

jieba库使用以及好玩的词云
jieba库、词云(wordcloud)的安装
打开window的CMD(菜单键+R+Enter)
一般情况下:输入pip install jiaba(回车),等它下好,建议在网络稳定的时候操作
不行就试试这个:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jiaba
词云安装也是如此:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple wordcloud
显示Successfully installed....就安装成功了(如下图👇:)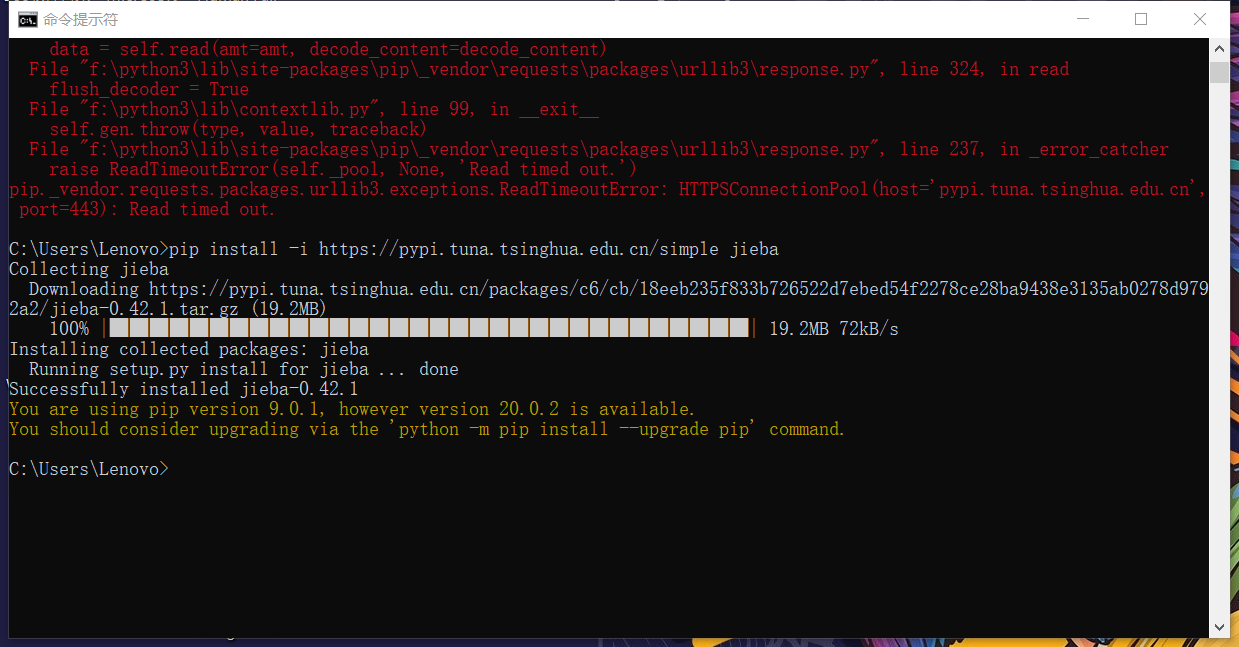
jieba库的使用
用jieba库分析文章、小说、报告等,到词频统计,并对词频进行排序
代码👇
(仅限用中文):


1 # -*- coding: utf-8 -*- 2 """ 3 Created on Wed Apr 22 15:40:16 2020 4 5 @author: ASUS 6 """ 7 #jiaba词频统计 8 import jieba 9 txt = open(r'C:\Users\ASUS\Desktop\创意策划书.txt', "r", encoding='gbk').read()#读取文件 10 words = jieba.lcut(txt)#lcut()函数返回一个列表类型的分词结果 11 counts = {} 12 for word in words: 13 if len(word) == 1:#忽略标点符号和其它长度为1的词 14 continue 15 else: 16 counts[word] = counts.get(word,0) + 1 17 items = list(counts.items())#字典转列表 18 items.sort(key=lambda x:x[1], reverse=True) #按词频降序排列 19 n=eval(input("词的个数:"))#循环n次 20 for i in range(n): 21 word, count = items[i] 22 print ("{0:<10}{1:>5}".format(word, count))
