【学习笔记】python
1. 基础
1.1 基础
- python是高级语言,CPU并不认识python代码,需要运行的时候才会动态翻译成cpu指令:python源码经过编译后,变成了一个个的字节码文件:.pyc,是一个二进制文件,然后不断的取出字节码的指令解释执行;
- python的数值类型三种:整型(int):包括正和负,其次boolean是整型的子类; 浮点型(float):小数部分和整数部分组成,其次也可以用科学计数法表示:2.5e2 = 2.5 * 10^2 = 250; 复数(complex):a+bj,或者complex(a, b),实部和虚部都是浮点型;
- isinstance(obj, classA) 会检查对象是否是目标类型的实例,子父类也会满足;hasattr(obj, x) 会检查对象是否有属性x
- 优先级:not>and>or; 乘方>按位取反>四则运算>位移>位运算>比较运算>逻辑运算
- for循环变量的作用域是在for结束后依旧有效,但是列表推导式中的变量在列表外就失效了;
- print()每执行一次默认在最后加上了\n,也就是默认会换行;if想要不换行则在后面加上end,例如 print(i, end = '')
- 逻辑操作符都是短路操作,优先级not>and>or;逻辑操作的返回值是最终能确定逻辑表达式值的最后一个变量:
3 and 4 # 结果为4
3 or 4 # 结果为3,3就可以直接确定逻辑表达式为真了,后面就不执行了;
- assert:断言,简单的理解就是断言为假的时候就会触发AssertionError异常
- if知道数组的大小,那创建list的时候就指定大小:lst = [None] * n;不断的append会不断地创建新的副本,if内容不变的时候,用tuple代替list节约内存;
- False,0,'',[],{},(),set()都可以视为False,但不是None。
1.2 关于命名
- 类和异常的命名采用每个单词首字母大写的方法(MyClass);常量采用全部字母大写加下划线的方法(FILE_SIZE);
- 其余所有(包、模块、变量、方法)都采用小写字母的方法(my_method);
- if方法或者成员属性为私有的,则加单下划线(self._member),if父类想要防止和子类重名,可以加__双下划线,这时候会被解释权自动改名,加上类名为前缀;
- 单下划线表示的是protected的属性,只允许本身和子类进行访问,一般约定单下划线开头的函数时模块私有的,所有from module import * 时不会进行导入,同时不建议直接在子类中访问父类中protected的属性,可以通过方法的方式(get_attr)来访问;
- 双下划线表示的是private的属性,只能是允许当前类进行访问,连子类也不可以,这类属性在运行时会自动改名:_类名__属性
- 使用双下划线开头的属性,实际上依然可以在外部访问,所以这种方式我们一般不用,(因为其实就是python将其自动改名了)
1.3 关于False
在python中,以下对象会被看作是False:
- 常量None和False
- 值为0的类型:0, 0.0, 0j, decimal.Decimal(0), fractions.Fraction(0,1)
- 空的序列和容器:’‘, (), {}, [], range(0), range(8,5)等
- 该对象的类定义了双下划线bool方法,且该方法返回False
- 该对象的类定义了双下划线len方法,且该方法返回0
1.4 关于比较
- 任何两个对象都可以比较,但是在python3中,字符串不允许和任何类型比较; 链式比较:4>33 # True 4>3 and 33(优先级:比较高于等于)
- is判断是否是指向同一个对象(判断两个对象的id是否相等),== 会调用双下划线eq方法判断是否相等(判断两个对象的值是否相等)
- 空不可变对象is空不可变对象 为True;空可变对象==空可变对象 为True; 不可变对象的id是相同的,可变对象的id是不同的;
a, b = 1, 1
print(a is b) # True,相同值的不可变对象赋值的地址相同
a, b = [], []
print(a is b) # False,可变对象的id是不同的;
- 字典间的比较时:只要是同样的键值对,用==比较时,就是true
# 下面是不同的字典初始化的方法
a = dict(one=1, two=2, three=3)
b = {'one': 1, 'two': 2, 'three': 3}
c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
d = dict([('two', 2), ('one', 1), ('three', 3)])
e = dict({'three': 3, 'one': 1, 'two': 2})
f = dict({'one': 1, 'three': 3}, two=2)
a == b == c == d == e == f # True
1.5 关于赋值
- python中的赋值语句有很多需要注意的地方,例如最常见的交换
众所周知,在python中是可以直接交换两个变量的值的,不需要像其他语言一样引入第三个变量
a, b = b, a # 这其实是利用了解包,当后面的b,a这样写的时候其实是装包成为了元组(b,a),然后进行赋值的时候其实就是将这个元组解包赋值给了a,b
# 但是需要注意的是,等号左边的两个不能有依赖关系
x = [0, 1]
i = 0
i, x[i] = 1, 2 # 0,2 因为前面两者有依赖关系,所以当i更新后,变更的是x[1],而不是x[0]!!
- 赋值中= 和+= 的区别:
L = L+L相当于重新赋值,L的id会发生改变
L = [1,2]
M = L
L = L + L
L.append(1)
print(L, M)
-------
2197624871872
2197625196800
[1, 2, 1, 2, 1] [1, 2]
L += L 是可变对象的修改,L的id不会发生改变
L = [1,2]
M = L
L += L
L.append(1)
print(L, M)
------------
[1, 2, 1, 2, 1] [1, 2, 1, 2, 1]
1.6 关于条件分支
- 条件分支在不指明指定的返回值时,会默认返回None,在写的时候,建议函数或者方法要么都有显式的返回值,要么都没有,不要混用,此外对于显式返回的分支,每个分支的返回值类型和个数尽量相同;
- break可以立即退出循环语句,包括else;pass是用来在循环或者判断中进行占位的(比如暂时没想好功能该怎么写,就先占位);
- 在for或者while循环中,if在这个循环外面有else,那么只有当整个循环过程中没有任何一个满足if的条件时,才会在执行结束后执行else后的,否则不会执行
for i in range(4):
if i == 2:
print(i, "found")
break
print(i, "not what we want")
else:
print("not found")
# 输出:只要有满足if的那else就不会执行
0 not what we want
1 not what we want
2 found
1.7 深拷贝浅拷贝
- 对于不可变对象(字符串、元祖、数值类型,bool),浅拷贝和深拷贝都是和赋值操作一样,对象的id与原来的一样;
- 对于可变对象(列表、字典、集合),深拷贝是拷贝了原来对象的全部元素,包含多层的嵌套;浅拷贝顾名思义,就是只是简单的拷贝了一层,对于里面的复杂结构(比如列表里的嵌套列表),同样只是引用,所以修改原来的值会影响;
- 通俗点理解:赋值就是跟原来对象完全一样(因为只是得到了引用);浅拷贝对于无复杂结构进行了完全拷贝,对复杂结构得到了引用;深拷贝彻底进行了完全拷贝;
a = [1,2]
import copy
b = copy.deepcopy(a)
print(id(a) == id(b))
print(id(a[0]) == id(b[0]))
---------
False
True # 一般的解释器会把相同的数值类型赋予相同的地址;
1.8 可变对象和不可变对象
每个对象都保存了三个数据:
id(标识/地址) type(类型) value(值)
- 可变对象:列表、字典、集合
- 不可变对象:数值类型、字符串、元祖、bool
a[0] = 10 # 这个是在改对象,不会改变变量的指向,只是指向的变量的值变了;
a = [4,5,6] # 这个是在改变量,会改变变量指向的对象;
# 可变对象和不可变对象作为函数参数:
>>> def myfunc(l): # l实际上是得到了实参的引用,然后对对象进行了修改;
... l.append(1)
... print(l)
...
>>> l = [1, 2, 3]
>>> myfunc(l)
[1, 2, 3, 1]
>>> l
[1, 2, 3, 1]
>>> def myfunc(a): # 对于不可变对象,形参的a实际上是一个新的地址,而全局上的a值时没有改变的;
... a += 1
... print(a)
...
