C++/Java中的二叉树及相关题目汇总
目录
在这里我们主要思考链式存储的方式
节点

图示
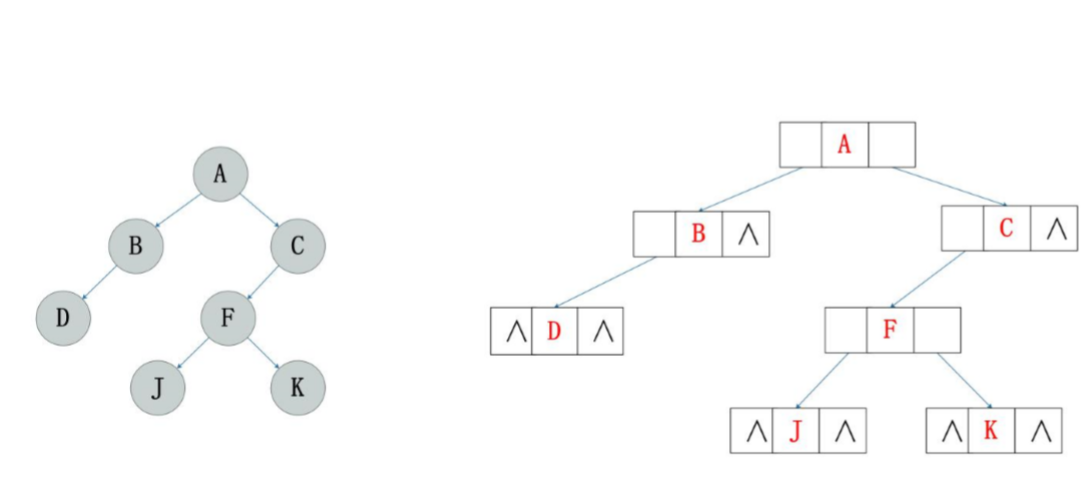
前序、中序和后序遍历过程:遍历过程中经过节点的路线一样,只是访问各节点的时机不同(都是先访问左节点,一直到左节点为空,开始返回,访问其右节点)

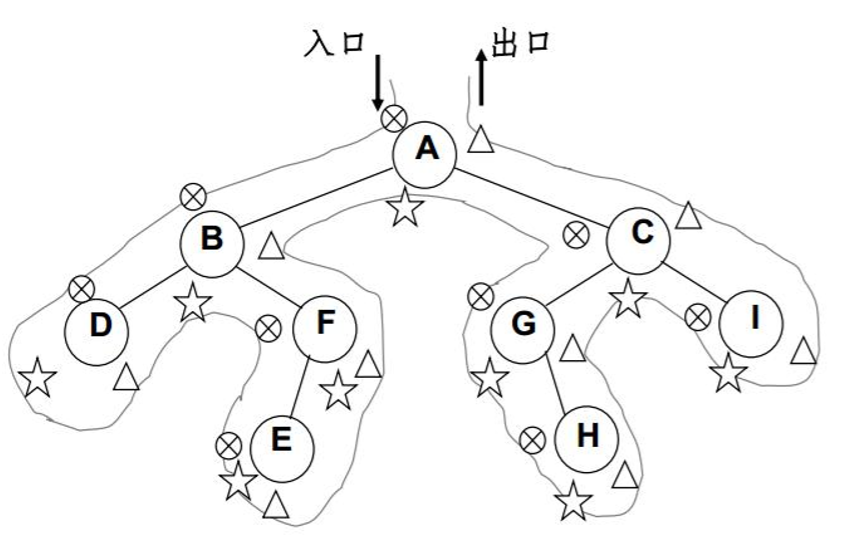
在上图中,
前序遍历:第一次遍历每个节点时即被访问
下列遍历及访问顺序关系中,-X表示第一次访问,--X表示第二次访问,---X表示第三次访问
- 遍历节点A,节点A被第一次遍历,输出A的值 -A
- 遍历A的左子树节点B,此时B被第一次遍历,输出B的值 -B
- 遍历B的左子树节点D,此时D被第一次遍历,输出D的值 -D
- 遍历D的左子树节点,D的左子树节点为空节点,返回D,此时D被第二次访问遍历 --D
- 遍历D的右子树节点,D的右子树节点为空节点,返回D,此时D被第三次遍历 ---D
- D的左右子树节点都被访问完,则直接从节点D返回节点B。
- 从B的左子树节点返回后,B被第二次遍历 --B
- 遍历B的右子树节点F,此时F被第一次遍历,输出F的值 -F
- 遍历F的左子树节点E,此时E被第一次遍历,输出E的值 -E
- 遍历E的左子树节点,E的左子树节点为空节点,返回E,此时E被第二次遍历 --E
- 遍历E的右子树节点,E的右子树节点为空节点,返回E,此时E被第三次遍历 ---E
- E的左右子树节点都被遍历完,则直接从节点E返回节点F。
- 从E返回节点F后,F被第二次访问 --F
- 遍历F的右子树节点,F的右子树节点为空节点,返回节点F,此时F被第三次遍历 ---F
- F的左右子树节点都被访问完,则直接从节点F返回节点B
- 从F节点返回B节点后,B被第三次遍历 ---B
- B的左右子树都被访问完,则直接从节点B返回节点A
- 从B返回节点A后,节点A被第二次访问 --A
- 遍历A的右子树节点C,此时C被第一次遍历,输出C的值 -C
- 遍历C的左子树节点G,此时G被第一次遍历,输出G的值 -G
- 遍历G的左子树节点,G的左子树节点为空节点,返回G,此时G被第二次遍历 --G
- 遍历G的右子树节点H,此时H被第一次遍历,输出H的值 -H
- 遍历H的左子树节点,H的左子树节点为空节点,返回节点H,此时H被第二次遍历 --H
- 遍历H的右子树节点,H的右子树节点为空节点,返回节点H,此时H被第三次遍历 ---H
- H的左右子树节点都被访问完,则直接从节点H返回节点G
- 从节点H返回节点G后,此时G被第三次遍历 ---G
- G的左右子树都被访问完,则直接从节点G返回节点C,此时节点C被第二次遍历 --C
- 遍历C的右子树节点I,此时I被第一次遍历,输出I的值 -I
- 遍历I的左子树节点,I的左子树节点为空节点,返回I,此时I被第二次遍历 --I
- 遍历I的右子树节点,I的右子树节点为空节点,返回I,此时I被第三次遍历 ---I
- I的左右子树节点都被访问完,则直接从节点I返回节点C
- 从节点I返回节点C后,此时C被第三次访问 ---C
- C的左右子树节点都被访问完,则直接从节点C返回节点A
- 从节点C返回节点A后,此时A被第三次遍历 ---A
- A的左右子树都被访问完,访问结束
中序遍历:第二次遍历每个节点时即被访问
后序遍历:第三次遍历每个节点时即被访问
前序遍历:先访问根节点,再访问左子树节点,最后访问右子树节点
实现前序遍历,实际上有两种方式:递归和循环,递归和循环思想都是一样的,即上述思想,递归是自动调用递归函数,开辟一块新的空间,也等同于使用栈。循环是使用栈来实现
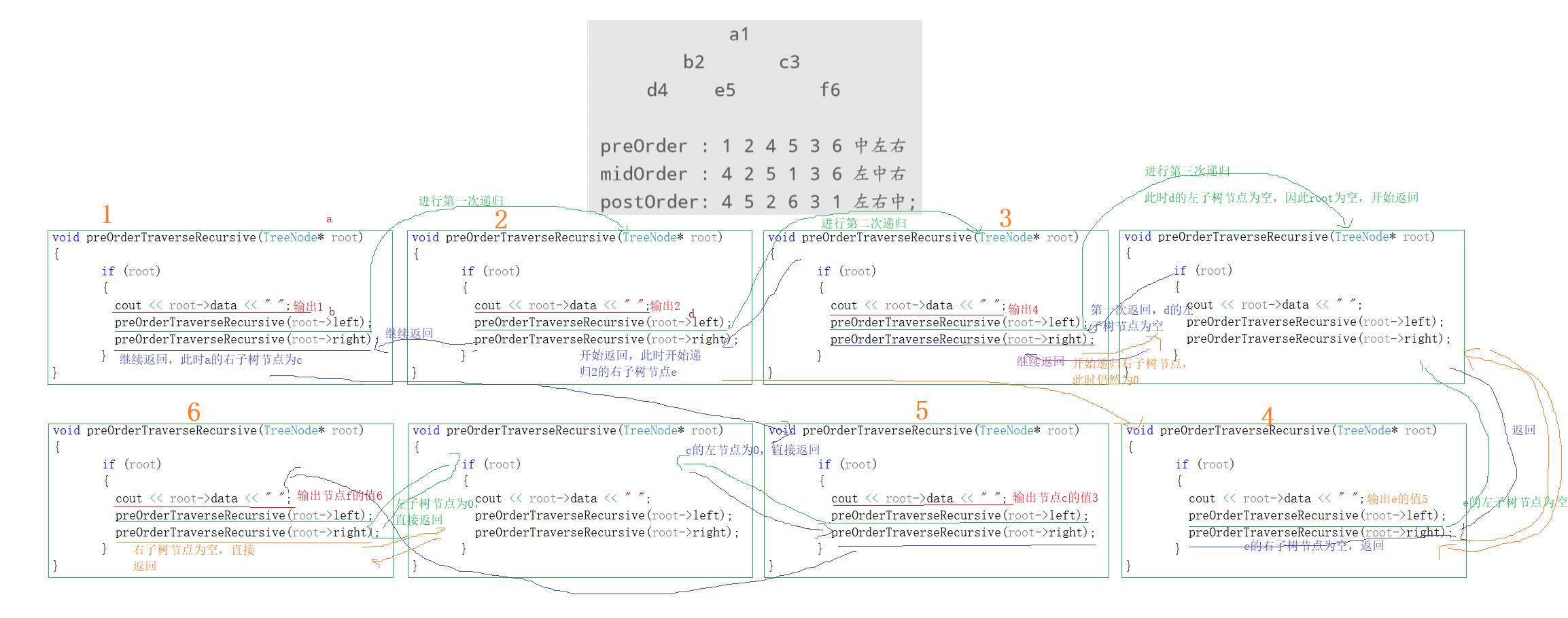
代码参考
typedef struct _treeNode { int data; struct _treeNode* left; struct _treeNode* right; }TreeNode; void preOrderTraverseRecursive(TreeNode* root) { if (root) { cout << root->data << " "; preOrderTraverseRecursive(root->left); preOrderTraverseRecursive(root->right); } }
mystack.h
1 typedef struct _treeNode 2 { 3 int data; 4 struct _treeNode* left; 5 struct _treeNode* right; 6 }TreeNode; 7 8 #pragma once 9 typedef struct _stack 10 { 11 int _len; 12 int _top; 13 TreeNode** _space; 14 }Stack; 15 16 void initStack(Stack* s, int size); 17 bool isStackEmpty(Stack* s); 18 bool isStackFull(Stack* s); 19 void mypush(Stack* s, TreeNode* data); 20 TreeNode* mypop(Stack* s);
mystack.cpp
