【生成对抗网络学习 其二】GAN(keras实现)代码阅读笔记
想来想去还是记录一下吧,主要是怕以后时间长忘了
好记性不如烂笔头
代码来自eriklindernoren的开源GAN实现:https://github.com/eriklindernoren/Keras-GAN
主要是添加了一些注解,大家可以参考原工程来看
因为dcgan本质上与gan没什么区别(在实现时就是把全连接层换成卷积层了而已),所以就不介绍了
依然是免责声明:水平有限,有错误请各位指正,谢谢了
接着上回的(https://www.cnblogs.com/DAYceng/p/16364564.html)继续
GAN的训练
整体结构如下
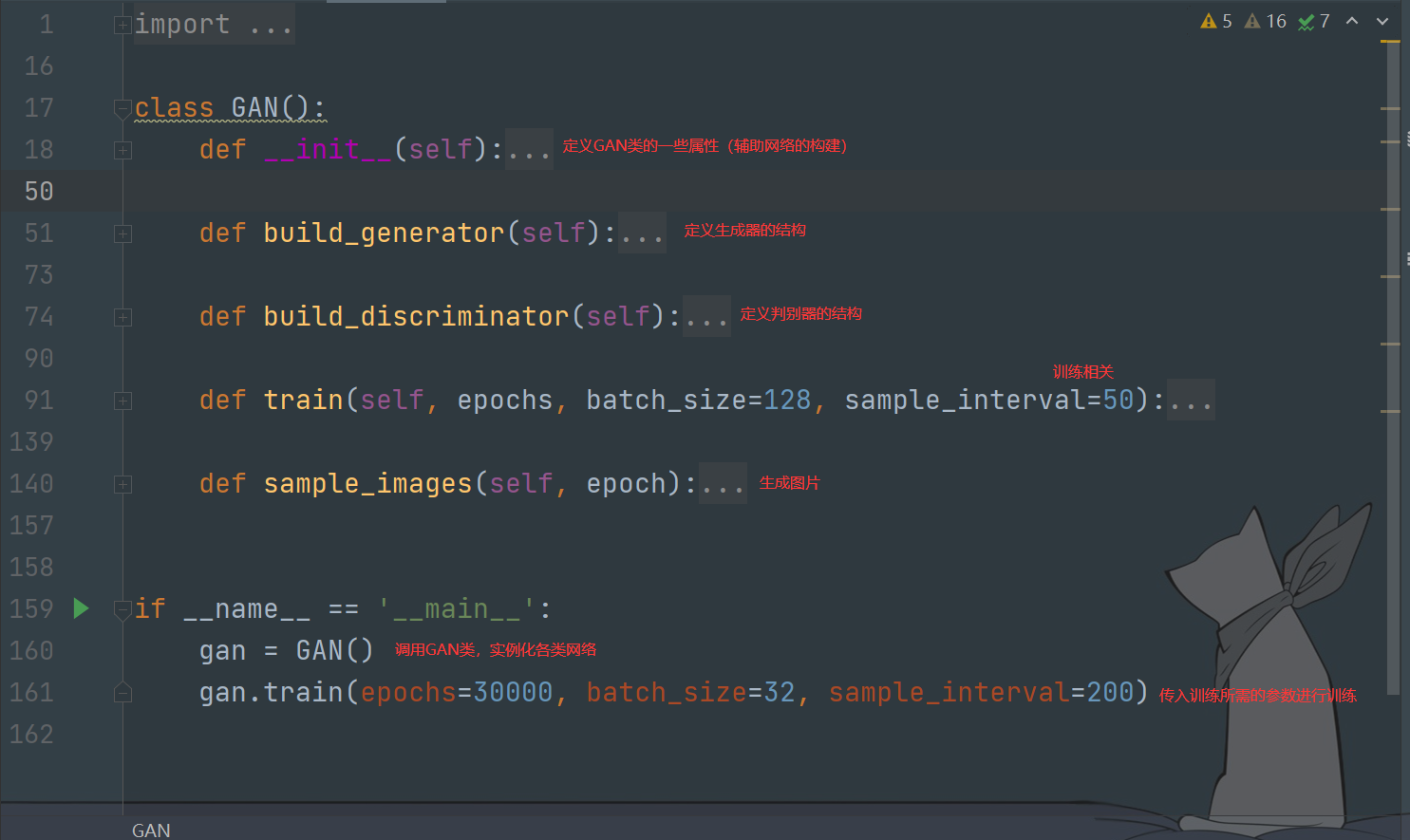
类属性
def __init__(self):
# 定义输入图片的尺寸、通道数和噪声的维数
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.latent_dim = 100
optimizer = Adam(0.0002, 0.5)
# 实例化判别器并指定训练时使用的优化器、loss等
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Build the generator
self.generator = self.build_generator()
# 为生成器设置一个输入层Input,形状为100维
z = Input(shape=(self.latent_dim,))
img = self.generator(z)
'''
https://blog.csdn.net/qq_38669138/article/details/109029782
说明:这里设置不训练判别器并不是判别器就一直不会训练
在train()中还是会通过train_on_batch的方式去训练判别器的
原因:
当discriminator被compile之后,即使设置了discriminator.trainable=False,
该discriminator仍然可以通过train_on_batch的方式被训练;
但是如果discriminator在被compile之前就把训练状态设置为False,
那么即使是使用discriminator.train_on_batch的方式也不能训练该判别器。
'''
self.discriminator.trainable = False
# 将生成器生成的图片输入判别器
validity = self.discriminator(img)
'''
使用Model构建一个网络
该网络由一个生成器层和一个判别器层组成
通过训练该网络,让生成器尽可能骗过判别器,也就是说,该网络的作用是训练生成器
由于之前的设置,该网络训练过程中,其判别器层不训练
'''
self.combined = Model(z, validity)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
生成器定义
def build_generator(self):
# 使用Sequential方式构建生成器
model = Sequential()
# 输入为100维的随机噪声数据,经过第一层全连接层后输出为256维
model.add(Dense(256, input_dim=self.latent_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))# 经过第二层全连接层,输出为512维
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))# 经过第三层全连接层,输出为1024维
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
# 经过第四层全连接层,输出为设置的图片的尺寸(这里是28*28,也就是784维)
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))# Reshape成1*28*28
