第一次个人编程作业
| 这个作业属于哪个课程 | 班级链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
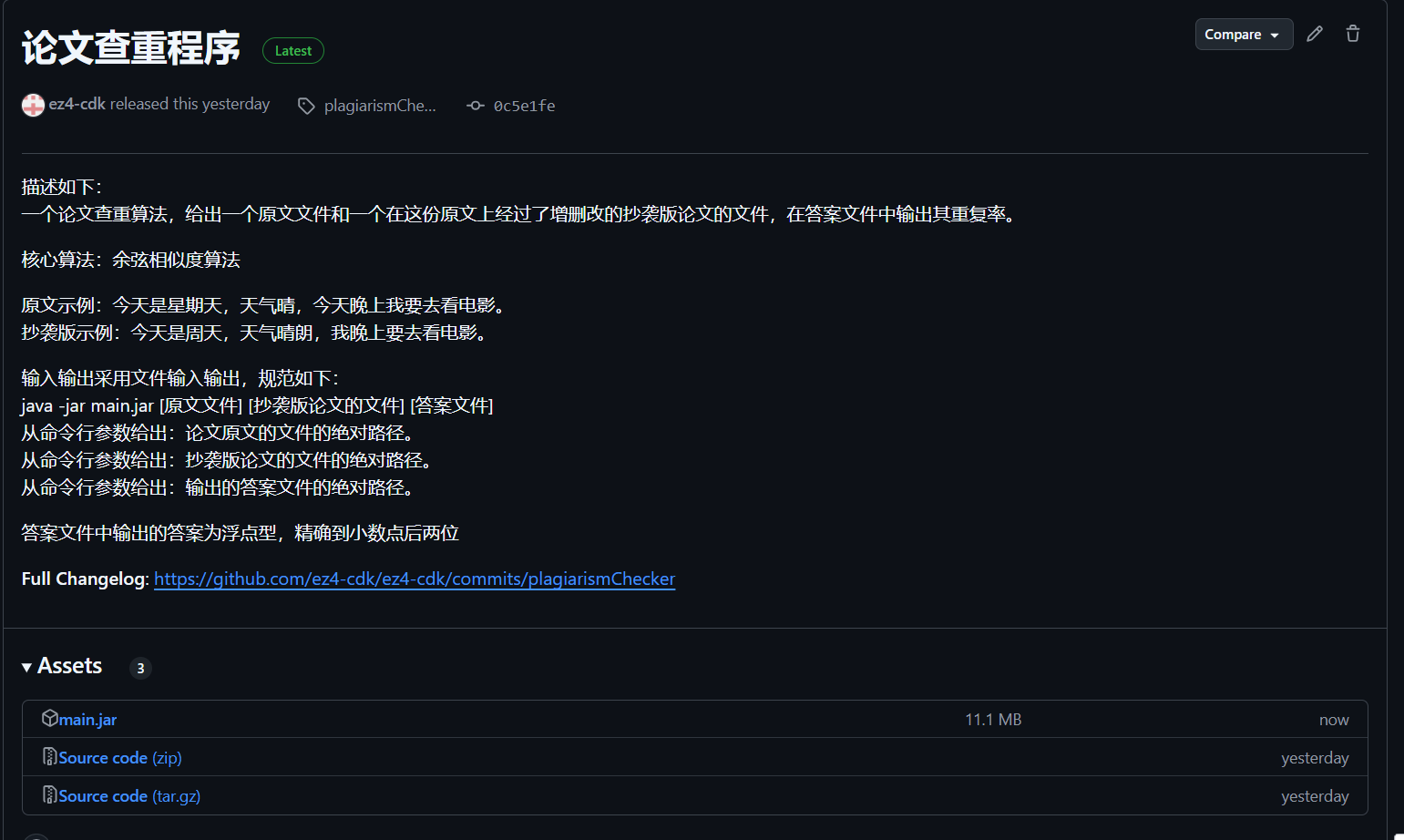
| 这个作业的目标 | 设计一个论文查重程序,并且整理开发文档 |
github:https://github.com/ez4-cdk/ez4-cdk/tree/master/3122004816
已发布
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 330 | 480 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 30 | 60 |
| · Design Review | · 设计复审 | 30 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| · Design | · 具体设计 | 60 | 150 |
| · Coding | · 具体编码 | 60 | 30 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 300 | 300 |
| · Test Repor | · 测试报告 | 120 | 120 |
| · Size Measurement | · 计算工作量 | 120 | 60 |
| Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 120 |
| · 合计 | 1200 | 720 | 930 |
二、项目设计
新建一个以学号为名的文件夹
上传了两次,第二次为最终版,优化了查重算法
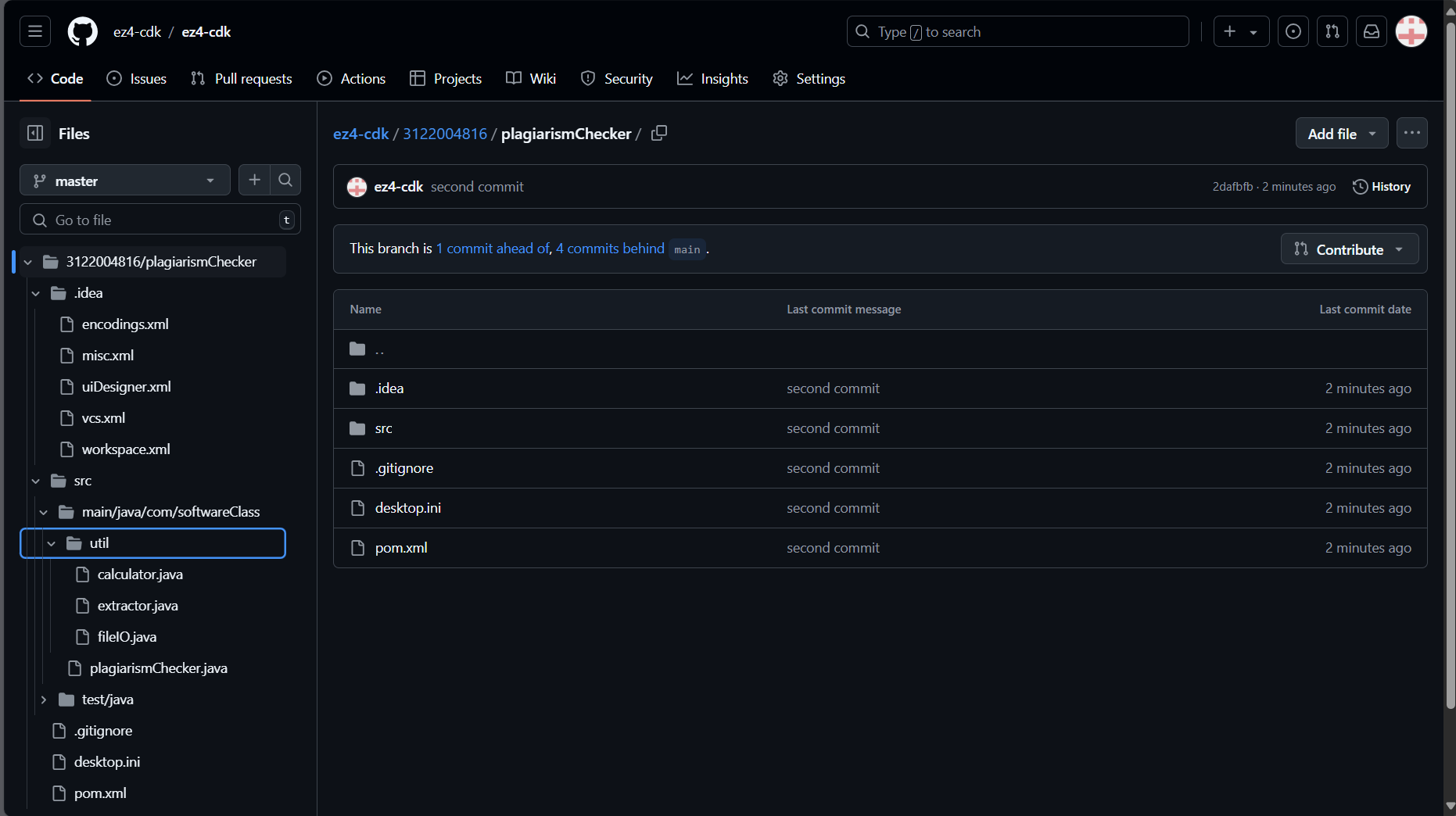
项目结构及解释
com
一softwareClass(包名)
一一test(测试数据)
一一一一answer(答案输出文件夹)
一一一一一一answer.txt(答案输出文件)
一一一一一一errorLogger.txt(异常日志文件)
一一一一example(样本文件夹)
一一一一一一orig_0.8_add.txt(样本文件)
一一一一一一orig_0.8_del.txt(样本文件)
一一一一一一orig_0.8_dis_1.txt(样本文件)
一一一一一一orig_0.8_dis_10.txt(样本文件)
一一一一一一orig_0.8_dis_15.txt(样本文件)
一一一一origin(对照文件夹)
一一一一一一orig.txt(原文文件)
一一util(工具类)
一一一一calculator(计算方法)
一一一一extractor(分词器)
一一一一fileIO(文件IO操作)
一一log4j.properties(配置文件-log4j)
一一plagiarismChecker(主类)
接口设计:
本程序一共有:
