据的分布分析
对于定量变量,选择“组数”和“组宽”是做频率分布分析时最主要的问题,一般按照以下步骤:
1)求极差;
2)决定组距与组数;
3)决定分点;
4)列出频率分布表;
5)绘制频率分布直方图。
遵循的主要原则有:
1)各组之间必须是相互排斥的;
2)各组必须将所有的数据包含在内;
3)各组的组宽最好相等。
下面结合具体实例运用分布分析对定量数据进行特征分析:
下表是描述菜品捞起生鱼片在2014年第二个季度的销售数据,绘制销售量的频率分布表、频率分布图,对该定量数据做出相应的分析。
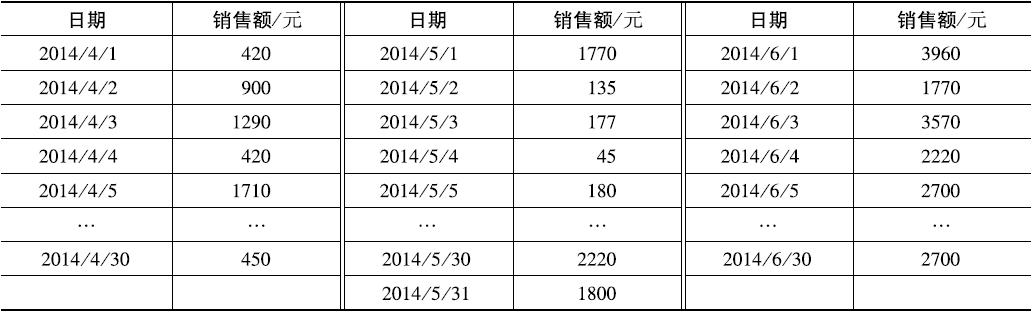
(1)求极差
极差=最大值-最小值=3960-45=3915(元)
(2)决定组距与组数
这里根据业务数据的含义,可取组距为500。
组数=极差/组距=3915/500=7.83=>8
(3)决定分点
分布区间如下表所示。

(4)列出频率分布表
根据分组区间得到如下表所示的频率分布表。其中,第1列将数据所在的范围分成若干组段,其中第1个组段要包括最小值,最后一个组段要包括最大值。习惯上将各组段设为左闭右开的半开区间,如第1个分组为[0,500)。第2列组中值是各组段的代表值,由本组段的上、下限相加除以2得到。第3列和第4列分别为频数和频率。第5列是累计频率,是否需要计算该列视情况而定。

(5)绘制频率分布直方图
若以2014年第二季度捞起生鱼片每天的销售额为横轴,以各组段的频率密度(频率与组距之比)为纵轴,上表的数据可绘制成频率分布直方图,如图所示。

2.1.2.定性数据的分布分析
对于定性变量,常常根据变量的分类类型来分组,可以采用饼形图和条形图来描述定性变量的分布。饼形图的每一个扇形部分代表每一类型的百分比或频数,根据定性变量的类型数目将饼形图分成几个部分,每一部分的大小与每一类型的频数成正比;条形图的高度代表每一类型的百分比或频数,条形图的宽度没有意义。
图1和图2是菜品A、B、C在某段时间的销售量分布图。
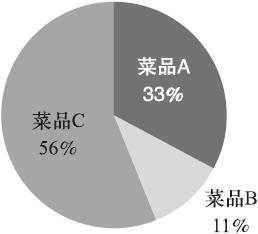
图1 菜品销售量分布(饼形图)
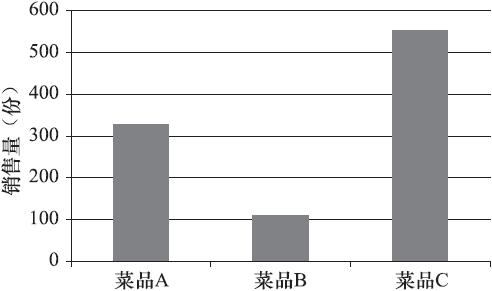
图2 菜品销售量分布(条形图)
2.2对比分析
对比分析是指把两个相互联系的指标进行比较,从数量上展示和说明研究对象规模的大小,水平的高低,速度的快慢,以及各种关系是否协调。特别适用于指标间的横纵向比较、时间序列的比较分析。在对比分析中,选择合适的对比标准是十分关键的步骤,选择合适,才能做出客观的评价,选择不合适,评价可能得出错误的结论。
对比分析主要有以下两种形式:
(1)绝对数比较
它是利用绝对数进行对比,从而寻找差异的一种方法。
(2)相对数比较
它是由两个有联系的指标对比计算的,用以反映客观现象之间数量联系程度的综合指标,其数值表现为相对数。由于研究目的和对比基础不同,相对数可以分为以下几种:
1)结构相对数:将同一总体内的部分数值与全部数值对比求得比重,用以说明事物的性质、结构或质量。例如,居民食品支出额占消费支出总额比重、产品合格率等。
2)比例相对数:将同一总体内不同部分的数值对比,表明总体内各部分的比例关系,如人口性别比例、投资与消费比例等。
3)比较相对数:将同一时期两个性质相同的指标数值对比,说明同类现象在不同空间条件下的数量对比关系。例如,不同地区商品价格对比,不同行业、不同企业间某项指标对比等。
4)强度相对数:将两个性质不同但有一定联系的总量指标对比,用以说明现象的强度、密度和普遍程度。例如,人均国内生产总值用“元/人”表示,人口密度用“人/平方公里”表示,也有用百分数或千分数表示的,如人口出生率用‰表示。
5)计划完成程度相对数:是某一时期实际完成数与计划数对比,用以说明计划完成程度。
6)动态相对数:将同一现象在不同时期的指标数值对比,用以说明发展方向和变化的速度,如发展速度、增长速度等。
2.3统计量分析
用统计指标对定量数据进行统计描述,常从集中趋势和离中趋势两个方面进行分析。平均水平的指标是对个体集中趋势的度量,使用最广泛的是均值和中位数;反映变异程度的指标则是对个体离开平均水平的度量,使用较广泛的是标准差(方差)、四分位数间距。
1.集中趋势度量
(1)均值
均值是所有数据的平均值。如果求n个原始观察数据的平均数,计算公式为:

有时,为了反映在均值中不同成分所占的不同重要程度,为数据集中的每一个xi赋予wi,这就得到了加权均值的计算公式:
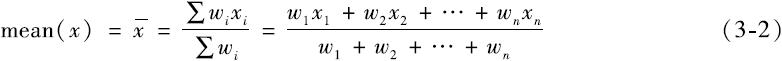
类似地,频率分布表(如表3-4)的平均数可以使用下式计算:

式中,x1,x2,…,xk分别为k个组段的组中值;f1,f2,…,fk分别为k个组段的频率。这里的fi起了权重的作用。
作为一个统计量,均值的主要问题是对极端值很敏感。如果数据中存在极端值或者数据是偏态分布的,那么均值就不能很好地度量数据的集中趋势。为了消除少数极端值的影响,可以使用截断均值或者中位数来度量数据的集中趋势。截断均值是去掉高、低极端值之后的平均数。
(2)中位数
中位数是将一组观察值从小到大按顺序排列,位于中间的那个数据。即在全部数据中,小于和大于中位数的数据个数相等。
将某一数据集x:{x1,x2,…,xn}从小到大排序:{x(1),x(2),…,x(n)}。
当n为奇数时

当n为偶数时

(3)众数
众数是指数据集中出现最频繁的值。众数并不经常用来度量定性变量的中心位置,更适用于定性变量。众数不具有唯一性。
2.离中趋势度量
(1)极差
极差=最大值-最小值
极差对数据集的极端值非常敏感,并且忽略了位于最大值与最小值之间的数据是如何分布的。
(2)标准差
标准差度量数据偏离均值的程度,计算公式为:

(3)变异系数
变异系数度量标准差相对于均值的离中趋势,计算公式为:

变异系数主要用来比较两个或多个具有不同单位或不同波动幅度的数据集的离中趋势。
(4)四分位数间距
四分位数包括上四分位数和下四分位数。将所有数值由小到大排列并分成四等份,处于第一个分割点位置的数值是下四分位数,处于第二个分割点位置(中间位置)的数值是中位数,处于第三个分割点位置的数值是上四分位数。四分位数间距是上四分位数QU与下四分位数QL之差,其间包含了全部观察值的一半。其值越大,说明数据的变异程度越大;反之,说明变异程度越小。
针对餐饮销量数据进行统计量分析,其R语言代码如下:
# 设置工作空间
# 把“数据及程序”文件夹拷贝到F盘下,再用setwd设置工作空间
setwd("F:/数据及程序/chapter3/示例程序")
# 读入数据
saledata <- read.table(file = "./data/catering_sale.csv", sep=",", header = TRUE)
sales <- saledata[, 2]
# 统计量分析
# 均值
mean_ <- mean(sales, na.rm = T)
# 中位数
median_ <- median(sales, na.rm = T)
# 极差
range_ <- max(sales, na.rm = T) - min(sales, na.rm = T)
# 标准差
std_ <- sqrt(var(sales, na.rm = T))
# 变异系数
variation_ <- std_ / mean_
# 四分位数间距
q1 <- quantile(sales, 0.25, na.rm = T)
q3 <- quantile(sales, 0.75, na.rm = T)
distance <- q3 - q1
a <- matrix(c(mean_, median_, range_, std_, variation_, q1, q3, distance),
1, byrow = T)
colnames(a) <- c("均值", "中位数", "极差", "标准差", "变异系数",
"1/4分位数", "3/4分位数", "四分位间距")
print(a)
程序运行结果如下:

我们通过上面的程序已经得到餐饮销量数的统计量情况:销量数据均值:2755.215,中位数:2655.85,极差: 9084.44,标准差:751.0298,变异系数:0.2725848,四分位数间距:574.15。
后续还有周期性分析和相关性分析以及一些其他统计函数,后面再介绍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号