深度学习-tensorflow学习笔记(2)-MNIST手写字体识别
深度学习-tensorflow学习笔记(2)-MNIST手写字体识别超级详细版
这是tf入门的第一个例子。minst应该是内置的数据集。
前置知识在学习笔记(1)里面讲过了
这里直接上代码
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Fri May 25 14:09:45 2018 4 5 @author: Administrator 6 """ 7 #导入数据集 8 from tensorflow.examples.tutorials.mnist import input_data 9 mnist=input_data.read_data_sets("MNIST_data/",one_hot=True) 10 #打印数据集的详情 11 print(mnist.train.images.shape,mnist.train.labels.shape) 12 print(mnist.test.images.shape,mnist.test.labels.shape) 13 print(mnist.validation.images.shape,mnist.validation.labels.shape)
打印结果如下
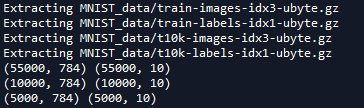
第一个是训练集的特征值和标签,第二个是测试集,第三个是验证集
MNIST数据集的特征值是28*28的
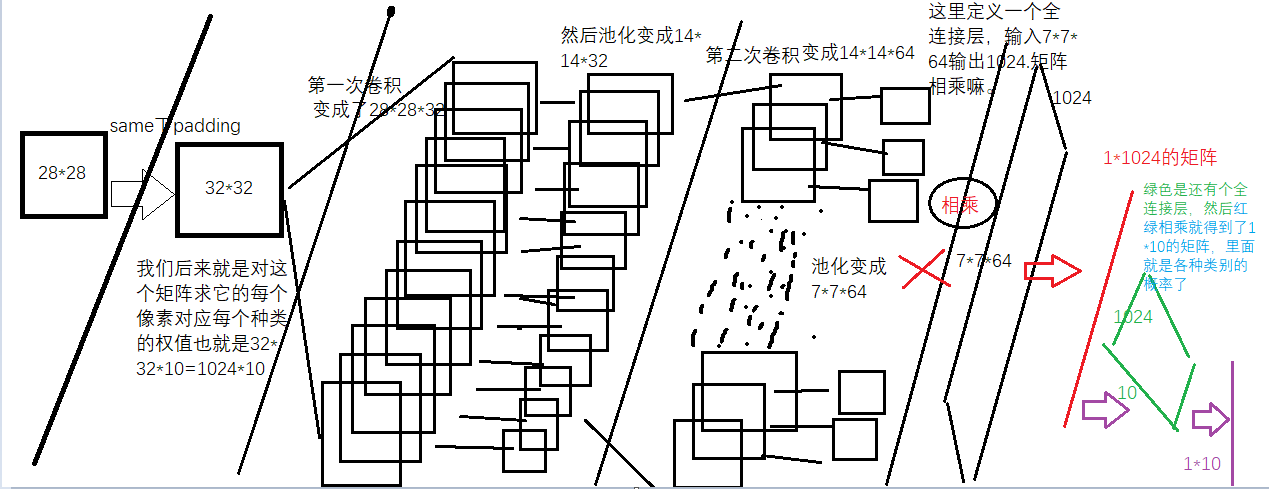
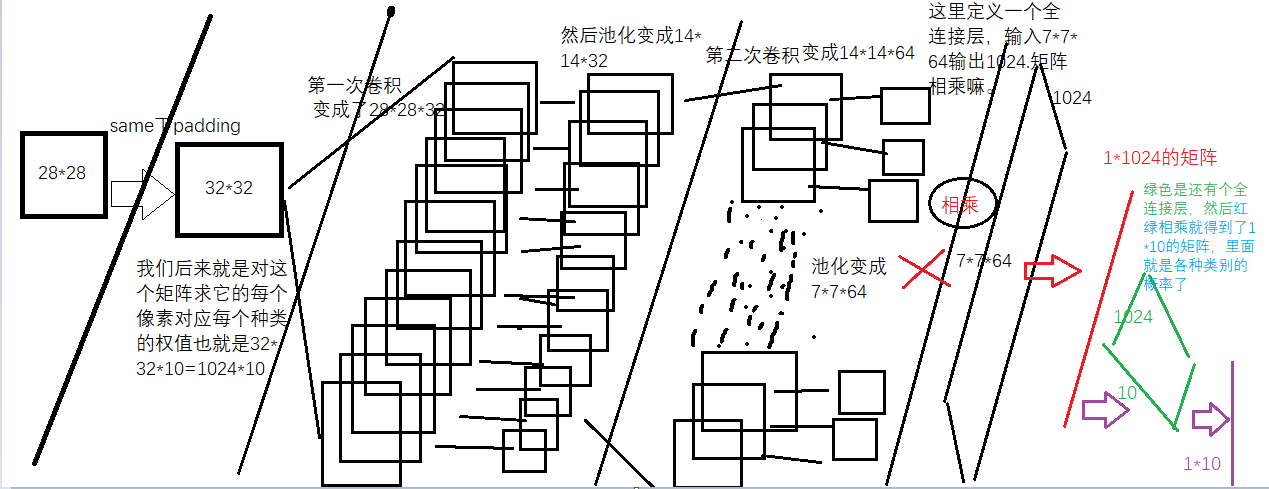
先看下一个CNN的过程
过程的文字描述如下-导入数据集-对特征值卷积-池化-激活-卷积-池化-激活-全连接-全连接-计算损失-计算精度
接下来开始通过代码讲
首先我们声明占位符-训练集特征值和标签,NONE表示自适应维度
x=tf.placeholder(tf.float32,[None,784]) #训练集真实标签 y_=tf.placeholder(tf.float32,[None,10])
导入的数据集是1*784维度的,原图像是28*28的
为了卷积运算我们把一位数据变成28*28的这里用的是tf.reshape函数
这里解释下reshape的参数,x是输入数据,[batch,weight,height,depth]
x_image=tf.reshape(x,[-1,28,28,1]
为了方便我们操作,定义了生成权重,偏置的函数
#生成权重,高斯分布,方差为0.1 def weight_variabel(shape): initial=tf.truncated_normal(shape,stddev=0.1) return tf.Variable(initial) #生成shape大小的偏置,偏置初时为0.1 def bias_variable(shape): initial=tf.constant(0.1,shape=shape) return tf.Variable(initial)
另外还定义了卷积和池化的操作