4个类:calculator、extractor、fileIO、plagiarismChecker
5个函数:
calculator{double calculateCosineSimilarity(Map<String, Integer> origFreq, Map<String, Integer> plagiarizedFreq) ;}
extractor{Map<String, Integer> extractWordFrequency(String text) ;}
fileIO{
String readFile(String filePath) throws IOException ;
void writeOutput(String filePath, Object T) throws IOException ;
}
plagiarismChecker{void main(String[] args);}
运行jar包时输入指令格式如下:
java -jar main.jar C:\tests\org.txt C:\tests\org_add.txt C:\tests\ans.tx
类间关系
①主类为plagiarismChecker,接收cmd输入的三个参数:原文路径、样本路径、答案路径
②主类内调用fileIO的readFile接口对原文文件以及样本文件进行读取到两个对象中
③调用extractor的extractWordFrequency接口对两个对象进行分词,返回样本对象以及原文对象的哈希表
④调用calculateCosineSimilarity接口采用余弦相似度算法对两个哈希表进行运算,返回查重率
⑤调用fileIO的writeOutput接口输出查重率到指定路径的文件夹
算法流程图
[开始]
↓
[初始化变量]
↓
[对于每个 word in allWords]
↓
[获取 origCount 和 plagiarizedCount]
↓
[更新 dotProduct, normA, normB]
↓
[检查 normA 或 normB 是否为零?]
↙ ↘
[是] [否]
↓ ↓
[返回 0.0] → [计算余弦相似度]
↓
[返回结果]
↓
[结束]
算法关键以及独特之处
关键:引用两个向量的余弦值来体现文本的相似度,1表示完全相同,-1表示完全相反,0表示没有相似性,步骤包括:
合并所有词汇
使用一个集合 allWords 来存储两个文本中的所有不同单词,以便对它们进行统一处理。
点积和范数的计算:
点积
计算两个向量在相同位置上的乘积之和,代表了两个文本之间的相似度。
L2范数(normA 和 normB):
分别计算原始文本和抄袭文本的范数,用于归一化,使得最终的相似度值在 0 到 1 之间。
防止除以零
在计算余弦相似度时,必须检查 normA 和 normB 是否为零,以避免出现除以零的情况。如果任一文本的范数为零,说明文本为空或没有任何可比的单词,返回相似度为 0.0。
独到之处