1 #include <iostream> 2 #include "mystack.h" 3 #include "mytree.h" 4 5 using namespace std; 6 7 8 void initStack(Stack* s, int size) 9 { 10 s->_len = size; 11 s->_top = 0; 12 s->_space = new TreeNode*; 13 } 14 15 bool isStackEmpty(Stack* s) 16 { 17 return s->_top == 0; 18 } 19 20 bool isStackFull(Stack* s) 21 { 22 return s->_top == s->_len; 23 } 24 25 void mypush(Stack* s, TreeNode* data) 26 { 27 s->_space[s->_top++] = data; 28 } 29 30 TreeNode* mypop(Stack* s) 31 { 32 return s->_space[--s->_top]; 33 }
preOrder
1 void preOrderTraverse(TreeNode* root) 2 { 3 if (root) 4 { 5 Stack s; 6 initStack(&s, 1000); 7 while (!isStackEmpty(&s) || root) 8 { 9 while (root) 10 { 11 cout << root->data << " "; 12 mypush(&s, root); 13 root = root->left; 14 } 15 root = mypop(&s); 16 root = root->right; 17 } 18 } 19 }
中序遍历:先访问左子树节点,再访问根节点,最后访问右子树节点
因此中序遍历即在节点第二次被遍历的时候访问
类似于前序遍历分析方式,首先递归左子树节点,然后输出节点,最后递归右子树节点
1 void midOrderTraverseRecursive(TreeNode* root) 2 { 3 if (root) 4 { 5 midOrderTraverseRecursive(root->left); 6 cout << root->data << " "; 7 midOrderTraverseRecursive(root->right); 8 } 9 }
还是利用栈来实现,在节点被弹出后对节点进行访问
1 void midOrderTraverse(TreeNode* root) 2 { 3 if (root) 4 { 5 Stack s; 6 initStack(&s,1000); 7 while (!isStackEmpty(&s) || root) 8 { 9 while (root) 10 { 11 mypush(&s, root); 12 root = root->left; 13 } 14 root = mypop(&s); 15 cout << root->data << " "; 16 root = root->right; 17 } 18 } 19 }
后序遍历:先访问左子树节点,再访问右子树节点,最后访问根节点
后序遍历是在第三次遍历时访问。后序遍历输出的前提是:该结点左右子树结点均为空,或者该结点左右子树节点军备访问过了,此时输出该元素。
-
- 后序遍历的递归实现
首先访问左子树节点,然后访问右子树节点,最后访问根节点
1 void postOrderTraverseRecursive(TreeNode* root) 2 { 3 if (root) 4 { 5 postOrderTraverseRecursive(root->left); 6 postOrderTraverseRecursive(root->right); 7 cout << root->data << " "; 8 } 9 }
-
- 后序遍历的循环实现
-
-
- 先将节点P入栈
- 若节点P不存在左孩子或右孩子;或者P存在左孩子或右孩子,但左右孩子已经被输出,则直接输出节点P,并将其出栈,将出栈节点标记位上一个输出的节点,再将此时的栈顶节点设置为当前节点
- 若不满足2的条件,则将P的右孩子和左孩子依次入栈,当前节点重新置为栈顶节点
- 直到栈为空,遍历结束。
-
1 void postOrderTraverse(TreeNode* root) 2 { 3 if (root) 4 { 5 Stack s; 6 initStack(&s, 1000); 7 TreeNode* pre = nullptr;//前一个访问的节点 8 TreeNode* cur; 9 mypush(&s, root); 10 while (!isStackEmpty(&s)) 11 { 12 cur = mypop(&s); 13 mypush(&s, cur); 14 if ((cur->left == nullptr || cur->right == nullptr) || pre != nullptr && (pre != cur->left || pre != cur->right)) 15 { 16 //如果节点没有孩子节点或者被访问过 17 cout << cur->data << " "; 18 mypop(&s); 19 pre = cur; 20 } 21 else 22 { 23 if (cur->right != nullptr) 24 mypush(&s, cur->right); 25 if (cur->left != nullptr) 26 mypush(&s, cur->left); 27 } 28 } 29 } 30 }
