NOIP2017赛前小结
NOIP2017赛前小结
前言
从新学期的第二周开始就是停课集训了,这也是一段很有意义的时光。集训期间,各方面的能力都得到了提升,代码能力,应试技巧,知识水平等等。NOIP2017即将来临,集训也要拿出自己的成果来。为了对学过的知识,也让自己的知识更加有条理,做一次“NOIP2017赛前小结”。
Fighting!
考试策略、方法、心态
- 联赛使用Ubuntu,配置可以打好F9编译以及括号补全即可。
- 联赛的题面往往很长,并且数据范围整整一版,先把3题都看一遍,看懂要干什么,数据范围可以先不去深究。每天的第一题不要想复杂了,多多读几遍题目,然后一气呵成打完,可以再看看特殊的数据,总之要保证切掉,并且不要太急,45分钟只能都是可以的。然后全力去写后面两道题。第二题与第三题,部分分都不是很难想,在想到方法之后,要想想难不难实现,细节没有想清楚之前不要打。然后不能卡在一道题上面了,第三题也必须留出时间,至少1h10min。最好选择先打好暴力保底,这样才能毫无顾虑的思考题目。
- 考试时要全神贯注,不要想一些奇怪的东西。不要因为难而担忧,尽力去从多角度思考(比如能不能打表、是不是结论题、贪心可行吗、随机之后再贪心?、、、、、、)。
- 如果在想题时一直卡住,可以出去洗脸之类的,让思路更加开阔。
算法总结
基础算法
贪心
贪心一般都是不会写的时候才选择的,考裸贪心的一般不太可能。大多数贪心是用来辅助DP分,比如一般对于区间的问题都是右端点排序之类的。
分治
二分
二分要注意边界的情况,自己采用的习惯是闭区间即while(L<=R)L=mid+1,R=mid-1。都这么打就可以了。
倍增
倍增一般是RMQ问题以及树上公共祖先问题。公共祖先就是个板子,打的很熟练了,如果考到了,也是没有问题的。
高精
高精度在联赛中也有出现,采用结构体的重载运算符的写法。要特别注意前导0的情况,特别是减法。除法的话,一位一位的除就可以了。还有不要随便就认为题目是高精度,要细心分析,例如有一次NOIP就有不是用高精但是很想高精的解方程的题目。
模拟
模拟题往往题面会很难懂,特别是要细心,比如NOIP2016的玩具谜题就是模拟,还有NOIP2006的作业调度方案。总之细心就可以了。
图论
最短路(dijkstra、spfa、floyd)
这三种最短路的基本算法各有所长。对于Floyd,适用于需要任意两点之间的最短路的情况,往往是用来辅助图上DP的转移。Dijkstra则是稳定的最短路算法,如果发现题目会卡SPFA,就使用Dij,而且Dij可以求解次短路,使用优先队列优化,每次要弹掉队列中一定使用过的点。SPFA可以说不仅仅是最短路,它的思想可以用到很多方面:“更新过就再更新其他的,否则就不更新”。
另外,次短路问题也可以使用Dijkstra来求解,每次先更新最短路,再更新次短路即可。
差分约束
差分约束系统使用了很巧妙的最短路思想。dis[u]+(u,v)>=dis[v],如果这一条边是v的最短路上的边那么就是等于否则就是大于。这样就可以连一条边了。差分约束的经典题譬如poj-3169-layout。图中存在负环,就无解,否则的话,当到终点的距离为初始值INF,也就是无法更新到终点,就是1~N可以无限大。图中的最短路对应着1~N的最大距离。
如果题目反过来,要求1~N的最短距离的话,那么就是最长路了,在最长路中,dis[u]+(u,v)<=dis[v],所以加边自然也要反过来。
最小生成树(kruskal、prim)
kruskal是最常用的最小生成树的算法,然后就像SPFA一样,有时候出题人会去卡kruskal,所以prim也是必须掌握的。prim的思想和Dijkstra一样,都是先找一个当前所有未加入生成树的点中距离整个生成树距离最短的点加入生成树,然后更新与这一个点相连的所有点的最短距离即可。
kruskal经典的应用是一道“Save your cats”。要想到是最小生成树还是有思维难度的。prim算法例如Star Way To Heaven,这个就充分利用了prim的稳定性来解题的。
并查集
并查集有很多小技巧。首先就是路径压缩,可以大大提升并查集的稳定性。然后写过一题名叫:“好像就是并查集”。此题要求把原本在一个并查集内的一个元素移动到另一个并查集,这就不能只改变fa[]了,否则整颗子树就全部移过去了。我们可以忽略被移动的点,然后新建一个点代替需要移动的点,移动过去即可。并查集还有带权并查集,最常见的权就是整个并查集的元素的个数或者到更节点的路径长度之类的,也有难的例如在“BZOJ4025二分图”中,维护的就是奇环还是偶环,这个也是不好维护的,而且不能路径压缩。题中所说的加边可能两个端点已经是一个并查集内的,所以就要更新权值。