>>> a = 2
>>> myfunc(a)
3
>>> a
2
2. 序列
序列就是用来保存一组有序的数据,所有的数据在序列中都有唯一的索引;
-
可变序列:列表(list);
-
不可变序列:字符串(str),元祖(tuple);
-
if seq 原理:
返回的是bool(seq),会调用seq.__bool__,if seq对应的类没有__bool__,则调用__len__,if也没有__len__且非None,会默认返回true
2.1 列表(list)
- 列表就是存储对象的对象;
# 数组的创建
a = [] # 创建数组
---
# 数组的增删改查
a.append(1) # 在末尾添加元素1;
a.append([1,2,3]) # 在末尾添加一个列表,最后返回就是[1,[1,2,3]],整体插入
a.extend([1,2,3]) # 扩展a序列,最后返回时[1,1,2,3],化整为零;list的方法append是整建制的追加,而extend是个体化的扩编
a.insert(2,1) # 在索引2添加元素1;
a.pop() # 删除最后索引的元素[1,1,2]
a.pop(1) # 删除索引1的元素[1,2,3],有返回值
del a[1] # 删除索引1的元素
a.remove(3) # 删除元素3,[1,1,2],if有多个3,只删除第一个
a.clear() # 清空列表
a[1] = 4 # [1,4,2,3] 更改元素
a[1] # 4,查看索引1的元素
index = a.index(4) # 1,查看元素4的索引
---
# 数组的其他方法
size = len(a) # 获取a的长度
a.sort() # 数组升序排列,无返回值
temp = sorted(a) # 数组升序排列,有返回值,原始序列不变
a.count(3) # 获取元素3在数组中个数
a.reverse() # 反转数组
---
# 数组的切片
a[-1] # 3,数组的最后一个
a[1:3] # 左闭右开
a[1:3:-1] # 步长为负,从后开始
a[1:3] = [1,2,3,4] # 在给切片进行赋值时,只能使用序列,序列的个数可以和切片的长度不一致,意思是替代指定的切片;
a[1:3] = 'abc' # [1.'a','b','c',3],if左边的是切片,会将右边的转变为列表,然后替代左边切片里的元素,所以会改变原始列表长度
a[::-1] # 数组反转
---
for i in a: # 遍历数组的三种方法,尽量用1,2,避免出现下标
print(i)
for index, element in enumerate(a):
print("index at ",index, "is :",element)
for i in range(0, len(a)):
print("i:" , i, "element : ", a[i])
- 列表切片的注意
x = [4,1,0,3,5]
x[2] = []
print(x) # [4,1,[],3,5]
x[2:3] = []
print(X) # [4,1,3,5],这种方法会改变list的长度
x[2:3] = [2,2,2]
print(X) # [4,1,2,2,2,3,5],序列的个数可以和切片的个数不一样;
x[2:3] = 'abc'
print(x) # [4,1,'a','b','c',3,5] if左边是切片,会将又边的转化为列表,然后代替左边切片里的元素,所以会改变长度
- 需要注意的是:列表起始位置的内存地址不变,每次删除一个元素时会将后面的元素向前
data_lst = [1,2,3,4,5]
for data in data_lst:
data_lst.remove(data) #第一次删除1,然后列表变为[2,3,4,5],2在1的内存位置了,相当于向前移动了!!
# 但是for循环遍历时是位置,所以第二次删除的是3,第三次删除的是5,最后剩下了[2,4]
- 列表和字符串的长度是不一样的
a = ["1222",
"111",
"222"]
print(len(a)) # 3
b = """1
22"""
print(len(b)) # 4
2.2 元组(tuple)
- 元祖就是不可变的列表
t = () # 创建空元组;
t = 1,2,3,4 # 当元组不为空时,括号可以不写;
t = 1, # if元组不为空,至少要有一个逗号;if没有括号就是单变量!!
a,b,c,d = t # 元组的解包,这时候a=1,b=2;
# 所以if想要交换两个元素,其实可以直接
a,b = b,a # b,a就是一个元组,进行了解包;
# 在对一个元组进行解包时,变量的数量必须和元组中的元素的数量一致
# 也可以在变量前边添加一个*,这样变量将会获取元组中所有剩余的元素
a , b , *c = t # c = [3,4];
# 解包是对所有序列都可以的,不仅是元组;
# 但是注意集合本身是无序的,所以解包时容易出现问题;
2.3 字典(dict)
- 列表存储数据很好,但是查询的性能很差;而字典查询效率很高;
- 字典中每个对象都有一个名字(key),而每个对象就是value;这样一个键值对称为一项(item);
- 字典的值可以是任意对象;字典的键可以是任意的不可变对象(int、str、bool、tuple ...),但是一般我们都会使用str
- 字典的键必须是可哈希的,python中的不可变对象都是可哈希的,可变容器(list、dict)是不可哈希的,也就是不可以作为字典的key;
# 创建哈希表
hashtable = [] #通过数组创建,key即为数组下标;
hashtable[2] = "liming" #添加元素/修改元素
mapping = {} #通过字典创建;
d = {'name':a, 'age':18}
d = dict(name='孙悟空',age=18,gender='男') # 这些都可以创建
# 这样的时候if有key1不在哈希表里直接查询mapping[key1]会报错
from collections import defaultdict
mapping1 = defaultdict(int) #参数是一个函数,可以是int,str,float,list等,意思就是每个元素会默认的是当前的类型的默认值
# 比如现在就是默认的是0, list就会默认的是[]
# 另外,Counter这个函数对可迭代对象统计个数后,返回也是一个字典,并且这个字典if有元素不在,然后直接count1[a],这样不会有错。
---
# 字典的增删改查
mapping[key1] = value1 # 增加键值对
mapping.update(map2) #将map2中的键值对添加到mapping中,if有相同的key会进行替代;
mapping.pop("key1") #删除元素,有返回值
del mapping[key1] #删除键值对
mapping.clear() # 清空字典
mapping["key1"] = "liming" # 修改键值对;
mapping[key1] # 获得value1
mapping.get(key, default = None) # 第二个参数在key不存在时可以指定一个返回值;例如 mapping.get(key, []) key不存在的时候会返回一个空列表
---
# 字典的其他方法
len(mapping)
---
# 字典的遍历
for k in d.keys():
print(d[k]) #通过keys()遍历;
for v in d.values():
print(v) #通过values()遍历:
for k,v in d.items():
print(k, '=', v) #items()会返回字典中所有的项;
# 会返回一个序列,序列中是元组,[('name',a),('age',18)],这时候赋值其实是解包
# 在python3.6之后,dict是按照添加元素的顺序进行返回的;
# if想要dict是有序的,可以用OrderedDict
from collections import OrderedDict
dict1 = OrderedDict() # 则是按照元素的插入顺序;
---
# 其次注意字典的key只能是不可变对象;
2.4 集合(set)
- 集合和列表非常相似
- 不同点:
1.集合中只能存储不可变对象 ( s= {[1,2,3]},这就是错误的,因为列表是可变的)
2.集合中存储的对象是无序(不是按照元素的插入顺序保存)
3.集合中不能出现重复的元素
# 创建集合
s = set() #创建一个集合
s = {1,3,4} # 创建一个集合
---
# 集合的增删改查
s.add(value1) # 向集合中添加元素value1
s.update(s2) # 将s2中的元素添加到s中
s.pop() # 因为集合是无序的,所以随机删除一个元素
s.remove(a) # 删除集合中的a,if a 不存在会报错
s.discard(a) # 删除集合中的a, if a 不存在不会报错
