【Java复健指南15】链表LinkedList及其说明
链表LinkedList by Java
之前有写过一些记录(引用),但是忘了乱了,现在重新梳理一遍
链表是Java中List接口的一种实现
定义(引用)
链表(linked list)是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的.
链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域(data),另一个是存储下一个结点地址的指针域(next),如下图所示:
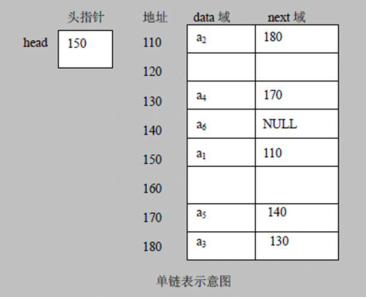
总结一下
1)链表是以节点的方式来存储,是链式存储
2)每个节点包含 data 域, next 域:指向下一个节点
3)如图:发现链表的各个节点不一定是连续存储.
4)链表分带头节点的链表和没有头节点的链表,根据实际的需求来确定
优势
相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
构建链表
由前面的介绍可知,链表这一数据结构中,最关键的东西就是节点
简单来说:要实现链表,需要先实现(定义)构成链表的节点
不同类型的链表主要也取决于对节点的不同定义
实现链表节点类
单链表的节点结构
Class Node<V>{
V value;
Node next;
}
对应到具体代码实现,每个ListNode对象(注意是对象)就代表一个节点
class ListNode{
public int val;//数据域
//ps:为什么这么写?
//基于链表节点的定义,指针域存放的是下一个节点的地址
//那么下一个节点怎么样才可以产生地址呢?当然是在创建下一个节点对象的时候产生咯
//所以这里需要实例化节点类来创建下一个节点,同时获取到下一个节点的地址,于是便有了下面的写法
public ListNode next;//指针域
//构造函数(无参)
public ListNode(){
}
//构造函数(有一个参数)
public ListNode(int val){
this.val = val;
}
//构造函数(有两个参数)
public ListNode(int val, ListNode next){
this.val = val;
this.next = next;
}
}
由以上结构的节点依次连接起来所形成的链叫单链表结构。
双链表的节点结构
Class Node<V> {
V value;
Node prev;
Node next;
}
对应到具体代码实现
class ListNode{
public int val;//数据域
public ListNode prev;//指向上一个节点,前指针
public ListNode next;//指向下一个节点,后指针
//构造函数
public ListNode(int a){
this.val = a;
}
}
由以上结构的节点依次连接起来所形成的链叫双链表结构。
如何使用链表
链表是一种数据结构
本质上是利用了"创建对象会产生地址"这一机制实现的(详见P3)
使用链表的一个过程:定义链表节点类-->定义链表类-->为链表类编写一系列你需要的类方法(为了操控链表)-->在主类中实例化链表类并使用各种类方法达成目的
那现在链表节点定义完了,把这些节点按照定义给连接起来,就构成一个链表了
实例:翻转链表
疑问
我在刚接触链表的时候常常会有疑惑:
我到底需要完成哪些部分?
刷题时要写哪些部分?
下面通过一个示例来说明链表的完整实现过程
例子:实现链表的翻转(完整代码,包括main方法)
public class TestLinkedList {
public static void main(String[] args) {
//这里用手动连接节点的方式创建了一个链表
//要是你愿意也可以在MyLinkedList写一个方法来创建链表
ListNode head1 = new ListNode(1);
head1.next = new ListNode(2);
head1.next.next = new ListNode(3);
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.printLinkedList(head1);
head1 = myLinkedList.reverseList(head1);
myLinkedList.printLinkedList(head1);
}
}
// 定义一个链表节点类
class ListNode{
public int val;//数据域
public ListNode next;//指针域
//构造函数(无参)
public ListNode(){
}
//构造函数(有一个参数)
public ListNode(int val){
this.val = val;
}
//构造函数(有两个参数)
public ListNode(int val, ListNode next){
this.val = val;
this.next = next;
}
}
//定义一个操控链表节点的类
class MyLinkedList {
// 创建一个单链表反转方法
public ListNode reverseList(ListNode head) {
ListNode pre = null; //指向当前节点的前一个节点的指针
ListNode cur = head; //指向当前节点的指针
ListNode tmp; //用于保存当前节点的下一节点,防止链表断掉
while (cur != null) {
//先将当前节点的后一个节点的地址保存
tmp = cur.next;
//将当前节点的后一个节点指针指向当前节点的前一个节点
cur.next = pre;
//将pre指向当前节点位置
pre = cur;
//将当前节点位置后移
//此时已经是2-1-3了
cur = tmp;
}
//等pre指到链表尾部(null)时结束并返回前一个值
//此时链表变为3-2-1
return pre;
}
//创建一个链表打印方法
public void printLinkedList(ListNode head) {
System.out.print("Linked List: ");
while (head != null) {
System.out.print(head.val + " ");
head = head.next;
}
System.out.println();
}
}
这个例子中我尝试将使用链表这个数据结构的整个流程都写清楚
那么无非就分为两大部分:链表节点类和操控链表节点的类
链表节点类
这里就只是单纯定义一个链表的节点应该是什么样的,其余的工作不用管
比如在LeetCode中,如果涉及链表的题,答题模板开头都会给出他们是怎么定义链表节点的
(类似这种)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
操控链表节点的类
这里是实现"链表节点-->链表"的类
所有对于节点的操作都可以在这里定义
比如最基本的:创建节点、对节点进行CURD等
我们需要对节点实现的一些算法也需要以类方法的形式给出(比如例子中的翻转操作)
结论
在LeetCode时,涉及链表的题,我们需要写两个部分:
- 创建节点的方法
这没什么好说的,先要把人家给的链表节点连接成需要的链表
- 操控节点的某种算法(以方法的形式实现)
后台会去调用这个算法来验证你对于链表的操控情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号