

原文:《Erasure Coding in Windows Azure Storage.pdf》,地址:https://www.usenix.org/system/files/conference/atc12/atc12-final181_0.pdf
WAS: (LRC, Local Reconstruction Codes)
1 概述
(1) Extent
当extent的大小达到一定值,extent就被sealed. Sealed的extent不能再被修改,作为编码的候选。WAS 在后台lazily地编码这个extent,一旦extent被编码成功,extent原始的3备份要被删除。
(2) LRU
A (k, l, r), k个数据段(data fragments),分成l个组,每个组生成一个本地编码块(local parity fragments),所有数据段,生成r个全局编码块。(6, 2, 2)
(3) Checking Decodability
swap local parity and data fragment , 然后检查删除的数据段和全局编码段的个数是不是小于全局编码段的个数,如果是,表明可解码。
(4) RS (10, 4) is used in HDFS-RAID in Facebook and RS (6, 3) in GFS II in Google.
(5) 其它编码技术:Weaver codes, Hover codes and Stepped Combination codes
(6) LRC和其他编码方案在重建读成本和存储复制两个维度的比较
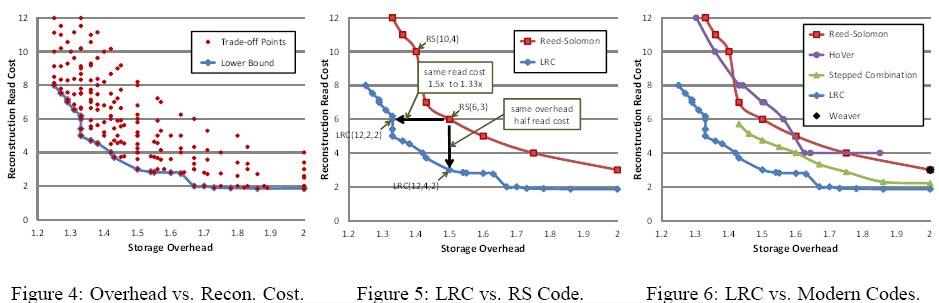
(7) LRC为了提供客户端读过程的重建需求,优化数据段重建,而非编码段。在编码段重建,modern codes更有效。在(12,6)的情况下,Stepped Combination code只需要3个数据段就可以重建编码段,LRC则需要12个数据段。
(8) WAS为了避免关联错误,将同一个编码组的数据段放在不同的fault domain
(9) WAS从架构上分为三层:前端层、分区对象层、流复制(replication)层
编码存储放在流复制层
2 实现
(1) 流层的架构:基于paxos的流管理器(Stream Managers, SM), Extent Nodes(EN)
(2) Extent, block, EN
每一个extent含有一系列的block(最大5M),每个block是CRC校验的,block是分区对象层读写数据的最小粒度。
每个extent在多个EN上复制。每个写操作在回复消息给客户端时,以菊花链的方式提交到一个复制集合的多个EN上
(3) Sealed
对应一个流的写操作持续追加到一个extent上,除非extent达到最大的大小(1G-3G),或者在复制集合中出现错误。无论哪种情况,一个新的extent会被创建,之前的extent被sealed。当extent被sealed(标记),数据就不能改变(immutable),并且成为编码存储的备选。
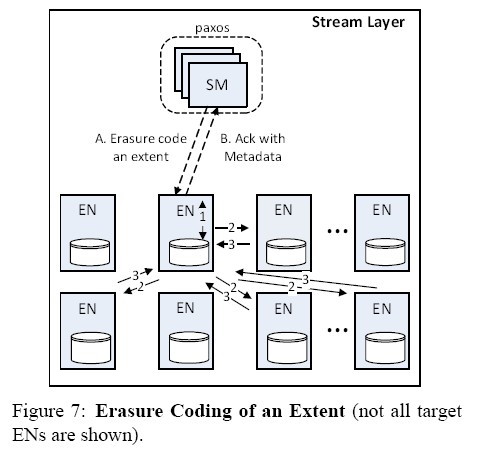
2.1 编码过程
编码存储是完全的异步和脱离客户端的写路径的。SM周期性扫描标记的extent,根据流策略和系统负载,安排一个子集用于编码。
We configure the system to automatically erasure code extents storing Blob data, but also have the option to erasure code Table extents too
过程:
(1) SM根据编码的参数(12,2,2),在一个集合的EN上创建fragment。SM从EN中选择一个协调者(coordinator),并且向它发生复制集合的元数据,从这开始,协调者负责编码的完成。
(2) coordinator EN选择编码的extent: 所有fragments的边界都在extent上。EN根据追加block的界限划分extent到fragment,而不是随意的划分。这确认读一个block不会跨越多个fragments
(3) coordinator EN开始编码过程,持续发送编码fragment给指定的EN。所有EN跟踪进度,并存储相应信息到新的fragment。当有错误发生,另外一个EN根据fragment中的进度信息,接手剩余工作
(4) 当整个extent都被编码了,协调者EN通知SM用fragment的界限和完成标记更新extent元数据。然后SM安排全备份的EN删除不需要的extent.