s.clear() # 清空集合
---
# 集合的运算:这些操作最后返回的仍然是集合;
s1 & s2 # 集合的交集;
s1 | s2 # 集合的并集;s1
s1 - s2 # 集合的差集;
s1 ^ s2 # 集合的异或集:获取只在一个集合中出现的元素;
s1 <= s2 # s1 是否是s2的子集 s1.issubset(s2)等同
s1 < s2 # s1 是否是s2的真子集
s1.issuperset(s2)
s1.isdisjoint(s2) # s1和s2的不相交集
# 注意集合没有+
2.5 字符串
2.5.1 字符串转义
print("a'b") # a'b
print("""a'b""") # a'b
print("a\'b") # a'b
print("a'b") # a'b
print('a''b'"c") # abc
2.5.2 字符串格式化
- 字符串格式化的速度:f-string > + > % > format
- f-string格式
# 冒号后面为width指定宽度
a = 123.456
f"{a:10}" #' 123.456'
f"{a:010}" #'000123.456',最高位用0填充
f"{a:8.2f}"#' 123.46',注意8是指全部长度是8,不是小数点前是8
f"{a:4.2f}"#'123.46' width比实际小,则不用管了
- format格式
# {}里面的数字指的是在format参数元祖中的位置,0代表format的第一个参数
'{0}-{1}-{2}'.format(1,2,3) # 1-2-3,后面的1,2,3是一个元祖,可以理解为一种装包;
'{0}'.format([1,2,3]) #[1,2,3] 整个list是第一个参数
# :后面是格式,f为浮点,d为整数,前面一位数字表示字符串总长度;
# *是指从后面的元祖中读取宽度或精度
print('pi=%*.*f' %(8,3,pi) # pi= 3.142
print('%+f' %pi) # 显示正负号 +3.14159
# 假设数字是5
{:0>2d} #左填充 05
{:x<4d} #右填充 5xxx
3. 函数
3.1 函数基础
- 函数也是对象;函数可以用来保存一些可执行的代码,并且可以在需要时,对这些语句进行多次的调用
def fn(a,b):
代码块 #fn是函数对象,fn()调用函数;
# 函数在调用时,解析器不会检查实参的类型;实参可以传递任意类型;比如列表甚至是函数都行(fn(fn1));
def fn1(*a,b):
代码块 #可变参数,会将所有的实参保存到一个元组中(装包)
# 可变参数不是必须写在最后,但是注意,带*的参数后的所有参数,必须以关键字参数的形式传递
# 注意函数的参数默认值是在函数声明的时候初始化一次,之后就不会再改变了;
x = 12
def f1(a, b=x)
print(a,b)
x = 15
f1(4) # 4,12 # 在函数声明的时候b就已经被初始化成12了,之后不会再更改;
# if是可变变量作为参数入参,那只会在程序执行期间初始化一次,只要调用过程不主动指定入参,就会一直使用一开始初始化过的那个变量
class Test(object):
def process_data(self, data=[]):
data.sort()
data.append("End")
return data
test1 = Test()
print(test1.process_data()) # ['end']
test2 = Test()
print(test2.process_data()) # ['end','end'] 还是刚才的那个
----------------------------
# *形参不能接收关键字参数;
# **形参可以接收关键字参数,会将这些参数统一保存到一个字典中;**参数必须在所有参数的最后;(**kwargs的kw是key-word,也就是键值对)
# *形参是将参数打包成元祖,而**是将参数打包成字典;同时*还可以用来解包
----------------------------
t = (1,2)
fn(*t)
#传递实参时,可以在序列类型的参数前添加星号,这样他会自动将序列中的元素依次作为参数传递(解包),序列的个数必须和参数个数相同;
# 同样,也可以用**来对字典进行解包,字典的key和参数形参名一样;
----------------------------
return 后面可以跟任意的值,甚至可以是函数;
# 文档字符串
def fn(a: int,b: bool,c: str='hello') -> int:
#这些里面的类型没有任何意义,仅仅是指示说明;
···
可以写一些说明文字
···
----------------------------
if 想在函数内部修改全局变量的值,要加关键字 global;
scope = locals() # locals() 获取当前作用域的命名空间;
# 命名空间其实就是一个字典,是一个专门用来存储变量的字典;所以scope是一个字典,这个字典就是当前作用域中所有的变量;
scope['c'] = 1000 # 向字典中添加键值对就相当于在全局中创建了一个变量c;
globals_scope = globals() #globals()这个函数可以在任意位置获取全局的命名空间;
3.2 高阶函数
- 将函数作为参数,或者将函数作为返回值的函数是高阶函数;当将一个函数作为参数时,实际上是将指定的代码传递给了目标函数;
- 这样的话就可以定制一些函数,然后将函数作为一种“规则”传递给目标函数,然后目标函数根据这种“规则”对参数(原料)做出相应的处理;
1.将函数作为参数传递:
3.2.1 map()
- 参数:
1.函数
2.序列
将序列中的每个元素作用于函数,然后返回一个map对象,所以一般在外面加list,返回一个列表;
list(map(str, [1,2,3,4,5])) # ['1','2','3','4','5']
3.2.2 reduce()
reduce把一个函数作用在一个序列上,这个函数必须接受两个参数,然后把结果继续和序列的下一个元素做累计计算。
from functools import reduce
def fn(x, y):
return x*10 + y
reduce(fn, [1,3,5,7,9]) # 13579
3.2.3 filter()
filter()可以从序列中过滤出符合条件的元素,保存到一个新的序列中
- 参数:
1.函数,根据该函数来过滤序列(可迭代的结构)
2.需要过滤的序列(可迭代的结构) - 返回值:
过滤后的新序列(可迭代的结构) - filter函数是把元素作用在函数上,然后根据函数的true还是false来决定是保留还是丢弃元素,注意和map的区分;
# 筛选出序列为奇数的元素
def is_odd(n):
return n%2 == 1
lst1 = filter(is_odd, [1,2,3,4])
3.2.4 sorted()
sorted()函数对序列进行排序,第一个参数是序列,第二个参数key可以指定一个函数,意思是将序列的元素作用在这个函数上然后再进行排序;
sorted([36, 5, -12, 9, -21], key=abs) # 将每个元素取绝对值后再排序
[5, 9, -12, -21, 36]
3.2.5 lambda函数表达式
有时候一个函数用一次就再也不用了,就可以用lambda表达式;匿名函数一般都是作为参数使用的;
语法:lambda 参数列表 : 返回值
r = filter(lambda i : i > 5 , l)
3.2.6 列表推导式和生成器表达式
# 列表推导式:
lst1 = [n for n in names if len(n) > 4] #提取出names中长度大于4的
# 当然也可以filter和lambda来代替
lst2 = list(filter(lambda n: len(n) > 4, names))
def fun1():
return [lambda x: i * x for i in range(4)] # 这其实是返回一个列表,列表里的元素是lambda函数,一共有四个
[<function <listcomp>.<lambda> at 0x000001BABCA720D0>, <function <listcomp>.<lambda> at 0x000001BABCB15048>, <function <listcomp>.<lambda> at 0x000001BABCB150D0>, <function <listcomp>.<lambda> at 0x000001BABCB15158>]
lst = [lambda x: x*i for i in range(4)]
res = [m(2) for m in lst]
print res #[6,6,6,6]
# 原因就在于上面的列表推导式其实是相当于一个闭包,和下面的等同:
def func():