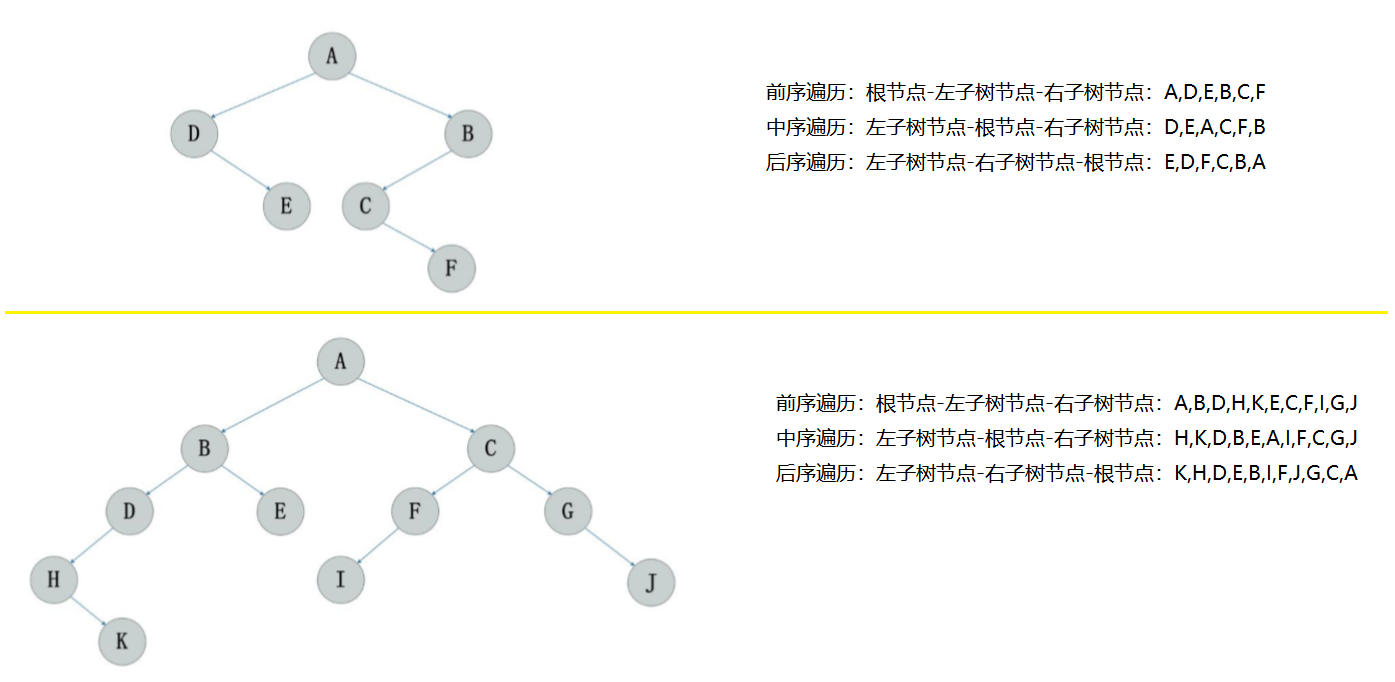
3.2 有如下两种遍历方式,找出第三种遍历方式并画图
- 已知先序遍历和中序遍历
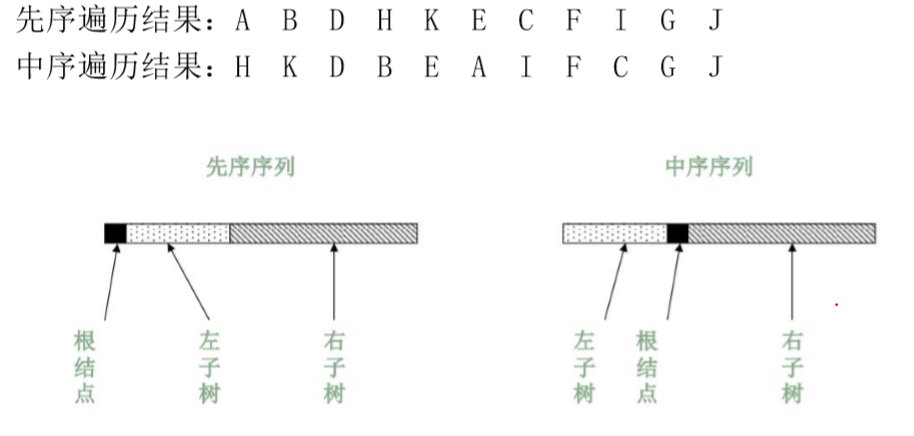
问题分析
- 已知中序遍历和后序遍历
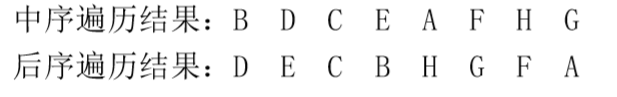
问题分析

- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 vector<int> preorderTraversal(TreeNode* root) { 13 vector<int> B; 14 if(root==nullptr) 15 return B; 16 stack<TreeNode*> s; 17 while(!s.empty()||root) 18 { 19 while(root) 20 { 21 B.push_back(root->val); 22 s.push(root); 23 root=root->left; 24 } 25 root=s.top(); 26 s.pop(); 27 root=root->right; 28 } 29 return B; 30 } 31 };
- JAVA代码参考
1 /** 2 * Definition for a binary tree node. 3 * public class TreeNode { 4 * int val; 5 * TreeNode left; 6 * TreeNode right; 7 * TreeNode() {} 8 * TreeNode(int val) { this.val = val; } 9 * TreeNode(int val, TreeNode left, TreeNode right) { 10 * this.val = val; 11 * this.left = left; 12 * this.right = right; 13 * } 14 * } 15 */ 16 class Solution { 17 public List<Integer> preorderTraversal(TreeNode root) { 18 List<Integer> list=new ArrayList<Integer>(); 19 Stack<TreeNode> st=new Stack<TreeNode>(); 20 if(root==null) 21 return list; 22 st.push(root); 23 while(!st.empty()) 24 { 25 root=st.peek(); 26 list.add(root.val); 27 st.pop(); 28 29 if(root.right!=null) 30 st.push(root.right); 31 32 if(root.left!=null) 33 st.push(root.left); 34 } 35 return list; 36 } 37 }
1.2 二叉树的中序遍历及相关变形题目
- C++代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 vector<int> inorderTraversal(TreeNode* root) { 13 vector<int> B; 14 if(root==nullptr) 15 return B; 16 stack<TreeNode*> s; 17 while(!s.empty()||root) 18 { 19 while(root) 20 { 21 s.push(root); 22 root=root->left; 23 } 24 root=s.top(); 25 s.pop(); 26 B.push_back(root->val); 27 root=root->right; 28 } 29 return B; 30 } 31 };
- JAVA代码参考
1 /** 2 * Definition for a binary tree node. 3 * public class TreeNode { 4 * int val; 5 * TreeNode left; 6 * TreeNode right; 7 * TreeNode() {} 8 * TreeNode(int val) { this.val = val; } 9 * TreeNode(int val, TreeNode left, TreeNode right) { 10 * this.val = val; 11 * this.left = left; 12 * this.right = right; 13 * } 14 * } 15 */ 16 class Solution { 17 public List<Integer> inorderTraversal(TreeNode root) { 18 Stack<TreeNode> s=new Stack<TreeNode>(); 19 List<Integer> list=new ArrayList<Integer>(); 20 if(root==null) 21 return list; 22 while(!s.empty()||root!=null) 23 { 24 while(root!=null) 25 { 26 s.push(root); 27 root=root.left; 28 } 29 root=s.peek(); 30 list.add(root.val); 31 s.pop(); 32 33 root=root.right; 34 } 35 return list; 36 } 37 }