''' 卷积操作 conv2d(输入图像,卷积核,在各个维度的滑动步长,SAME-or-VALID) VALID当卷积核超出边缘了,就会直接丢弃 SAME的话会给padding 0来满足 ''' def conv2d(x,W): return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME') ''' 池化的输入,池化窗口大小,步长 第二个参数[batchs,height,width,channels] 返回[batch,height,width,channels] 池化方式-mean-pooling 求平均-对背景保留更好 -max-pooling 求特征点最大,对纹理保留最好 -stochastic_pooling两者之间,通过对像素点按照数值大小赋予概率 ''' def max_pool_2x2(x): return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
接下来开始第一层卷积操作
这里输入参数为input=28*28 用5*5*1的32个不同的卷积核 卷积后遍历后 得到 28*28*32的图像
下面再生成32个偏置,这里的偏置应该是对图的每一个深度加的偏置
w_conv1=weight_variable([5,5,1,32])
b_conv1=bias_variable([32])
然后我们用激活函数来修正线性单元
这里用的激活函数relu
h_conv1=tf.nn.relu(conv2d(x_image,w_conv1)+b_conv1)#relu激励函数+卷积
这里执行了卷积和激励的操作-
由于是SAME所以padding后为32*32(28+4嘛)
然后我们对这个32*32进行卷积 卷积核为5*5,所以卷积后是28*28*32(很符合我们对卷积后大小不变得期望)
然后我们开始池化操作
卷积是为了提取特征值,多层不同的filter就是为了获取不同的特征值,池化就是为了压缩特征,减少运算量
h_pool1=max_pool_2x2(h_conv1)#池化操作
用2*2的max_pool池化后得到了14*14*32的图
然后我们开始第二层卷积
#第二层卷积 w_conv2=weight_variable([5,5,32,64]) b_conv2=bias_variable([64]) h_conv2=tf.nn.relu(conv2d(h_pool1,w_conv2)+b_conv2) h_pool2=max_pool_2x2(h_conv2)
这里同样用5*5的卷积层对32深度的卷积----这里运算非常复杂每次都要对5*5*32的矩阵和5*5*1的64个不同的矩阵相乘
然后池化后为7*7*64的矩阵
池化后为全连接层操作了
w_fc1=weight_variable([7*7*64,1024])
b_fc1=bias_variable([1024])
这里 定义全连接层的权重和偏置
7*7*64就是输入 1024为输出 为啥是1024呢? 因为输入是32*32---手写字体是28*28由于paading=SAME所以成了32*32-然后对每个像素计算权重和偏置-自然就是32*32=1024了。
h_pool2_flat=tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,w_fc1)+b_fc1)
这里把池化层的输出变成了7*7*64的一纬度向量
便于输入全连接层-全连接层的输出是1024*1维度的向量
然后执行relu激活函数,做线性修正