fun_list = []
for i in range(4):
def foo(x):
return x*i
fun_list.append(foo)
return fun_list
for m in func():
print m(2)
# func是一个四个函数的列表,但是当运行m(2)时,跳转到foo函数里,这时候没有i就会去函数外部寻找,但是这时候外面的for已经循环完毕了,所以i直接就是3
# 注意函数没有调用,就只是简单的定义,并不会把i值传递给函数里面,函数调用和函数定义是有区别的;
def func():
fun_list = []
for i in range(4):
def foo(x, i=i): #当有了这个默认值后,在定义的时候就已经把i的值传给了函数,也就是说默认值参数只在函数初始化的时候初始化一次,之后不变;
return x*i
fun_list.append(foo)
return fun_list
for m in func():
print m(2) #[0,2,4,6]
# 生成器表达式:
a = (n for n in names if len(n) > 4) # 将中括号换成圆括号;但是a会是一个生成器对象,并不是列表这种直接用的东西;
<generator object <genexpr> at 0x0000020CE2EC4C48
# 所以当想要生成器开始迭代的时候,可以用for
for t in a:
print(t)
2.将函数作为返回值
3.3 闭包
- 将函数作为返回值返回,这就是一种闭包,通过闭包可以创建一些只有当前函数能访问的变量,可以将一些私有的数据藏到闭包里;
闭包顾名思义就是一种封闭的包裹,当调用了一个函数A时,这个函数A会返回一个函数B给我们,这个返回的函数B就是闭包,在调用函数A的时候传递的参数叫做自由变量;
形成闭包的条件:
1.函数嵌套;
2.将内部函数作为返回值返回;
3.内部函数必须要使用到外部函数的变量;
def fn(name):
a = 10
# 函数内部再定义一个函数
def inner():
print('我是fn2', a, name)
# 将内部函数 inner作为返回值返回
return inner
r = fn()
# inner就是一个闭包,name和a就是自由变量,当fn这个函数的声明周期结束后,name和a这两个变量依然是存在的,因为它们被闭包引用了,不会被回收;(被引用的自由变量会和闭包一起存在,其实已经离开了创造它的环境)
# r是一个函数,是调用fn()后返回的函数,也就是inner
# 这个函数是在fn()内部定义,并不是全局函数
# 所以这个函数总是能访问到fn()函数内的变量
# 变量是里面能看到外面的,但是外面看不到里面的;通过闭包的方式就能够使r接触到fn内部的变量,也就是外面能看到里面的了;
- 闭包的最大特点就是将父函数(即外部函数)的变量和内部函数(闭包)绑定,并且返回绑定变量后的函数(即闭包),这样即便生成闭包的环境(父函数)已经释放,闭包仍然存在;
参考闭包
3.4 装饰器
3.4.1 装饰器
在写程序的时候,if我们想扩展一个函数,但是我们要尽量不去动原始的函数,而是要遵从开闭原则,即开放对程序的扩展,而关闭对程序的修改;
装饰器其实就是一个函数,这个函数什么功能呢?它接收一个旧函数作为参数,然后在装饰器里对它进行装饰包装,然后以一个新函数作为返回;这样就可以在不修改原始函数的情况下对函数进行扩展;
- 装饰器就是闭包的一种,只不过传递的变量是函数;
例如:
在上图中,b为被装饰的函数,a为装饰器@a对应的函数,装饰后返回一个新的函数b
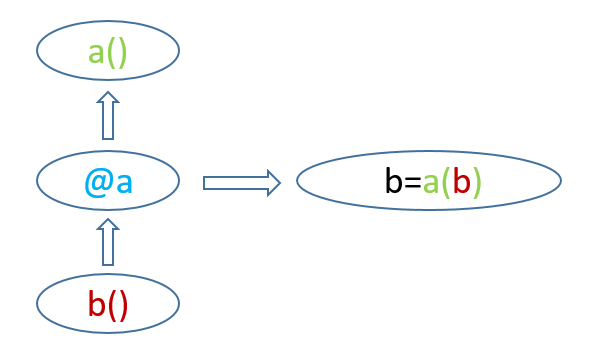
流程:
1.python解释器发现了装饰器@a,就去调用对应的函数a
2.函数a需要有一个参数,接着传入@a下面修饰的函数作为参数,也就是b
3.a()函数执行,返回一个新的函数b = a(b)
可以直接在旧函数上声明@装饰器函数
可以给函数多个装饰器,装饰的时候从内向外;
3.4.2 多个装饰器
def AA(func):
print('AA 1')
def func_a(*args, **kwargs):
print('AA 2')
return func(*args, **kwargs)
return func_a
def BB(func):
print('BB 1')
def func_b(*args, **kwargs):
print('BB 2')
return func(*args, **kwargs)
return func_b
@BB
@AA
def f(x):
print('F')
return x * 10
print(f(1))
-----
AA 1
BB 1
BB 2
AA 2
F
10
- 注意函数和函数调用是不一样的,f是一个函数,f()是函数调用;
- 装饰器刚装饰的时候就会立即执行,从内向外,所以先执行AA,也即f = AA(f),返回了func_a,此时的f已经是func_a,然后再装饰,f = BB(f) = BB(func_a),f变为了func_b
- 然后函数执行,f(1)也就是func_b(1),返回闭包的参数,也就是func_a,再执行func_a,返回闭包的参数f,最后再执行f;
3.4.3 @property和@setter
- @property是一个装饰器,其对应的函数为property,if我们想要隐藏类的属性,那可以在__init__的时候将属性设置为_下划线,然后提供get和set方法,当有了这两个方法后,我们可以通过property函数直接将其变为一个属性;
例如 score = property(get_score, set_score); - 当然也可以用更简单的方法就是直接使用装饰器@property ; @x.setter
- 使用@property装饰器来创建只读属性,@property装饰器会将方法转换为相同名称的只读属性,可以与所定义的属性配合使用,这样可以防止属性被修改。
class Student():
def __init__(self):
self._score = None
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
if __name__ == "__main__":
s = Student()
s.score = 66
print(s.score)
- 像上面一样,可以直接像利用属性一样来操作了,我们为两个同名函数(score)配置了装饰器,当把函数作为变量读取时会调用property;当把函数作为变量赋值时会调用setter对应的函数,
- 注意前提是@.setter装饰器必须在@property装饰器的后面,且两个被修饰的函数的名称必须保持一致, 即为函数名称。
3.5 nolocal与global
在python的函数里,可以直接引用外部变量,但是不能操作外部变量,这样会报错;
- 变量在寻找时,是按照局部作用域、闭包、全局作用域、内嵌这样的顺序去查找的;
- 函数内可以读取到在函数外的变量(因为在局部搜不到后会去全局进行搜索),但是当想要修改时(例如x = x+1),就会报错,因为函数会把这个变量当做局部变量去使用,但是函数内又没有定义这个局部变量,就会报错(报错的内容就是说在定义前用了变量),那该怎么做呢,就是用global关键字,在函数内部声明这个变量是全局的;
- if想要在函数内部修改全局变量,可以使用global关键字,禁止在函数内使用global直接创建全局变量,当只需要读全局变量时,不需要global声明; 注意在函数外使用global关键字是无效的
- if在函数内部出现了全局变量名字一样的变量并且没有用global声明,其实就相当于直接在函数内部直接定义了一个新变量;
- 对于python来说,全局变量的使用是比较谨慎的,也不被提倡,所以有了一个新的关键字,nonlocal;nonlocal用在封装函数中,也就是闭包里,在外部函数中先声明变量,然后在内部函数中声明nonlocal,然后在闭包和外部函数中的变量就是同一个变量了;
count = 1
def a():
count = 'a函数里面' #如果不事先声明,那么函数b中的nonlocal就会报错(因为nonlocal不会去全局中搜索,所以不会找到最外面的count);if在这里直接声明nonlocal count 也是会报错;
def b():
nonlocal count
print(count)
count = 2
b()
print(count)
if __name__ == '__main__':
a()
print(count)
#最后的执行结果是:
a函数里面
2
1
# 第一行里的count是全局变量,而a函数里面的count是局部变量,是两个变量,在b里声明nonlocal,证明b和a中的是同一个变量
4. 类和对象
4.1 类基础
- 类用大驼峰来命名:MyClass; 类也是对象,类就是一个用来创建对象的对象,一切皆对象!