- 问题分析
由于二叉搜索树是的中序遍历是排序的,因此我们可以借助中序遍历来实现,如果节点的左子树节点不为空,则一直压栈,直到其为空时 ,出栈,再访问其右子树节点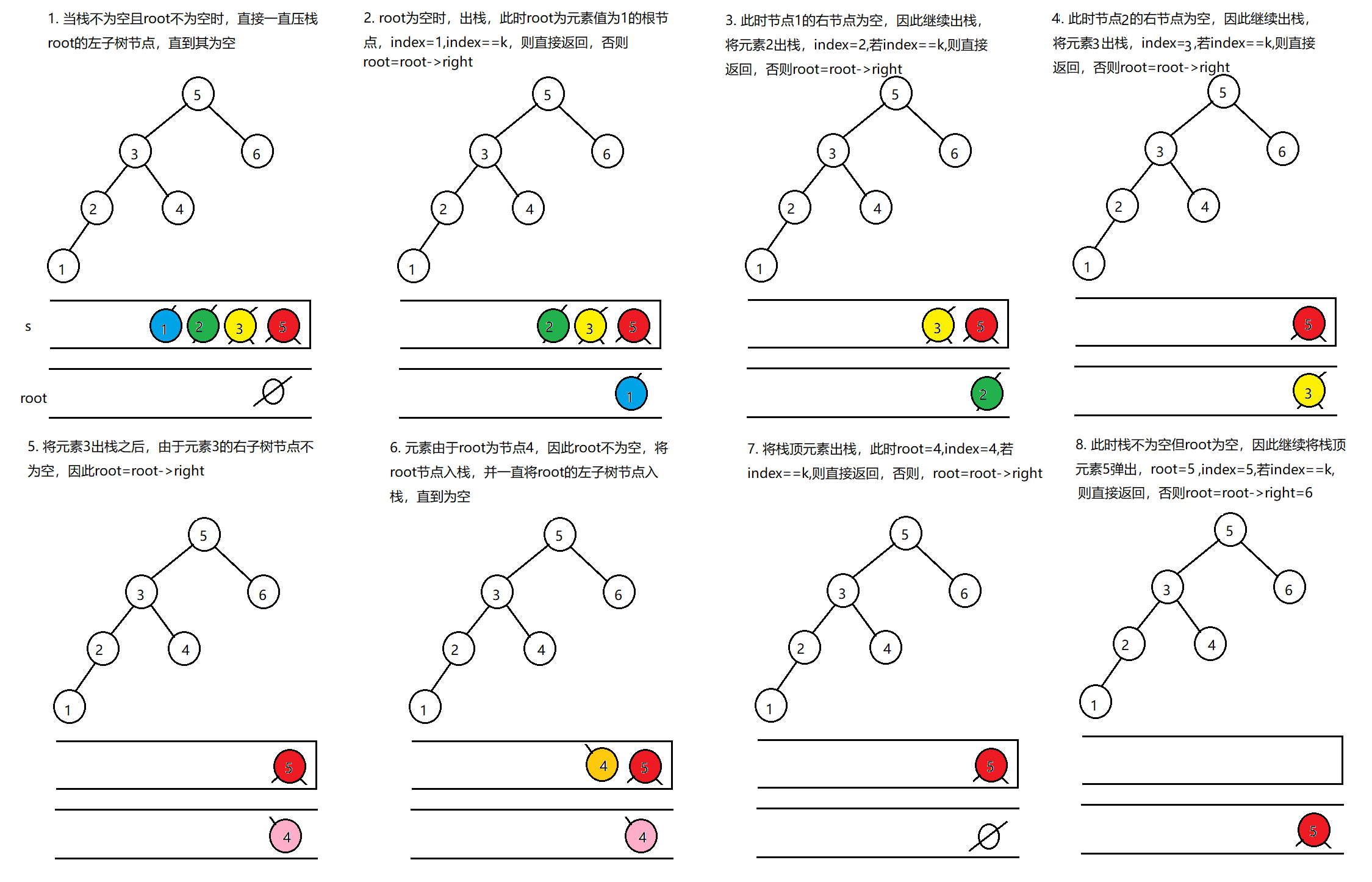
- 代码参考
1 /* 2 struct TreeNode { 3 int val; 4 struct TreeNode *left; 5 struct TreeNode *right; 6 TreeNode(int x) : 7 val(x), left(NULL), right(NULL) { 8 } 9 }; 10 */ 11 class Solution { 12 public: 13 TreeNode* KthNode(TreeNode* pRoot, int k) 14 { 15 if(pRoot==nullptr) 16 return nullptr; 17 int index=0; 18 stack<TreeNode*> s; 19 while(!s.empty()||pRoot!=nullptr) 20 { 21 while(pRoot) 22 { 23 s.push(pRoot); 24 pRoot=pRoot->left; 25 } 26 pRoot=s.top(); 27 s.pop(); 28 ++index; 29 if(index==k) 30 return pRoot; 31 pRoot=pRoot->right; 32 } 33 return nullptr; 34 } 35 36 37 };

- 问题分析
二叉搜索树中序遍历的结果是递增序列,中序遍历的逆序的第k个元素就是本题的解
中序遍历的逆序遍历方法:
每个节点都先访问右子树,再访问左子树
按这种方法,最先访问的一定是第1大的节点
第k个访问的一定是第k大的节点
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 int kthLargest(TreeNode* root, int k) { 13 if(root==nullptr) 14 return 0; 15 stack<TreeNode*> s; 16 int index=0; 17 while(!s.empty()||root!=nullptr) 18 { 19 while(root) 20 { 21 s.push(root); 22 root=root->right; 23 } 24 root=s.top(); 25 s.pop(); 26 ++index; 27 if(index==k) 28 return root->val; 29 root=root->left; 30 } 31 return 0; 32 } 33 };
- JAVA代码参考
1 /** 2 * Definition for a binary tree node. 3 * public class TreeNode { 4 * int val; 5 * TreeNode left; 6 * TreeNode right; 7 * TreeNode(int x) { val = x; } 8 * } 9 */ 10 class Solution { 11 public int kthLargest(TreeNode root, int k) { 12 /* 13 由于二叉搜索树的中序遍历顺序是按照顺序的,因此要找到二叉搜索树的第k大节点,需要找到中序遍历的逆序 14 中序遍历的逆序遍历方法: 15 每个节点先访问右子树,再访问左子树 16 */ 17 int index=0; 18 int result=0; 19 if(root==null) 20 return 0; 21 Stack<TreeNode> s=new Stack<TreeNode>(); 22 while(!s.empty()||root!=null) 23 { 24 while(root!=null) 25 { 26 s.push(root); 27 root=root.right; 28 } 29 30 root=s.peek(); 31 s.pop(); 32 ++index; 33 if(index==k) 34 result=root.val; 35 root=root.left; 36 } 37 return result; 38 } 39 }
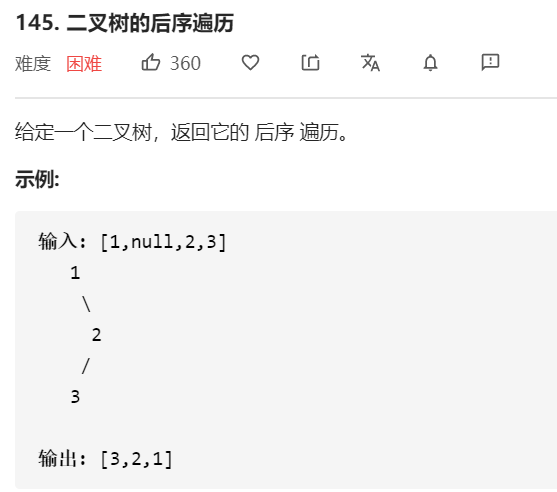
- 问题分析
二叉树的后序遍历,是先访问左子树节点,再访问右子树节点,最后访问根节点
借助栈来进行实现,声明两个指针,cur指向当前节点,pre指向当前节点的前一个节点
后序遍历的非递归实现需要保证根节点的左子树节点和右子树节点都被访问后才能访问
思路如下:
对于任意一节点p
将节点p入栈
