2024数据采集与融合技术实践-作业1
作业①:
1)用requests和BeautifulSoup库方法定向爬取给定网址http://www.shanghairanking.cn/rankings/bcur/2020的数据,屏幕打印爬取的大学排名信息
1.部分代码展示
def url_text_get(url, header) #这个函数用于传入url和请求头,返回网页内容
html=url_text_get(url,header)
soup = BeautifulSoup(html, 'html.parser')
rows = soup.find_all('tr') #找到网页的表格部分
print("排名\t学校名称\t\t省市\t学校类型\t总分")
for row in rows:
rank = row.find('td').text.strip() if row.find('td') else "" #表格第一列为排名
name = row.find('span', class_="name-cn") #通过特定标签查找大学名字
university_name = name.text.strip() if name else ""
province = row.find_all('td')[2].text.strip() if len(row.find_all('td')) > 2 else "" #表格第三列
type_of_university = row.find_all('td')[3].text.strip() if len(row.find_all('td')) > 3 else "" #表格第四列
total_score = row.find_all('td')[4].text.strip() if len(row.find_all('td')) > 4 else "" #表格第五列
print(f"{rank}\t{university_name}\t\t{province}\t{type_of_university}\t{total_score}") #打印大学排名信息
2.运行结果
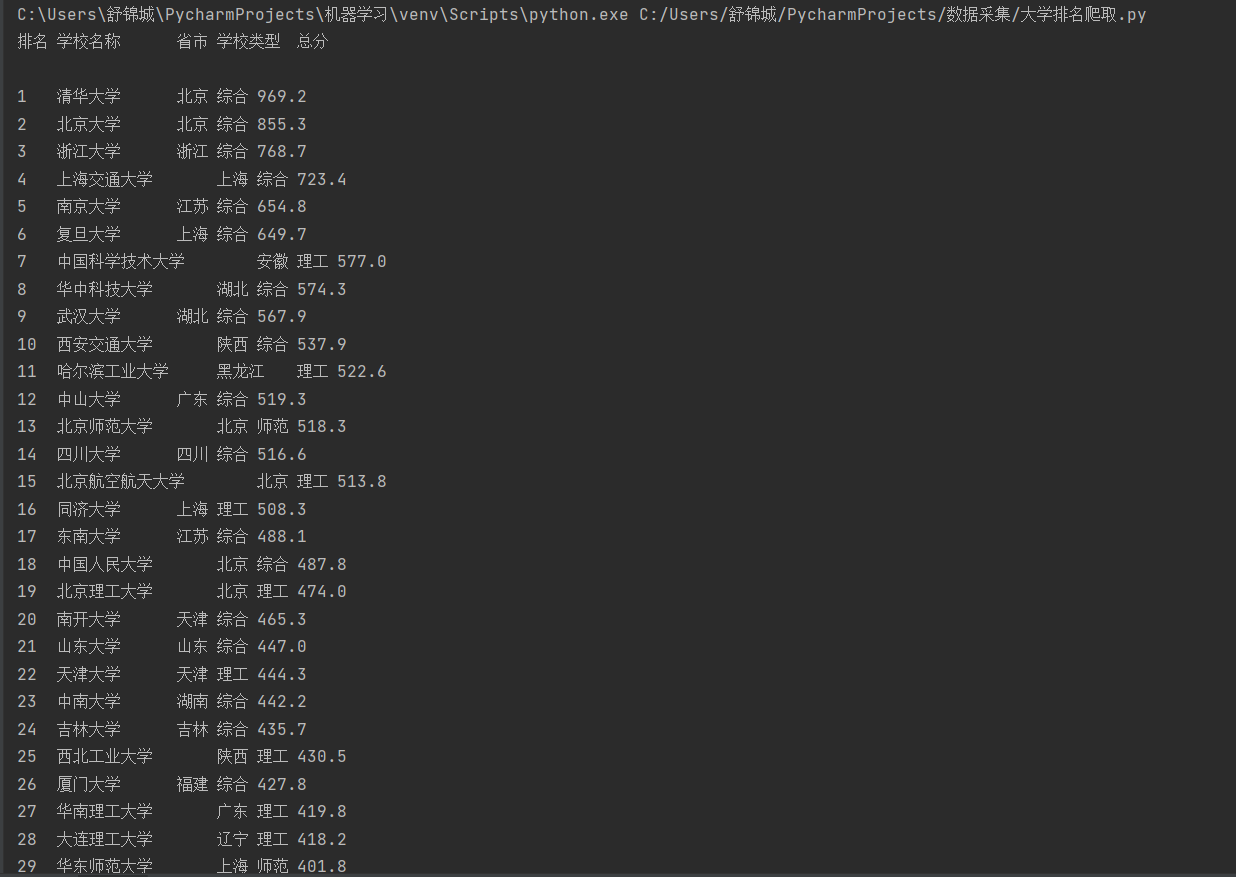
2)心得体会
知道了怎么对于网页中表格信息的处理,以后对于网页表格处理会效率会更加高,因为表格的标签相对固定,且更好定位我想要的资源在哪一行哪一列
作业②:
1)用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格
1.部分代码展示
def url_text_get(url, header) #这个函数用于传入url和请求头,返回网页内容
content=url_text_get(url,header)
soup=BeautifulSoup(content,'lxml')
print('商品名称\t\t\t\t\t\t\t\t\t\t\t\t\t\t价格')
links=soup.find_all('li') #每个商品都放在各个名为‘li’的标签中(但还有其他多余的内容的标签也为‘li’,后面会变为空值然后过滤)
for link in links:
tag=link.find('a',attrs={'dd_name':'单品图片'})['title'].strip() if link.find('a',attrs={'dd_name':'单品图片'}) else ''
price=link.find('span',attrs={'class':'price_n'}).text.strip() if link.find('span',attrs={'class':'price_n'}) else ''
if tag: #tag不为空则打印,过滤掉空行
print(f'{tag}\t\t\t{price}')
2.运行结果
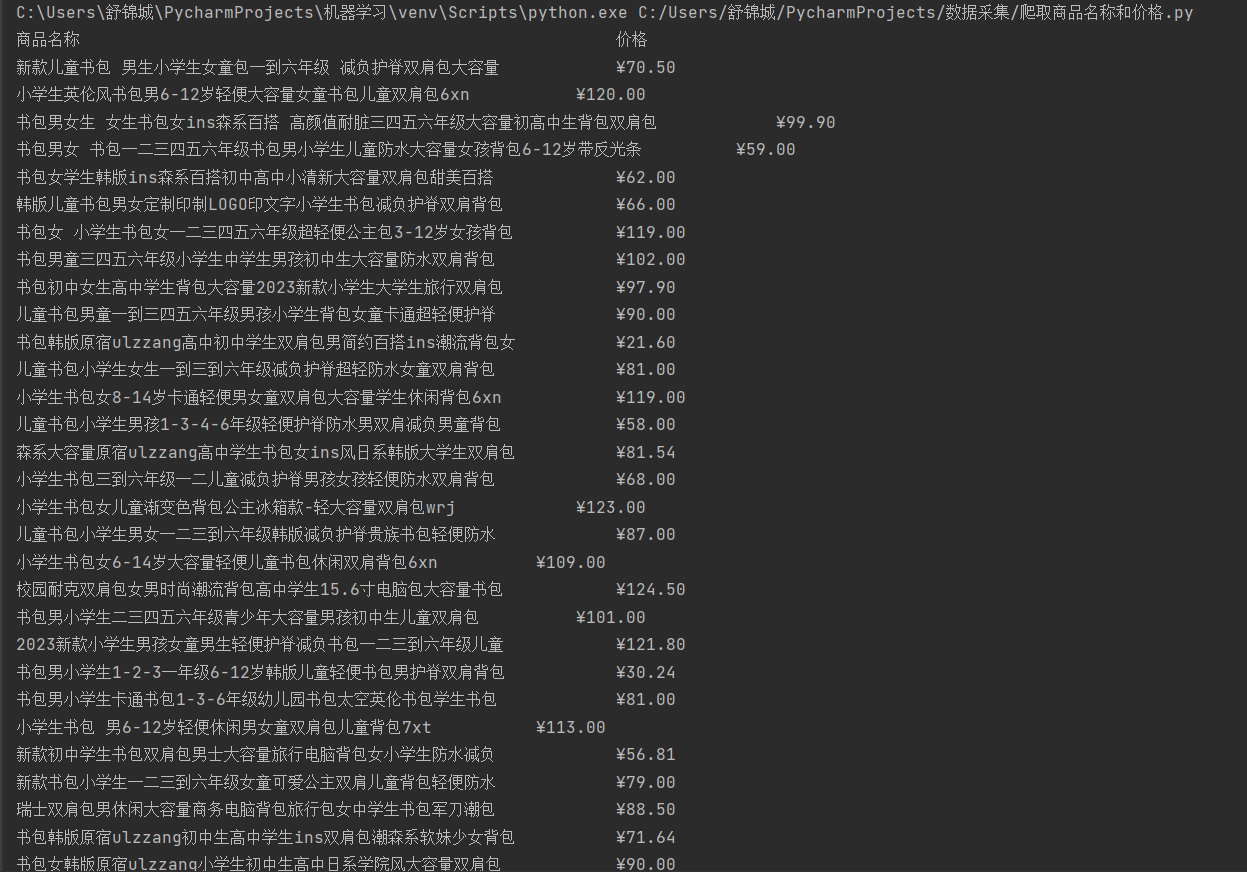
2)心得体会
学会了对大型网站中信息的爬取,同时也会设置合适的请求头来避免被IP封禁
作业③:
1)爬取一个给定网页https://news.fzu.edu.cn/yxfd.ht或者自选网页的所有JPEG和JPG格式文件
1.部分代码展示
url = 'https://news.fzu.edu.cn/yxfd.htm'
header = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre'
}
images=[] #用于存储图片的url
count=0 #计数爬取的图片
html=url_text_get(url, header)
soup=BeautifulSoup(html,'lxml')
tags=soup.find_all('li')