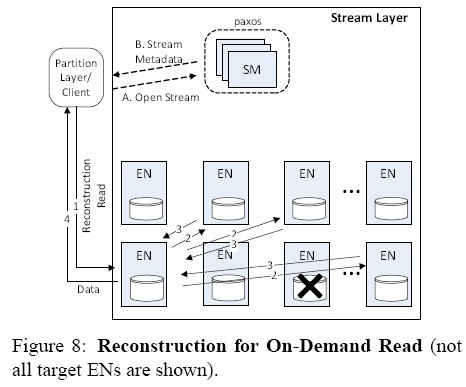
2.2 重建
(1) 读过程的重建
客户端进行读的时候,如果对应的EN不存活,或是一个热点,可以联系任何一个拥有extent的fragment的EN,开始一个重建读,EN完成重建读后会缓存相应的fragment.
(2) EN或磁盘丢失重建
由SM启动在另外一个EN进行重建,过程同上
2.3 Fragment存放
存放位置考虑的因素:
(1)负载,倾向于更空闲、更小负载的EN;
(2)可靠性,避免将同一个编码组的两个fragments放在相关联的域中。Fault domain(rack)、upgrade domain.
示例:
一个典型的WAS有20个机架,10个升级域(每次升级,有10%的存储资源不在线)。
LRU(10,2,2),分成2个本地组,然后每组选一个,一起放入一个升级域,一共要6个升级域。2个本地编码块,放入一个升级域,然后2个全局编码块放入2个升级域。一共需要9个升级域。这样在任何一个域的升级,每个数据fragment都可以获取到,或直接读取,或通过重建。
2.4 IO安排
每一个EN监控网络、每个独立磁盘的负载,决定接受、拒绝、delay IO
类似的,SM监控EN上的复制负载,来决定启动复制、编码、删除extent和其它系统维护操作,为了对其它IO操作的公平的性能。同时,也是为了确保编码的速度能赶上从用户进来的数据速率。
重建预读和cache:
重建fragment时以unit大小(大于block的大小)进行,减少磁盘和网络的IO数。预读的数据缓存在内存中(最大256M)。
2.5 数据一致性
Checksum和parity。每个block的同步都有一个crc,读写的时候检查。
在每一个编码操作后,很多解码的集合都在coordinator EN的内存中被尝试,以检查是否能成功的恢复。这样做的目的是为了确保编码的算法本身没有引入数据不一致。
LRC(12,2,2)在允许编码完成前,将尝试下列的解码验证:
(1)随机选择一个数据fragment,local group内重建;
(2)随机选择一个数据fragment,用其中一个全局parity重建;
(3)随机选择一个数据fragment,用另外一个全局parity重建;
(4)随机选择两个数据fragment,重建;
(5)随机选择3个数据fragment,重建;
(6)随机选择4个数据段(只是一个本地组要有一个),重建。
对于每种情况解码出来的数据,和实际的数据比较CRC
最后coordinator EN执行一个所有数据段的CRC,和extent的原始的CRC进行比较。如果这些检查都通过了,编码段才会被持久化到存储磁盘中。如果在这个过程,任何一个错误发生了,编码操作会被终止,保留extent的数据不变。SM过段时间在另一EN再开始调度编码。
2.6 编码算法优化
Galois Field arithmetic。使用预计算、加法、乘法表,根据编解码矩阵的形式来排序XOR操作,这样可以减少冗余的操作和限制实际编码过程中对编码矩阵的重复检查
3 Performance

 浙公网安备 33010602011771号
浙公网安备 33010602011771号