若节点p不存在左孩子和右孩子,或者p存在左孩子和右孩子,但是其左孩子和右孩子已经被输出,则直接输出节点p,并将其出栈,将出栈节点p标记为上一个输出的节点,再将此时栈顶元素设置为当前元素
否则将p的右子树节点和左子树节点压栈
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 vector<int> postorderTraversal(TreeNode* root) { 13 //后序遍历是第三次遍历的时候输出 14 /* 15 对于节点p 16 首先将节点p压栈 17 如果p不存在左孩子或者右孩子,或者p存在左孩子和右孩子,但是左孩子和右孩子已经被访问过了,直接将p输出 18 否则依次将右孩子和左孩子入栈 19 */ 20 vector<int> B; 21 if(root==nullptr) 22 return B; 23 TreeNode* cur; 24 TreeNode* pre=nullptr; 25 stack<TreeNode*> s; 26 s.push(root); 27 while(!s.empty()) 28 { 29 cur=s.top(); 30 s.pop(); 31 s.push(cur); 32 if((cur->left==nullptr&&cur->right==nullptr)||(pre!=nullptr&&(pre==cur->left||pre==cur->right))) 33 { 34 B.push_back(cur->val); 35 s.pop(); 36 pre=cur; 37 } 38 else 39 { 40 if(cur->right) 41 s.push(cur->right); 42 if(cur->left) 43 s.push(cur->left); 44 } 45 } 46 return B; 47 } 48 };
- JAVA代码参考
/** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; * TreeNode right; * TreeNode() {} * TreeNode(int val) { this.val = val; } * TreeNode(int val, TreeNode left, TreeNode right) { * this.val = val; * this.left = left; * this.right = right; * } * } */ class Solution { public List<Integer> postorderTraversal(TreeNode root) { /* 二叉树的后续遍历顺序:先访问左子树节点,再访问右子树节点,最后访问根节点 借助栈来实现 */ Stack<TreeNode> s=new Stack<TreeNode>(); List<Integer> list=new ArrayList<Integer>(); while(!s.empty()||root!=null) { while(root!=null) { s.push(root); list.add(root.val); root=root.right; } root=s.peek(); s.pop(); root=root.left; } Collections.reverse(list); return list; } }
/** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; * TreeNode right; * TreeNode() {} * TreeNode(int val) { this.val = val; } * TreeNode(int val, TreeNode left, TreeNode right) { * this.val = val; * this.left = left; * this.right = right; * } * } */ class Solution { public List<Integer> postorderTraversal(TreeNode root) { /* 二叉树的后续遍历顺序:先访问左子树节点,再访问右子树节点,最后访问根节点 借助栈来实现 */ Stack<TreeNode> s=new Stack<TreeNode>(); List<Integer> list=new ArrayList<Integer>(); while(!s.empty()||root!=null) { while(root!=null) { s.push(root); list.add(root.val); root=root.right; } root=s.peek(); s.pop(); root=root.left; } Collections.reverse(list); return list; } }

- 问题分析
二叉搜索的后序遍历就是先访问左子树节点,再访问右子树节点,最后访问根节点。根节点是后序遍历序列中的最后一个元素,因此二叉搜索树的后序遍历序列数组可以分为两个部分:第一部分是左子树节点的值,其都比根节点小;第二部分是右子树节点的值,其都比根节点大
因此判断二叉搜索树的后序遍历序列算法如下:
首先从头到尾遍历整个数组,找到第一个大于根节点的位置,记为i;
从第一个大于根节点的位置到数组最后一个元素,判断是否都大于根节点
如果大于根节点,则继续迭代判断子数组是否满足条件