拓扑排序、dfs 序
这两个是一个东西,dfs序可以保证一个点,与他的子树,在序列中是一段连续的区间,这样我们就可以使用数据结构进行优化了。
二分图染色、二分图匹配
二分图的算法最好的莫过于匈牙利算法了。匈牙利算法每次去寻找一个交替路,然后更新con数组。用来求解二分图的最大匹配。二分图的最大匹配等于二分图的最小点覆盖。最小路径覆盖=最大独立集=点数-最小点覆盖。
1 bool dfs( int now ) 2 { 3 vis[ now ]=1; 4 for( int i=head[now];i;i=Next[i] ) 5 { 6 int son=to[ i ]; 7 if( son==now )continue; 8 if( !vis[ son ] ) 9 { 10 vis[ son ]=1; 11 if( con[ son ]<0 || dfs( con[ son ] ) ) 12 { 13 con[ now ]=son; 14 con[ son ]=now; 15 return 1; 16 } 17 } 18 } 19 return 0; 20 }
tarjan 找 scc、桥、割点、缩点
Tarjan找这些东西,大体上都是一样的,只是在一些小地方上不一样。两个数组dfn[],low[]。一个是访问的dfs序,还有一个是通过返祖边能到达的最小dfn的点。
割点:low[v]>=dfn[u]则u是割点。
割边:low[v]>dfn[u]则(u,v)是割边。
Scc:在for(int i=head[u];i;i=Next[i])之后,如果dfn[u]==low[u]则发现了强联通分量了,把栈内元素取出直到u为止。缩点就直接记下team[]即可。
无向图的边-双联通分量:无向图的边双的求法和强连通分量的类似,只是注意else if(dfn[v]<dfn[u] && fa!=v)中需要fa!=v。
给出无向图的点-双联通分量的求法(利用栈来求,割点属于每一个相连的点-双,所以它的team没有意义。):
1 void Tarjan(int u,int fa) 2 { 3 dfn[u]=low[u]=++DFN; 4 int child=0; 5 for(int i=head[u];i;i=Next[i]) 6 { 7 int v=to[i]; 8 if(!dfn[v]) 9 { 10 sta[++top]=i;//切记切记!!!要放在两个if里面,不能放在外面,否则反向的同一条边会被加2次!!! 11 child++; 12 Tarjan(v,u); 13 low[u]=min(low[u],low[v]); 14 if(low[v]>=dfn[u]) 15 { 16 is[u]=1; cnt++; bcc[cnt].clear(); 17 int now; 18 while(1) 19 { 20 now=sta[top--]; 21 if(team[from[now]] != cnt) team[from[now]]=cnt , bcc[cnt].push_back(from[now]); 22 if(team[to[now]] != cnt) team[to[now]]=cnt , bcc[cnt].push_back(to[now]); 23 if(from[now]==u && to[now]==v)break; 24 } 25 } 26 } 27 else if(dfn[v]<dfn[u] && fa!=v) 28 { 29 sta[++top]=i; 30 low[u]=min(low[u],dfn[v]); 31 } 32 } 33 if(fa==0) 34 { 35 if(child>1)is[u]=1; 36 else is[u]=0; 37 } 38 }
树的直径、树的重心
树的直径就是树上的最长链。任意选择一个点,算出dis,然后找到dis最大的那一个点(它一定是最长链的一个端点),再算一遍dis。就可以确定树的直径了。
树的直径可以延伸一个DAG的最长路。因为是有向图,所以从入度为0的点出发才可能是最长路。每次从队列中取出一个点,--rudu[],在rudu==0时更新最长路。
树的重心:树的重心也叫树的质心。找到一个点,其所有的子树中最大的子树节点数最少,那么这个点就是这棵树的重心,删去重心后,生成的多棵树尽可能平衡。与点分治相关。
树链剖分
树链剖分可以用于求解要修改的树上的关于链(路径)的查询问题。比如两点之间的路径上的最大边权。
定义一堆数组:fa[],sz[],top[],w[],dep[],son[].代表父亲节点,子树大小,当前链(剖过的)的顶端节点,在线段树中对应的位置,深度,重儿子。Dep[root]=1.