#dropout防止过度拟合,随机去掉某些连接 keep_prob=tf.placeholder(tf.float32) h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob)
这里为了防止过度拟合丢弃了一些连接
# 把1024维的向量转换成10维,对应10个类别
#每个类别的每个像素都有自己的权重。所有一共一1024*10个
#然后矩阵相乘下面用1*1024 和1024*10matmul出对应10个类别的概率+偏置 w_fc2 = weight_variable([1024, 10]) b_fc2 = bias_variable([10]) y_conv = tf.matmul(h_fc1_drop, w_fc2) + b_fc2
#这里的y_conv就是我们的概率,是个1*10的矩阵
然后我们再定义误差和训练步骤
这里的adamoptimizer是快速随机梯度下降,
cross_entropy = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv)) # 同样定义train_step-让cross-entropy最小化 train_step =tf.train.AdamOptimizer(1e4).minimize(cross_entropy)
再定义测试的准确率
#argmax获取最大值得下标,equal判断是否相等,y_是真实值,y_conv是预测的值 correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1)) #cast把True变成1,flase变0然后reduce_mean求平均值 accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
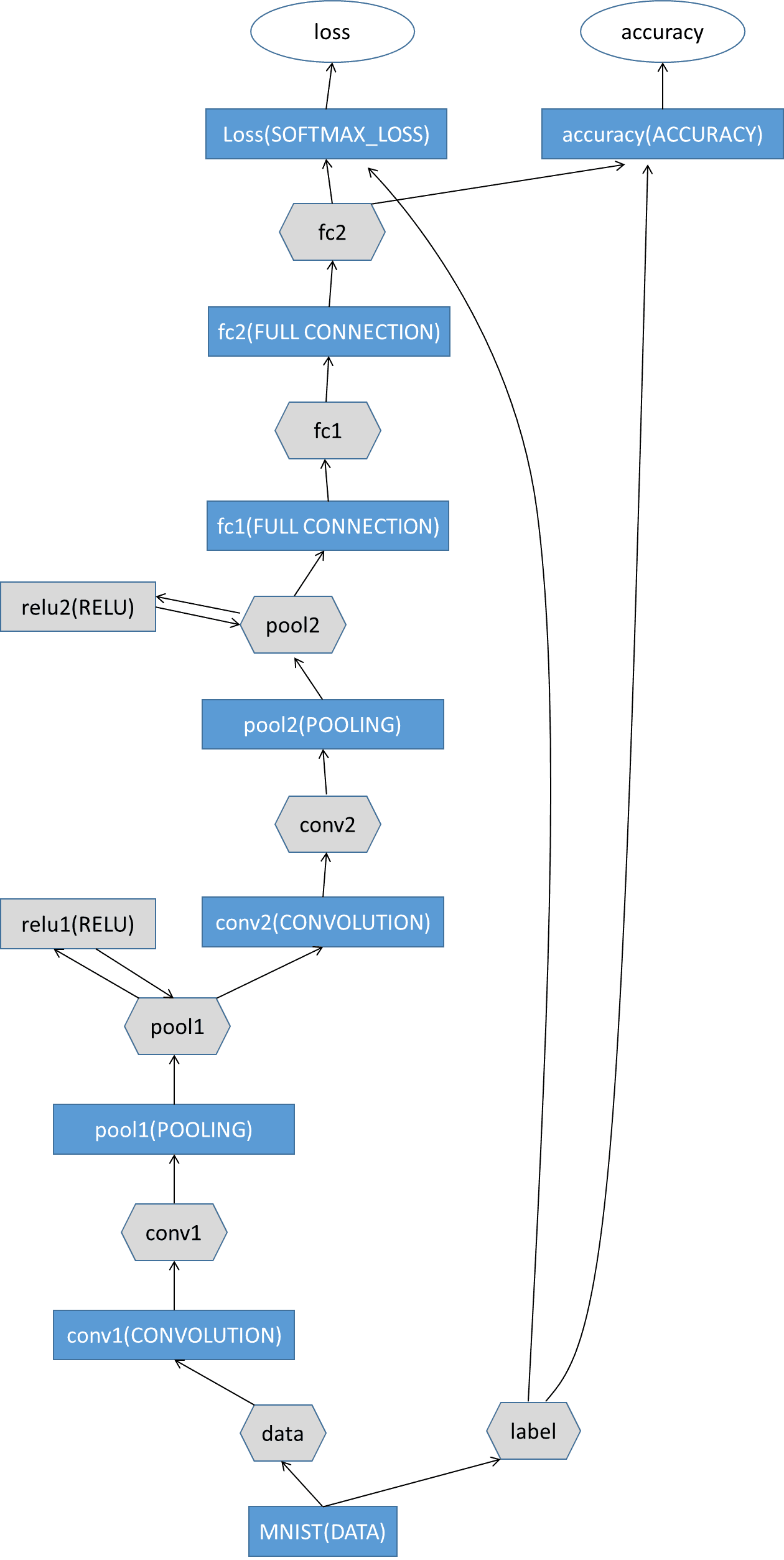
此时我们模型以及建立完毕
我们用图来看下,我画了一张垃圾图,希望自己以后能看的懂。
到这里为止
我们的模型已经建立好了,我们现在要开始训练了
首先初始化所有值,建立会话
# 创建Session和变量初始化 sess = tf.InteractiveSession() sess.run(tf.global_variables_initializer())
开始训练
# 训练2000步 for i in range(2000): batch = mnist.train.next_batch(50)#一次取50个数据 # 每100步报告一次在验证集上的准确度 if i % 100 == 0: train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0}) print("step %d, training accuracy %g" % (i, train_accuracy)) train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
最后报告精确度
# 训练结束后报告在测试集上的准确度 print("test accuracy %g" % accuracy.eval(feed_dict={ x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
友情提示cpu会跑很久。。。大概几分钟。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号