2024数据采集与融合技术实践-作业3
作业①:
1)指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
1.核心代码描述
items.py
import scrapy
class WeatherItem(scrapy.Item):
img_url=scrapy.Field()#用于存储图片url
pass
weather_spider.py
import scrapy
from ..items import WeatherItem
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class MySpider(scrapy.Spider):
name='weather'
start_urls=['https://www.weather.com.cn/'] #目标网站
def parse(self, response):
try:
data = response.body.decode()
selector = scrapy.Selector(text=data)
imgs = selector.xpath('//img')#查找所有具有img属性的标签
for img in imgs:
item=WeatherItem()
item['img_url']=img.xpath('./@src').extract_first() #将图片的url存储到item
print(item['img_url'])#打印url到控制台
yield item
except Exception as err:
print(err)
pipelines.py(单线程)
class WeathersPipeline:
count=0 #用于图片命名,同时计数
def process_item(self, item, spider):
WeathersPipeline.count+=1
#以下是写入图片到本地文件夹images的部分
img_url=item['img_url']
response = requests.get(img_url)
if response.status_code == 200:
image_name = WeathersPipeline.count
with open(os.path.join('images', f'{image_name}.jpg'), 'wb') as file:
file.write(response.content)
return item
pipelines.py(多线程)
def download_image(img_url,name): #将下载图片的代码封装,方便线程函数的调用
response = requests.get(img_url)
if response.status_code == 200:
with open(os.path.join('images', f'{name}.jpg'), 'wb') as file:
file.write(response.content)
class WeathersPipeline:
count=0 #用于图片命名,同时计数
threads = [] # 存放线程,用于后续确认所有线程运行完毕
def process_item(self, item, spider):
WeathersPipeline.count+=1
img_url=item['img_url']
thread = threading.Thread(target=download_image, args=(img_url,WeathersPipeline.count))
WeathersPipeline.threads.append(thread)
thread.start()
return item
def close_spider(self, spider):
for thread in WeathersPipeline.threads:
thread.join() #确保所有线程运行完毕
2.输出信息
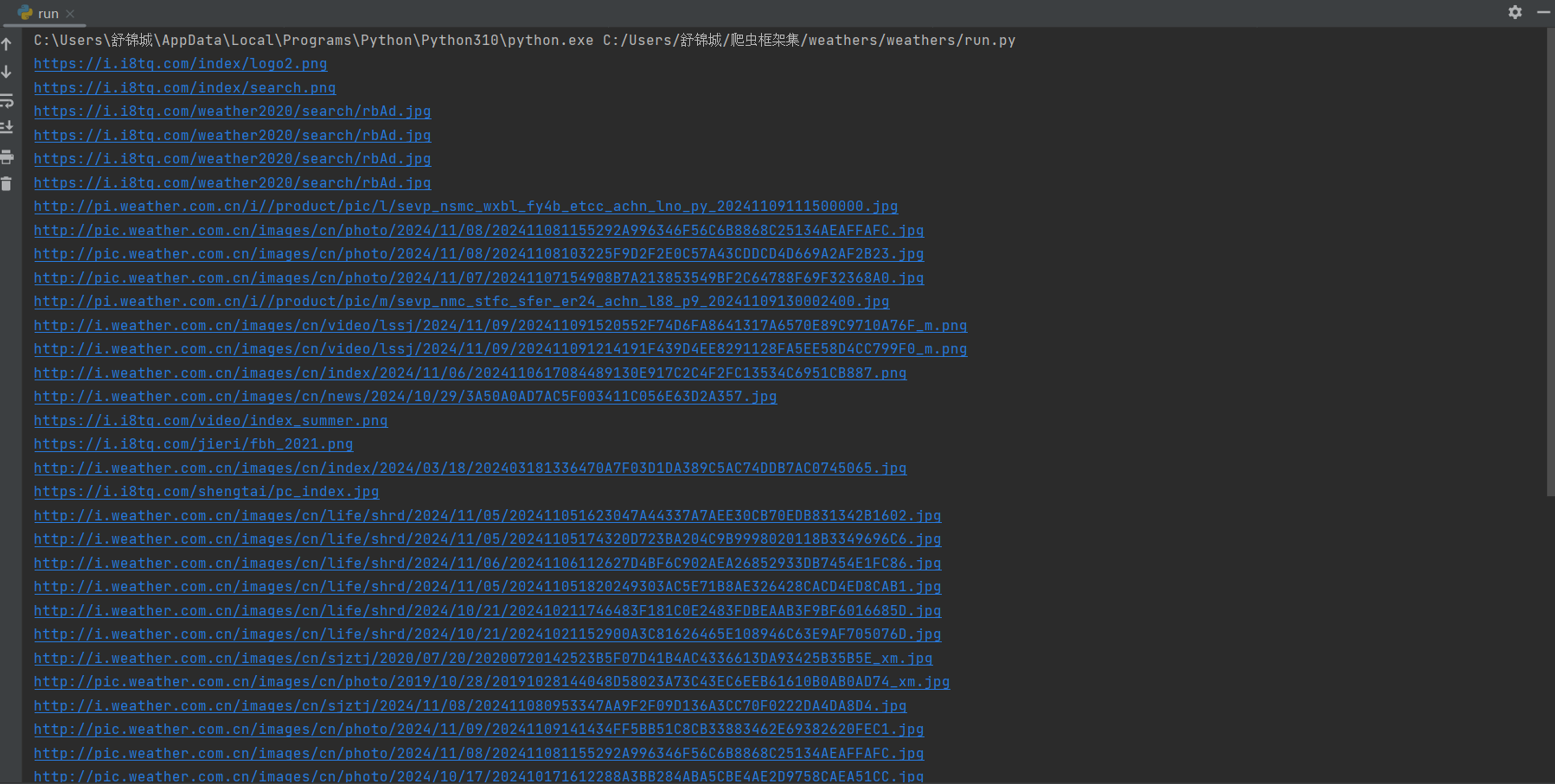
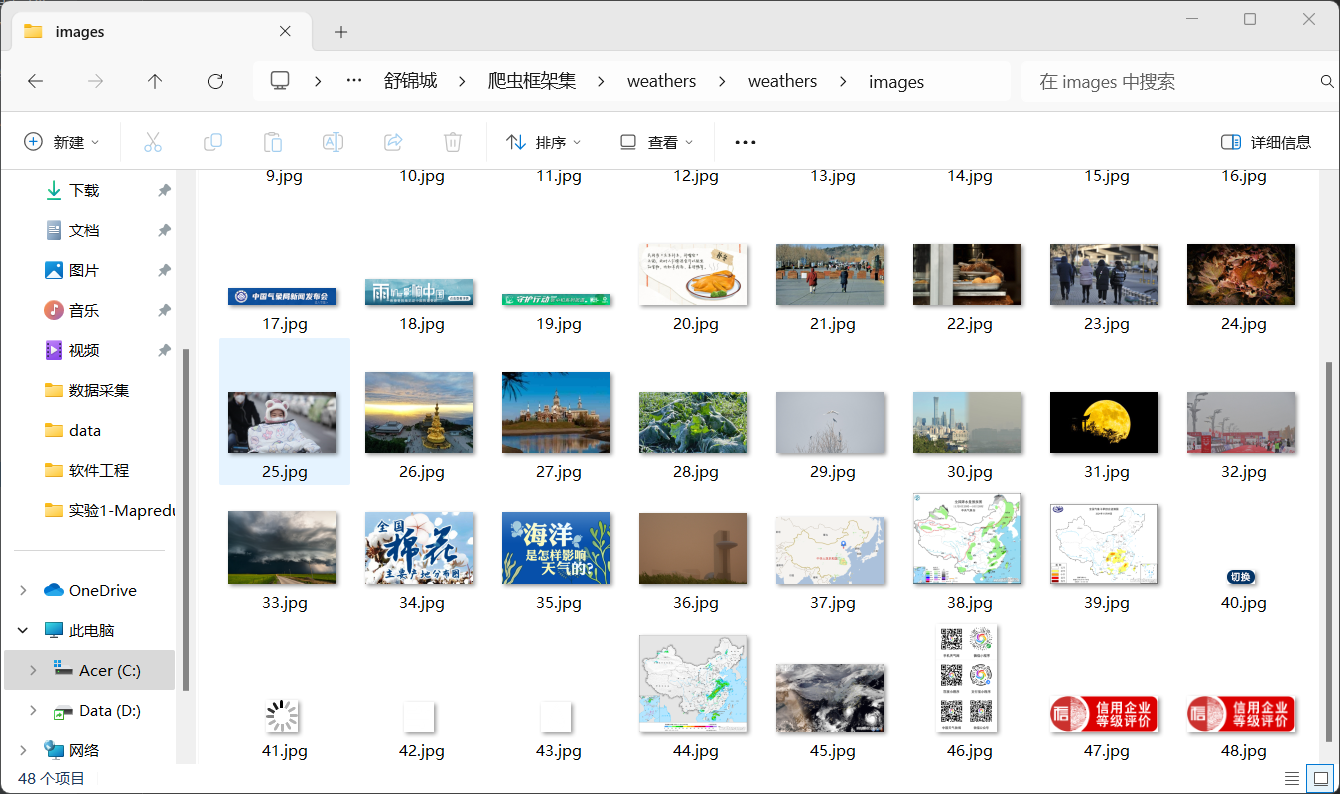
3.Gitee文件夹链接
作业3/1 · 舒锦城/2022级数据采集与融合技术 - 码云 - 开源中国
作业②:
1)熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
1.核心代码描述
items.py
import scrapy
class StocksItem(scrapy.Item):
#按作业输出要求设置item数据
f2=scrapy.Field()#最新价
f3=scrapy.Field()#涨跌幅
f4=scrapy.Field()#涨跌额
f5=scrapy.Field()#成交量
f7=scrapy.Field()#振幅
f12=scrapy.Field()#代码
f14=scrapy.Field()#名称
f15=scrapy.Field()#最高
f16=scrapy.Field()#最低
f17=scrapy.Field()#今开
f18=scrapy.Field()#昨收
pass
stocks_spider.py
import json
import re
import scrapy
from ..items import StocksItem
class MySpider(scrapy.Spider):
name='stocks'
#抓包获得的股票数据url