model.summary()# 打印网络结构
# 下面两句就是给定输入,获取一个输出
# 有点类似pytorch模型类中forward函数的意思
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img) # 返回构造好的模型
判别器定义
def build_discriminator(self):
# 使用Sequential方式构建判别器
model = Sequential()
# 将输入的图片展平并输入全连接层
model.add(Flatten(input_shape=self.img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))# 最后通过维度是1的全连接层
model.summary()
img = Input(shape=self.img_shape)
validity = model(img)
return Model(img, validity)
训练部分
def train(self, epochs, batch_size=128, sample_interval=50):
# 载入数据集
(X_train, _), (_, _) = mnist.load_data()
# 将数据调整到-1~1范围上
X_train = X_train / 127.5 - 1.
X_train = np.expand_dims(X_train, axis=3)# 增加X_train的维度
# 创建标签(判断为真/假,1/0)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# 根据索引,随机从数据集中选择图片数据
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# 使用Sequential建立的模型可以通过predict方法返回输出值
gen_imgs = self.generator.predict(noise)
# 输入真实图片与生成图片训练单独判别器
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
# 产生正态分布的随机噪声
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# 训练combined网络,注意,其中的判别器不训练
g_loss = self.combined.train_on_batch(noise, valid)
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
if epoch % sample_interval == 0:
self.sample_images(epoch)
WGAN的训练
整体结构如下
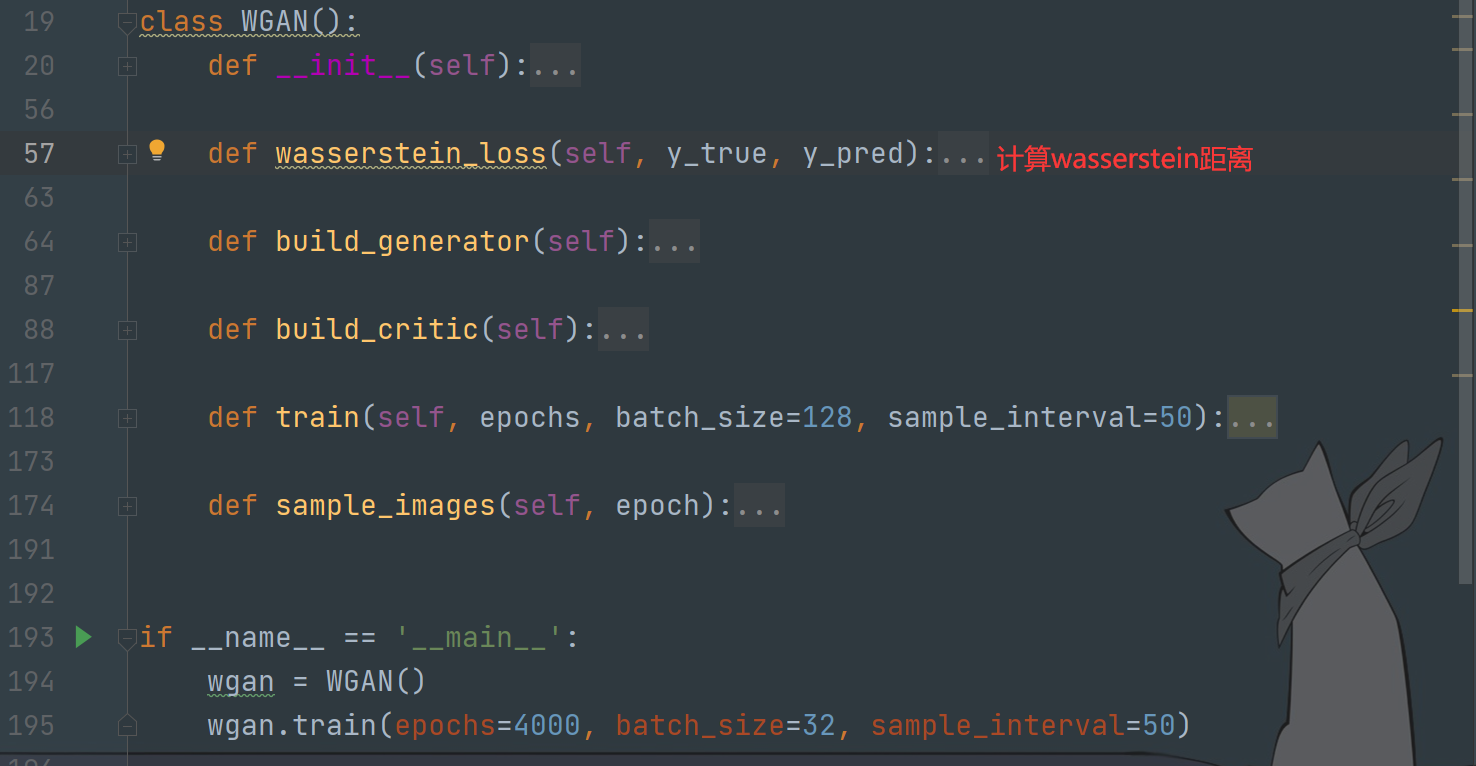
注意:经典GAN的生成器与编码器均使用简单的全连接层构建,而其他衍生种类GAN一般使用卷积层/反卷积层代替全连接层
类属性
def __init__(self):
# 定义输入图片的尺寸、通道数和噪声的维数
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.latent_dim = 100
self.n_critic = 5 # 定义判别器训练的次数
self.clip_value = 0.01 # 设置权重裁剪参数
optimizer = RMSprop(lr=0.00005) # 使用RMSprop优化器
# 实例化判别器并指定训练时使用的优化器、loss等
self.critic = self.build_critic()
self.critic.compile(loss=self.wasserstein_loss,
optimizer=optimizer,
metrics=['accuracy'])
# Build the generator
self.generator = self.build_generator()
# 为生成器设置一个输入层Input,形状为100维
z = Input(shape=(self.latent_dim,))