如果小于根节点,则直接输出为false
- 代码参考
1 class Solution { 2 public: 3 bool VerifySquenceOfBST(vector<int> sequence) { 4 /* 5 由于二叉搜索树有个特性:根节点左边的节点都比根节点小,根节点右边的节点都比根节点大 6 算法如下: 7 根节点在最后一个节点sequence[end] 8 从头到尾扫描整个数组,找到第一个大于根节点的位置i 9 扫描能够保证i之前的元素都比根节点小,但不能保证i之后的元素比根节点大,因此需要判断i之后的元素,如果其比根节点大,则继续迭代,否则直接输出 10 */ 11 if(sequence.empty()) 12 return false; 13 int i; 14 int begin=0; 15 int end=sequence.size()-1; 16 for(i=0;i<end;++i) 17 { 18 if(sequence[i]>sequence[end]) 19 break; 20 } 21 for(int j=i;j<=end;++j) 22 { 23 if(sequence[j]<sequence[end]) 24 return false; 25 } 26 bool left=true; 27 vector<int> seq_left(sequence.begin(),sequence.begin()+i); 28 if(i>begin) 29 left=VerifySquenceOfBST(seq_left); 30 bool right=true; 31 vector<int> seq_right(sequence.begin()+i+1,sequence.end()); 32 if(i<end) 33 right=VerifySquenceOfBST(seq_right); 34 return left&&right; 35 } 36 };

- 问题分析
要实现从上到下打印二叉树,我们可以借助队列来实现,首先将根节点入队,当队列不为空时,将队头元素出队,再依次将队头元素的左子树节点和右子树节点入队,以此类推
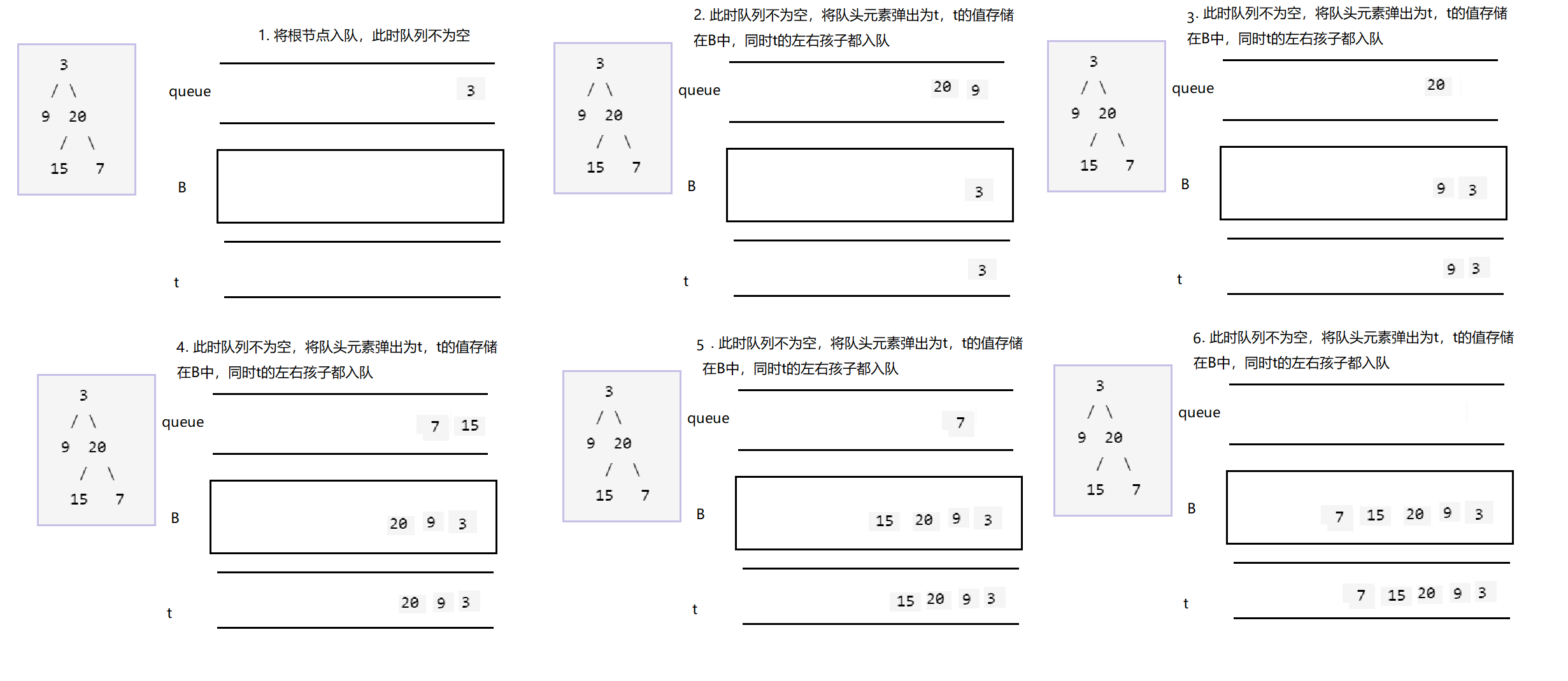
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 vector<int> levelOrder(TreeNode* root) { 13 //利用队列来实现 14 vector<int> B; 15 if(root==nullptr) 16 return B; 17 queue<TreeNode*> q; 18 q.push(root); 19 while(!q.empty()) 20 { 21 TreeNode* t=q.front(); 22 q.pop(); 23 B.push_back(t->val); 24 if(t->left) 25 q.push(t->left); 26 if(t->right) 27 q.push(t->right); 28 } 29 return B; 30 } 31 };
1.5 二叉树的层序遍历
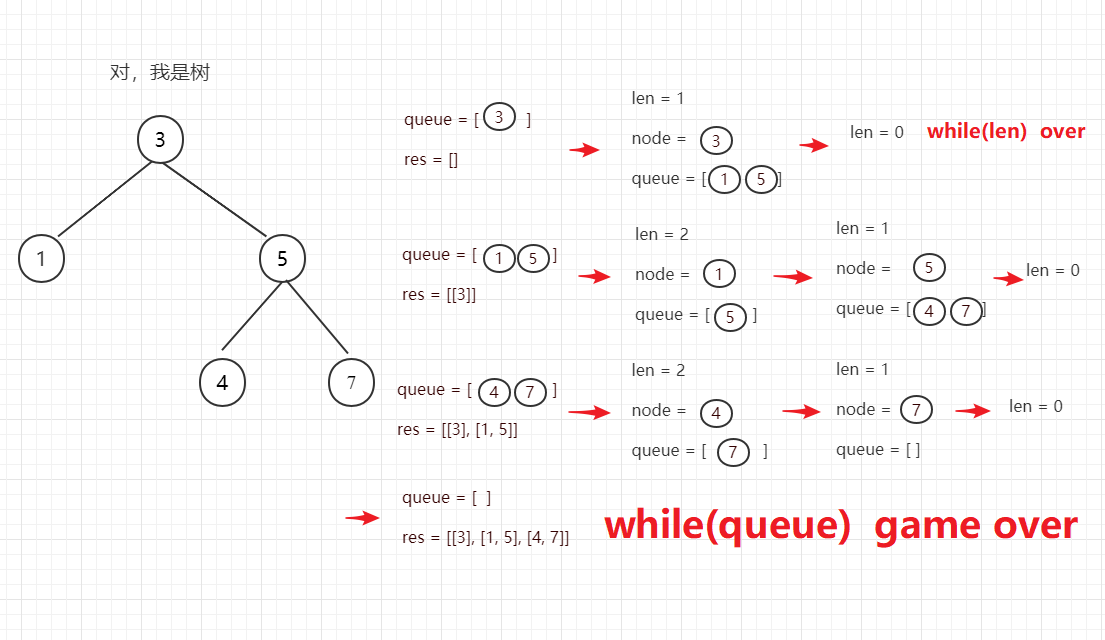
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 vector<vector<int>> levelOrder(TreeNode* root) { 13 vector<vector<int>> B; 14 if(root==nullptr) 15 return B; 16 vector<int> line; 17 queue<TreeNode*> parent; 18 queue<TreeNode*> child; 19 parent.push(root); 20 while(!parent.empty()||!child.empty()) 21 { 22 TreeNode* t=parent.front(); 23 parent.pop(); 24 line.push_back(t->val); 25 if(t->left) 26 child.push(t->left); 27 if(t->right) 28 child.push(t->right); 29 if(parent.empty()) 30 { 31 B.push_back(line); 32 line.clear(); 33 while(!child.empty()) 34 { 35 parent.push(child.front()); 36 child.pop(); 37 } 38 } 39 } 40 return B; 41 } 42 };
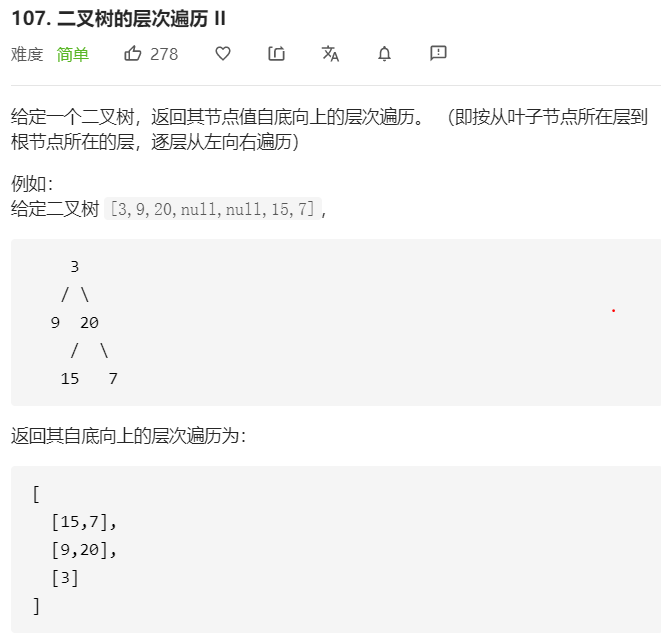
- 问题分析
其思路类似于1.5.1,只是在遍历完一行之后插入时要从头开始插入
