
Zephyr与Linux线程切换
// 本文部分内容来自网络
Zephry线程切换
Zephyr线程列表:
_kernel->current: 当前线程
_kernel->current->next_thread: 下一个线程,最后一个线程的next_thread是0
(struct k_thread)0x12430
entry:线程入口
base->thead_state:当前状态
base->prio: 优先级
base->sched_locked: 锁抢占
base->preempt: 是否可抢占
1. 关于Zephry线程优先级
Zephyr优先级是个整形值,可以是负的或者非负。数值越小,优先级越高。
例如,优先级为4的线程A会比优先级为7的线程B拥有更高优先级,优先级为-2的线程C拥有比线程A和线程B更高的优先级。
协作式线程使用负数优先级数值。一旦变为当前线程,协作线程将会持续保留,直到它执行动作进入未就绪状态。
抢占式线程使用非负数优先级数值。一旦它变为当前线程,如果有协作式线程,或者更高或相等的抢占式线程进入就绪状态,当前抢占式线程将会被取代。
线程优先级定义在struct k_thread结构体中:(thread->base.prio)
配置选项 CONFIG_NUM_COOP_PRIORITIES 以及 CONFIG_NUM_PREEMPT_PRIORITIES 指定不同类型线程的优先级等级数,限定如下的优先级范围:
协作式线程: (-CONFIG_NUM_COOP_PRIORITIES) to -1 抢占式线程: 0 to (CONFIG_NUM_PREEMPT_PRIORITIES - 1)
例如,把5个协作式线程的优先级设置为 -5 到 -1,以及抢占式线程的优先级设置为 0 到 9,笔者项目:
#define CONFIG_NUM_COOP_PRIORITIES 16
另外,struct k_thread结构体中还定义了一个是否可抢占:(thread->base.preempt),这个值和以下两个阈值比较得出当前线程是否能被抢占:
#define _NON_PREEMPT_THRESHOLD 0x0080 –> 128
/* highest value of _thread_base.preempt at which a thread is preemptible */
#define _PREEMPT_THRESHOLD (_NON_PREEMPT_THRESHOLD - 1) --> 127
prio和preempt两个变量之间有相关性,从下面定义可以看出:prio+sched_locked 和preemt组成了一个联合体,总共占用16bit空间;假设该16bit空间的数值最终为0x00f7,那么:
1. union的存放顺序是所有成员都从低地址开始存放,所以preempt值=0x00f7,对于小端格式,prio = 0xf7, sched_locked = 0x00。
2. preempt类型为u16_t,prio格式为s8_t,sched_locked格式为u8_t
s8_t的的范围:-128~-1~0~127(0x80~0xff~0x0~0x7f)
(对于有符号数,计算机统一采用补码进行处理和运算:
反码:正数的反码与其原码相同;负数的反码是对其原码逐位取反,但符号位除外。
补码:正数的补码与其原码相同;负数的补码等于其反码+1。)
对于preempt值来说,大于0x80表明prio值为负数,该线程不可抢占;
3. sched_locked用于可抢占线程的临时锁抢占(_sched_lock函数),每次锁抢占时会将sched_locked减1,解除锁抢占再加1,其取值范围为0x0--0xff--0x1,所以对于可抢占线程,一旦将sched_locked减1后,preempt值也会大于0x80,表明此时已不能被抢占。
1 /* 2 * scheduler lock count and thread priority 3 * 4 * These two fields control the preemptibility of a thread. 5 * 6 * When the scheduler is locked, sched_locked is decremented, which 7 * means that the scheduler is locked for values from 0xff to 0x01. A 8 * thread is coop if its prio is negative, thus 0x80 to 0xff when 9 * looked at the value as unsigned. 10 * 11 * By putting them end-to-end, this means that a thread is 12 * non-preemptible if the bundled value is greater than or equal to 13 * 0x0080. 14 */ 15 union { 16 struct { 17 #if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__ 18 u8_t sched_locked; 19 s8_t prio; 20 #else /* LITTLE and PDP */ 21 s8_t prio; 22 u8_t sched_locked; 23 #endif 24 }; 25 u16_t preempt; 26 };
2. 线程切换的几个时机
(1) 中断处理完成返回时(_IntExit)
