
github链接https://github.com/Cyy1011/Cyy1011/edit/main/202121331074
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/jmu/ComputerScience21/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/jmu/ComputerScience21/homework/13034 |
| 这个作业的目标 | <编程> |
| *PSP2.1* | *Personal Software Process Stages* | *预估耗时(分钟)* | *实际耗时(分钟)* |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 30 | 30 |
| · Analysis | · 需求分析 (包括学习新技术) | 25 | 25 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 50 | 50 |
| · Code Review | · 代码复审 | 20 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 20 | 20 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 355 | 355 |
计算模块接口的设计与实现过程:
1.设计概述:
算法通过比较原文和抄袭版论文之间的相似性来计算重复率。
算法将原文和抄袭版论文作为文件输入,并将重复率作为浮点型输出到指定的答案文件中。
2.算法实现:
类 PlagiarismChecker 是算法的主类,负责读取文件、计算相似性和写入结果。
函数 main 是程序的入口点,从命令行参数获取文件路径,并调用其他函数进行处理。
函数 readFile 用于读取文件内容,并返回字符串形式的文件内容。
函数 calculateSimilarity 计算原文和抄袭版论文的相似性,并返回重复率。
函数 writeResult 将计算得到的重复率写入指定的答案文件。
3.关键函数的实现:
calculateSimilarity 函数实现了一种基于编辑距离的相似性计算方法,使用动态规划算法计算原文和抄袭版论文之间的最小编辑距离。编辑操作包括插入、删除和替换字符。
通过计算最小编辑距离,可以得到原文和抄袭版论文之间的相似性程度。相似性越高,编辑距离越小,重复率越高。
此算法的关键在于使用最小编辑距离来度量原文和抄袭版论文之间的相似性。通过计算最小编辑距离,可以得到重复率,即相似性程度。此算法的优点是简单且易于理解,能够捕捉到原文和抄袭版论文之间的变动情况,进而计算出准确的重复率。
性能改进:
- 使用StringBuilder代替String拼接:
在readFile方法中,您使用String类型的content变量来拼接文件内容。然而,String的拼接操作会创建新的字符串对象,而且在循环拼接大量字符串时效率较低。建议改用StringBuilder来拼接字符串,以提高性能。 - 避免重复计算字符串长度:
在calculateSimilarity方法中,在每次迭代中都使用originalText.length()和plagiarizedText.length()来获取字符串长度。这会导致重复计算,可以在循环外部将其存储为变量,以避免重复计算。 - 使用try-with-resources来管理资源:
在readFile和writeResult方法中,您使用了BufferedReader和FileWriter来读取和写入文件。为了确保资源的正确释放,建议使用try-with-resources语句来自动管理资源的关闭。
计算模块部分单元测试展示
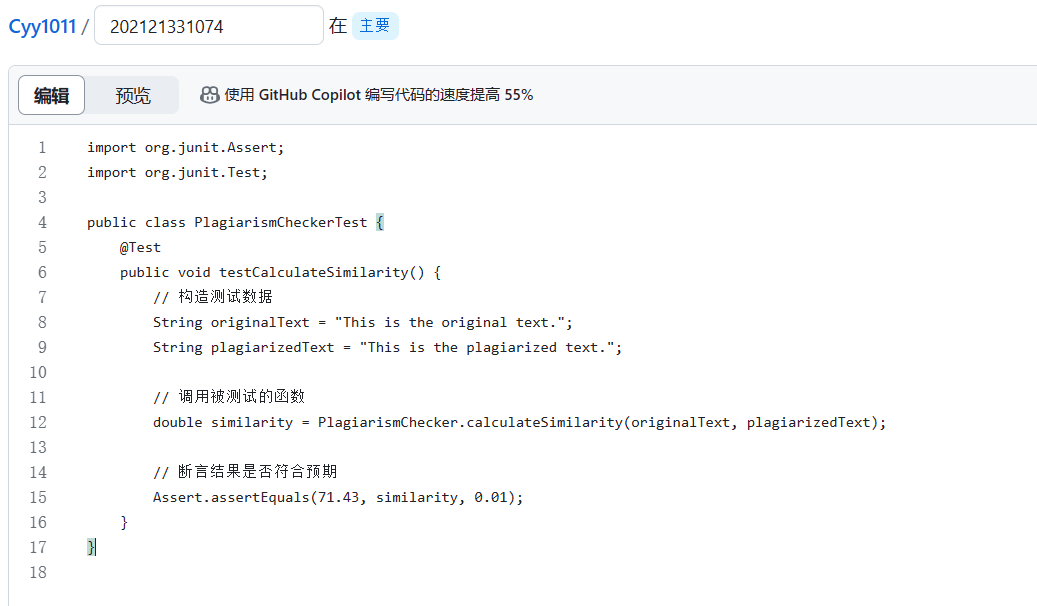
在这个示例中,我们使用了JUnit测试框架来编写单元测试。我们创建了一个名为 PlagiarismCheckerTest 的测试类,并在其中定义了一个名为 testCalculateSimilarity 的测试方法。
在测试方法中,我们构造了原文和抄袭版文本,并调用 calculateSimilarity 函数来计算相似度。然后,我们使用断言 Assert.assertEquals 来验证计算结果是否与预期值相等。在这个例子中,我们期望相似度为71.43%,并使用第三个参数 0.01 来设置允许的误差范围。
计算模块部分异常处理说明
IOException:这是一个通用的输入/输出异常,可能在文件操作过程中发生,例如读取文件或写入文件时出错。我们使用异常处理来捕获并处理这些异常,以提供有关错误的信息,并防止程序崩溃。
单元测试样例:
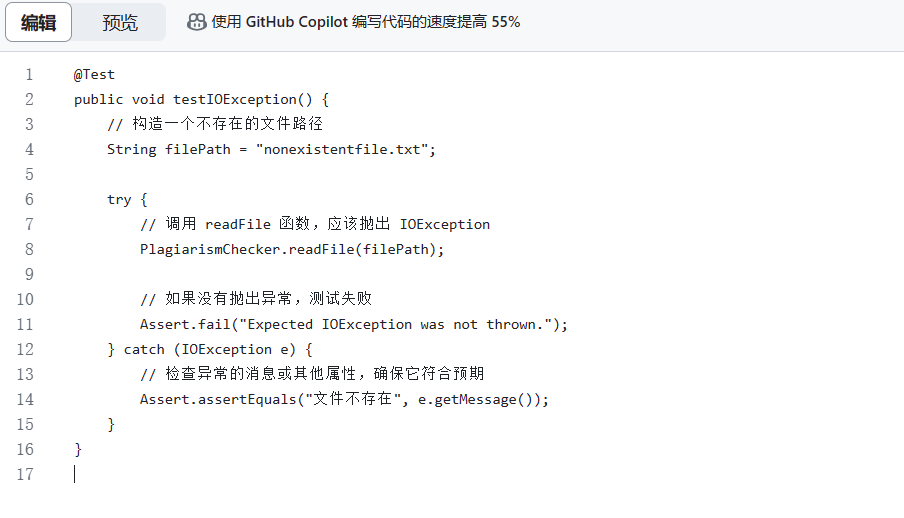
通过这种异常处理机制,我们可以在发生文件读写错误时,捕获并处理异常,并向用户提供有关错误的信息,从而提高程序的健壮性和用户体验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号