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 vector<vector<int>> levelOrderBottom(TreeNode* root) { 13 vector<vector<int>> B; 14 if(root==nullptr) 15 return B; 16 vector<int> line; 17 queue<TreeNode*> parent; 18 queue<TreeNode*> child; 19 parent.push(root); 20 while(!parent.empty()||!child.empty()) 21 { 22 TreeNode* t=parent.front(); 23 parent.pop(); 24 line.push_back(t->val); 25 if(t->left) 26 child.push(t->left); 27 if(t->right) 28 child.push(t->right); 29 if(parent.empty()) 30 { 31 B.insert(B.begin(),line); 32 line.clear(); 33 while(!child.empty()) 34 { 35 parent.push(child.front()); 36 child.pop(); 37 } 38 } 39 } 40 return B; 41 } 42 };

- 问题分析
要实现二叉树的之字形打印,可以用两个辅助栈实现,当前排数为奇数时,从右向左压栈,否则,从左到右压栈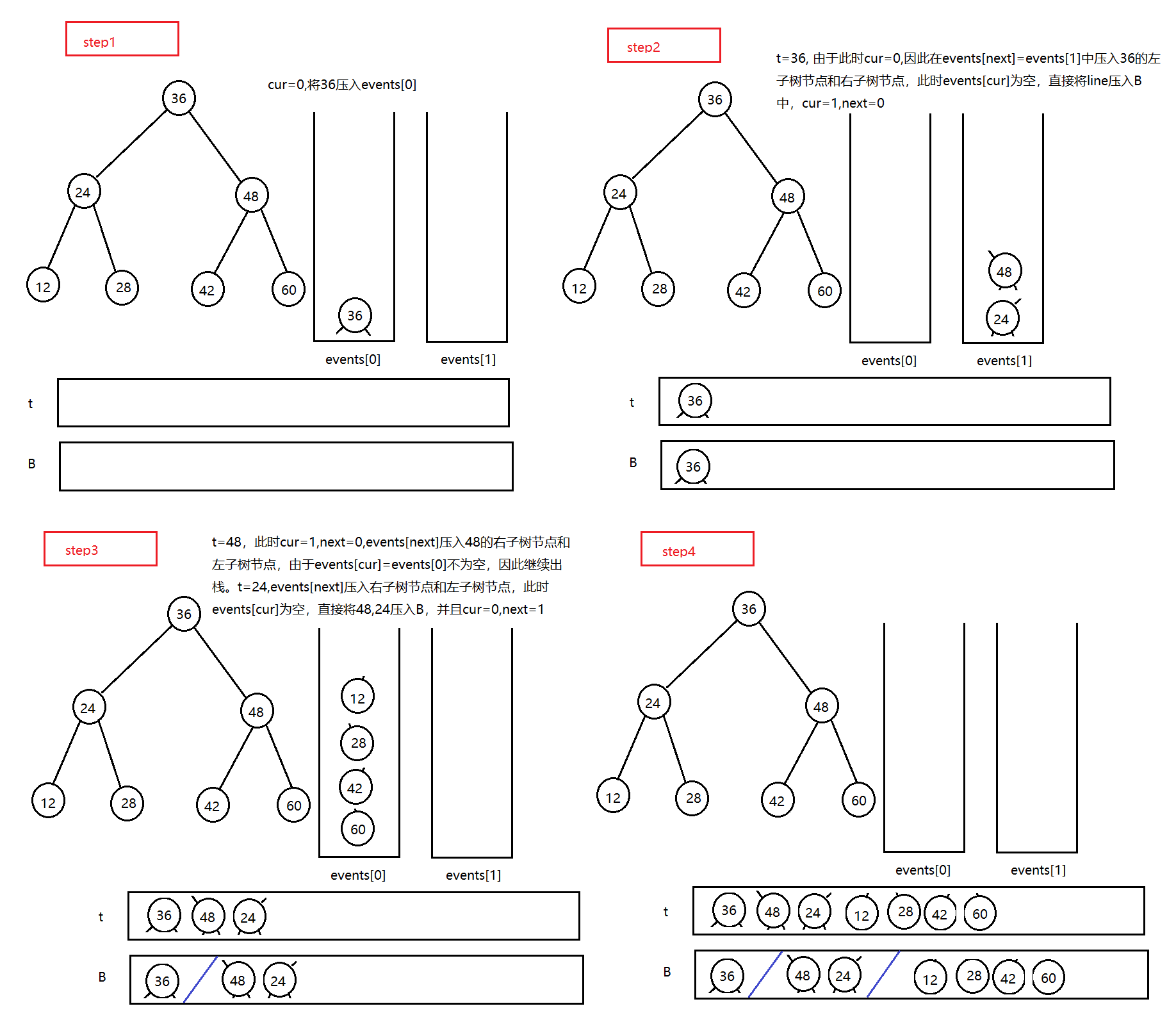
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 vector<vector<int>> levelOrder(TreeNode* root) { 13 vector<vector<int>> B; 14 if(root==nullptr) 15 return B; 16 vector<int> line; 17 stack<TreeNode*> events[2]; 18 int cur=0; 19 int next=1; 20 events[cur].push(root); 21 while(!events[0].empty()||!events[1].empty()) 22 { 23 TreeNode* t=events[cur].top(); 24 events[cur].pop(); 25 line.push_back(t->val); 26 if(cur==0) 27 { 28 if(t->left) 29 events[next].push(t->left); 30 if(t->right) 31 events[next].push(t->right); 32 } 33 else 34 { 35 if(t->right) 36 events[next].push(t->right); 37 if(t->left) 38 events[next].push(t->left); 39 } 40 if(events[cur].empty()) 41 { 42 B.push_back(line); 43 line.clear(); 44 cur=1-cur; 45 next=1-next; 46 } 47 } 48 return B; 49 } 50 };

- 问题分析
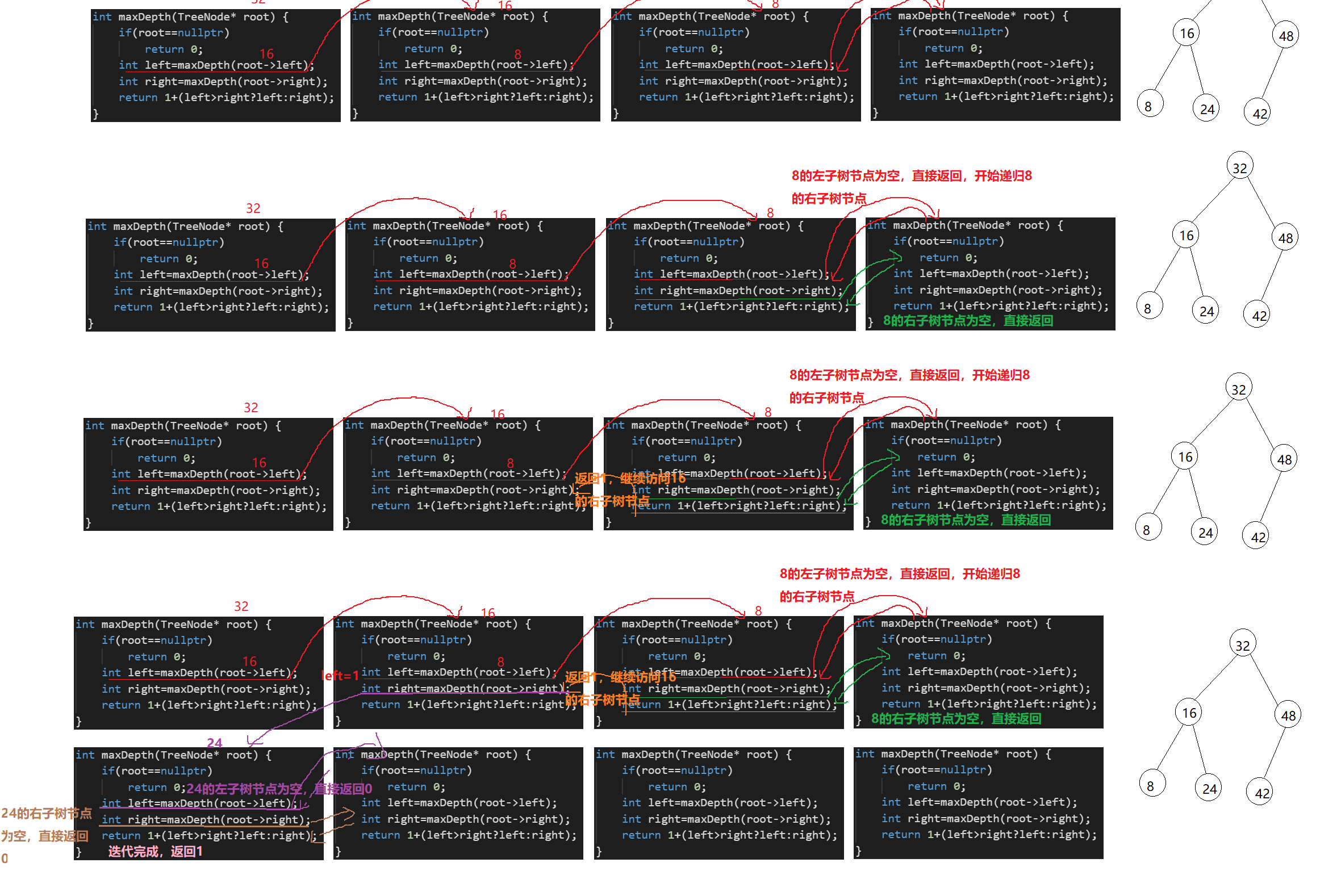
我们可以采用递归的方法,以下图中二叉树为例,主要分为以下几个步骤
- 首先输入根节点3,此时根节点不为空,开始第一次递归,递归为根节点的左子树节点9
- 由于节点9不为空,因此继续递归,递归节点9的左子树节点,由于9的左子树节点为空,开始返回,left=0
- 继续递归9 的右子树节点,9的右子树节点为空,开始返回right=0
- 返回1+(left>right?left:right)=1
- 节点9遍历完之后,返回节点3,开始遍历节点3的右子树节点
- 然后遍历3的左子树节点20
- 继续递归遍历20的左子树节点15
- 继续递归遍历15的左子树节点,其左子树节点为空,开始返回
- 返回到节点20,开始遍历节点20的右子树节点7
- 继续遍历7的左右子树节点,由于都为空,因为返回1+0=1
- 继续返回节点20,左右子树都迭代完了,返回2
- 继续返回节点3,左右子树都迭代完了,返回1+(left>right?left:right)=1+max(1,2)=3

或者如下理解方式(剑指offer第二版上的思想)
对于如下列一个二叉树
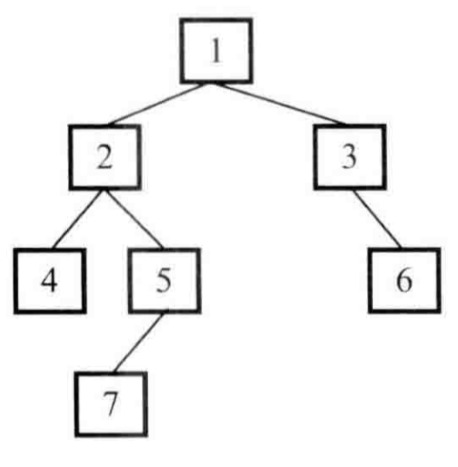
如果二叉树只有一个根节点,则这个二叉树的深度为1;
如果二叉树只有左子树而没有右子树,则树的深度是其左子树的深度+1;
如果二叉树只有右子树而没有左子树,则树的深度是其右子树的深度+1;
如果二叉树既有左子树节点又有右子树节点则树的深度是其左右子树中深度更大的那个+1
对于上述二叉树,
根节点1的左子树深度为3,右子树深度为2,因此二叉树的深度为1+max(2,3)=4;
根节点2的左子树深度为1,右子树深度为2,因此节点2的深度为3;
根节点4只有一个节点,因此这个二叉树的深度为1;
根节点5只有左子树而没有右子树,因此这个二叉树的深度为左子树的深度+1;
根节点3的左子树深度为0,右子树深度为1,因此节点3的深度为2;
因此我们可以采用递归算法来进行实现
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 int maxDepth(TreeNode* root) { 13 if(root==nullptr) 14 return 0; 15 int left=maxDepth(root->left); 16 int right=maxDepth(root->right); 17 return 1+(left>right?left:right); 18 } 19 };
