[MySQL]join的底层原理
简单嵌套循环算法:SNLJ (simple-nested-loop-join)
当我们的join连接字段没有建立索引或者索引失效,并且数据量较小的情况下,可能会使用此算法优化查询,本质上就是循环匹配,连接比如有A表,B表,两个表JOIN的话会拿着A表的连表条件一条一条在B表循环,匹配A表和B表相同的id 放入结果集,这种效率是最低的。
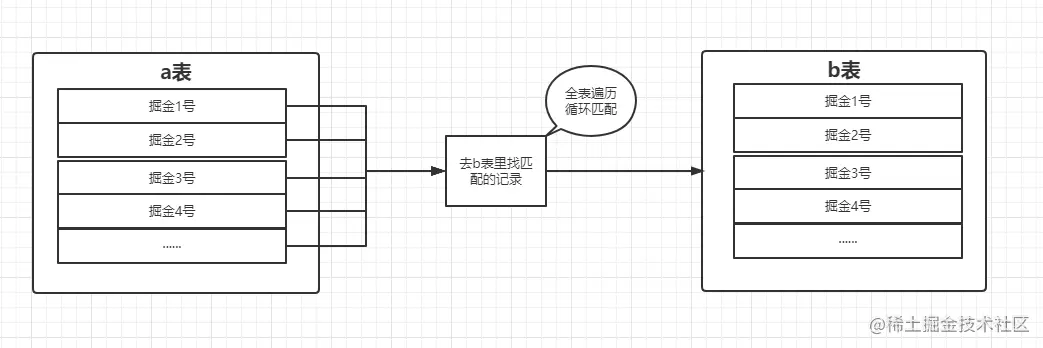
这种方法有两个很糟糕的地方,一个是,IO次数太多了,每次读取出一条记录来,很耗时间。第二是全表扫描的效率太低了,不如走索引。下面两个算法就是对第一个算法的不同方面的改进。
索引嵌套循环算法:INLJ (index-nested-loop-join)
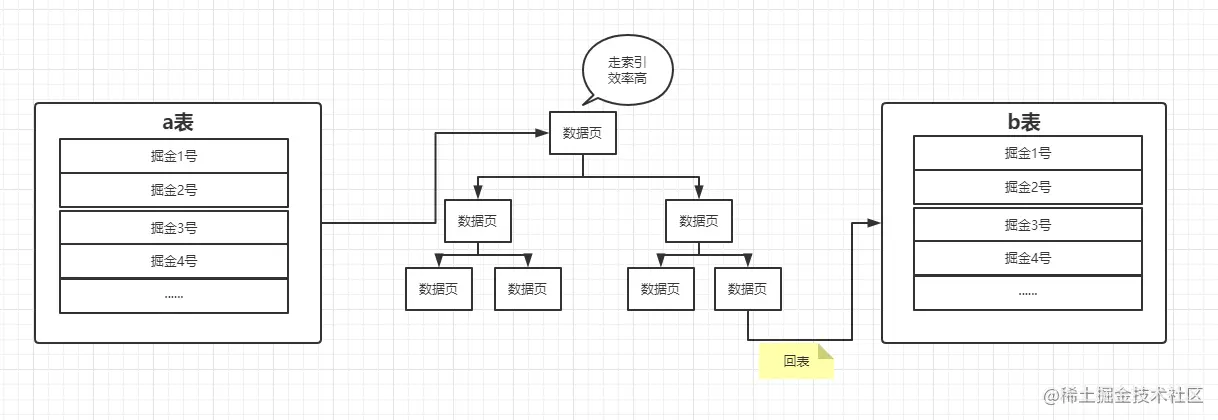
在join的关联字段有索引的情况下,显然对于驱动表使用关联字段去匹配被驱动表可以使用到索引,如下如:
很明显,此算法的效率比第一种高,因为走了索引,我们都知道索引的数据是排好序的,所以读取磁盘的时候是顺序io,我们来看下此算法的消耗。
驱动表的扫描次数:只需要一次。
被驱动表的扫描次数:0次,因为走了索引。
读取记录数:驱动表条数+匹配次数。
join比较次数: 匹配次数。
回表次数:如果是主键索引,那么不需要回表,如果是非聚簇索引那么回表次数就是匹配次数。
批量嵌套循环算法:INLJ (block-nested-loop-join)
还是在没索引的情况下,此算法是基于优化SNLJ算法的补充,因为在大数据量的情况下,驱动表的每条记录都去循环被驱动表,io的开销太高了,所以此算法就是一次性将多条记录放在一次循环里和被驱动表匹配,如下图:
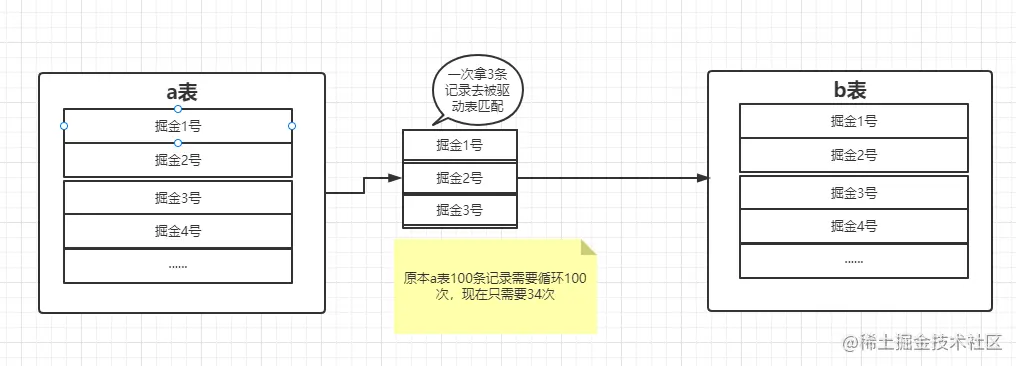
驱动表的扫描次数:只需要一次。
被驱动表的扫描次数:批量匹配的次数。
读取记录数:驱动表条数+驱动表条数 * 匹配次数。
join比较次数: 匹配次数。
回表次数:0次。
补充:一次批量你拿多少条记录和你MySQL的join_buffer和查询字段的大小、多少都有直接关系,所以说尽量只查询需要的字段,非必要字段会占用join_buffer的内存,同时返回的时候还会占用更多的内存和带宽资源。
工作中我们可以将join_buffer_size设置为服务器最大内存的75%左右。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号