

周末遐想(计算最长英语单词链)
0.前言
刚从北京回来,恰逢周末,好友近日也不在武汉。又因在博客中的一些交流,恰好看见微软邹欣老师关于《现代软件工程作业 -- 计算最长英语单词链》的博文。因此得空,按照需求分析到设计到实现以及测试和效能分析的流程,编写程序,分析程序并攥写一篇博文。考虑到时间比较有限,随笔之中难免出现语句不通,错别字,以及一些错误分析等等现象,还望见谅。
周末时间只有一天,此篇博文包括代码均有很多坑!嘿嘿~
《计算最长英语单词链》 https://www.cnblogs.com/xinz/p/7119695.html
Github地址: https://github.com/yuan574954352/WordChain
1.需求分析(略)
英语的接龙吧:一个文本文件中有N 个不同的英语单词, 我们能否写一个程序,快速找出最长的能首尾相连的英语单词链,每个单词最多只能用一次。最长的定义是:最多单词数量,和单词中字母的数量无关。
例如, 文件里有:
Apple
Zoo
Elephant
Under
Fox
Dog
Moon
Leaf
Tree
Pseudopseudohypoparathyroidism
最长的相连英语单词串为: apple - elephant – tree, 输出到文件里面,是这样的:
Apple
Elephant
Tree
- 设计以及主要实现过程
【PSP】
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
10 |
8 |
|
· Estimate |
· 估计这个任务需要多少时间 |
960 |
- |
|
Development |
开发 |
720 |
700 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
15 |
10 |
|
· Design Spec |
· 生成设计文档 |
10 |
15 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
10 |
12 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
10 |
15 |
|
· Design |
· 具体设计 |
20 |
22 |
|
· Coding |
· 具体编码 |
480 |
500 |
|
· Code Review |
· 代码复审 |
15 |
20 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
60 |
30 |
|
Reporting |
报告 |
30 |
35 |
|
· Test Report |
· 测试报告 |
20 |
22 |
|
· Size Measurement |
· 计算工作量 |
5 |
7 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
20 |
20 |
|
合计 |
|
695 |
708 |
二、解题思路
这个题的解题思路其实很简单啦,也就是说Make it work的实现方式很容易想到,但如何使程序高效率的实现就需要深入考虑了。首先,思考一个基本的方向,核心算法就是使用图论的相关知识,OK。这里关于图论就不详细叙述,简单地以个人的语言来叙述一下:
【图论】
图论的起源就可以追溯到欧拉(Leonhard Euler)所处的那个年代。1736年,欧拉来到了普鲁士的Konigsberg(哈哈,康德老家),发现当地人就有一项消遣活动,就是试图将下图中的每座桥恰好走过一遍并回到原出发点。但从来没有成功过。
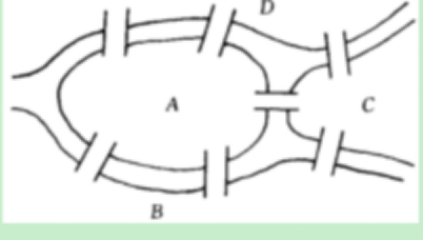
欧拉呢,就想着证明为什么一直没成功啦~~~~
欧拉就把这个问题抽象成 点与线的构造,这不就是图嘛!
至于为什么不可能。可以百度搜索【欧拉七桥问题的证明】
- 图的分类
(1)无向图:就是说两个顶点没有明确的指向关系,只有一条边相连。就我目前的知识而言,我所了解的关于图论的大部分算法都是基于无向连通图的。
(2)有向图:说白了,就是有方向的图呗!!嘿嘿,但是有方向,一定要记清几个定义!这也是顺理成章的定义,就是In与out!在无向图中,一个顶点有多少条可以出去的路,就这个顶点的度。显然,在有向图就会分为 出度与入度。
事实上,度与边是有数学关系的,出度与入度也是一样。度与边的关系也是【欧拉七桥问题】关键点啦。
(3)连通图:任意两个顶点之间是连通的。
(4)非连通图:无向图中,存在两个顶点之间是不连通的
(5)强连通图:针对有向图而言的,A->B 而B 不能 ->A
(6)非强连通图:有向图中存在两个顶点之间是不连通
到后面反过来思考,其实我们求解的最长单词链就是非强连通图哦,那么如果有算法将非强连通图转成类似于无向图的连通图的,会不会提高效率呢~,哈哈。遐想遐想!