1 SECTION_SUBSEC_FUNC(TEXT, _HandlerModeExit, _IntExit) 2 SECTION_SUBSEC_FUNC(TEXT, _HandlerModeExit, _ExcExit) 3 4 ldr r0, =_kernel 5 6 ldr r1, [r0, #_kernel_offset_to_current] 7 8 /* 9 * Non-preemptible thread ? Do not schedule (see explanation of 10 * preempt field in kernel_struct.h). 11 */ 12 ldrh r2, [r1, #_thread_offset_to_preempt] 13 cmp r2, #_PREEMPT_THRESHOLD 14 bhi _EXIT_EXC 15 16 ldr r0, [r0, _kernel_offset_to_ready_q_cache] 17 cmp r0, r1 18 beq _EXIT_EXC 19 20 #ifdef CONFIG_TIMESLICING 21 push {lr} 22 bl _update_time_slice_before_swap 23 pop {r0} 24 mov lr, r0 25 #endif /* CONFIG_TIMESLICING */ 26 27 /* context switch required, pend the PendSV exception */ 28 ldr r1, =_SCS_ICSR 29 ldr r2, =_SCS_ICSR_PENDSV 30 str r2, [r1] 31 32 _ExcExitWithGdbStub: 33 34 _EXIT_EXC: 35 36 pop {r0} 37 mov lr, r0 38 bx lr
切换条件:
1. 当前线程是可抢占线程
2. 线程不是当前就绪最高优先级线程
(2) 有信号量/互斥量等同步信号就绪时(以信号量为例)
1 void k_sem_give(struct k_sem *sem) 2 { 3 unsigned int key; 4 5 key = irq_lock(); 6 7 if (do_sem_give(sem)) { 8 _Swap(key); 9 } else { 10 irq_unlock(key); 11 } 12 }
1 static int do_sem_give(struct k_sem *sem) 2 { 3 struct k_thread *thread = _unpend_first_thread(&sem->wait_q); 4 5 if (!thread) { 6 increment_count_up_to_limit(sem); 7 return handle_poll_events(sem); 8 } 9 (void)_abort_thread_timeout(thread); 10 _ready_thread(thread); 11 _set_thread_return_value(thread, 0); 12 13 return !_is_in_isr() && _must_switch_threads(); 14 }
1 static inline int _must_switch_threads(void) 2 { 3 return _is_preempt(_current) && __must_switch_threads(); 4 }
1 int __must_switch_threads(void) 2 { 3 4 K_DEBUG("current prio: %d, highest prio: %d\n", 5 _current->base.prio, _get_highest_ready_prio()); 6 _dump_ready_q(); 7 8 return _is_prio_higher(_get_highest_ready_prio(), _current->base.prio); 9 10 }
切换条件:
1. 不在中断上下文(如在中断中,可交给中断返回时处理)
2. 当前线程是可抢占线程
3. 线程不是当前就绪最高优先级线程
(3) 当前线程阻塞时(以获取信号量为例)
1 int k_sem_take(struct k_sem *sem, s32_t timeout) 2 { 3 __ASSERT(!_is_in_isr() || timeout == K_NO_WAIT, ""); 4 5 unsigned int key = irq_lock(); 6 7 if (likely(sem->count > 0)) { 8 sem->count--; 9 irq_unlock(key); 10 return 0; 11 } 12 13 if (timeout == K_NO_WAIT) { 14 irq_unlock(key); 15 return -EBUSY; 16 } 17 18 _pend_current_thread(&sem->wait_q, timeout); 19 20 return _Swap(key); 21 }
切换条件:
1. 不在中断上下文(中断不能阻塞)
2. 满足阻塞条件且Timeout非0
(4) 当前线程主动放弃时
k_yield
切换到其它更高或相同优先级的就绪态线程,如果不存在,将立即返回;
1 void k_yield(void) 2 { 3 __ASSERT(!_is_in_isr(), ""); 4 5 int key = irq_lock(); 6 7 _move_thread_to_end_of_prio_q(_current); 8 9 if (_current == _get_next_ready_thread()) { 10 irq_unlock(key); 11 12 } else { 13 _Swap(key); 14 } 15 }
切换条件:
1. 不在中断上下文(中断不能阻塞)
2. 线程不是当前就绪最高优先级线程
k_sleep
让当前线程进入持续一段时间的睡眠非就绪状态。在该时间内允许其它任意优先级的线程得以运行