img = self.generator(z)
# 设置在网络中不训练判别器
self.critic.trainable = False
# 将生成器生成的图片输入判别器
valid = self.critic(img)
'''
使用Model构建一个网络
该网络由一个生成器层和一个判别器层组成
通过训练该网络,让生成器尽可能骗过判别器,也就是说,该网络的作用是训练生成器
由于之前的设置,该网络训练过程中,其判别器层不训练
'''
self.combined = Model(z, valid)
self.combined.compile(loss=self.wasserstein_loss,
optimizer=optimizer,
metrics=['accuracy'])
EM距离
def wasserstein_loss(self, y_true, y_pred):
'''
沿着指定轴取张量的平均值,
得到一个具有y_true * y_pred元素均值的张量
'''
return K.mean(y_true * y_pred)
生成器定义
def build_generator(self):
model = Sequential()
# 第一个全连接层,输入值是100维的噪声,输出是128*7*7=6272维的数据
model.add(Dense(128 * 7 * 7, activation="relu", input_dim=self.latent_dim))
model.add(Reshape((7, 7, 128)))# Reshape成以下形状
# 上采样,对数据进行插值,该操作将数据的行和列分别重复size[0]和size[1]次
# 从而将特征图放大,其默认参数size为(2,2),即放大两倍
model.add(UpSampling2D())# (None, 14, 14, 128)
# 引入卷积层,128个过滤器(128维),卷积核大小为4,边缘填充
# 注:padding="same"且strides为1(默认为1)时,输入与输出图片大小一致
# 具体计算:https://blog.csdn.net/weixin_40964777/article/details/105695251?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165465535616781685358205%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=165465535616781685358205&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-105695251-null-null.nonecase&utm_term=%E5%8D%B7%E7%A7%AF%E5%B1%82%E8%BE%93%E5%87%BA&spm=1018.2226.3001.4450
model.add(Conv2D(128, kernel_size=4, padding="same"))# (None, 14, 14, 128)
# 使用BatchNormalization对卷积得到的每个特征图进行标准化处理
model.add(BatchNormalization(momentum=0.8))# (None, 14, 14, 128)
model.add(Activation("relu"))# 添加激活层,(None, 14, 14, 128)
model.add(UpSampling2D())# (None, 28, 28, 128)
# 64个过滤器(64维),卷积核大小为4,边缘填充
model.add(Conv2D(64, kernel_size=4, padding="same"))# (None, 28, 28, 128)
model.add(BatchNormalization(momentum=0.8))# (None, 28, 28, 128)
model.add(Activation("relu"))# (None, 28, 28, 128)