start_urls=['https://85.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409414367090395277_1731159541093&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f26&fs=b:BK0707&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f26,f22,f11,f62,f128,f136,f115,f152&_=1731159541094']
def parse(self, response):
json_data = self.extract_json_data(response.text)
if json_data:
data = json.loads(json_data)
for stock in data['data']['diff']:
item = StocksItem() #将对应数据存储到item中
item['f2'] = stock['f2']
item['f3'] = stock['f3']
item['f4'] = stock['f4']
item['f5'] = stock['f5']
item['f7'] = stock['f7']
item['f12'] = stock['f12']
item['f14'] = stock['f14']
item['f15'] = stock['f15']
item['f16'] = stock['f16']
item['f17'] = stock['f17']
item['f18'] = stock['f18']
yield item
else:
self.logger.error("Failed to extract JSON data")
def extract_json_data(self, content): #使用正则表达式搜索给定字符串中被包裹在括号内的 JSON 数据部分
json_data_match = re.search(r'\(({.*})\)', content)
if json_data_match:
return json_data_match.group(1)
return None
pipelines.py
import pymysql
class StocksPipeline:
def open_spider(self, spider):
self.conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='******', charset='utf8')#密码涉及个人隐私,这里就不展示了^^
self.conn.autocommit(True)
with self.conn.cursor() as cursor:
cursor.execute('CREATE DATABASE IF NOT EXISTS stocks')
cursor.execute('USE stocks')
cursor.execute("""
CREATE TABLE IF NOT EXISTS stocks (
id SERIAL PRIMARY KEY,
stock_code VARCHAR(10),
stock_name VARCHAR(255),
latest_price DECIMAL(10,2),
change_percentage DECIMAL(5,2),
change_amount DECIMAL(8,2),
trading_volume BIGINT,
amplitude DECIMAL(5,2),
highest_price DECIMAL(10,2),
lowest_price DECIMAL(10,2),
opening_price_today DECIMAL(10,2),
closing_price_yesterday DECIMAL(10,2)
);
""")#创建数据表
def process_item(self, item, spider):
sql = """
INSERT INTO stocks (stock_code, stock_name, latest_price, change_percentage, change_amount, trading_volume, amplitude, highest_price, lowest_price, opening_price_today,closing_price_yesterday)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
data = (
item["f12"], item["f14"], item["f2"], item["f3"], item["f4"],
item["f5"], item["f7"], item["f15"], item["f16"], item["f17"],
item["f18"]
)#插入数据
with self.conn.cursor() as cursor:
try:
cursor.execute(sql, data)
except Exception as e:
print(e)
return item
def close_spider(self, spider):
self.conn.close()
print("数据存储完毕")
2.输出信息
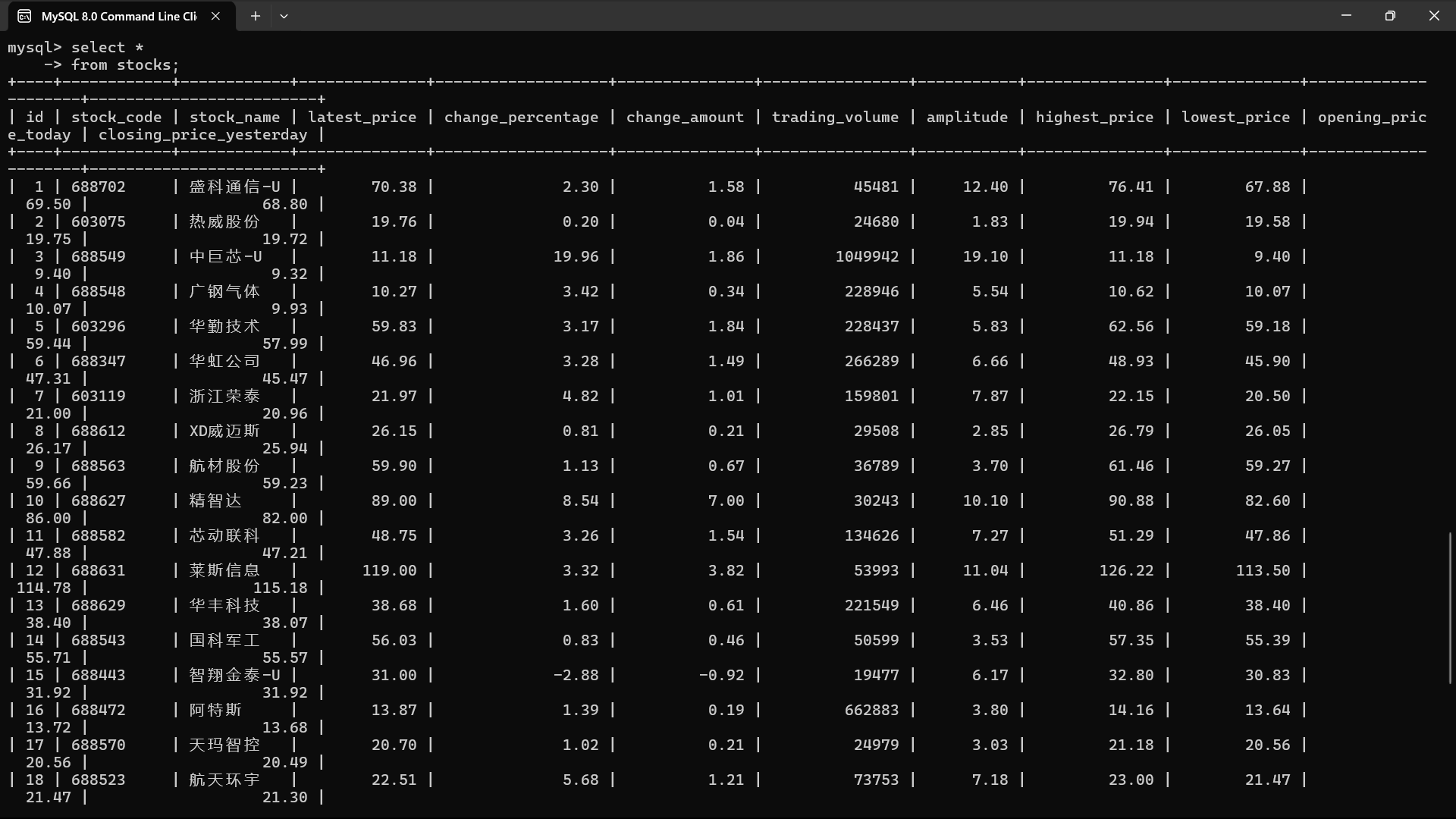
3.Gitee文件夹链接
作业3/2 · 舒锦城/2022级数据采集与融合技术 - 码云 - 开源中国
作业③:
1)熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