void k_sleep(s32_t duration) { /* volatile to guarantee that irq_lock() is executed after ticks is * populated */ volatile s32_t ticks; unsigned int key; __ASSERT(!_is_in_isr(), ""); __ASSERT(duration != K_FOREVER, ""); K_DEBUG("thread %p for %d ns\n", _current, duration); /* wait of 0 ms is treated as a 'yield' */ if (duration == 0) { k_yield(); return; } ticks = _TICK_ALIGN + _ms_to_ticks(duration); key = irq_lock(); _remove_thread_from_ready_q(_current); _add_thread_timeout(_current, NULL, ticks); _Swap(key); }
切换条件:
1. 不在中断上下文(中断不能阻塞)
(5)其他改变线程状态的接口
例如k_wakeup(),k_thread_cancel(),k_thread_abort(),k_thread_suspend(),k_thread_resume()等
3. 线程切换方法
Zephyr切换线程都会通过_Swap函数完成,_Swap函数的最终实现与体系结构相关,这里以CortexM0为例:
1 static inline unsigned int _Swap(unsigned int key) 2 { 3 4 #ifdef CONFIG_TIMESLICING 5 _update_time_slice_before_swap(); 6 #endif 7 8 return __swap(key); 9 }
1 SECTION_FUNC(TEXT, __swap) 2 3 ldr r1, =_kernel 4 ldr r2, [r1, #_kernel_offset_to_current] 5 str r0, [r2, #_thread_offset_to_basepri] 6 7 /* 8 * Set __swap()'s default return code to -EAGAIN. This eliminates the need 9 * for the timeout code to set it itself. 10 */ 11 ldr r1, =_k_neg_eagain 12 ldr r1, [r1] 13 str r1, [r2, #_thread_offset_to_swap_return_value] 14 15 #if defined(CONFIG_ARMV6_M) 16 /* No priority-based interrupt masking on M0/M0+, 17 * pending PendSV is used instead of svc 18 */ 19 ldr r1, =_SCS_ICSR 20 ldr r3, =_SCS_ICSR_PENDSV 21 str r3, [r1, #0] 22 23 /* Unlock interrupts to allow PendSV, since it's running at prio 0xff 24 * 25 * PendSV handler will be called if there are no other interrupts 26 * of a higher priority pending. 27 */ 28 cpsie i 29 #elif defined(CONFIG_ARMV7_M) 30 svc #0 31 #else 32 #error Unknown ARM architecture 33 #endif /* CONFIG_ARMV6_M */ 34 35 /* coming back from exception, r2 still holds the pointer to _current */ 36 ldr r0, [r2, #_thread_offset_to_swap_return_value] 37 bx lr
19-21行:写入中断控制盒状态寄存器(ICSR)设置挂起位以触发PendSV异常。
PendSV具有可编程的优先级,利用该特性,将PendSV设置为最低的异常优先级,可以让PendSV异常处理在其他所有中断处理任务完成后执行,这对于上下文切换非常有用。
SVC(系统服务调用,亦简称系统调用)和 PendSV(可悬起系统调用)
它们多用于在操作系统之上的软件开发中。 SVC 用于产生系统函数的调用请求。例如,操作系统不让用户程序直接访问硬件,而是通过提供一些系统服务函数,用户程序使用 SVC 发出对系统服务函数的呼叫请求,以这种方法调用它们来间接访问硬件。因此,当用户程序想要控制特定的硬件时,它就会产生一个 SVC 异常,然后操作系统提供的 SVC 异常服务例程得到执行,它再调用相关的操作系统函数,后者完成用户程序请求的服务。
另一个相关的异常是 PendSV(可悬起的系统调用),它和 SVC 协同使用。一方面, SVC异常是必须立即得到响应的(若因优先级不比当前正处理的高, 或是其它原因使之无法立即响应, 将上访成硬 fault),应用程序执行 SVC 时都是希望所需的请求立即得到响应。另一方面, PendSV 则不同,它是可以像普通的中断一样被悬起的(不像 SVC 那样会上访)。 OS 可以利用它“缓期执行” 一个异常——直到其它重要的任务完成后才执行动作。 悬起 PendSV 的方法是:手工往 NVIC 的 PendSV 悬起寄存器中写 1。 悬起后, 如果优先级不够高,则将缓期等待执行。
线程切换时软件保存的寄存器:
k_thread->callee_saved:
struct _callee_saved {
u32_t v1; /* r4 */
u32_t v2; /* r5 */
u32_t v3; /* r6 */
u32_t v4; /* r7 */
u32_t v5; /* r8 */
u32_t v6; /* r9 */
u32_t v7; /* r10 */
u32_t v8; /* r11 */
u32_t psp; /* r13 */
};
