【生成对抗网络学习 其三】BiGAN论文阅读笔记及其原理理解
参考资料:
1、https://github.com/dragen1860/TensorFlow-2.x-Tutorials
2、《Adversarial Feature Learning》
本次是对阅读BiGAN论文的一个记录,包含我自己对于BiGAN的一些理解
因为BiGAN在代码实现上没有很大的不同,甚至类似经典GAN(详见:https://www.cnblogs.com/DAYceng/p/16365562.html),所以这里不做介绍
参考1中有源码
依然是免责声明:水平有限,有错误请各位指正,谢谢了
注:图片刷不出来可能需要fq,最近jsdelivr代理好像挂了。
双向GAN网络(BiGAN)
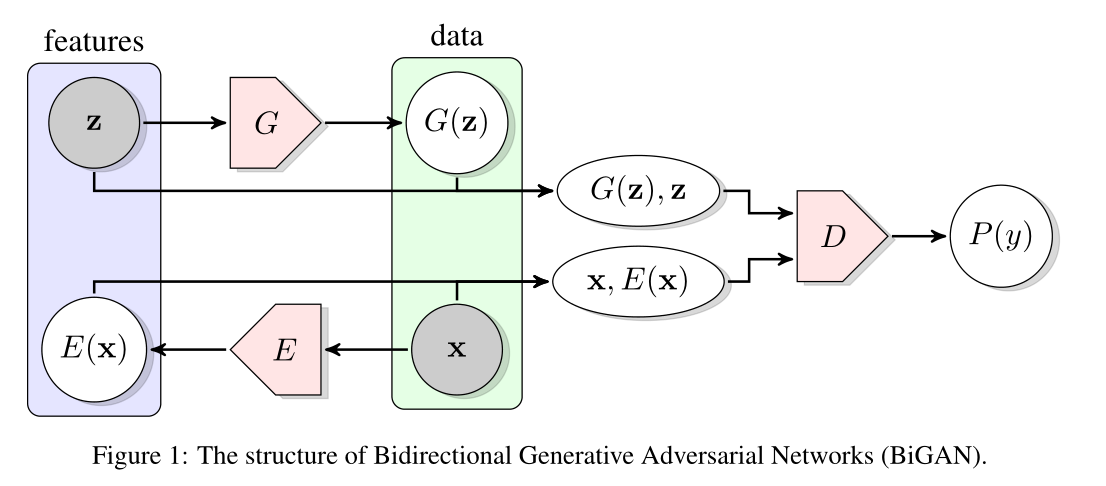
BiGAN相较于GAN更多的是结构上的改进,除了标准GAN框架中的生成器G,BiGAN还新增了一个编码器E
结构
整个结构包括三部分:Encode网络(编码器E),G网络(生成器G),D网络(判别器D)
-
Encode网络,提取原始图片的隐变量
-
G网络,将噪声生成图片
-
D网络,判断这个数据对(原始图片和隐变量 生成图片和噪声)是来自编码器E还是生成器G
根据论文的说法:“编码器E将数据x映射到潜在表征z”
结合结构图,“潜在表征z”应该对应E(x),也就是“真实数据在对应噪声域下的映射”
文章认为,编码器E给出的对应编码具有某种语义特征,因此E(x)可以被认为是数据x的某种标签
判别器D在判断什么?
这个问题刚开始想会有点奇怪,因为经典的GAN是去判别“输入数据是不是真实数据”。
而BiGAN中不太一样,这里的输入变成了数据对(【数据,数据在噪声域下的变换】)
并且在BiGAN中,真实数据从始至终没有直接输入过判别器D,也就是说判别器D从来也没见过真实数据
判别器D所学习到的真实数据的特征都是编码器E“告诉”它的
而编码器E在干什么呢?它在学习(提取)真实数据的特征,这些特征有可能是更高维度的更抽象的特征,有可能有助于刻画原来的真实数据,有可能也没什么效果。但是编码器E是不知道这些的,它只有尽可能的去提取特征(这就是我们训练编码器E的过程)
并且由于我们的生成器G也会生成图片,这些图片也有对应的所谓特征,因为假图片是由随机噪声生成的,那么随机噪声就是这些假图片的特征。因此,编码器E提取的真实图片的特征也需要落到与随机噪声相同的空间域内,这样才可以去进行判别。(计算相似度)
那么现在可以总结一下了:
BiGAN中的判别器D在"区分"当前的输入究竟是编码器E给的真实数据的特征,还是此时生成器G用来生成假图片的随机噪声
编码器E与生成器G的目的
明白了判别器D在做什么,现在要理解一下编码器E和生成器G在干嘛了
我们会很自然地类比经典GAN得出结论:编码器E和生成器G在尽可能的欺骗判别器D
为了达到这个目的,编码器E与生成器G需要不断接近对方的形式,对应原文中的就是:
we will both argue intuitively and formally prove that the encoder and generator must learn to invert one another in order to fool the BiGAN discriminator.
"编码器E与生成器G需要学会互相反转"
通俗一点解释就是:对于编码器E来说,虽然它真的是从真实数据中提取特征,但在不断训练的过程中,它也逐渐学习到了生成器G生成图片的特征,所以编码器E会故意模仿假图片的特征输送给判别器D,测试判别器能否分辨出来。
这就是BiGAN的结构图为什么把编码器E和生成器G的输入输出框在一起的原因,因为他们之间互相联系(是有可能互换的)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号