1.核心代码描述
items.py
import scrapy
class ForeignExchangeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency=scrapy.Field()#货币名称
TBP=scrapy.Field()#现汇买入价
CBP=scrapy.Field()#现钞买入价
TSP= scrapy.Field()#现汇卖出价
CSP = scrapy.Field()#现钞卖出价
Time= scrapy.Field()#时间
pass
exchange_spider.py
import scrapy
from ..items import ForeignExchangeItem
class MySpider(scrapy.Spider):
name='exchange'
start_urls=['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
#直接查询有cellpadding属性的table标签下第2-28行的表格,第28行刚好是表格最后一行,通过f12复制表格最后一行的xPath路径知道的
for tr in response.xpath("//table[@cellpadding]//tr")[2:29]:
item = ForeignExchangeItem()
item['Currency']=tr.xpath('./td[1]/text()').extract_first() #对应表格第1-8列的数据存储到item中
item['TBP']=tr.xpath('./td[2]/text()').extract_first()
item['CBP']=tr.xpath('./td[3]/text()').extract_first()
item['TSP']=tr.xpath('./td[4]/text()').extract_first()
item['CSP']=tr.xpath('./td[5]/text()').extract_first()
item['Time']=tr.xpath('./td[8]/text()').extract_first()
yield item
pipelines.py
import pymysql
class ForeignExchangePipeline:
def open_spider(self, spider):
self.conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='******', charset='utf8')
self.conn.autocommit(True)
with self.conn.cursor() as cursor:
