阅读笔记《A hybrid video anomaly detection framework via memory-argumented flow reconstruction and flow-guided frame prediction》
1. 摘要
在本文中,提出了HF2VAD框架,一个集成了光流重建和框架预测的混合框架来处理视频异常检测。首先,设计了ML-MemAE-SC(具有跳过连接的自动编码机中的多层次记忆模块)来记忆光流重建的正常模式,以便在光流重建误差较大时敏感的识别异常事件。更重要的是,在重构流的条件下,我们使用条件变分自动编码器(CVAE)来捕捉视频帧和光流之间的高相关性,以预测给定前几帧的下一帧。通过CVAE,流重建的质量本质是影响了帧预测的质量。因此,异常事件的光流重构差进一步恶化了最终预测的未来帧的质量。使得异常更容易检测。实验结果证明了该方法的有效性。
2. HF2VAE模型介绍
在本文中,我们提出了一种新颖的流重建和流导向预测框架相结合的混合框架HF2VAE。如下图所示,基于条件VAE(CVAE)的未来帧预测模型同时接受原始视频帧和光流帧作为输入。但是和原始帧不同的是,我们预先重建他们,而将重建后的流输入到CVAE模型中。
我们设计了一种带有跳过连接的多层记忆增强自动编码机(ML-MemAE-SC),用于光流重建。采用多个记忆模块来记忆不同特征级别的正常模式,同时在编码器和解码器之间添加跳过连接,以补偿由于记忆而造成的强信息压缩。我们观察到,这样一个设计良好的流重构网络可以清晰地重构正常流,同时对异常输入产生较大的重构误差。
我们使用CVAE的模型来进行未来帧的预测。一方面,以ML-MemAE-SC的重构流作为条件,自然地将重构条件统一到预测管道中。另一方面,CVAE模块通过最大化观察视频帧和重构光流帧变量诱导的证据下界(ELBO)量,对输入帧和未来帧流的一致性进行编码。
以上设计利用重建的正常流和异常流之间的质量差距,提高基于CVAE的预测模块的VAD精度。即重构的正常流通常具有较高的质量,通过预测模块可以成功地预测未来的帧,预测误差较小。相比之下,重建的异常流通常质量较低,从而导致未来帧的预测误差较大。我们使用流重建和帧预测误差作为我们最终的异常检测线索,论文和前人工作的区别:
- 首先,在具有跳过连接编码器-解码器结构中使用多级内存模块,保证正常模式能很好地被记忆,从而敏感的识别异常事件或活动
- 其次,我们设计了HF2-VAE混合结构,从之前的视频帧和相应的光流帧中预测未来的帧,并预先进行重建,重建误差增大了预测误差,使异常更容易被检测到。
- 最后,我们在三个公共数据集上进行了广泛的实验,结果表明,我们提出的HF2-VAD比最先进的方法有更好的异常检测性能。
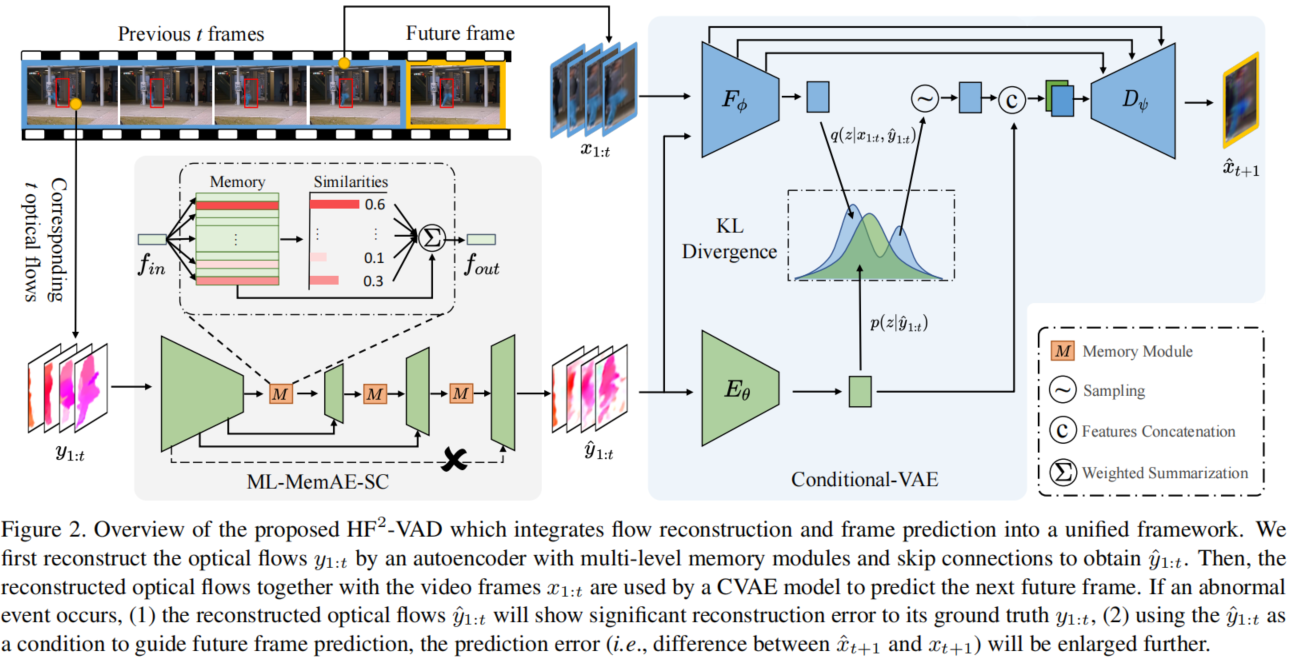
3. 论文方法
如图所示,HF2-VAD模型由两个组件组成:
(1) 用于跳过连接的多层记忆增强自动编码机(ML-MemAE-SC)进行流重建
(2) 用于帧预测的条件变分自动编码器(CVAE)
整个框架都是在正常数据集上进行训练的。在训练时,同时采用重建误差和预测误差。下面分别对两个组件进行介绍,最后展示如何使用模型进行异常检测。