其中psp保存了线程最后被切走时的栈指针,该指针已包含了线程模式向Handler模式切换时硬件保存的寄存器帧,从低地址到高地址依次是:
r0, r1, r2, r3, r12, lr(r14), pc(r15), xpsr

结合callee_saved中存的其他寄存器值,一个完整的现场即可被还原。注意还原现场时r13的值需要加上32(去掉硬件保存的寄存器帧)。
Linux线程切换
在内核里谈切换的时候,Linux并不区分进程与线程,因为这里只有task,一个进程里如果有多个线程,每一个都是一个task。内核实际上切换的就是task。所以,来自同一个进程的不同线程的task和来自不同进程的task对于内核来说并没有区别。)
Linux进程切换的核心代码是函数context_switch(),此函数的骨干内容如下:
static inline void
context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next)
{
switch_mm(oldmm, mm, next);
switch_to(prev, next, prev);
}
#define switch_to(prev,next,last) \
do { \
last = __switch_to(prev,task_thread_info(prev), task_thread_info(next)); \
} while (0)
其中prev是当前进程/切出进程的task_struct指针,next是下一进程/切入进程的task_struct指针。context_switch()主要做两件事情,一件是切换页表,另一件是切换进程上下文。分别由一个函数来实现。
switch_mm switch_mm()的作用是切换切换进程的页表,要做的最重要的事情就是把下一进程的二级页表地址pgd(物理地址)设置到CPU的CP15控制器。进程的页表pgd可以分为两部分来看,0~3G空间部分是用户空间,采用二级映射,每个进程各不相同;3G~4G空间部分是内核空间,采用一级映射,每个进程都相同,其实每个进程的这一块页表内容都是从内核的页表拷贝来的。切换页表的主要目的是切换用户空间的页表,内核空间部分都一样,不需要切换。所以,如果next是一个内核线程的话,并不会调用switch_mm()。
下面是经过简化的switch_mm()汇编代码:
/* r0 = pgd_phys, * r1 = context_id */ ENTRY(cpu_v6_switch_mm) mov r2, #0 orr r0, r0, #TTB_FLAGS_UP mcr p15, 0, r2, c7, c5, 6 @ flush BTAC/BTB mcr p15, 0, r2, c7, c10, 4 @ drain write buffer mcr p15, 0, r0, c2, c0, 0 @ write Translation Table Base Register 0 mcr p15, 0, r1, c13, c0, 1 @ set context ID mov pc, lr ENDPROC(cpu_v6_switch_mm)
其中第8行是最核心的一行,它把pgd的值设置给CP15的C2寄存器,C2即是”Translation Table Base Register 0“(地址转换表基地址寄存器)。
switch_mm()调用完之后,用户空间的内容已经是新的进程了,但这时内核空间还属于老的进程,因为CPU还在老进程的内核栈上面运行。下面要做的就是赶紧把内核空间空间也切换到新进程中去,这就是switch_to()所要做的。
switch_to switch_to()的作用有两个:一是要把当前所运行的进程(切出进程)的现场(包括各个通用寄存器、SP和PC)保存好;二是切换到新进程(切入进程),即取出此前已保存的新进程的现场,并从上次保存的地方继续运行。注意,这里所说的的现场是内核空间的现场,用户空间的现场在中断刚刚发生时已经保存过。
下面是经过简化的switch_to()汇编代码:
/* r0 = previous task_struct, r1 = previous thread_info, r2 = next thread_info
*/
ENTRY(__switch_to)
/* thread_info + TI_CPU_SAVE hold saved cpu context, registers value is stored */
/* now ip hold the address of the context of previous process */
add ip, r1, #TI_CPU_SAVE
/* now r3 hold TP value of next process */
ldr r3, [r2, #TI_TP_VALUE]
/* store current regs to prev thread_info */
stmia ip!, {r4 - sl, fp, sp, lr} @ Store most regs on
/* store CPU_DOMAIN of next to r6 */
ldr r6, [r2, #TI_CPU_DOMAIN]
/* set tp value and domain to cp15 */
mcr p15, 0, r3, c13, c0, 3 @ yes, set TLS register
mcr p15, 0, r6, c3, c0, 0 @ Set domain register
/* now r4 hold the address of the next context */
add r4, r2, #TI_CPU_SAVE
/* put next context to registers */
ldmia r4, {r4 - sl, fp, sp, pc} @ Load all regs saved previously
ENDPROC(__switch_to)
