



第一个爬虫与测试
第一个爬虫和测试
一、完善球赛程序,测试你写的球赛程序,所有函数的测试结果
实例代码
预测球队比赛结果代码:
def GameOver(a,b):
if a>=10 and b>=10:
if abs(a-b)==2:
return True
if a<10 or b<10:
if a==11 or b==11:
return True
else:
return False
测试:


1 def GameOver(a,b): 2 if a>=10 and b>=10: 3 if abs(a-b)==2: 4 return True 5 if a<10 or b<10: 6 if a==11 or b==11: 7 return True 8 else: 9 return False 10 try: 11 c=GameOver(15,13) 12 print(c) 13 except: 14 print("error")
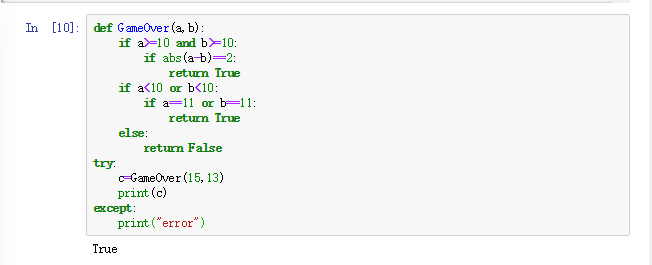
运行结果正确
二、使用request库的get()函数访问百度网页20次并且打印返回状态,text内容,计算text()属性和content()属性所返回网页内容的长度
1.访问一次
a.代码
import requests
r = requests.get("http://www.google.cn",timeout=30)
print("状态 = {}".format( r.status_code))
print("text内容 = {}".format(r.text))
print("text编码方式 = {}".format(r.encoding))
print("二进制形式 = {}".format(r.content))
b.结果
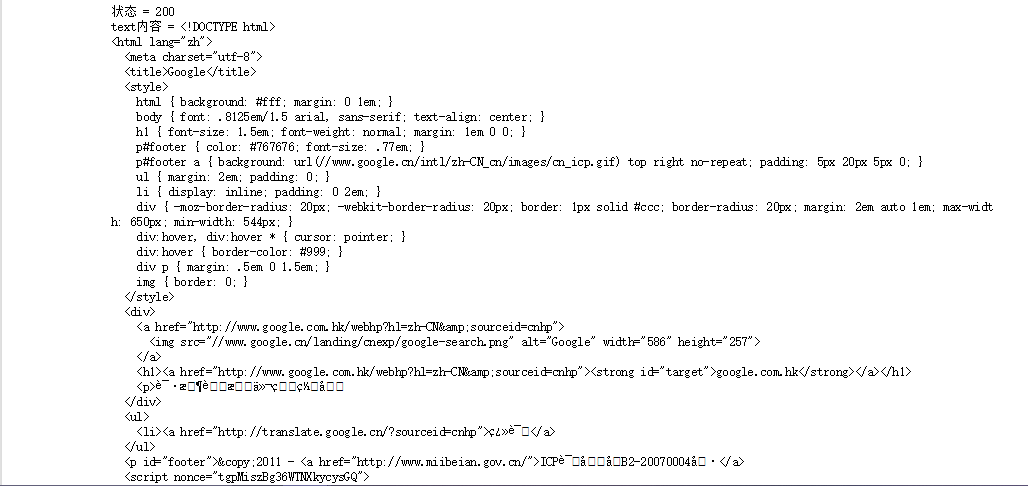


2、访问20次
a、代码
import requests
for i in range(20):
r = requests.get("http://www.google.cn",timeout=30)
print("状态 = {}".format( r.status_code))
print("text编码方式 = {}".format(r.encoding))
print("text内容 = {}".format(r.text))
print("二进制形式 = {}".format(r.content))
b、结果
http://localhost:8888/notebooks/Untitled15.ipynb?kernel_name=python3
太长了可以自行查看👆
三、HTML页面的简单操作
a、代码
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup("<!DOCTYPE html><html><head><meta charset=‘utf-8‘>\
<title菜鸟教程(rounoob.com)</title></head><body>\
<h1>我的第一标题</h1>\
<p id='first'>我的第一个段落。</p></body>\
<table border=‘1‘><tr><td>row 1,cell 1\
</td><td>row 1,cell 2</td></tr><tr><td>row 2,cell 1\
</td><td>row 2,cell 2</td></tr</table></html>")
print(soup.head,"06") #获取并打印head标签的内容和学号后两位
print(soup.body) #获取并打印body的内容
print(soup.find_all(id="first")) #获取并打印id为first的文本
print(soup.h1.string,soup.p.string) #获取并打印html页面中的中文字符
b、结果