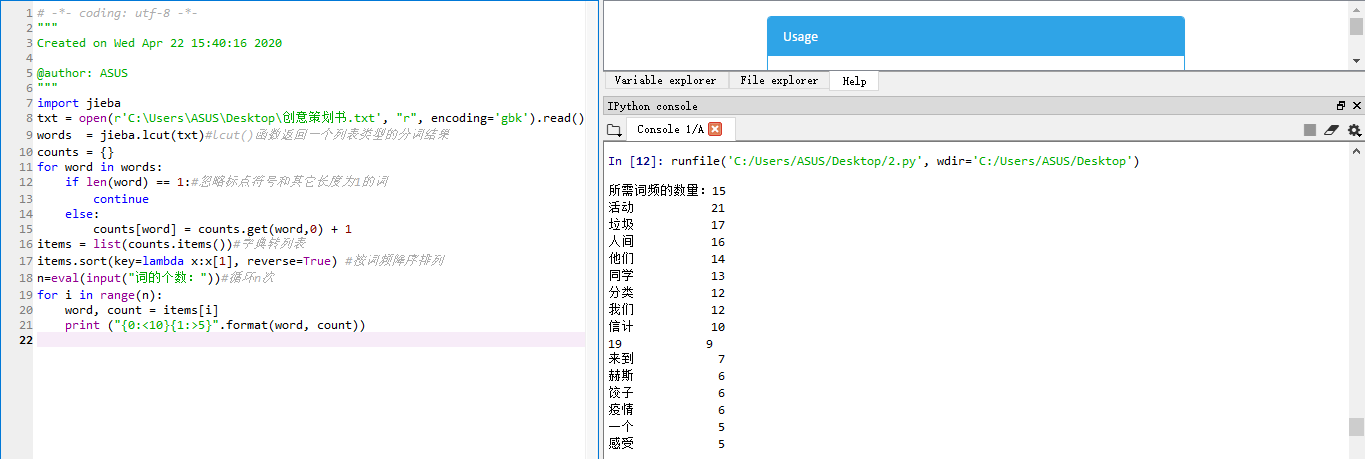
(用于英文需要做些许调整):
def getText():
txt=open('hamlet.txt')#文件的存储位置
txt = txt.lower()#将字母全部转化为小写
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
txt = txt.replace(ch, " ") #将文本中特殊字符替换为空格
return txt
好玩的词云
做一个词云图
1 import jieba 2 import wordcloud 3 import matplotlib.pyplot as plt 4 f = open(r"C:\Users\ASUS\Desktop\创意策划书.txt", "r", encoding="gbk")#有些电脑适用encoding="utf-8",我电脑只能用encoding="gbk",我也不知道为啥 5 t = f.read() 6 f.close() 7 ls = jieba.lcut(t) 8 9 txt = " ".join(ls) 10 w = wordcloud.WordCloud( \ 11 width = 4800, height = 2700,\ 12 background_color = "black", 13 font_path = "msyh.ttc" #msyh.ttc可以修改字体,在网上下载好自己喜欢的字体替换上去 14 ) 15 myword=w.generate(txt) 16 plt.imshow(myword) 17 plt.axis("off") 18 plt.show() 19 w.to_file("词频.png")#生成图片
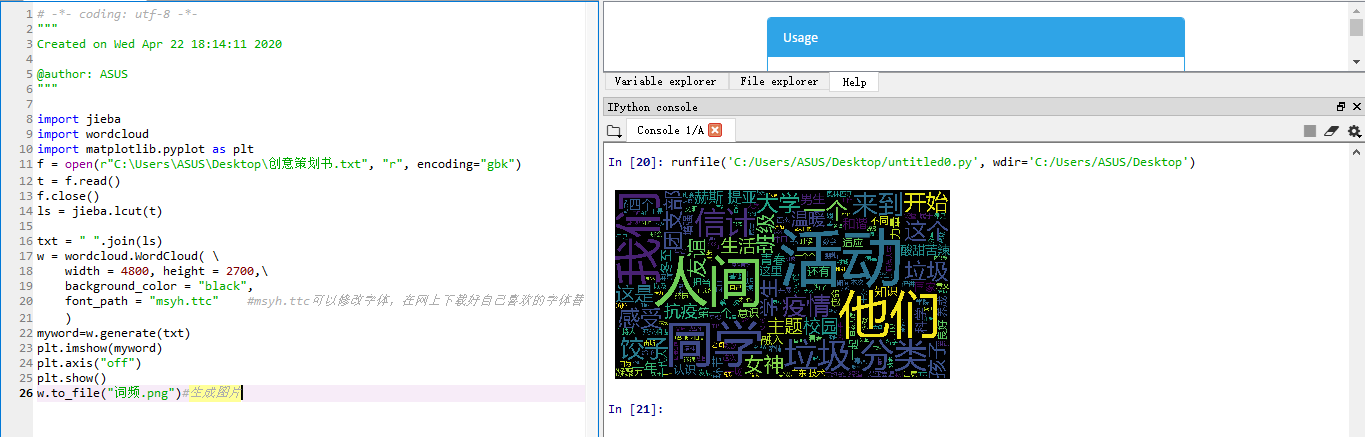
统计的内容可以忽略,代码可以认真看看
