
Java实现编辑距离算法
编辑距离,又称Levenshtein距离(莱文斯坦距离也叫做Edit Distance),是指两个字串之间,由一个转成另一个所需的最少编辑操作次数,如果它们的距离越大,说明它们的相似度越小。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
oracle数据库中有一个编辑距离函数: UTL_MATCH.EDIT_DISTANCE(str1,str2)
在plsql中执行: select UTL_MATCH.EDIT_DISTANCE('Java你好','你好') from dual;
执行结果为: 4
此函数的含义为:
计算两个字符串的差异, str1 str2, str1要做多少次插入 删除、 替换、 操作才能与str2一致(每次一个字符),这里取出来的是最小变更次数 即 最小距离。
eg: str1 = "Java你好"; str2="你好";
由 str1 变为 str2, 至少需要做四次删除操作,分别删除字符 J ,a, v, a然后才能与str2保持一致。故这里的编辑距离为 4。
(这里也可以由 str2变为srt1,str2至少需要做4次插入操作,分别在前面插入 J ,a ,v,a 才能与str1保持一致。)
Java代码实现编辑距离,且计算出两个字符串的相似度(这里是因为我要做hive的自定义UDF函数,所以继承了 UDF,正常使用可以不用继承UDF类。)
字符串相似度: 相似度 = (长串的长度 - 编辑距离)/ 长串的长度 ; // 长串的长度: Math.max(str1.length(),str2.length());
OracleEditDistance .java
package org.clio.hiveudf.hiveudf; import org.apache.hadoop.hive.ql.exec.UDF; /** * <p> * Description: 编辑距离算法 * 距离值:变更次数--- 先计算两个字符串的差异, str1 str2, str1要做多少次(每次一个char字符)增加 删除 替换 操作 才能与str2一致 * 相似度:用最长的字符串的len 减去 变更次数 ,然后除以最长的字符串长度. similarity = (maxLen - changeTimes)/maxLen * ORACLE函数: UTL_MATCH.EDIT_DISTANCE * select UTL_MATCH.EDIT_DISTANCE('Java你好','你好') from dual; * </p> * @author duanfeixia * @date 2019年7月30日 */ public class OracleEditDistance extends UDF{ /** * 编辑距离算法 * @param sourceStr 原字符串 * @param targetStr 目标字符串 * @return 返回最小距离: 原字符串需要变更多少次才能与目标字符串一致(变更动作:增加/删除/替换,每次都是以字节为单位) */ public static int minDistance(String sourceStr, String targetStr){ int sourceLen = sourceStr.length(); int targetLen = targetStr.length(); if(sourceLen == 0){ return targetLen; } if(targetLen == 0){ return sourceLen; } //定义矩阵(二维数组) int[][] arr = new int[sourceLen+1][targetLen+1]; for(int i=0; i < sourceLen+1; i++){ arr[i][0] = i; } for(int j=0; j < targetLen+1; j++){ arr[0][j] = j; } Character sourceChar = null; Character targetChar = null; for(int i=1; i < sourceLen+1 ; i++){ sourceChar = sourceStr.charAt(i-1); for(int j=1; j < targetLen+1 ; j++){ targetChar = targetStr.charAt(j-1); if(sourceChar.equals(targetChar)){ /* * 如果source[i] 等于target[j],则:d[i, j] = d[i-1, j-1] + 0 (递推式 1) */ arr[i][j] = arr[i-1][j-1]; }else{ /* 如果source[i] 不等于target[j],则根据插入、删除和替换三个策略,分别计算出使用三种策略得到的编辑距离,然后取最小的一个: d[i, j] = min(d[i, j - 1] + 1, d[i - 1, j] + 1, d[i - 1, j - 1] + 1 ) (递推式 2) >> d[i, j - 1] + 1 表示对source[i]执行插入操作后计算最小编辑距离 >> d[i - 1, j] + 1 表示对source[i]执行删除操作后计算最小编辑距离 >> d[i - 1, j - 1] + 1表示对source[i]替换成target[i]操作后计算最小编辑距离 */ arr[i][j] = (Math.min(Math.min(arr[i-1][j], arr[i][j-1]), arr[i-1][j-1])) + 1; } } } System.out.println("----------矩阵打印---------------"); //矩阵打印 for(int i=0;i<sourceLen+1;i++){ for(int j=0;j<targetLen+1;j++){ System.out.print(arr[i][j]+"\t"); } System.out.println(); } System.out.println("----------矩阵打印---------------"); return arr[sourceLen][targetLen]; } /** * 计算字符串相似度 * similarity = (maxlen - distance) / maxlen * ps: 数据定义为double类型,如果为int类型 相除后结果为0(只保留整数位) * @param str1 * @param str2 * @return */ public static double getsimilarity(String str1,String str2){ double distance = minDistance(str1,str2); double maxlen = Math.max(str1.length(),str2.length()); double res = (maxlen - distance)/maxlen; //System.out.println("distance="+distance); //System.out.println("maxlen:"+maxlen); //System.out.println("(maxlen - distance):"+(maxlen - distance)); return res; } public static String evaluate(String str1,String str2) { double result = getsimilarity(str1,str2); return String.valueOf(result); } public static void main(String[] args) { String str1 = "2/F20NGNT"; String str2 = "1/F205ONGNT"; int result = minDistance(str1, str2); String res = evaluate(str1,str2); System.out.println("最小编辑距离minDistance:"+result); System.out.println(str1+"与"+str2+"相似度为:"+res); } }
执行结果如下图:

编辑距离主要是为了计算两个字符串的相似度,在查阅资料的时候看到了一篇博客关中文的相似度匹配算法觉得挺有意思的,这里引入了一个 音形码 的概念来计算汉字的相似度,感觉兴趣的可以看看原博主的博客。
中文相似度匹配算法: https://blog.csdn.net/chndata/article/details/41114771
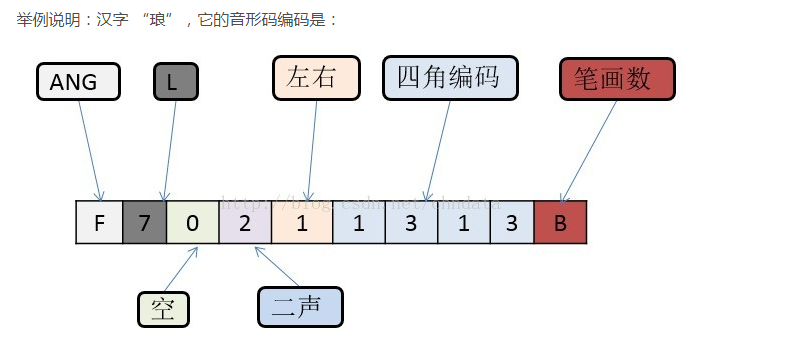
音形码

音形码示例:
这里顺便记录一下mysql函数自动填充时间工具表。
因为hive对数据初始化时每次都要手动更新表 rs_tool_date,往里面插入日期,让里面的数据为 20190101到当前日期前一天为止。(所以就写了这个函数,需要的时候手动运行一下这个函数即可~)
BEGIN
declare i int default 0;
declare len int default 1;
set i=1; -- 从i=1开始,保证存储在数据库中的数据为20190101到当前日期的前一天
set len = DATEDIFF(now(),date'2019-01-01');
-- set len = DATEDIFF(date('2019-07-15'),date'2019-01-01');
DROP TABLE IF EXISTS `rs_tool_date`; -- rs_tool_date
CREATE TABLE `rs_tool_date` (
`ID` bigint(20) NOT NULL AUTO_INCREMENT,
`tool_date` date DEFAULT NULL,
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 ROW_FORMAT=COMPACT;
while i<= len DO
insert into rs_tool_date (tool_date) values(DATE_ADD(now(),INTERVAL -i day));
set i=i+1;
end while;
END
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号