- 如果是函数调用,则调用时传几个参数,就会有几个实参;但是如果是方法调用,默认传递一个参数,这个实参是解析器自动传的,所以方法中至少要定义一个形参(self),这个默认传递的实参其实就是调用方法的对象本身!if是p1调的,那第一个参数就是p1,if是p2调的,那第一个参数就是p2;所以我们把这个参数命名为self,这个self就是指的是谁调用这个方法了,这个谁就是self;self就是当前对象
- 当我们调用一个对象的属性时,解析器会先在当前对象中寻找是否含有该属性,
如果有,则直接返回当前的对象的属性值,
如果没有,则去当前对象的类对象中去寻找,如果有则返回类对象的属性值,如果类对象中依然没有,则报错! - 类对象和实例对象中都可以保存属性(方法)
- 如果这个属性(方法)是所有的实例共享的,则应该将其保存到类对象中
- 如果这个属性 (方法)是某个实例独有,则应该保存到实例对象中
- python中一切都是对象,它们要么是类的实例,要么是元类的实例,元类就是类的类,可以通过type()来创建元类,在定义类时,可以通过meteclass参数来指定此类的元类;
p1 = Person()的运行流程
1.创建一个变量p1
2.在内存中创建一个新变量,这个变量的类型是Person
3.init(self)方法执行
4.将对象的id(地址)赋值给变量
- 继承,在类的括号里写父类,if没写,就是继承自object.
issubclass(a,b) 检查a是否是b的子类
isinstance(a,A) 检查a是否是A的实例
父类中所有的方法和属性都可以被继承
# 父类中的所有方法都会被子类继承,包括特殊方法,也可以重写特殊方法
class Dog(Animal):
def __init__(self,name,age):
# 希望可以直接调用父类的__init__来初始化父类中定义的属性
# super() 可以用来获取当前类的父类,
# 并且通过super()返回对象调用父类方法时,不需要传递self
super().__init__(name)
self._age = age
- if子类没有定义自己的初始化方法,父类的初始化方法会被默认调用;if子类有自己的初始化方法,没有显式的调用父类的初始化方法,则父类的属性不会被初始化;
- python中可以多重继承:
class C(A,B):
pass
# C继承自两个父类,AB,ifA,B中有同名的方法,会先调用A的,if C(B,A)那就会先调用B的,
- 多态:在函数的参数中,if要传入一个对象,其实不关注对象是什么类型的,只关注这个对象是否有某些属性和方法,只要有某些属性和方法,那就可以传递进去,这样保证了程序的灵活性;
4.2 类方法和类属性
- 类属性可以通过A.属性和a.属性访问,实例属性只能通过a.属性访问,类.属性无法访问;在类中以self作为第一个参数的方法是实例方法,实例方法可以通过类和实例调用,注意实例方也能通过类调用;通过实例调用时,会自动将当前对象传递给self,但是通过类调用时,不会自动传,所以,A.fangfa(a) = a.fangfa()
4.2.1 类属性
- 类变量是类的变量,当这个类有实例化的对象时,会把类变量拷贝一份给对象,对象拿到的只是类变量的副本,所以通过对象.属性来修改类变量的值并不会影响类自身和其他对象;
class TestClass(object):
#类变量
val1 = 100
def __init__(self):
#成员变量
self.val2 = 200
-----
a.val1 = 200
b.val1 # 100
TestClass.val1 = 300
b.val1 # 300 没有经过修改,跟类变量保持一致
a.val1 # 200 经过了修改,跟类变量没有关系了
4.2.2 类方法classmethod和静态方法staticmethod
- 在一个类里,出现最多的就是三种方法:被classmethod装饰的类方法;被staticmethod装饰的静态方法;用的最多的不带装饰器的实例方法;
class A(object):
def m1(self, n):
print("self:", self)
@classmethod
def m2(cls, n):
print("cls:", cls)
@staticmethod
def m3(n):
pass
# A.m1是一个还没有传实例的实例方法,它必须显式的传入一个实例对象进去,而a.m1会自动把当前实例对象传递给self。
# A.m1(a, 1) 其实和a.m1(1)是等价的
# m2是类方法,A.m2会自动将当前类对象A传递给cls;a.m2也可以通过实例对象a找到所属的类A,然后将当前类绑定到cls上
# A.m2(1) 和 a.m2(1)是等价的;
# m3是一个静态方法,这其实和函数是没有区别的,它与类和实例都没有进行绑定,只不过是在类里面罢了;所以通过类和实例都是可以引用的
# A.m3(1) 和 a.m3(1) 都能够引用;
# 静态方法其实就相当于定义了一个局部函数来专门为这个类服务;
子类会继承父类的类方法,但是不会继承父类的静态方法,静态方法的作用域仅在当前类中;
a = A()
a.m1(1) # self: <__main__.A object at 0x000001E596E41A90>
A.m2(1) # cls: <class '__main__.A'>
A.m3(1)
当程序开始运行时,一共发生了下面的几件事情:
1.开始创建一个class A对象,这个类也是一个对象(类对象),同时初始化类里的属性和方法,注意此时并没有实例!这时候其实是变量A指向了真正的类对象;
2.3.执行a=A(),这时候系统自动调用类里的构造器,构造出来了实例对象,变量a指向了实例对象;
4.调用a.m1(1):m1是实例方法,系统会自动把实例对象传递给self参数进行绑定,所以self和a都指向了实例对象;
5.调用A.m2(1):m2是类方法,系统会把类对象传递给cls参数,所以cls和A都指向了类对象;
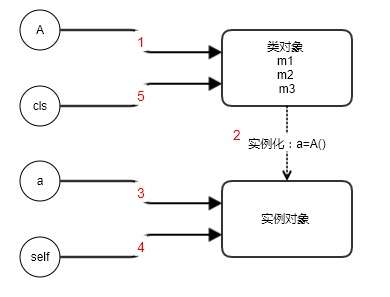
左边都是变量名,右边才是真正的对象;
# 类方法
# 在类内部使用 @classmethod 来修饰的方法属于类方法
# 当被classmethod装饰时,函数相当于是被借调到子类中去作为一个独立方法,因此会影响到类变量的值;
# 而被staticmethod装饰时,函数作用域仅在当前类,子类中的变量不受影响;
# 类方法的第一个参数是cls,也会被自动传递,cls就是当前的类对象
# 类方法和实例方法的区别,实例方法的第一个参数是self,而类方法的第一个参数是cls
# 类方法可以通过类去调用,也可以通过实例调用,没有区别
@classmethod
def test_2(cls):
print('这是test_2方法,他是一个类方法~~~ ',cls)
print(cls.count)
# 静态方法
# 在类中使用 @staticmethod 来修饰的方法属于静态方法
# 静态方法不需要指定任何的默认参数,静态方法可以通过类和实例去调用
# 静态方法,基本上是一个和当前类无关的方法,它只是一个保存到当前类中的函数
# if不用staticmethod,可以通过类方法来调用,但是实例方法会报错;
# 静态方法一般都是一些工具方法,和当前类无关
---
# 当被staticmethod修饰时,函数作用域仅在当前类中,子类中的变量不会受影响;
class Spam:
num_instances = 0
@staticmethod
def count(cls):
cls.num_instances += 1
def __init__(self):
self.count()
class Sub(Spam):
num_instances = 0
class Other(Spam):
num_instances = 0
x = Spam()
y1, y2 = Sub(), Sub() # 子类没有,所以会调用父类的__init__初始化方法,但是cls指的是spam类;
z1, z2, z3 = Other(), Other(), Other()
x.num_instances, y1.num_instances, z1.num_instances # (6, 0, 0)
Spam.num_instances, Sub.num_instances, Other.num_instances # (6, 0, 0)
---
# 当被classmethod修饰时,函数相当于被借调到一个子类中作为一个独立方法
class Spam:
num_instances = 0
@classmethod
def count(cls): # 相当于子类中也有了count方法,自然调用的也就是子类中的num
cls.num_instances += 1
def __init__(self):
self.count() # 将self.__class__传给count方法
class Sub(Spam):
num_instances = 0
class Other(Spam):
num_instances = 0
x = Spam()
y1, y2 = Sub(), Sub()
z1, z2, z3 = Other(), Other(), Other()
x.num_instances, y1.num_instances, z1.num_instances # (1, 2, 3)
Spam.num_instances, Sub.num_instances, Other.num_instances # (1, 2, 3)
--
class Spam(object):
num_instances = 0
@staticmethod
def count():
Spam.num_instances += 1
def __init__(self):
self.count()
class Sub(Spam):
pass
# num_instances = 0
class Other(Spam):
pass
# num_instances = 0
x = Spam()
y1, y2 = Sub(), Sub()
z1, z2, z3 = Other(), Other(), Other() # 继承父类中的变量
print(x.num_instances, y1.num_instances, z1.num_instances) # 6,6 ,6
print(Spam.num_instances, Sub.num_instances, Other.num_instances) 6 6 6
---
class Spam(object):
num_instances = 0
@classmethod
def count():
Spam.num_instances += 1
def __init__(self):
self.count()
class Sub(Spam):
pass
# num_instances = 0
class Other(Spam):
pass
# num_instances = 0
x = Spam()
y1, y2 = Sub(), Sub()
z1, z2, z3 = Other(), Other(), Other() # 继承父类中的变量
print(x.num_instances, y1.num_instances, z1.num_instances) # 1,3,4
print(Spam.num_instances, Sub.num_instances, Other.num_instances) 1,3,4
------
class Foo:
count = 0
def __init__(self):
self.count = 0
def incr_one(self):
self.count += 1
@staticmethod
def incr_two():
Foo.count += 1
@classmethod
def incr_three(cls):
cls.count += 1
class Bar(Foo):
pass
foo = Foo()
bar = Bar()
foo.incr_one() # 注意实例变量和类变量不是一回事,现在foo.count = 1
bar.incr_one() #bar.count = 1
foo.incr_two() # Foo.count = 1,注意Bar自己没有count,所以是继承Foo的count,而且Bar还没有修改,所以Bar.count = 1!!!