其中第10行和第19行是比较核心的代码,它们分别是保存当前cpu context以及恢复上一次保存的cpu context。这里所说的”上一次“指的是当前进程在上一次处于内核态的时候,当时在离开内核态(切出)的时候,保存了现场。
这里所说的cpu context是由结构体cpu_context所表示的,内容如下。
struct cpu_context_save {
__u32 r4;
__u32 r5;
__u32 r6;
__u32 r7;
__u32 r8;
__u32 r9;
__u32 sl; /* r10 */
__u32 fp; /* r11 */
__u32 sp; /* r13 */
__u32 pc; /* r15 */
__u32 extra[2]; /* Xscale 'acc' register, etc */
};
在switch_to()的第10行,当前正在运行的SVC模式下的各寄存器(包括r4-r9, sp, lr等等)都被保存起来。
在switch_to()的第19行,r4指向的是下一进程的cpu_context结构地址,这一行执行完后,cpu context中所保存的内容就被读进各个寄存器,sp和pc都被更新,现在CPU已经不在刚刚的那个内核栈上了。
第10行和第19行的寄存器列表有一处区别:第10行的最后一个寄存器是lr,即调用__switch_to()的返回地址;而第19行的最后一个寄存器是pc。这就是说,在切换的时候,当前进程在切回来的时候会从__switch_to()的下一条指令开始执行,这正是内核所需要的。
cpu_context_save存在task中的thread结构体:
struct thread_info {
unsigned long flags; /* low level flags */
int preempt_count; /* 0 => preemptable, <0 => bug */
mm_segment_t addr_limit; /* address limit */
struct task_struct *task; /* main task structure */
struct exec_domain *exec_domain; /* execution domain */
__u32 cpu; /* cpu */
__u32 cpu_domain; /* cpu domain */
struct cpu_context_save cpu_context; /* cpu context */
……
thread结构体地址位于task的栈起始地址,即:
(struct thread_info *) ((struct task_struct)*0xC2E61680 –> stack)
为什么寄存器R12不需要保存
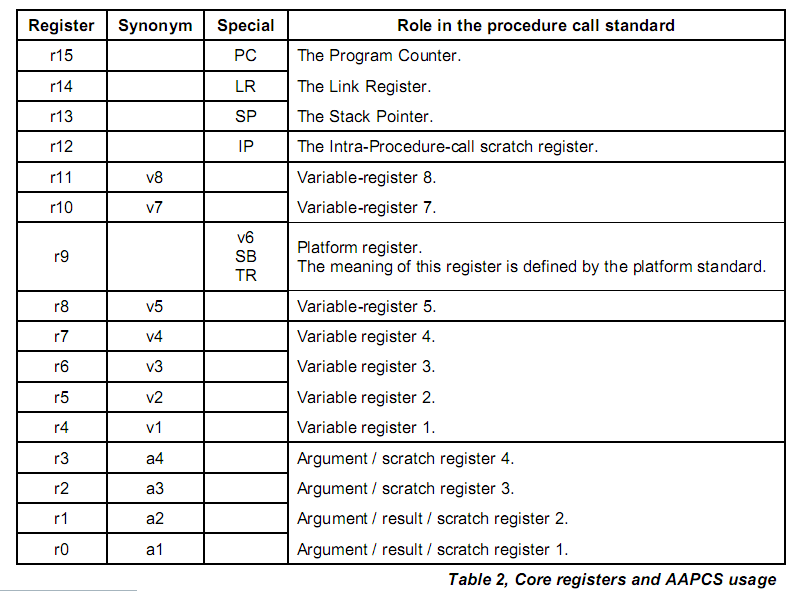
根据AAPCS (Procedure Call Standard for the ARM Architecture),寄存器的定义:
r0-r3 – 参数传递以及返回值寄存器,scratch register
r4-r11 – 变量寄存器,preserved registers
r12 – IP, 内部调用暂存寄存器, scratch register
r13-r15 – 特殊寄存器
main:
...
BL foo
...
foo :
...
BX lr
Main():caller
foo() : callee.
scratch register: 对于callee来说,不需要压栈保存寄存器的原始值;如果有需要,caller需要保存
preserved registers:callee如果会改变这些寄存器的值,则需要在入口保存原始值
R12(IP)的使用:
1.用作普通临时寄存器
mov ip, sp
stmfd sp!, {fp, ip, lr, pc} //ARM 的经典函数入口代码,用ip暂存sp
2.用于链接器实现长地址跳转
<Procedure Call Standard for the ARM Architecture> :
Register r12 (IP) may be used by a linker as a scratch register between a routine and any subroutine it calls (for details, see §5.3.1.1, Use of IP by the linker). It can also be used within a routine to hold intermediate values between subroutine calls.
Both the ARM- and Thumb-state BL instructions are unable to address the full 32-bit address space, so it may be necessary for the linker to insert a veneer between the calling routine and the called subroutine. Veneers may also be needed to support ARM-Thumb inter-working or dynamic linking. Any veneer inserted must preserve the contents of all registers except IP (r12) and the condition code flags; a conforming program must assume that a veneer that alters IP may be inserted at any branch instruction that is exposed to a relocation that supports inter-working or long branches.
所以,R12的值可能会被链接器插入的veneer程序修改掉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号