3.1 ML-MemAE-VAD(具有跳过连接的多级内存增强的自动编码机)
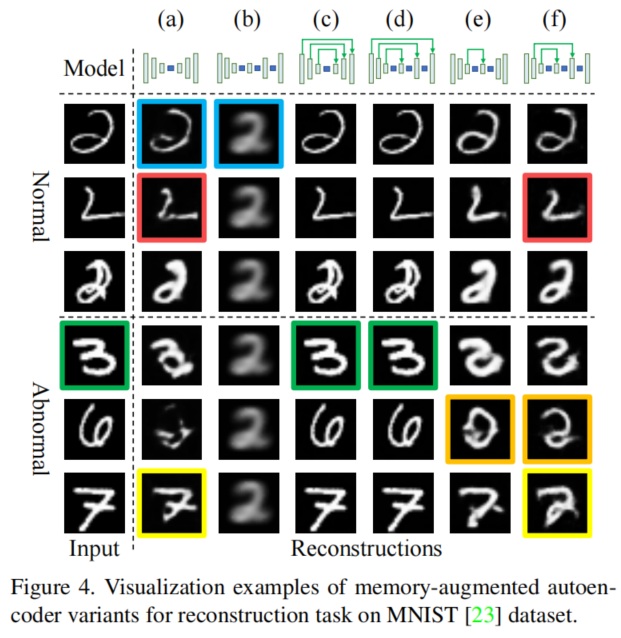
将内存模块置于自动编码机中是异常检测中的最新进展。下图(a) 中显示了这种内存增强的自动编码器(MemAE)。然而,我们观察到,只能只用一个内存模块并不能保证所有的正常模式都能被记住,而异常的输入仍然有一定的机会被很好地重构。MemAE的自然扩展是放置更多内存模块到自动编码机的其他层中(如图(b)所示)。但是太多的内存模块可能导致过度的信息过滤,使得网络无法记住最具代表性的正常模式,而不是所有需要的正常模式。为了解决这个问题,我们在编码器和解码器之间添加跳过连接以获得具有跳过连接的多级内存增强自动编码机(ML-MemAE-SC),如下图中(c)所示。一方面,跳过连接直接将编码器信息传输到解码器,为不同层的内存存储模块提供更多的信息,以发现正常模式。另一方面,该网络具有更高层次的编码特性,虽然被内存过滤了,但他可以更容易地解码输入。在测试时,所提出的ML-MemAE-SC可以清晰地重构正常数据,而对异常数据表现不佳。为了让读者易于验证这一点,我们进行了一个玩具示例来探索许多记忆增强的自动编码机变体,并演示了所提出的ML-MemAE-SC的有效性,详情见图4。值得注意的是,不应该添加最外层的跳过连接,即图3(c)中的黑色虚线连接。否则,重构可能由最高级别的编码-解码信息完成,使得其他较低级的编码、解码和内存模块无法工作。
我们设计了一个四级的ML-MemAE-SC,包括三层编码/解码层和一个bottleneck。在编码器中的每一层,我们堆叠两个卷积块,紧接着为一个下采样层。在解码器的每一层中,我们首先从编码器中复制特征映射,然后将其与较低层的上采样特征映射连接起来。然后该连接依次通过两个卷积块,一个存储器模块和一个上采样层。在我们的实现中,一个卷积块包含三层:一个卷积层,一个正则化层和一个ReLU激活层。通过卷积和反卷积实现了下采样层和上采样层。
对于内存模块,我们采用了类似[8]中的简单实现,每个内存模块实际上是一个矩阵 ,矩阵的每一行被称为一个slot mi(槽),其中i=1,2,3,...,N。内存模块的角色是表示由相似内存槽的加权和输入他的特征,因此在正常数据上训练时具有记忆正常模式的能力。
,矩阵的每一行被称为一个slot mi(槽),其中i=1,2,3,...,N。内存模块的角色是表示由相似内存槽的加权和输入他的特征,因此在正常数据上训练时具有记忆正常模式的能力。
为了训练ML-MemAE-SC,我们可以将正常的视频、图像或光流输入其中,并尝试重构输入数据。设y为输入数据,y'为重构结果,我们训练目标为最小化输入数据和重构数据之间的误差l2.
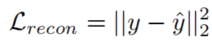
我们将每个内存模块的匹配概率wi'上的熵损失加权为:

其中M为内存模块的数量,wi,k'为第k个内存模块中第k个插槽的匹配改了吧我们对上述两个损失函数进行平衡,得到以下损失函数来训练ML-MemAE-SC:
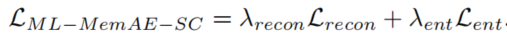


 浙公网安备 33010602011771号
浙公网安备 33010602011771号