for tag in tags:
img=tag.find('img')['src'] if tag.find('img') else ''
if img:
images.append(img) #find返回值不为空,说明找到了图片url,加入到列表中
for img_url in images:
response = requests.get('https://news.fzu.edu.cn'+img_url) #加上学校图片url的同一前缀
if response.status_code == 200:
image_name = img_url.split('/')[-1]
with open(os.path.join('学校图片', image_name), 'wb') as file:
file.write(response.content) #写入图片
count+=1
print(f'下载完成:{image_name}')
else:
print(f'下载失败:{img_url}')
print(f'总共下载图片:{count}')
2.运行结果
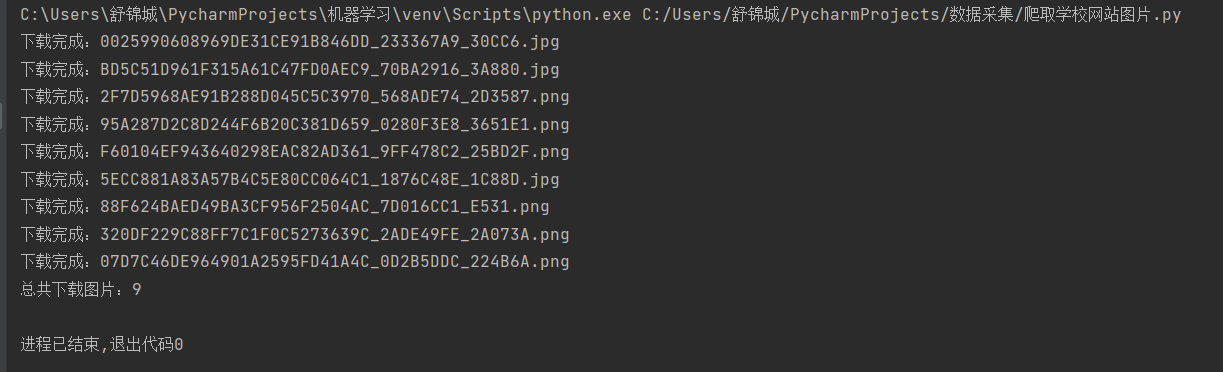
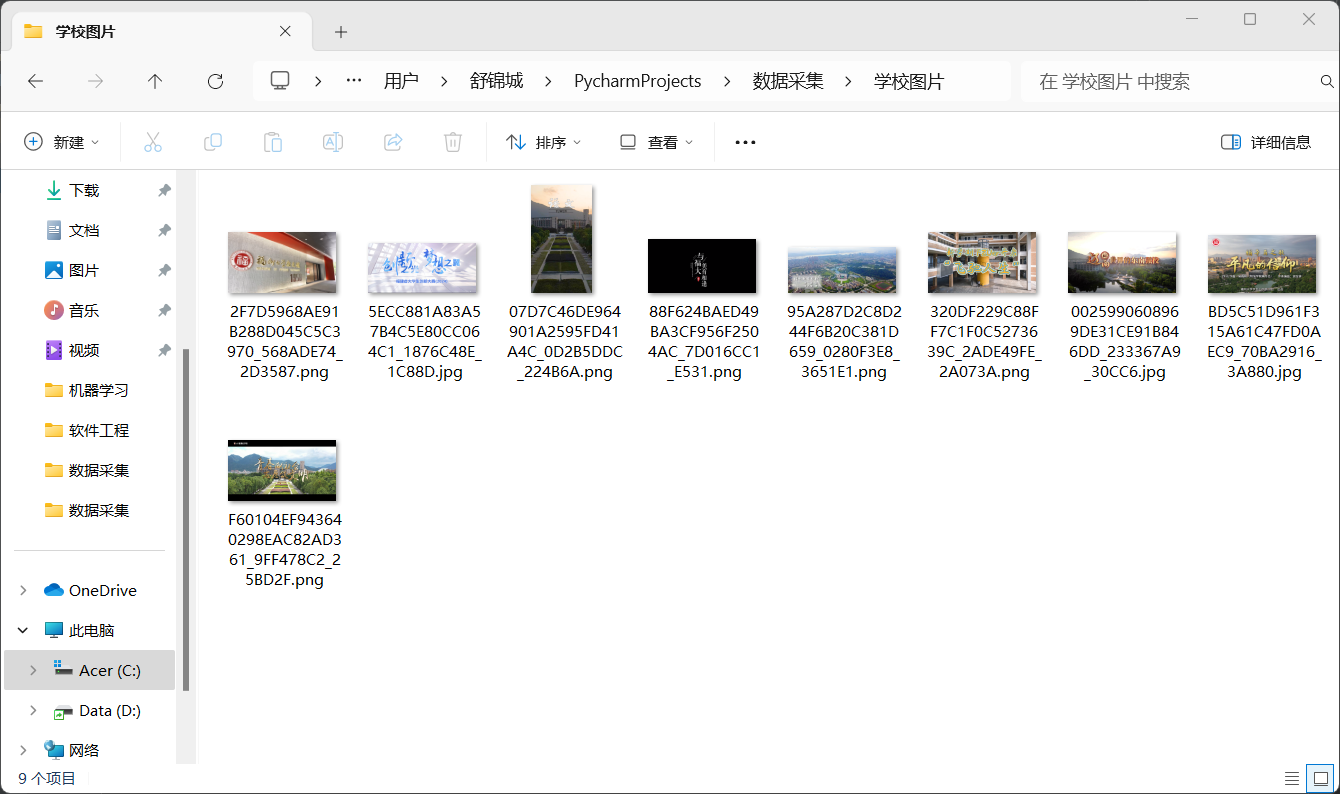
2)心得体会
学会了对网页中图片url的获取与图片下载,能够自主的从网页上爬取想要的图片集,对与url的提取和非文本内容的获取更加得心应手了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号