不需要关注每个词出现的顺序,而是关注每个词出现的频率。
而且算法效率也较高,一万字左右的长文本处理效果较好。
三、性能分析
Jprofiler
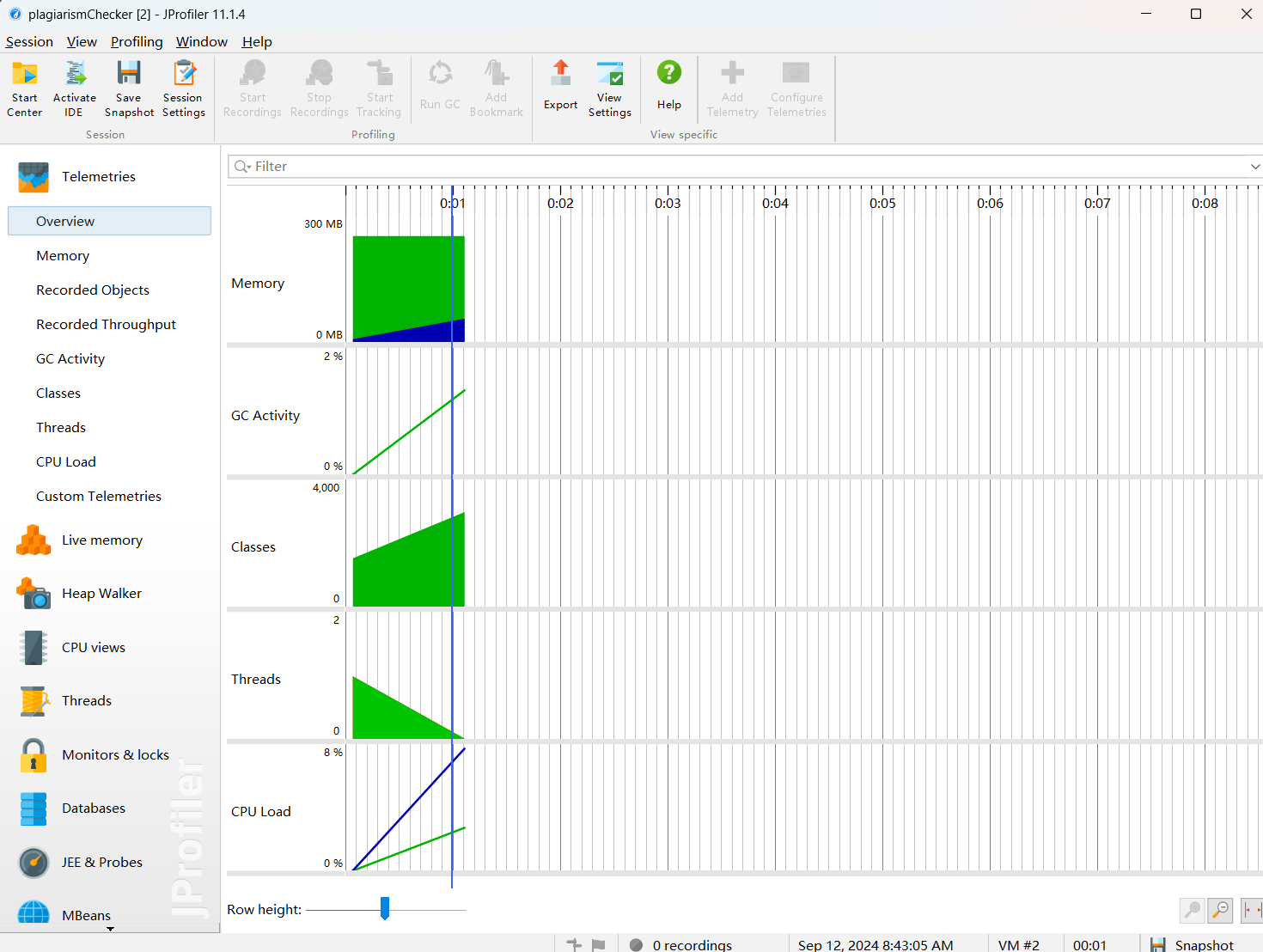
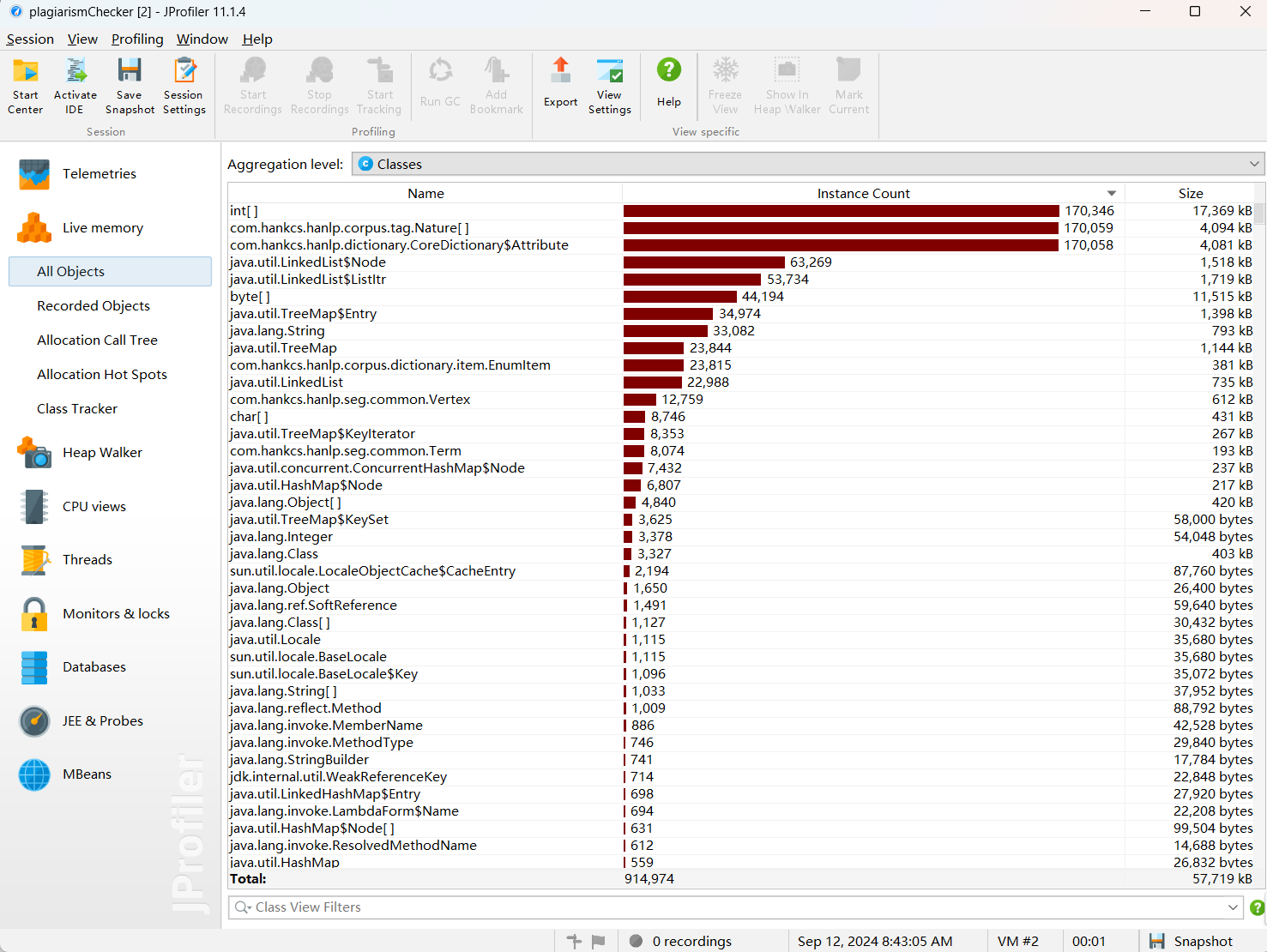
占用内存最大的函数
//提取关键字
public static Map extractWordFrequency(String text) {
text = text.replaceAll("[^\\u4e00-\\u9fa5\\w\\s]", ""); // 保留中文及字母数字
Segment segment = HanLP.newSegment(); // 创建分词器实例
List termList = segment.seg(text); // 使用分词器进行分词
Map frequencyMap = new HashMap<>(); // 存储词频的Map
for (Term term : termList) {
if (term.nature.toString().startsWith("n")) { // 只提取名词
frequencyMap.put(term.word, frequencyMap.getOrDefault(term.word, 0) + 1); // 更新词频
}
}
return frequencyMap; // 返回词频Map
}
改进思路
由jprofiler的性能分析图可知,占用内存比较大的是所用到的中文分词库hanlp,次之是LinkedList。
所以可以改进的两个部分如下:
1.在读取文本的同时进行分词去重。两条线程控制同步进行,类似生产者-消费者问题。
2.读取文本时使用的数据结构优化。map所占内存有点过大,可以选择合适的数据结构进行优化。
四、测试
测试思路在代码注释中
1.calculator
import com.softwareClass.util.calculator;
import org.junit.jupiter.api.Test;
import java.util.HashMap;
import java.util.Map;
import static org.junit.jupiter.api.Assertions.assertEquals;
public class CalculatorTest {
//两个向量都为空
@Test
public void testCalculateCosineSimilarity_BothEmpty() {
Map origFreq = new HashMap<>();
Map plagiarizedFreq = new HashMap<>();
double similarity = calculator.calculateCosineSimilarity(origFreq, plagiarizedFreq);
