

ORACLE存储过程获取索引信息-转为MySQL索引创建语句
背景:因为在使用DataPipeline做数据同步(oracle到TiDB[语法与MySQL基本一致的数据库])的时候发现oracle数据库的索引是没有被一起同步过来的,在查询数据的时候会很慢,所以需要手动在TiDB中创建索引,这个就很麻烦啦.... 如果一个一个的手工创建,且oracle那边没有办法直接将索引创建语句导出,表多且每张表的索引也很多,这种情况下,我们还是写个存储过程 获取oracle表的索引信息,在存储过程里直接拼凑为TiDB(MySQL)的索引创建语句。
关于ORACLE的索引信息:
1.查看当前表的索引信息
select * from user_indexes where table_name='tablename' ; -- 将tablename替换为你的表名就即可 ,也可以不指定表名,直接查询出所有表的索引信息

2. 根据索引名称,查询到表的索引列信息
select * from user_ind_columns where index_name=upper('I1PBASEPAPER'); -- I1PBASEPAPER是上面那条语句查询出来的 INDEX_NAME 值

3.一条sql语句查询出索引相关信息 ,将tablename替换为需要的表名即可
select
a.index_name
, a.table_name
, a.column_name
,b.index_type
,b.uniqueness
FROM all_ind_columns a, all_indexes b
WHERE a.index_name=b.index_name
AND a.table_name = upper('tablename')
ORDER BY a.table_name, a.index_name, a.column_position
;

4.来咯,上重点啦,存储过程 取出oracle表中的所有索引并且拼凑为MYSQL的索引创建脚本输出
思路很简单,借用上面的查询索引语句,循环取出我们要的索引信息(索引名称,索引类型(唯一/非唯一),索引所属的表名),然后手动拼凑sql即可
需要注意的点:
唯一索引需要单独判断
组合索引写法有点不一样,需要单独拼接
先来一段简单的,看看索引信息(第一段for里面的in (T1APL,tablename2)指定表名信息即可,多张表用逗号分割)
declare
begin
for curidx in (select index_name,TABLE_NAME from user_indexes where table_name in('T1APL','tablename2')) loop
dbms_output.put('索引:【表:'||curidx.TABLE_NAME||', 索引: '||curidx.index_name||', 索引列:');
for curidxcol in (select * from user_ind_columns where index_name=upper(curidx.index_name)) loop
dbms_output.put_line(curidxcol.column_name||'】');
end loop;
end loop;
end;
执行上面的语句,我们会看到类似下面的数据输出,这里组合索引列输出会有点乱,下面的脚本会统一整理,这里只做索引基本信息获取然后迭代出来的演示

5.来咯,放大招啦哈哈哈哈,实实在在的使用的脚本:(你只需要替换你的tablename即可使用啦)
declare
idx_cnt int(10) ; -- 用于保存索引列的数量
begin
for curidx in (select index_name,table_name,uniqueness from user_indexes where table_name in('tablename','T1APL')) loop
select count(*) into idx_cnt from user_ind_columns where index_name=upper(curidx.index_name);
if idx_cnt >1 -- 组合索引
then
if curidx.uniqueness = 'UNIQUE' then -- 判断是否为 唯一索引如果是就在创建索引的时候添加 unique 关键字
dbms_output.put('ALTER TABLE or_lifepro.'||curidx.table_name||' add '||curidx.uniqueness||' index '||curidx.index_name||' (');
else
dbms_output.put('ALTER TABLE or_lifepro.'||curidx.table_name||' add index '||curidx.index_name||'(');
end if;
for curidxcol in (select * from user_ind_columns where index_name=upper(curidx.index_name)) loop
idx_cnt := idx_cnt -1; -- 当前循环每执行一次,变量次数减1
if idx_cnt=0 -- 当前循环为最后一次循环时 使用括号结束索引创建语句
then
dbms_output.put_line(curidxcol.column_name||');');
else
dbms_output.put(curidxcol.column_name||',');
end if;
end loop;
else -- 单列索引
for curidxcol in (select * from user_ind_columns where index_name=upper(curidx.index_name)) loop
if curidx.uniqueness = 'UNIQUE' then -- 判断是否为 唯一索引如果是就在创建索引的时候添加 unique 关键字
dbms_output.put_line('ALTER TABLE or_lifepro.'||curidx.table_name||' add '||curidx.uniqueness||' index '||curidx.index_name||'('||curidxcol.column_name||');');
else
dbms_output.put_line('ALTER TABLE or_lifepro.'||curidx.table_name||' add index '||curidx.index_name||'('||curidxcol.column_name||');');
end if;
end loop;
end if;
end loop;
end;
在PLSQL里面执行脚本(注意这个脚本中我添加了库名前缀 or_lifepro[这是我TiDB里面的库名],可以看自己喜好选择修改为你的库名或者删除哦)
执行结果如下图:我们可以看到这里的组合索引都是正常的输出哦,且唯一索引也都加了UNIQUE关键字
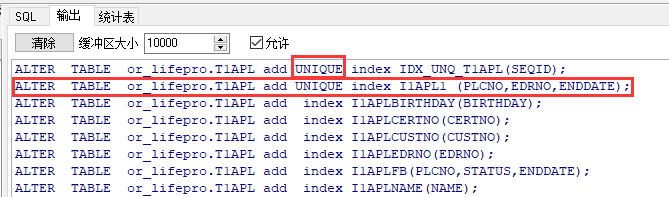
到这里我们的ORACLE索引转换为MySQL就执行完了,接下来将输出里面的内容复制到MySQL数据库中执行一遍即可啦!!!
关于MySQL的索引信息
1.mysql查看表索引语句
show index from tablename;
2.添加索引
ALTER table table_name ADD INDEX index_name (column1,column2,column3); -- 添加组合索引
ALTER table table_name ADD INDEX index_name (columnname); -- 添加普通索引
ALTER table table_name ADD UNIQUE INDEX index_name (columnname); -- 添加唯一索引
3.分析表,使得索引生效
analyze table tablename;
4.批量删除mysql表索引
先将表索引信息删除语句拼凑好,执行如下sql,更改你的tablename即可
SELECT i.TABLE_NAME, i.COLUMN_NAME, i.INDEX_NAME,
CONCAT('ALTER TABLE ',i.TABLE_NAME,' DROP INDEX ',i.INDEX_NAME,' ;')
FROM INFORMATION_SCHEMA.STATISTICS i where i.TABLE_NAME='tablename'
;

 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号