源码阅读-java基础-java.lang.Object
java.lang.Object是所有类的父类。更准确的说是所有类,包括数组的超类。所以源码阅读系列从它先开始。
1、概览
以下是java.lang.Object的所有属性和方法。
public class Object { private static native void registerNatives(); static { registerNatives(); }
public native int hashCode();
public boolean equals(Object obj) { return (this == obj); }
protected native Object clone() throws CloneNotSupportedException;
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
protected void finalize() throws Throwable {
} public final native Class<?> getClass();
public final native void notify();
public final native void notifyAll();
public final native void wait(long timeout) throws InterruptedException;
public final void wait(long timeout, int nanos) throws InterruptedException { if (timeout < 0) { throw new IllegalArgumentException("timeout value is negative"); } if (nanos < 0 || nanos > 999999) { throw new IllegalArgumentException("nanosecond timeout value out of range"); } if (nanos > 0) { timeout++; } wait(timeout); } public final void wait() throws InterruptedException { wait(0); } }

2、名词解释
2.1、本地方法与native
Java有两种方法:Java方法和本地方法。Java方法是由Java语言编写,编译成字节码,存储在class文件中。本地方法是由其他语言(比如C,C++,或者汇编)编写的,编译成和处理器相关的机器代码。本地方法保存在动态连接库中,格式是各个平台专有的。Java方法是平台无关的,但本地方法却不是。运行中的Java程序调用本地方法时,虚拟机装载包含这个本地方法的动态库,并调用这个方法。本地方法是联系Java程序和底层主机操作系统的连接方法。
被native修饰的方法是一个本地方法,简单的讲,一个被native修饰的方法就是告知Java调用一个非Java实现的方法,由于Java的理念是“Write Once, Run Anywhere”,因此高移植性也让Java丧失了对底层的控制。但有的时候必须访问系统底层权限或系统资源的时候,又或者丧失移植性来追求程序的效率是个不错的想法的时候,纯Java的实现可能很复杂或者根本不可能的时候,就需要去调用一个native修饰的本地方法。和abstract修饰的方法一样,被native修饰的方法也只有声明。没有实现体,两者唯一的区别在于abstract修饰的方法是一个抽象方法,需要由该类的非抽象子类或实现一个接口的类来提供实现,而native修饰的方法需要一个非Java语言提供实现,比如C,因此使用native关键字将使程序失去跨平台的能力。
2.2、registerNatives()
不光是Object类,甚至System类、Class类、ClassLoader类、Unsafe类等等,都能在类代码中找到如下代码:private static native void registerNatives(); static { registerNatives(); }
registerNatives本质上就是一个本地方法,但这又是一个有别于一般本地方法的本地方法,该方法是用来注册本地方法的。上述代码的功能就是先定义了registerNatives()方法,然后当该类被加载的时候,调用该方法完成对该类中本地方法的注册。
在Object类中,除了有registerNatives这个本地方法之外,还有hashCode()、clone()等本地方法,而在Class类中有forName()这样的本地方法等等。也就是说,凡是包含registerNatives()本地方法的类,同时也包含了其他本地方法。所以,显然,当包含registerNatives()方法的类被加载的时候,注册的方法就是该类所包含的除了registerNatives()方法以外的所有本地方法。
一个Java程序要想调用一个本地方法,需要执行两个步骤:第一,通过System.loadLibrary()将包含本地方法实现的动态文件加载进内存;第二,当Java程序需要调用本地方法时,虚拟机在加载的动态文件中定位并链接该本地方法,从而得以执行本地方法。registerNatives()方法的作用就是取代第二步,让程序主动将本地方法链接到调用方,当Java程序需要调用本地方法时就可以直接调用,而不需要虚拟机再去定位并链接。
使用registerNatives()方法的三点好处:
1)通过registerNatives方法在类被加载的时候就主动将本地方法链接到调用方,比当方法被使用时再由虚拟机来定位和链接更方便有效;
2)如果本地方法在程序运行中更新了,可以通过调用registerNative方法进行更新;
3)Java程序需要调用一个本地应用提供的方法时,因为虚拟机只会检索本地动态库,因而虚拟机是无法定位到本地方法实现的,这个时候就只能使用registerNatives()方法进行主动链接。
4)通过registerNatives()方法,在定义本地方法实现的时候,可以不遵守JNI命名规范
2.3、权限修饰符public与protected
既然java.lang.Object是所有类的父类,为什么有些方法,比如:clone(),finalize()要设计成protected修饰?