bar.incr_three() # Bar.count = 2,这时候Bar已经更改了,所以和Foo的count没有关系了
Foo.incr_two() # Foo.count = 2
Bar.incr_three() # Bar.count = 3
Foo.incr_three() # Foo.count = 3
4.2.3 new__和__init
new是创建一个实例,而init是初始化一个实例
__new__方法就是类方法,所以第一个参数是cls。是类在实例化的时候要调用的,__new__方法返回什么,实例化的对象就是什么;
__init__方法是在__new__方法基础上完成初始化动作,不需要返回值,if__new__没有正确的返回当前cls类的实例,那__init__就不会被调用;
class A(object)
def __new__(cls):
'重写__new__方法'
return 'abc'
a = A()
print(a) #abc,实例化对象取决于__new__方法;
---
class B():
def __new__(cls):
print ("__new__方法被执行")
def __init__(self):
print ("__init__方法被执行")
b=B() # __new__方法被执行;因为没有正确的返回值,所以init方法不会被调用;
4.3 特殊方法
- 特殊方法也叫魔法方法,一般不需要手动调用,在一些特殊的时候会自动执行,以双下划线开始,
__init__和__new__ :在初始化和对象创建的时候调用;
__del__ 在结束时调用,进行垃圾回收;
__name__ 可以通过__name__属性获取到模块的名字
- 对于所有的类都有以下的属性,用dir()可以查看
__name__:类的名字(字符串)
__doc__:类的文档字符串
__bases__:类的所有父类组成的元祖
__dict__:类的属性组成的字典
__module__:类所属的模块
__class__:类对象的类型
4.3.1 all
在python中使用from 模块 import * 来进行导入时,能导入一个模块中不以下划线(_或者双下划线)开头的成员,if是以下划线开头,那就不会导入
除此之外,可以使用双下划线all来声明哪些成员可以被导入;这个变量的值时一个列表,元素是str,存放的是当前模块的一些成员,当其他文件以from module import * 进行导入(注意只在这种导入时起作用)时,只能导入双下划线all里的成员,不在这里面的是没有办法导入的;
__all__ = ['say','laugh'] # say和laugh都是方法
4.3.2 dict
__dict__是一个字典,用来返回对象的属性;
a.__dict__ # 返回一个字典,key是实例属性,value是对应的值,并不返回所有的属性,只返回和实例关联的实例属性;
A.__dict__ # 返回一个字典,返回所有实例共享的类属性和方法,但并不包括父类的属性;
dir(A) # 会返回一个对象的所有属性(包括从父类中继承的; 所以__dict__是dir的子集;
许多内嵌类型比如list并不拥有__dict__属性,所以要用dir
4.3.3 del
当内存不需要的时候调用这个删除方法,这是属于类的,也就是当这个类没用的时候,python解释器会自动调用;
4.3.4 call
__call__的作用是能够使一个类实例像函数一样去调用,if想要达到这个目的,我们需要在类中实现__call__方法;
例如x是X的一个实例,那么调用x.__call__(1, 2)就等同于x(1,2),这个类实例就像函数一样;
4.3.5 eq
当比较两个对象的时候(==),实际上是调用的对象里的双下划线eq方法,所以if想要自定义一些相等的时候,可以重写双下划线eq方法;
- 子类和父类进行比较时,都是会去调用子类的__eq__
- 当两个对象进行比较时,是去调用__eq__方法,而__eq__方法是按照对象的id进行比较的;
4.3.6 slots
python是动态语言,在创建了一个类的实例后,可以给该实例绑定任何属性和方法;如下面的例子:
class Student(object):
pass
# 定义了一个类
s = Student() # 类的实例
s.name = 'liming' # 给当前实例动态的绑定一个name属性;
def set_age(self, age):
self.age = age
from types import MethodType
s.set_age = Method(set_age, s) # 给实例绑定一个方法;
# 注意对当前实例绑定的属性和方法只对当前实例起作用;
# if想要对所有实例都起作用;可以给类绑定;
Student.set_age = set_age
- slots是用来限制实例的属性的,只允许添加slots里面的属性;
class Student(object):
__slots__ = ('name', 'age') # 用tuple定义允许绑定的属性名称
s = Students
s.name = 'limimg'
s.age = 24
s.score = 99 # AttributeError: 'Student' object has no attribute 'score'
4.4 可迭代对象和迭代器
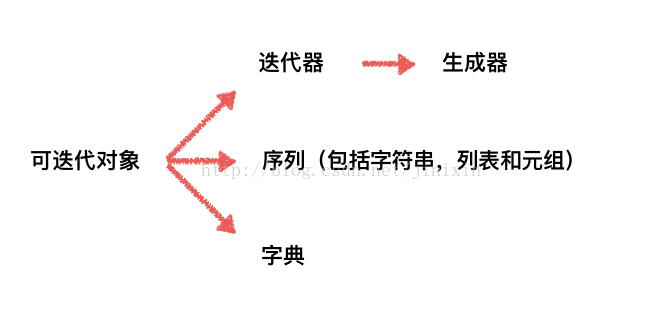
- 可迭代对象包含迭代器;
- 可迭代对象类必须实现__iter__方法,迭代器类必须实现__iter__和next方法;
- __iter__方法返回的是迭代器类的实例; next方法返回迭代的每一步(当前迭代值);
参考:迭代器
class MyList(object): # 定义可迭代对象类
def __init__(self, num):
self.data = num # 上边界
def __iter__(self):
return MyListIterator(self.data) # 返回该可迭代对象的迭代器类的实例
class MyListIterator(object): # 定义迭代器类,其是MyList可迭代对象的迭代器类
def __init__(self, data):
self.data = data # 上边界
self.now = 0 # 当前迭代值,初始为0
def __iter__(self):
return self # 返回该对象的迭代器类的实例;因为自己就是迭代器,所以返回self
def next(self): # 迭代器类必须实现的方法
while self.now < self.data:
self.now += 1
return self.now - 1 # 返回当前迭代值
raise StopIteration # 超出上边界,抛出异常,必须有
# 在python3.7以上,生成器退出时的StopIteration会被解释器转换成RuntimeError,所以在这之后要用return代替raise StopIteration
my_list = MyList(5) # 得到一个可迭代对象
print type(my_list) # 返回该对象的类型
my_list_iter = iter(my_list) # 得到该对象的迭代器实例,
for i in my_list: # 迭代
print i #0,1,2,3,4
# iter有两种用法,一是接收函数iter(函数,参数),会不断的执行函数,直到返回值与参数相同或者stopiteration
# 二是iter与__iter__联系紧密,iter()是直接调用该对象的__iter__,所以其功能常用作创建迭代器;
例如:lst = [1,2,3,4] # lst就是一个可迭代对象
l1 = iter(lst) # 创建迭代器对象
print(next(l1) # 1
print(next(l2) # 2
print type(my_list_iter)
# 除了使用next以外,还可以使用for循环进行遍历
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
for x in it:
print (x, end=" ") # 1 2 3 4
# 判断一个对象是否是可迭代对象;
dir会检查对象含有什么方法,列出然后看是否有__iter__即可
print('__iter__' in dir([1,2,3]))
- 生成器(yield)是一种特殊的迭代器,其自动实现了__iter__和next方法,不需要手动实现;生成器往往是一种无限的,例如斐波那契数列
- 只要函数使用了yield那就不再是一个函数,而是一个生成器,这个函数会返回一个迭代器对象,只能用于迭代使用;
- 每次遇到yield时函数会暂停并保存当前所有的运行信息,返回yield的值;
def foo():
print("starting...")
while True:
res = yield 4
print("res:",res)
g = foo()
print(next(g))
print("*"*20)
print(next(g))
# 输出:
starting...