assertEquals(0.0, similarity, 0.01);
}
//有一个向量为空
@Test
public void testCalculateCosineSimilarity_OneEmpty() {
Map origFreq = new HashMap<>();
origFreq.put("word1", 3);
Map plagiarizedFreq = new HashMap<>();
double similarity = calculator.calculateCosineSimilarity(origFreq, plagiarizedFreq);
assertEquals(0.0, similarity, 0.01);
}
//两个相似的向量
@Test
public void testCalculateCosineSimilarity_NonZeroSimilarity() {
Map origFreq = new HashMap<>();
origFreq.put("word1", 3);
origFreq.put("word2", 5);
Map plagiarizedFreq = new HashMap<>();
plagiarizedFreq.put("word1", 2);
plagiarizedFreq.put("word2", 4);
double similarity = calculator.calculateCosineSimilarity(origFreq, plagiarizedFreq);
assertEquals(0.999846, similarity, 0.01);
}
//两个不相似的向量
@Test
public void testCalculateCosineSimilarity_NoCommonWords() {
Map origFreq = new HashMap<>();
origFreq.put("word1", 3);
origFreq.put("word2", 5);
Map plagiarizedFreq = new HashMap<>();
plagiarizedFreq.put("word3", 2);
plagiarizedFreq.put("word4", 4);
double similarity = calculator.calculateCosineSimilarity(origFreq, plagiarizedFreq);
assertEquals(0.0, similarity, 0.01);
}
}
2.extractor
import org.junit.jupiter.api.Test;
import java.util.HashMap;
import java.util.Map;
import static com.softwareClass.util.extractor.extractWordFrequency;