2.3.1、关于protected的理解
很多介绍博客/书籍都对protected介绍的比较的简单,基本都是一句话,就是:被protected修饰的成员对于本包和其子类可见。这种说法有点太过含糊,常常会对大家造成误解。实际上,protected的可见性在于两点:
1)父类的protected成员是包内可见的,并且对子类可见;
2)若子类与父类不在同一包中,那么在子类中,子类实例可以访问其从父类继承而来的protected方法,而不能访问父类实例的protected方法。
在碰到涉及protected成员的调用时,首先要确定出该protected成员来自何方,其可见性范围是什么,然后就可以判断出当前用法是否可行。
2.3.2、用protected修饰的原因
利用protected修饰clone方法,是为了安全考虑。Object类中的clone方法是浅拷贝,如果是对象,它拷贝的只是这个对象的一个引用,而这个引用仍然指向那个对象,当我们改变这个引用的属性时,原来对象也会跟着改变,这不是我们希望看到的。但是Object类肯定做不到深拷贝,因为它不知道你的类里有哪些引用类型,所以把修饰符定义为protected,这样想要在其他任何地方调用这个类的clone方法,这个类就必须去重写clone方法并且把修饰符改为public,这样在任何地方都可以调用这个类的clone方法了。
总结:用protected修饰clone方法,主要是为了让子类去重写它,实现深拷贝,以防在其他任何地方随意调用后修改了对象的属性对原来的对象造成影响。
3、各个方法
3.1、Class<?> getClass()
返回此对象(Object)的运行时类,即一个Class。
3.2、hashCode():返回对象的哈希码。
3.2.1、哈希,哈希值,哈希表
什么是哈希——hash是把任意长度的输入通过散列算法变换成固定长度的输出,该输出就是散列值(哈希值)。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。特点是:压缩,同一输入相同输出,存在数据冲突。——百度百科
哈希值——通过哈希算法得到的对象的值。常见的哈希算法有:直接取余法,乘法取整法,平方取中法。
哈希表——通过hash算法得到的hash值就在这张hash表中,也就是说,hash表就是所有的hash值组成的。hashcode就是在hash表中有对应的位置。
哈希code与对象的地址是不同的。hashcode代表对象的地址说的是对象在hash表中的位置,物理地址说的对象存放在内存中的地址,那么对象如何得到hashcode呢?通过对象的内部地址(也就是物理地址)转换成一个整数,然后该整数通过hash函数的算法就得到了hashcode。举个例子,hash表中有 hashcode为1、hashcode为2、(…)3、4、5、6、7、8这样八个位置,有一个对象A,A的物理地址转换为一个整数17(这是假如),就通过hash算法(比如:直接取余算法),17%8=1,那么A的hashcode就为1,且A就在hash表中1的位置。
3.2.2、哈希值的作用
为什么hashcode不直接写物理地址呢,还要另外用一张hash表来代表对象的地址?HashCode的存在主要是为了查找的快捷性。
为什么hashcode就查找的更快,比如:我们要存放1-1000的数到内存中,在其中要存放1000个不一样的数字,用最笨的方法,就是存一个数字,就遍历一遍,看有没有相同得数,当存了900个数字,开始存901个数字的时候,就需要跟900个数字进行对比,这样就很麻烦,很是消耗时间。hash表中有1、2、3、4、5、6、7、8个位置,存第一个数,hashcode为1,该数就放在hash表中1的位置,存到100个数字,hash表中8个位置会有很多数字了,1中可能有20个数字。存101个数字时,他先查hashcode值对应的位置,假设为1,那么就有20个数字和他的hashcode相同,他只需要跟这20个数字相比较(equals),如果没一个相同,那么就放在1这个位置,这样比较的次数就少了很多,实际上hash表中有很多位置,这里只是举例只有8个,所以比较的次数会让你觉得也挺多的,实际上,如果hash表很大,那么比较的次数就很少很少了。
3.2.3、hashCode()与equals()的关系
通过上面放数的例子,我们可以知道:
1)如果两个对象equals相等,那么这两个对象的HashCode一定也相同;