4
********************
res: None
4
# 1.程序运行开始后,因为有yield,所以foo函数并不会真正执行,而是得到一个生成器g;
# 2.直到调用next方法后,生成器开始迭代,先执行print,然后进入while循环
# 3.程序遇到yield后,直接将yiled想象成return后,return一个4,程序暂停,这时候并没有执行赋值操作,也就是res并不是4,然后next执行完毕;
# 4.然后遇到下一个next后,从刚才暂停的地方开始,但是要注意的是:res赋值右边是没有值的,因为刚才那个已经return4了,所以这时候res的值是None,然后在下一次循环后再次yield 4,然后程序再次停止;
4.5 元类(metaclass)
- 在Python里,万物皆对象,类A也是一个对象;
- 在python中,type除了可以用来查看一个对象的类型外,还可以用来动态的创建类;
type(类名, 父类的元祖(可以为空), 包含属性和方法的字典(名称和值))
# 假设这是之前的类:
class Foo(object):
foo = True
def greet(self):
print 'hello world'
print self.foo
# 当用type来创建这个类时:
def greet(self):
print 'hello world'
print self.foo
Foo = type('Foo', (object, ), {'foo': True, 'greet': greet})
# 这和上面是等价的:
f = Foo()
f.foo # True
f.greet() # hello world True
- 元类就是用来创建类的东西,可以这么理解:实例对象是类的实例,而类是元类的实例;
- 元类主要是为了控制类的创建行为;
- 元类主要做了三件事:拦截类的创建;修改类的定义;返回修改后的类;
class Foo(object):
name = 'foo'
def bar(self):
print 'bar'
# if想给这个类的每个方法和属性前面加上my_,然后再加上一个echo方法,就可以使用到元类;
# 1.定义一个元类,从type继承,因为元类是用来创建类的,而type也是;
class PrefixMetaclass(type):
def __new__(cls, name, bases, attrs):
'''cls:当前准备创建的类;
name:类的名字;在这里就是Foo
bases:类的父类集合;这里是object
attrs:类的属性和方法,是一个字典;'''
# 给所有属性和方法前面加上前缀 my_
_attrs = (('my_' + name, value) for name, value in attrs.items())
_attrs = dict((name, value) for name, value in _attrs) # 转化为字典
_attrs['echo'] = lambda self, phrase: phrase # 增加了一个 echo 方法
return type.__new__(cls, name, bases, _attrs) # 返回创建后的类
# 2.指示Foo使用PrefixMetaclass来定制类
class Foo(metaclass=PrefixMetaclass):
name = 'foo'
def bar(self):
print 'bar'
------
f = Foo()
f.name # 会报错,因为没有那么属性了
f.my_name # bar
- 元类就是类的类,常用在类工厂中;
- 在定义类的时候,可以通过metaclass参数来指定当前类的元类,python语句在执行时,会先查找类本身的metaclass属性,if没找到,会继续在父类中查找,if还没找到,在模块中查找,最后再用内置的type来创建类;
5. 异常
try:
代码块(可能出现错误的语句)
except 异常类型 as 异常名:
代码块(出现错误以后的处理方式)
else:
代码块(没出错时要执行的语句))
finally:
代码块(该代码块总会执行)
-----
def divide(x, y):
try:
return x/y
except Exception:
return 0
finally:
return -1
print(divide(1, 0)) # -1 只会返回-1,原因在于一个函数只能有一个return,会执行到return 0,但是finally总会执行,最后就返回-1
# 所以需要注意finally不要有return、break等操作,可能会导致异常的操作不能够正常执行返回;
-
异常也是一个对象,比如 : ZeroDivisionError类的对象专门用来表示除0的异常
NameError类的对象专门用来处理变量错误的异常 -
BaseException是所有异常类的基类,包括键盘中断、进程退出等异常,而Exception是所有不需要进程退出的异常基类,其关系如下:
- BaseException |- KeyboardInterrupt |- SystemExit |- GeneratorExit |- Exception |- (all other current built-in exceptions)自定义异常类必须继承自Exception,不需要去关注键盘中断等这些异常;
-
不要直接使用except:这种语句,这种会捕获所有的异常,不方便之后的工作,except后要跟明确的异常类,并且按照从小到大的原则,BaseException和Exception放在最后一个;
-
可以使用 raise 语句来抛出异常,
raise语句后需要跟一个异常类 或 异常的实例,if后面啥也不跟,那会抛出 RuntimeError,丢失了原始的异常信息; -
OSerror 是操作系统错误,包括I/O操作失败,例如‘文件未找到’或者‘磁盘已满’等,不包括非法参数或其他偶然性错误;
6. 文件
| 模式 | 可做操作 | if文件不存在 | 是否覆盖 |
|---|---|---|---|
| r | 只读 | 报错 | 是 |
| r+ | 可读可写 | 报错 | 是 |
| w | 只能写 | 创建 | 是 |
| w+ | 可读可写 | 创建 | 是 |
| a | 只能写 | 创建 | 否,追加写 |
| w+ | 可读可写 | 创建 | 否,追加写 |
- 打开文件,opne(file_name)会返回一个对象,if当前文件和目标文件在同一级目录下,则直接写名字就可以,其他的时候就必须用路径了。可以使用..来向上返回一级目录
. 是指当前目录; .. 是指当前目录的上一级目录
- read()用来读,会将内容保存为一个字符串返回;
- 关闭文件;对象.close(),这时候其实经常是忘记的,所以有了with..as语句
- rb方式打开的文档,读的是byte不是str,if文件内容是中文,r可以打开,rb会报错;
with open(file_name) as file_obj: #这其实就是和file_obj = open(file_name)一样,当出去这个with后,会自动关闭;
#打开file_name并返回一个变量file_obj
file_obj.read()
with open(file_name , 'x' , encoding='utf-8') as file_obj:
# 使用open()打开文件时必须要指定打开文件所要做的操作(读、写、追加)
# 如果不指定操作类型,则默认是 读取文件 , 而读取文件时是不能向文件中写入的
# r 表示只读的
# w 表示是可写的,使用w来写入文件时,如果文件不存在会创建文件,如果文件存在则会截断文件
# 截断文件指删除原来文件中的所有内容
# a 表示追加内容,如果文件不存在会创建文件,如果文件存在则会向文件中追加内容
# x 用来新建文件,如果文件不存在则创建,存在则报错
# + 为操作符增加功能
# r+ 即可读又可写,文件不存在会报错
# seek() 可以修改当前读取的位置
seek()需要两个参数
第一个 是要切换到的位置
第二个 计算位置方式
可选值:
0 从头计算,默认值
1 从当前位置计算
2 从最后位置开始计算
# tell() 方法用来查看当前读取的位置
7. 模块和包
- 模块是一段代码,表现为将写的代码保存为文件,这个文件就是一个模块;包是一个有层次的文件目录结构,由多个模块或者子包组成,就是一个包含双下划线__init.py__文件的目录,这个目录下有这个文件和其他模块;库是能够完成一定功能的代码的集合;
- 当导入模块的时候,python解释器会先去搜索具有该名称的内置模块,if没有找到,会在sys.path给出的目录列表中搜索名为导入名字.py的文件;sys.path会从PYTHONPATH初始化;
- 整个文件的顺序:文档字符串 -》 __future_模块的导入 -》 双下划线开头结尾的全局变量 -》import导入 -》全局变量
"""This is a module
Functions of this module
"""
from __future__ import print_function
__all__ = ['hello', 'world']
__version__ = 'V1.0'
import os
import sys
from time import sleep
sample_global_variable = 0
M_SAMPLE_GLOBAL_CONSTANT = 0
- 每行只能导入一个模块 import os,sys 不对; if从一个模块导入多个对象可以:from sys import stdin, stdout
- 一个py文件就是一个模块,模块也是一个对象!在每一个模块内部都有一个__name_属性,通过这个属性可以获取到模块的名字_name_属性值为 _main_的模块是主模块,一个程序中只会有一个主模块,主模块就是我们直接通过 python 执行的模块
- 一个文件夹就是一个包,一个包里可以有多个模块,包中必须含有一个__init__.py文件,一个包里会有__pycache_文件夹,这是模块的缓存文件, py代码在执行前,需要被解析器先转换为机器码,然后再执行,所以我们在使用模块(包)时,也需要将模块的代码先转换为机器码然后再交由计算机执行
而为了提高程序运行的性能,python会在编译过一次以后,将代码保存到一个缓存文件中,这样在下次加载这个模块(包)时,就可以不再重新编译而是直接加载缓存中编译好的代码即可;python中的package必须包含一个_init.py__的文件,可以为空,只要它存在就说明该目录应该被当做为一个package处理!!