# 1个过滤器(1维),卷积核大小为4,边缘填充
model.add(Conv2D(self.channels, kernel_size=4, padding="same"))#(None, 28, 28, 1)
model.add(Activation("tanh"))
model.summary()
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img)
判别器定义
def build_critic(self):
model = Sequential()
# 输入是28,28,1。16个过滤器(16维),卷积核大小为3,步数2,边缘填充
model.add(Conv2D(16, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
# 32个过滤器(32维),卷积核大小为3,步数2,边缘填充
'''
这里的输出需要计算(有点奇怪,不是应该输入输出形状相同吗)
[(14-3)+2]/2+1=6.5+1=6+1=7(当前版本tf为下取整)
因此,经过下面卷积层后,数据的形状为(None, 7, 7, 32)
'''
model.add(Conv2D(32, kernel_size=3, strides=2, padding="same"))# (None, 7, 7, 32)
# 用于在二维矩阵的四周填充0
# 上面不填充,下面填充一行;左边不填充,右边填充一列
model.add(ZeroPadding2D(padding=((0,1),(0,1))))# (None, 8, 8, 32)
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))# (None, 8, 8, 32)
'''
[(8-3)+2]/2+1=3.5+1=3+1=4(当前版本tf为下取整)
因此,经过下面卷积层后,数据的形状为(None, 4, 4, 64)
'''
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))# (None, 4, 4, 64)
# 由于strides=1,所以形状不变,维度变为128,即(None, 4, 4, 128)
model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
# 展平,4*4*128=2048
model.add(Flatten())
# 经过全连接层,输出0/1
model.add(Dense(1))
model.summary()
img = Input(shape=self.img_shape)
validity = model(img)
return Model(img, validity)
训练部分
def train(self, epochs, batch_size=128, sample_interval=50):
# 载入数据集
(X_train, _), (_, _) = mnist.load_data()
# 将数据调整到-1~1范围上
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3)
# 创建标签(判断为真/假,1/0)
valid = -np.ones((batch_size, 1))
fake = np.ones((batch_size, 1))
for epoch in range(epochs):
for _ in range(self.n_critic):
# ---------------------
# Train Discriminator
# ---------------------
# 每训练五次判别器训练一次生成器
# 根据索引,随机从数据集中选择图片数据
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
# 产生正态分布的随机噪声
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# 使用Sequential建立的模型可以通过predict方法返回输出值
gen_imgs = self.generator.predict(noise)