首先dfs一遍求出fa[],sz[],dep[],son[].然后第二便dfs,先把重链上的所有点遍历完,w对应线段树中一段连续的区间,然后把轻儿子的top设为儿子自己,再把轻链加入进去。
然后update,将所有的边权之类的转移到线段树中去,因为映射到线段树中的是点,所以如果要求边,就要把边下放到点。接着就是修改和查询了。不在同一条重链上,就跳深度较深的,在同一条链上的时候就直接查询即可。
数论
gcd、lcm
1 int gcd(int a,int b) 2 { 3 if(a%b==0)return b; 4 return gcd(b,a%b); 5 }
Lcm普通的就是lcm(a,b,c)=lcm(lcm(a,b),c)。Lcm(a,b)=a×b/gcd(a,b)。
埃氏筛法
线性筛质数与欧拉函数φ()。
1 void getPrime() 2 { 3 is[1]=1; 4 for(int i=2;i<=n;i++) 5 { 6 if(!is[i]) 7 { 8 Q[++top]=i; 9 Phi[i]=i-1; 10 } 11 for( int j=1 ; j<=top ; j++) 12 { 13 if( i * Q[j] > MAXN ) break ; 14 is[i * Q [j] ] = 1; 15 if( i%Q[j] == 0 ) 16 { 17 Phi[ i*Q[j] ] = Phi[i] * Q[j]; 18 break; 19 } 20 else 21 Phi[ i*Q[j] ] = Phi[i] * ( Q[j] - 1 ); 22 } 23 } 24 }
Exgcd、求解同余方程、逆元
求解形如ax+by=gcd(a,b)的方程的一组合法解。最后将x变成正数一定要先取个模!否则T飞!
1 int x,y; 2 int ex_gcd(int a,int b) 3 { 4 if(b==0) 5 { 6 x=1,y=0; 7 return a; 8 } 9 int ans=ex_gcd(b,a%b); 10 int t=x; 11 x=y; 12 y = t - a / b * y ; 13 return ans; 14 }
组合数
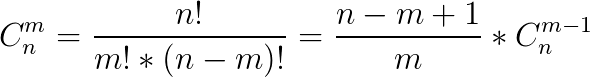
矩阵
矩阵快速幂优化递推。

数据结构
队列(单调队列)、栈(单调栈)
单调栈:是每次加入一个元素就与栈顶元素相比较,如果栈顶元素不优,那么就弹掉栈顶。显然,单调栈是可以二分弹栈的。比如一次考试的“lost my music”就是二分弹栈。
单调队列:主要运用于滑动窗口问题,可以用来求解限制长度的最大子段和。更多用于优化DP问题。注意单调队列与单调栈之内存储的往往是下标。还有二位单调队列。
单调栈:
while(st[ top ]<=a[i])top--;st[++top]=i;
单调队列:
1 while(Q[head]<=a[i] && head>=tail)head--; 2 Q[++head]=i; 3 while(i-Q[tail]>limit)tail++;
堆
堆可以使用系统的优先队列来实现,也很方便。但是有时候堆需要合并,那么就要手写可并堆了也就是左偏树。对于系统堆的重在运算符要特别注意不要打反了,虽然可以大于小于都试一试就可以了。如果是单个元素,直接加负数进去,出来再改为正数即可。如果是结构体,bool operator <(const ed a){const };记住打好两个const,bool返回真,代表把小于号左边的元素丢到后面去,因为系统为大根堆而我们是要小跟堆,那么就是v>a.v,就把大的丢到后面去了。
左偏树的一些操作:
删除堆顶元素:merge(ls[root],rs[root]);
加入一个元素:merge(root,now);