2)如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置;
所以为了遵从这个定律,我们重新hashCode()方法后,一定要重写toString()方法,不然上面的两条规则就不满足了。
3.3、equals()
比较两个对象是否相等。注意java.lang.Object里面equals的实现时采用的==实现的,就是说比如有A,B两个对象,则比较的是A,B的堆内存地址是否相同,指向的是不是同一个内存区域。
但是有时,我们需要比较对象的内容,比如比较两个person的身份证号否一样来确定是否是同一人,如果用原生的equals(继承来的),则一般情况下判断的结果是两个人,这肯定不行。怎么办呢?就需要重写equas方法,但是注意啊,重写equals时,必须重新hashCode方法,理由前面说了。
equals的几个特性:自反性,对称性,传递性,一致性。了解一下就好。
3.4、clone()
clone()方法是浅拷贝。这个方法比较特殊,有空我单独写篇博客介绍;
3.4.1、深拷贝与浅拷贝
深拷贝和浅拷贝最根本的区别在于是否真正获取一个对象的复制实体,而不是引用。
假设B复制了A,修改A的时候,看B是否发生变化:如果B跟着也变了,说明是浅拷贝,拿人手短!(修改堆内存中的同一个值);如果B没有改变,说明是深拷贝,自食其力!(修改堆内存中的不同的值)。
浅拷贝(shallowCopy)只是增加了一个指针指向已存在的内存地址。深拷贝(deepCopy)是增加了一个指针并且申请了一个新的内存,使这个增加的指针指向这个新的内存,使用深拷贝的情况下,释放内存的时候不会因为出现浅拷贝时释放同一个内存的错误。浅复制:仅仅是指向被复制的内存地址,如果原地址发生改变,那么浅复制出来的对象也会相应的改变。深复制:在计算机中开辟一块新的内存地址用于存放复制的对象。
3.5、toString():返回对象的“全限定名@哈希值”
如果类不重写toString()方法,那就返回“全限定名@哈希值”,否则返回重写后的内容。
3.6、notify()与notifyAll()
notify方法只唤醒一个等待(对象的)线程并使该线程开始执行。所以如果有多个线程等待一个对象,这个方法只会唤醒其中一个线程,选择哪个线程取决于操作系统对多线程管理的实现。notifyAll 会唤醒所有等待(对象的)线程,尽管哪一个线程将会第一个处理取决于操作系统的实现。如果当前情况下有多个线程需要被唤醒,推荐使用notifyAll 方法。比如在生产者-消费者里面的使用,每次都需要唤醒所有的消费者或是生产者,以判断程序是否可以继续往下执行。
3.7、wait()、wait(timeout)、wait(timeout,nanos)
wait()使当前线程阻塞,前提是 必须先获得锁,一般配合synchronized 关键字使用,即,一般在synchronized 同步代码块里使用 wait()、notify/notifyAll() 方法。
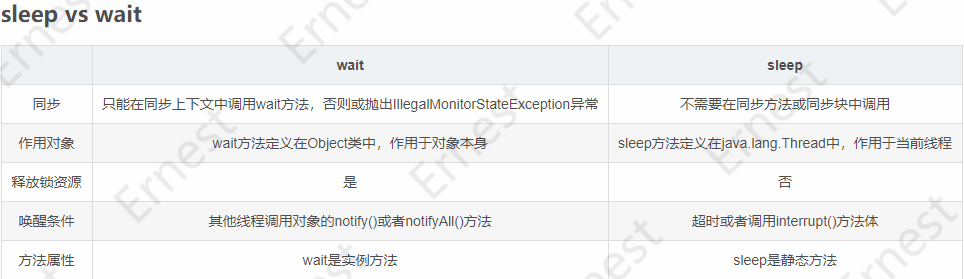
3.7.1、wait()与sleep()的区别
3.8、finalize()
当垃圾回收器将要回收对象所占内存之前被调用,即当一个对象被虚拟机宣告死亡时会先调用它finalize()方法,让此对象处理它生前的最后事情(这个对象可以趁这个时机挣脱死亡的命运)。finalize()只会在对象内存回收前被调用一次。finalize()的调用具有不确定行,只保证方法会调用,但不保证方法里的任务会被执行完(比如一个对象手脚不够利索,磨磨叽叽,还在自救的过程中,被杀死回收了)。
虽然以上以对象救赎举例,但finalize()的作用往往被认为是用来做最后的资源回收。基于在自我救赎中的表现来看,此方法有很大的不确定性(不保证方法中的任务执行完)而且运行代价较高。所以用来回收资源也不会有什么好的表现。综上:finalize()方法并没有什么鸟用。至于为什么会存在这样一个鸡肋的方法:《深入理解java虚拟机:JVM高级特性与最佳实践》中说“它不是C/C++中的析构函数,而是Java刚诞生时为了使C/C++程序员更容易接受它所做出的一个妥协”。
4、参考文档
1)一文秒懂Java(jdk11) native关键字的使用
2)Object类中的registerNatives方法的作用深入介绍
5)Object类中clone()方法的修饰符为什么是protected

 浙公网安备 33010602011771号
浙公网安备 33010602011771号