# 训练判别器
d_loss_real = self.critic.train_on_batch(imgs, valid)
d_loss_fake = self.critic.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_fake, d_loss_real)
# 梯度裁切
for l in self.critic.layers:
weights = l.get_weights()
weights = [np.clip(w, -self.clip_value, self.clip_value) for w in weights]
l.set_weights(weights)
# ---------------------
# Train Generator
# ---------------------
g_loss = self.combined.train_on_batch(noise, valid)# 训练生成器
# Plot the progress
print ("%d [D loss: %f] [G loss: %f]" % (epoch, 1 - d_loss[0], 1 - g_loss[0]))
if epoch % sample_interval == 0:
self.sample_image
WGAN-gp的训练
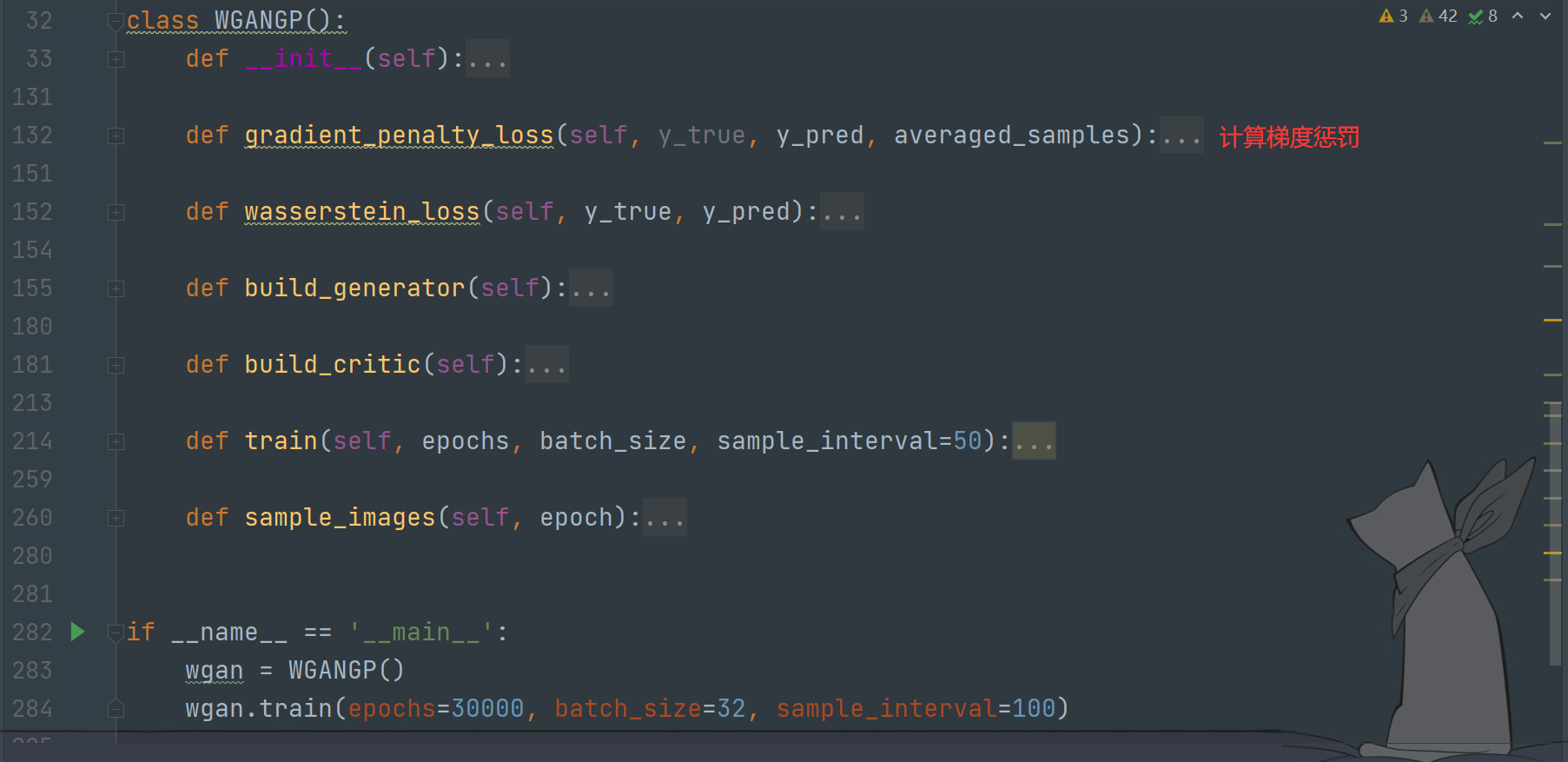
类属性
def __init__(self):
# 定义输入图片形状
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.latent_dim = 100
self.n_critic = 5# 定义判别器训练的次数
optimizer = RMSprop(lr=0.00005)# 使用RMSprop优化器
# 实例化生成器与判别器
self.generator = self.build_generator()
self.critic = self.build_critic()
#-------------------------------
# Construct Computational Graph
# for the Critic
#-------------------------------
# 当训练判别器的时候冻结生成器层
self.generator.trainable = False
# 规定输入样本的维数,即1*28*28(注意此处不包含batch_size)
real_img = Input(shape=self.img_shape)
# 同理规定输入的随机噪声的维数,即100(注意此处不包含batch_size)
z_disc = Input(shape=(self.latent_dim,))
# 将噪声输入生成器获得生成数据fake_img
fake_img = self.generator(z_disc)
# 使用判别器分别对生成数据和真实数据进行判断
fake = self.critic(fake_img)
valid = self.critic(real_img)
# 使用随机权重将真实/生成数据样本混合为加权样本
interpolated_img = RandomWeightedAverage()([real_img, fake_img])
# (32,28,28,1)
# Determine validity of weighted sample,对加权样本进行判别
validity_interpolated = self.critic(interpolated_img)
# 因为需要频繁调用gradient_penalty_loss,如果每次都写就很会变得冗余
# 所以用partial处理一下,类似pytorch版里面定义的block函数
# https://blog.csdn.net/qq_43426908/article/details/118530231
partial_gp_loss = partial(self.gradient_penalty_loss,