- 在python中使用from 模块 import * 来进行导入时,能导入一个模块中不以下划线开头的成员,if是以下划线开头,那就不会导入
除此之外,可以使用__all_来声明哪些成员可以被导入;这个变量的值是一个列表,元素是str,存放的是当前模块的一些成员,当其他文件以from module import * 进行导入(**注意只在这种导入时起作用**)时,只能导入__all__里的成员,不在这里面的是没有办法导入的;
__all__ = ['say','laugh'] # say和laugh都是方法
- 导入的顺序按照标准库-》第三方标准库-》自定义库的顺序导入,每个类别之间有空行;同时对于系统库和第三方库使用绝对路径导入,对于项目库内的代码,可以使用相对路径
from sys_lib import module_a # 系统库用绝对路径
from third_lib import module_b # 第三方库用绝对路径
from .module_c.module_cc import classA # 本项目库可以使用相对路径
8. 日志
- 一般的日志等级从小到大,debug、info、notice、warning、error、critical。显示的信息越来越少;
| 日志等级 | 描述 |
|---|---|
| debug | 最详细的日志信息,典型应用场景是 问题诊断 |
| info | 信息详细程度仅次于DEBUG,通常只记录关键节点信息,用于确认一切都是按照我们预期的那样进行工作 |
| warning | 当某些不期望的事情发生时记录的信息(如,磁盘可用空间较低),但是此时应用程序还是正常运行的 |
| error | 由于一个更严重的问题导致某些功能不能正常运行时记录的信息 |
| CRITICAL |
logging.log(logging.ERROR, "this is a error log") # 会直接打印在输出台,python里默认的是>=warning的会打印;
# ERROR:root:This is a error log.
LOG_FORMAT = "%(asctime)s - %(levelname)s - %(message)s"
logging.basicConfig(filename='my.log', level=logging.DEBUG, format=LOG_FORMAT) # 使用logging.basicConfig进行配置,这个配置只在第一次配置的时候有用
# 在代码的相同目录下会生成my.log文件,里面的内容是:2017-05-08 14:29:53,784 - ERROR - This is a error log.这样的格式
- 日志采用 ‘%s, %s’,(str1,str2)这样的格式,采用logging模块来记录来而不是用print,不要直接使用外部数据来记录日志;
9. 调试
9.1 pdb
pdb是python自带的调试工具,有两种用法:
- 非侵入方法
# 无需修改源代码,在命令行下直接运行就能调试
python -m pdb filename.py
- 侵入方法
# 需要在被调试的代码中添加一行然后再正常运行;
import pdb
pdb.set_trace()
# 当在命令行下看到这个提示符时,说明已经正确打开了pdb
(Pdb)
# 然后就可以开始输入pdb命令了
| 命令 | 解释 |
|---|---|
| break 或 b | 设置断点 |
| continue 或 c | 继续执行程序 |
| list 或 l | 查看当前行的代码段 |
| step 或 s | 进入函数 |
| return 或 r | 执行代码直到从当前函数返回 |
| exit 或 q | 中止并退出 |
| next 或 n | 执行下一行 |
| pp | 打印变量的值 |
- pdb一行可以设置多个断点,断点可以设置在import位置,不可以设置在空行;
- 进入pdb模式后,代码执行位置会停留在第一行有效非注释代码的位置;
- 有一些bug很难用pdb进行debug,此时可以用gdb,比如段错误(无法捕捉的python异常)、卡住的进程(无法用pdb进行跟踪)、控制之外的后台处理守护进程
9.2 代码检查
- 常用的代码检查工具:timeit、profile、cProfile、line_profiler、memory_profiler
- cprofile比profile快
- pylint:是一个python代码分析工具,能够查找不符合代码风格标准,默认的代码风格是PEP 8;
- too many instance attributes规定类属性不得多于7个
- too many arguments告警可以通过dict class等方式消除
- deprecated-lambda告警的消除做法是用列表推导代替map和filter
- 遍历设计范围和索引时尽量使用enumerate和range
10 并行
- ython并不能实现真正意义上的多线程,造成这种现象的原因是GIL(全局解释器锁),但是注意它并不是python的问题,而是目前使用最为广泛的使用c语言实现的python解释器CPython上。multithreading因为上述原因,同时只能由一个线程运行,if要利用多核心,需要用multiprocessing;
- 在python中一些看起来很简单的命令并不能保证原子性,例如下面的非线程安全的操作:
i = i + 1
L.append(L[-1])
L[i] = L[j]
可以使用threading.Lock()来加锁;
- python的多线程适用于阻塞式IO的场景,不适用于并行计算的场景,在阻塞式IO场景下,线程在执行IO操作时并不需要占用CPU时间,此时阻塞IO的线程可以被挂起的同时继续执行IO操作,而让出CPU时间给其他线程执行非IO操作。这样一来,多线程并行IO操作就可以起到提高运行效率的作用了。使用协程来处理并发场景。
- 使用subprocess模块管理子进程的时候,给communicate方法传入timeout参数(等待一定时间无响应就抛异常),以避免子进程死锁或者失去响应;
- 并行是多个CPU,是真正意义上的同时执行多个任务;并发是看起来是多个任务同时执行,实际上是采用的时间切片的方式,CPU来回切换;线程是CPU执行的最基本单元;进程是系统进行资源分配的基本单元;多线程相比多进程,无需重复申请资源,子线程和父线程是共享资源的,所以线程间的通信速度要快于多个进程;协程:又叫做微线程,协程的特点是只有一个线程在执行,只有当子程序内部发生阻塞或者IO时,才会交出执行权,线程的优点是:省去了线程间的切换开销;由于是单线程的不需要加锁,所以执行效率更高;进程间的通信方式:管道、共享存储器系统、消息传递系统、信号量;
- 关于python中的协程
asynico.run()用来运行最高层级的入口点main()函数;
await 后接一个可等待对象;并不会在开启并发;
asyncio.create_task()才是真正用来并发运行asyncio任务的多个协程;当一个协程通过这个函数被打包成一个任务时,该协程会自动排入日程准备立即运行;但是当前task并不会真正执行,而是等待await后才可以执行,也就是当前线程上有任务的时候task才能开始执行;
import asyncio
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
task1 = asyncio.create_task(say_after(1, "hello1"))
task2 = asyncio.create_task(say_after(2, "world1"))
await say_after(1, "hello2")
await say_after(2, "world2")
await task1 # 即使没有这两句也会执行hello1和world1,当上面创建任务的时候就已经准备执行了,只要有一个await,就会开始执行了;
await task2 # 直接用await是顺序执行,用create的是并行的,然后两者之间也是并行的;
asyncio.run(main())
# 输出:
hello2
hello1
world1
world2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号