大数据竞赛练习题一
导入数据
import numpy as np
import pandas as pd
from pandas import DataFrame, Series
#可视化显示在界面
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来显示中文
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
import seaborn as sns
sns.set(color_codes=True)
import json
import warnings
warnings.filterwarnings('ignore')
from wordcloud import WordCloud, STOPWORDS
movies = pd.read_csv('C:\\Users\\杜子轩\\Desktop\\王建民作业\\大数据竞赛练习题\\MathorCup大数据竞赛练习题1\\data\\tmdb_5000_movies.csv', encoding='utf_8')
credits = pd.read_csv('C:\\Users\\杜子轩\\Desktop\\王建民作业\\大数据竞赛练习题\\MathorCup大数据竞赛练习题1\\data\\tmdb_5000_credits.csv', encoding='utf_8')
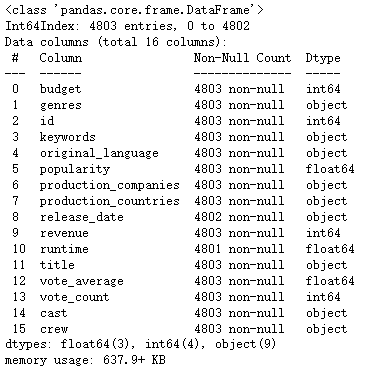
movies.info() # 查看信息
credits.info()

# 两个数据框都有title列,以及movies.riginal_title
# 以上三个数据列重复,删除两个
del credits['title']
del movies['original_title']
# 连接两个csv文件
merged = pd.merge(movies, credits, left_on='id', right_on='movie_id', how='left')
# 删除不需要分析的列
df=merged.drop(['homepage','overview','spoken_languages','status','tagline','movie_id'],axis=1)
df.info()