averaged_samples=interpolated_img)
partial_gp_loss.__name__ = 'gradient_penalty'
'''
通过Model构建一个网络(即将之前写好的网络中的各部分整合起来,搭建网络)
该网络由三组(生成器+判别器)层组成,分别用于判别真实图片、生成图片和混合样本图片
通过训练该网络,让判别器尽可能的识别出生成器和真混合采样图片与实图片的区别
也就是说,该网络的作用是训练判别器
输入:
真实数据real_img;
随机噪声z_disc;
输出:
判别器对生成数据的判断结果valid;
判别器对真实数据的判断结果fake;
compile参数注释(用于配置模型训练):
loss:用于定义整合的模型各部分使用的loss函数,
在这里,计算valid和fake时使用self.wasserstein_loss,
计算validity_interpolated用partial_gp_loss。
optimizer:指定优化器
loss_weights:损失函数权重
使用self.wasserstein_loss和gradient_penalty_loss作为该网络的损失函数
'''
self.critic_model = Model(inputs=[real_img, z_disc],
outputs=[valid, fake, validity_interpolated])
self.critic_model.compile(loss=[self.wasserstein_loss,
self.wasserstein_loss,
partial_gp_loss],
optimizer=optimizer,
loss_weights=[1, 1, 10])
#-------------------------------
# Construct Computational Graph
# for Generator
#-------------------------------
# 为了训练生成器,冻结判别器层
# 注意:此处需要再开启生成器层,不然compile后生成器层仍然无法得到训练
self.critic.trainable = False
self.generator.trainable = True
# 使用随机噪声作为输入
z_gen = Input(shape=(self.latent_dim,))
# 生成数据
img = self.generator(z_gen)
# 判断生成数据
valid = self.critic(img)
'''
通过Model构建一个网络
该网络由一个生成器层和一个判别器层组成
通过训练该网络,让生成器尽可能骗过判别器,也就是说,该网络的作用是训练生成器
使用self.wasserstein_loss作为该网络的损失函数
'''
self.generator_model = Model(z_gen, valid)
self.generator_model.compile(loss=self.wasserstein_loss, optimizer=optimizer)
梯度惩罚项计算(感觉有点没理解完,可能以后会更新)
def gradient_penalty_loss(self, y_true, y_pred, averaged_samples):
"""
Computes gradient penalty based on prediction and weighted real / fake samples
"""
# 求y_pred关于averaged_samples的导数(梯度)
# 即判别器的判断结果validity_interpolated与加权样本interpolated_img求导
# ps:interpolated_img作为默认参数(averaged_samples)在使用partial封装时已经提供
gradients = K.gradients(y_pred, averaged_samples)[0]
# compute the euclidean norm by squaring ...,计算范数
gradients_sqr = K.square(gradients)