import static org.junit.jupiter.api.Assertions.assertEquals;
public class ExtractorTest {
//分词器分词“今天天气不错,适合出去玩。” 包括名词、动词和形容词
@Test
public void testExtractWordFrequency_withChineseText() {
// 示例输入文本
String text = "今天天气不错,适合出去玩。";
Map frequencyMap = extractWordFrequency(text);
System.out.println("分词结果: " + frequencyMap);
// 预期结果
Map expectedMap = new HashMap<>();
expectedMap.put("天气", 1);
expectedMap.put("不错", 1);
expectedMap.put("适合", 1);
expectedMap.put("出去", 1);
expectedMap.put("玩", 1);
// 验证实际结果和预期结果是否相同
assertEquals(expectedMap, frequencyMap);
}
}

3.fileIO
import com.softwareClass.util.fileIO;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.junit.jupiter.api.Assertions.assertThrows;
public class FileIOTest {
private String testFilePath;
@BeforeEach
public void setUp() {
// 设置测试文件路径,采用绝对路径,testFile.txt提前创建,后续测试完会删除
testFilePath = "C:\\Users\\11298\\Desktop\\3122004816\\plagiarismChecker\\src\\test\\java\\res\\test\\answer\\testFile.txt";
}
@AfterEach
public void tearDown() throws IOException {
// 删除测试文件
Files.deleteIfExists(Paths.get(testFilePath));
}
//测试写入和读出
@Test
public void testReadFile_existingFile() throws IOException {
String content = "Hello, World!";
Files.writeString(Paths.get(testFilePath), content);
String result = fileIO.readFile(testFilePath);
// 验证结果是否匹配