1 int merge(int x,int y) 2 { 3 if( ! x )return y; 4 if( ! y )return x; 5 if( key[ x ] > key[ y ] )swap( x , y ); 6 rs[ x ] = merge( rs[ x ] , y ); 7 if( dis[ rs[ x ] ] >= dis[ ls[ x ] ] )swap( ls[ x ] , rs[ x ] ); 8 dis[ x ] = dis[ rs[ x ] ]+1; 9 return x; 10 }
线段树、树状数组
如果题目不是卡常,线段树是个不错的选择,毕竟打得特别的熟练了。要注意打线段树之前特别注意是否有区间的可和并性。
树状数组:加入:for(int i=v;i<=n;i+=(i*-i))c[i]++; 查询:for(int i=v;i>=0;i-=(i&-i))res+=c[i]。特别注意树状数组是从1开始,如果输入有0,往往要++。
线段树:注意空间要够,注意Updata就可以了。还有就是动态开节点的线段树,只要访问的不多,值域可以开到很大。对于lazy的操作也是要注意的,下放置后要清空。区间取模只要记下max即可。
字典树
Tri树。主要用于字符串的查询与匹配,也可以用来对与亦或的01串的贪心。Tri树每一个点都要有很多儿子,然后信息是动态开的,要注意查询单词的时候,是需要结束标记的,所以插入的时候要在最后打好结束标记。
用于字符串匹配大部分就是AC自动机,这里不再赘述。
分块
复杂度O(n√n)。把区间分成√n段,belong[i]=i/cnt+1;两个点之间的完整的段直接查询,两个点所属的段,暴力一个一个查询。注意,大部分的分块任务线段树都可以完成,要优先使用线段树,当区间没有可并性或者不好查询时才考虑分块。例题:【HNOI2010】弹飞绵羊。
动态规划
Dp总的来说还是要设好状态,考虑转移的时候要全面。然后最好写对拍程序,防止出错。要发散自己的思维,想想是不是以前做过类似的题目。
背包 DP
01背包:for(int i=1;i<=n;i++) for(int j=C;j>=w[i];j--) dp[j]=max(dp[j],dp[j-w[i]]+v[i]); 当背包强制要求装满的时候:for(int i=1;i<=C;i++)dp[i]=-INF; 初始化为-INF,第一次只能从0转移,这样就都是满的了。
完全背包:就是把枚举j反过来就可以了。
多重背包:多一维枚举选择几个。
树形 DP
树形DP一般都要利用到子树。例题:UVA-10859 Placing Lampposts。
LCS、LIS、LCIS
最长公共子序列、最长上升子序列、最长公共上升子序列。这三个经典的问题。
最长公共子序列:设dp[i][j]表示序列a到i,序列b到j的长度,当a[i]==b[j]就可以转移dp[i][j]=dp[i-1][j-1]+1。否则dp[i][j] = max( dp[i-1][j] , dp[i][j-1] )。
最长上升子序列:设dp[i]表示长度为i的子序列的末尾值,显然末尾值越小越好,每次二分找一个更新即可,复杂度O(nlogn)。
最长公共上升子序列:综合二者,同样设dp[i][j]表示序列a到i,序列b到j的长度,只是转移更改一点即可。For(j)的时候,每次从dp[i][1~j-1]中找一个b[j]小于a[i]的最大值,当a[i]==b[j]时转移即可,若不想等,直接从dp[i-1][j]转移。
搜索
搜索大部分是用来打暴力对拍用的,但是如果要考搜索的话,往往对代码能力是一个挑战,比如玛雅游戏,如果不注意,可能调试就会耗时繁多。总而言之,搜索要加剪枝,并且如果是纯搜索题一定要想好细节再去打代码。
STL
Pair<int,int>可以不需要重载运算符。
Map<#,#>一个映射。
Queue<#>
注意事项
- 在网络流中因为对应的两条边亦或1即可得到,所以num从-1开始,head要初始化为-1.
- 分块的数组的下标从零开始。
- 注意乘法不要爆int。
- 取模要注意是否会出现负数!加模加回来!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号