# ... summing over the rows ...
gradients_sqr_sum = K.sum(gradients_sqr,
axis=np.arange(1, len(gradients_sqr.shape)))
# ... and sqrt
# 基本上就是对论文中的公式的实现
gradient_l2_norm = K.sqrt(gradients_sqr_sum)
# compute lambda * (1 - ||grad||)^2 still for each single sample
gradient_penalty = K.square(1 - gradient_l2_norm)
# return the mean as loss over all the batch samples
return K.mean(gradient_penalty)
EM距离
def wasserstein_loss(self, y_true, y_pred):
'''
沿着指定轴取张量的平均值,
得到一个具有y_true * y_pred元素均值的张量
'''
return K.mean(y_true * y_pred)
生成器定义
def build_generator(self):
model = Sequential()
# 第一个全连接层,输入值是100维的噪声,输出是128*7*7=6272维的数据
model.add(Dense(128 * 7 * 7, activation="relu", input_dim=self.latent_dim))
model.add(Reshape((7, 7, 128)))# Reshape成以下形状
model.add(UpSampling2D())# 上采样,对数据进行插值
# 引入卷积层,128个过滤器(128维),卷积核大小为4,边缘填充
model.add(Conv2D(128, kernel_size=4, padding="same"))# (None, 14, 14, 128)
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D())# (None, 28, 28, 128)
model.add(Conv2D(64, kernel_size=4, padding="same"))# (None, 28, 28, 128)
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
# 1个过滤器(1维),卷积核大小为4,边缘填充
model.add(Conv2D(self.channels, kernel_size=4, padding="same"))#(None, 28, 28, 1)
model.add(Activation("tanh"))
model.summary()
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img)
判别器定义
def build_critic(self):
model = Sequential()
# 输入是28,28,1。16个过滤器(16维),卷积核大小为3,步数2,边缘填充
model.add(Conv2D(16, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
'''
这里的输出需要计算(有点奇怪,不是应该输入输出形状相同吗)
[(14-3)+2]/2+1=6.5+1=6+1=7(当前版本tf为下取整)
因此,经过下面卷积层后,数据的形状为(None, 7, 7, 32)
'''
model.add(Conv2D(32, kernel_size=3, strides=2, padding="same"))# (None, 7, 7, 32)
# 用于在二维矩阵的四周填充0
# 上面不填充,下面填充一行;左边不填充,右边填充一列
model.add(ZeroPadding2D(padding=((0,1),(0,1))))# (None, 8, 8, 32)
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
'''
[(8-3)+2]/2+1=3.5+1=3+1=4(当前版本tf为下取整)
因此,经过下面卷积层后,数据的形状为(None, 4, 4, 64)
'''
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))# (None, 4, 4, 64)
# 由于strides=1,所以形状不变,维度变为128,即(None, 4, 4, 128)
model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
# 展平,4*4*128=2048
model.add(Flatten())
# 经过全连接层,输出0/1
model.add(Dense(1))
model.summary()
img = Input(shape=self.img_shape)
validity = model(img)
return Model(img, validity)
训练部分
def train(self, epochs, batch_size, sample_interval=50):
# Load the dataset,载入数据集
(X_train, _), (_, _) = mnist.load_data()
# X_train:{tuple}(60000,28,28);_:对应标签
# 将数据调整到-1~1范围上
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3)
# 创建标签(判断为真/假,1/0)
valid = -np.ones((batch_size, 1))
fake = np.ones((batch_size, 1))
dummy = np.zeros((batch_size, 1))
for epoch in range(epochs):
for _ in range(self.n_critic):
# ---------------------
# Train Discriminator
# ---------------------
# 每训练五次判别器训练一次生成器
# 在60000个样本中随机选择32个组成一个batch
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
# 产生正态分布的随机噪声
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# 训练判别器(此时生成器不训练)
d_loss = self.critic_model.train_on_batch([imgs, noise],
[valid, fake, dummy])
# ---------------------
# Train Generator
# ---------------------
# 训练生成器
g_loss = self.generator_model.train_on_batch(noise, valid)
# Plot the progress
print ("%d [D loss: %f] [G loss: %f]" % (epoch, d_loss[0], g_loss))
if epoch % sample_interval == 0:
self.sample_images(epoch)