assertEquals(content, result);
}
//// 测试读取一个不存在的文件
@Test
public void testReadFile_nonExistingFile() {
String nonExistingFilePath = "non_existing_file.txt";
// 验证抛出 IOException
assertThrows(IOException.class, () -> fileIO.readFile(nonExistingFilePath));
}
//测试当不存在答案文件时写入是否允许
@Test
public void testWriteOutput_createsNewFile() throws IOException {
double valueToWrite = 123.45678;
fileIO.writeOutput(testFilePath, valueToWrite);
// 验证文件被创建且内容正确
String content = Files.readString(Paths.get(testFilePath));
assertEquals("123.46", content);
}
// 验证再次输入文件内容时是否会被覆盖
@Test
public void testWriteOutput_overwritesExistingFile() throws IOException {
fileIO.writeOutput(testFilePath, 123.45678);
fileIO.writeOutput(testFilePath, 987.65432);
String content = Files.readString(Paths.get(testFilePath));
assertEquals("987.65", content); // 确保保留了两位小数
}
}

4.PlagiarismCheckerTest
import com.softwareClass.plagiarismChecker;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.nio.file.Files;
import java.nio.file.Paths;
import static org.junit.jupiter.api.Assertions.assertEquals;
public class PlagiarismCheckerTest {
private String origFilePath;
private String plagiarismFilePath;
private String outputFilePath;
//预输入的绝对路径:原文路径 样本路径 答案路径
@BeforeEach
public void setUp() throws Exception {