好啦。一口气简单介绍了图的来历与分类。那么现实抽象成图,图抽象成数字!就可以成为两个向量:
Vertice={结点1,结点2,.....}
Edge={(1,2),(2,3),(4,6)........}
这两个向量就能描述一张图嘛。而且也好对图进行运算。
OK!我们说提高程序效率从两方面入手,一个是程序输入参数的数据组织结构,也就是数据结构啦,另一个就是算法。
第一:数据结构
关于图的数据结构,常规的有:邻接矩阵,压缩表呀,十字链表呀等等,我也记不清啦。这里就牵扯到 这种数据结构一方面提高程序效率,另一方面要尽可能的减小存储空间,这也就是大多数《数据结构》的书,都分析时间需求,存储空间。
第二:算法
就我了解的呀,大的思想类似于贪婪算法,分而治之,动态规划。好像克瑞斯托,以及Prim算法都是基于贪婪算法的啦,但是好像这些都是基于无向连通图的,我也一直没把我实际需要解决的问题(计算最长单词链)直接套用某个算法的,所以掌握这些算法的思想最重要啦,嘿嘿! 就像室内定位的研究领域,想找某个算法直接套用根本不可能啦,但是运用类似于隐马尔科夫,条件随机场呀的思想还是可以的~~~扯远了。。。哈哈
【核心思想】
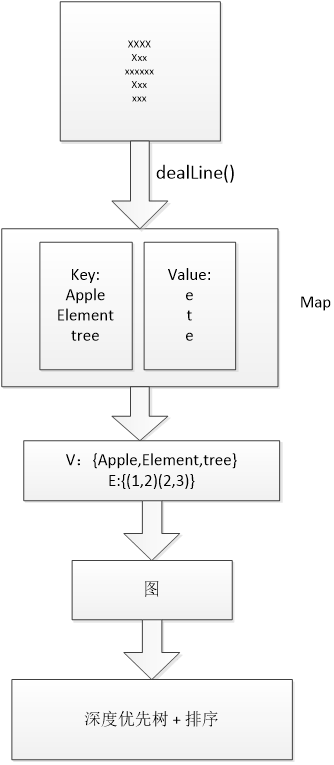
假设结点是:Apple,Elephant,tree.等等,结点与结点的边就是根据首尾字母是否相同来构造的。这边就能得到V,E。构成一个图。请注意:我们一定要构造的是一个非强连通的有向图!
利用图去生成树,利用树去生成路径!
这个思想还是很重要的,据说有一个中国人就发现了一种树,改进了一个算法。我印象在本科阶段上《数据挖掘与分析》的时候,提及过。韩嘉炜老师的FP-Tree.
所以,我也在遐想,能不能也搞一个专用于处理非强连通的有向图生成的树,这个树便于获取最长/最短路径~~~当然是遐想啦,还是务实!其实有时候国内就是这样,很多想法不敢去实施,因为一旦实施失败便意味着你的论文将空荡荡,这个以论文数量论成绩的环境里,我还是要随下大流~~【笑哭】
说到FP-Tree又在联想我这个实际问题,所谓的FP就是频繁模式(frequent pattern),那么我能否也构造一个FP-Tree去找出input.txt中哪些单词总是相伴出现的呢?这又牵扯到关联规则啦,我可没有那么多时间在去扯别的领域的知识啦,“啤酒与尿布”故事总会让我以为关联规则很简单,事实上可不是这样,有时需要用更严格的统计学知识来控制规则的增殖!
OK!运用“敏捷”思想,第一个想到的当然是深度优先生成树。生成n(结点数)个树,获取每个树的最长链!最后排序这些最长链,也就得到我们想要最最长链!
这是“敏捷”思想在促使我这样做,因为我知道这样做,I can make it work!至于后面如何改进就是后话了!
【核心思想图】
三、其他遐想
其实关于图论在工程上实现要考虑的细节很多,那么考虑到我实际的问题,我想。
第一,是用BFS还是DFS?
BFS就是广度优先生成树,当然有些书籍把它称之为宽度优先生成树。DFS是深度优先生成树。说实在的,在以前本科阶段的学习,我只知道有这两种方案可以生成树。生成的树可能只是遍历的顺序不同吧,对此也没有什么好的印象。那个时候,就想着混学分。恨不得早点考完,哈哈。
从理论上讲,这两个算法都能够在大致相同的时间里生成整个单词森林!【这个时间是节点数量V和边的数量E之和的线性函数,即O(V+E)】。那BFS和DFS的在工程上的区别又是如何呢!就拿目前这个问题来说吧,深度优先,他可以比广度优先,提前生成某棵树的一个链路。 这样是不是可以运用多线程的思想,来提前后面的后续操作呢? 当然,这只是遐想,而且这种操作应该需要单词量很多的情况。
四、效率图,考虑到已经到晚上10点啦,下班啦,要去跑步啦啦.....就做了几个就不粘贴上来了。哈哈~~~ 下次有周末再补上来。。嘻嘻。有兴趣的读者也可以自行测试。代码已上传Github。
五、网页版的程序,使用Spring MVC框架,control层调用程序里的lib()即可
写于 地大(武汉)工程研究中心 2018/7/15 (周日)