cursor.execute('USE homework')
cursor.execute("""
CREATE TABLE IF NOT EXISTS exchange (
Currency VARCHAR(20),
TBP DECIMAL(5,2),
CBP DECIMAL(5,2),
TSP DECIMAL(5,2),
CSP DECIMAL(5,2),
Time TIME
);
""")
def process_item(self, item, spider):
sql = """
INSERT INTO exchange (Currency,TBP,CBP,TSP,CSP,Time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
data = (
item["Currency"], item["TBP"], item["CBP"], item["TSP"], item["CSP"],
item["Time"]
)
with self.conn.cursor() as cursor:
try:
cursor.execute(sql, data)
except Exception as e:
print(e)
return item
def close_spider(self, spider):
self.conn.close()
print("数据存储完毕")
2.输出信息

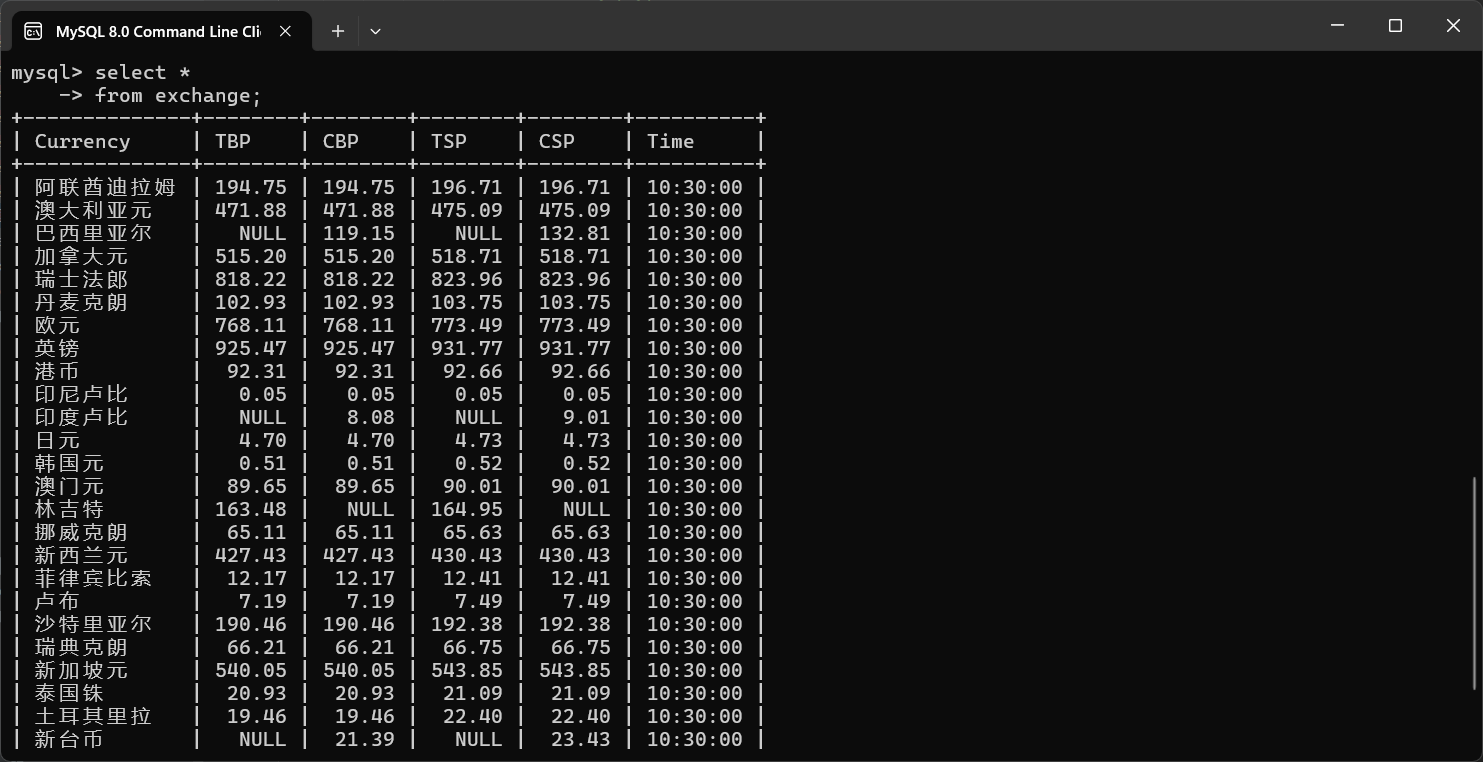
3.Gitee文件夹链接
作业3/3 · 舒锦城/2022级数据采集与融合技术 - 码云 - 开源中国
心得体会:
这次作业还是比较有难度的,特别是有以下几个点值得铭记:
①对数据的相关操作(如存储,下载等)是在pipelines.py下进行的
之前对书上的例子没有细看,在询问老师后才知道pipelines.py是专门用来处理item各类操作的,之前一直误以为只要设置好setting.py,scrapy框架会自动帮你下载item(T T 还是太想当然了,犯了这种低级错误),以至于在第一题花了很久时间都没有把图片下载下来。后面熟悉了基本上能够很好的使用pipelines下载各种类型的文件了。
②在调试程序时,务必打印日志信息,不要隐藏
在做第二题,想调试一下程序的时候,编写了一个run.py并隐藏了日志信息,反复运行程序控制台没有任何输出,以为是代码有误,反复检查甚至是删除框架再重写都没有输出,后来查看日志信息后知道了ROBOTSTXT_OBEY要设置成False(当然这个老师上课有讲过,一直以为是自己的问题没有在意),为了以后更好的调试程序,务必养成查看日志信息的好习惯。
最后也算是圆满完成了这次实践作业,同时通过这次实验,我对于scrapy的使用才算真正的熟悉起来了,同时也对sql相关操作熟悉很多,总的来说收获满满。