origFilePath = "C:\\Users\\11298\\Desktop\\3122004816\\plagiarismChecker\\src\\test\\java\\res\\test\\origin\\orig.txt";
plagiarismFilePath = "C:\\Users\\11298\\Desktop\\3122004816\\plagiarismChecker\\src\\test\\java\\res\\test\\example\\orig_0.8_dis_15.txt";
outputFilePath = "C:\\Users\\11298\\Desktop\\3122004816\\plagiarismChecker\\src\\test\\java\\res\\test\\answer\\answer.txt";
}
//测试整个论文查重程序
@Test
public void testCheckPlagiarism() throws Exception {
plagiarismChecker.main(new String[]{origFilePath, plagiarismFilePath, outputFilePath});
String content = Files.readString(Paths.get(outputFilePath));
assertEquals(0.90,Double.parseDouble(content),0.10);
}
}

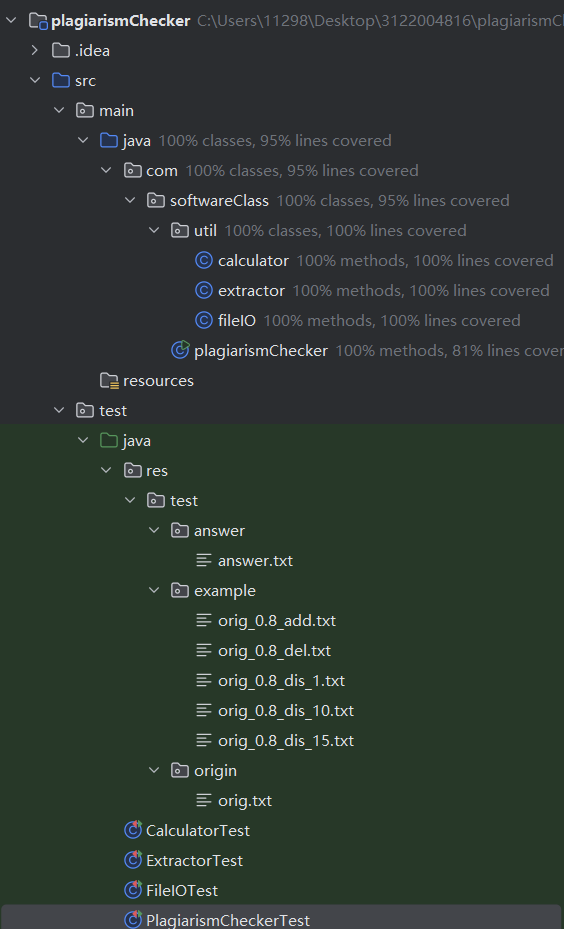
测试覆盖率
五、异常处理
1.参数不正确
当输入命令行参数不足3个字符串时,则立刻返回,代码如下:
if (args.length !=3 ){
return;
}
2.除数为0
这个异常已经被考虑进计算器calculator并且避开了,在calculator中含如下代码:
if (normA == 0 || normB == 0) {
return 0.0; // 避免除以零
}
当除数为0时,直接返回0.0,避免除以0的情况。
3.IO异常或其他异常
这里则输出这些错误信息加以提醒
public static void main(String[] args) {
try {
......
} catch (IOException e) {
System.err.println("Error: " + e.getMessage());
logger.error("文件读取或写入出现错误:{}", e.getMessage());
} catch (Exception e) {
System.err.println("Unexpected error: " + e.getMessage());
logger.error("发生了意外错误:{}", e.getMessage());
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号