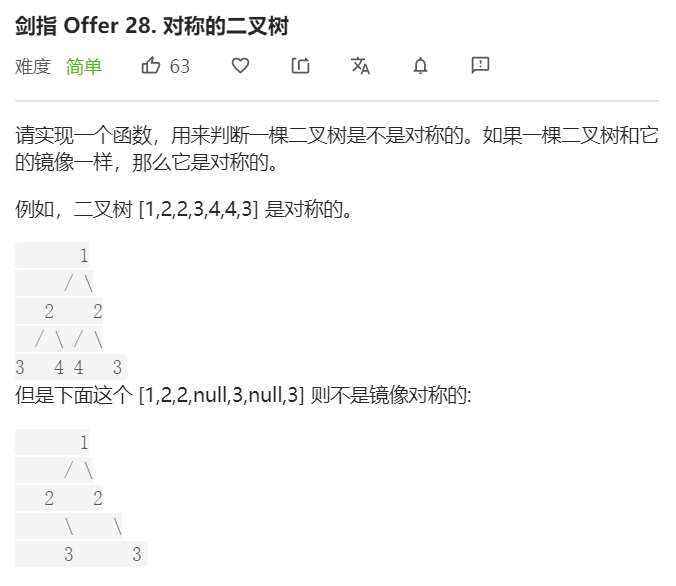
- 问题分析
对称二叉树定义:对于数中任意两个对称节点L和R,一定有
L.val=R.val
L.left.val=R.right.val
L.right.val=R.left.val
综合对称二叉树的规律,考虑从顶至底递归,判断每队节点是否对称,从而判断树是否是对称二叉树

- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 bool myisSymmetric(TreeNode* node1,TreeNode* node2) 13 { 14 if(node1==nullptr&&node2==nullptr) 15 return true; 16 if(node1==nullptr||node2==nullptr||node1->val!=node2->val) 17 return false; 18 return myisSymmetric(node1->left,node2->right) 19 &&myisSymmetric(node1->right,node2->left); 20 } 21 bool isSymmetric(TreeNode* root) { 22 if(root==nullptr) 23 return true; 24 TreeNode* left=root->left; 25 TreeNode* right=root->right; 26 return myisSymmetric(left,right); 27 } 28 };
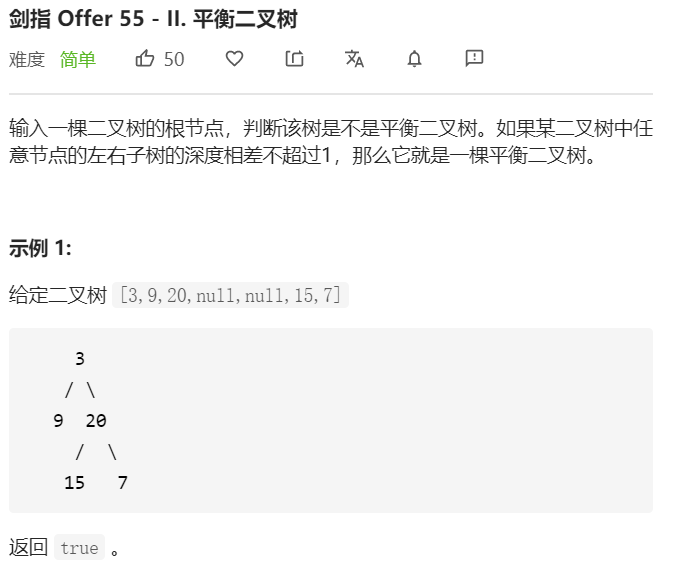
- 问题分析
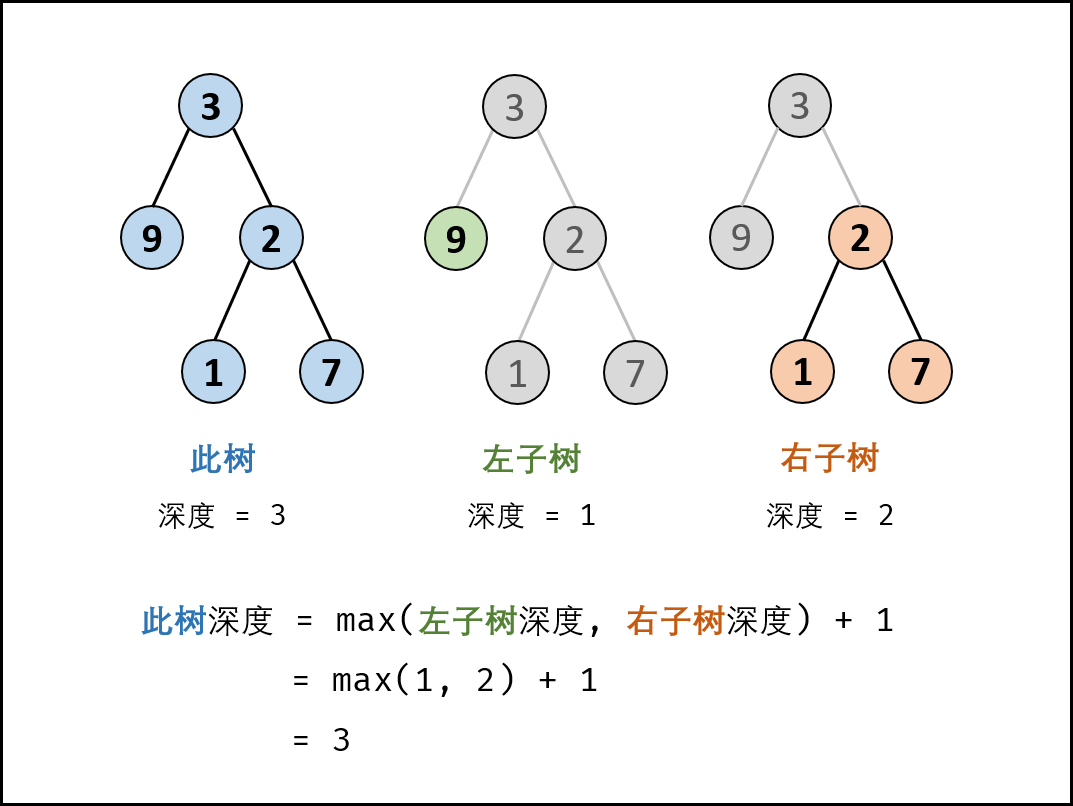
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 int maxDepth(TreeNode* root) 13 { 14 if(root==nullptr) 15 return 0; 16 int left=maxDepth(root->left); 17 int right=maxDepth(root->right); 18 return 1+(left>right?left:right); 19 } 20 bool isBalanced(TreeNode* root) { 21 if(root==nullptr) 22 return true; 23 int left=maxDepth(root->left); 24 int right=maxDepth(root->right); 25 if(abs(left-right)>1) 26 return false; 27 return isBalanced(root->left) 28 &&isBalanced(root->right); 29 } 30 };
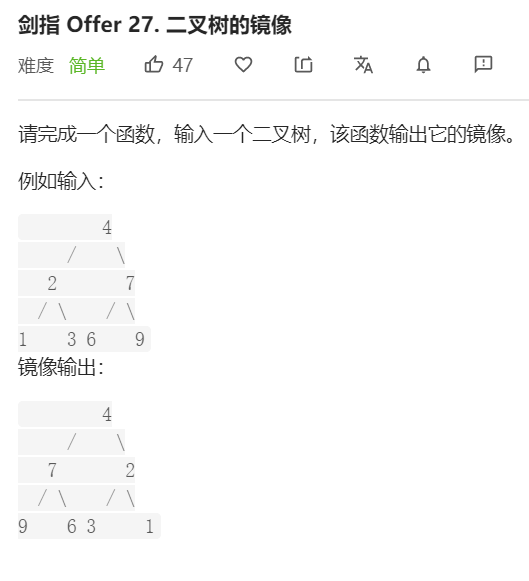
- 问题分析
首先搞懂二叉树镜像的概念,如下图左右两边两颗二叉树就是互为镜像二叉树
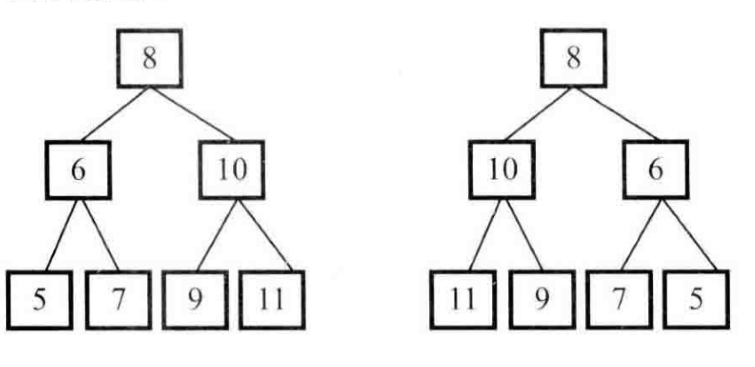
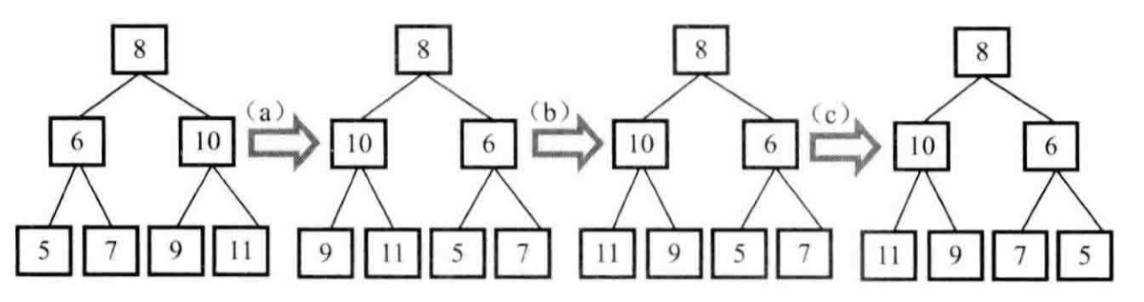
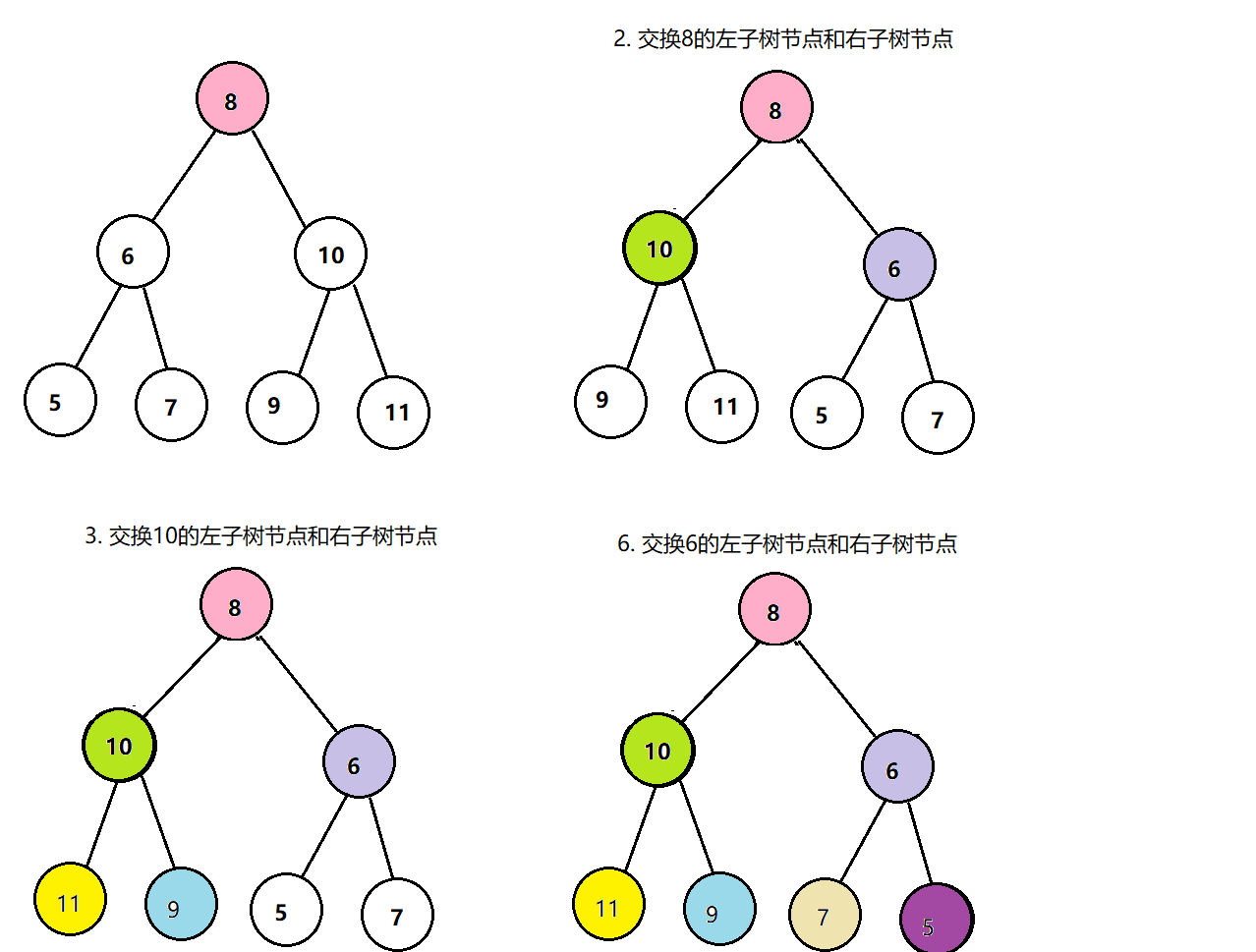
仔细分析上述两颗二叉树的特点,我们发现这两颗二叉树的根节点相同,但其左、右两个子节点交换了位置,因此,
我们首先在树中交换根节点的左右两个子节点,得到如图中的第二颗树;
交换根节点的两个子节点之后,我们注意到值为10,6的节点的子节点仍然不变,因此我们还需要交换这两个节点的左右子树
继续交换节点10的左右子树
然后交换节点6的左右子树
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 TreeNode* mirrorTree(TreeNode* root) { 13 if(root) 14 { 15 TreeNode* t=root->left; 16 root->left=root->right; 17 root->right=t; 18 mirrorTree(root->left); 19 mirrorTree(root->right); 20 } 21 return root; 22 } 23 };
除此之外,可以用递归的就可以用栈来实现,因为递归是不断开辟空间,以上述为例
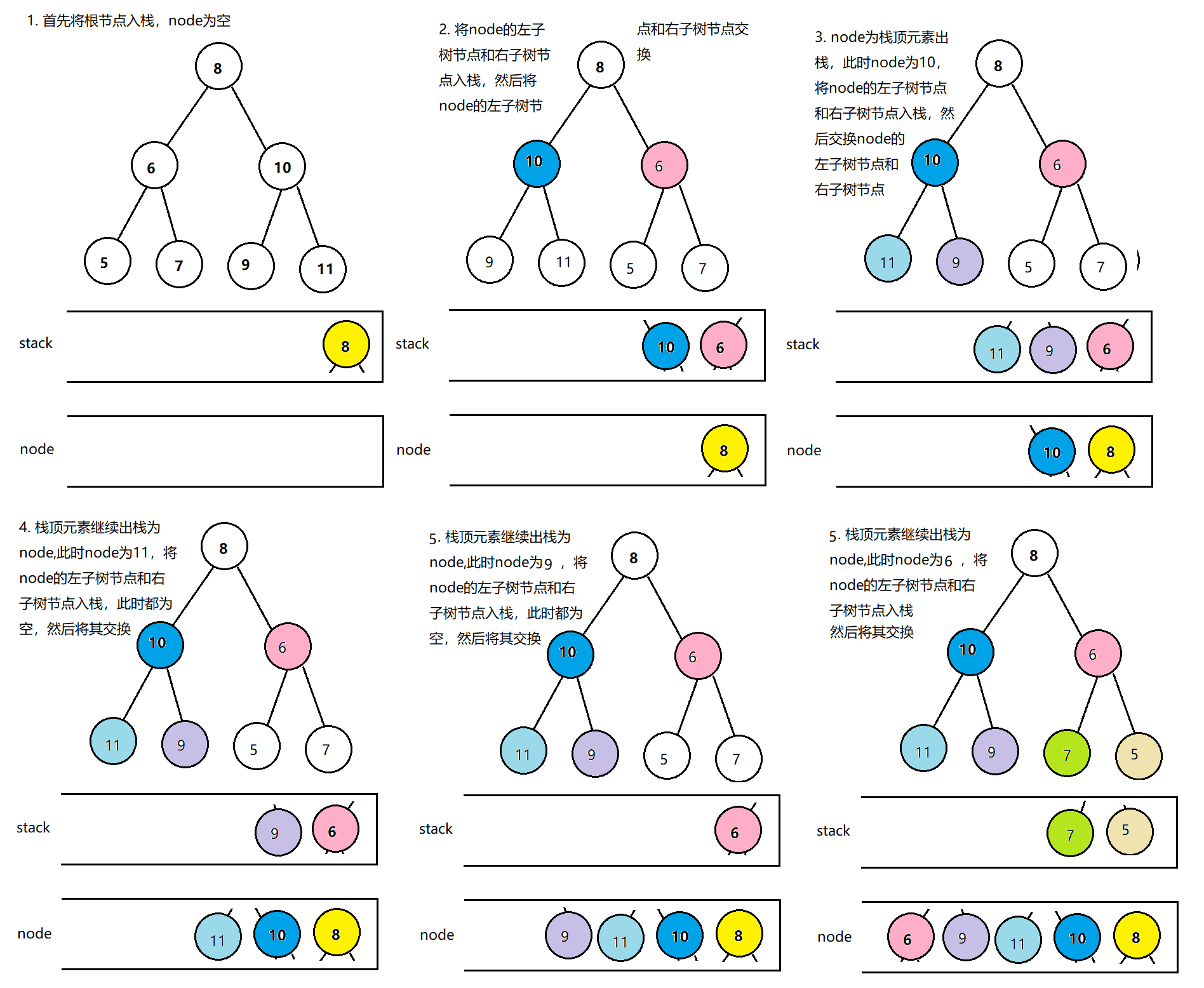
- 代码分析
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 TreeNode* mirrorTree(TreeNode* root) { 13 if(root==nullptr) 14 return nullptr; 15 stack<TreeNode*> s; 16 s.push(root); 17 while(!s.empty()) 18 { 19 TreeNode* node=s.top(); 20 s.pop(); 21 if(node->left) 22 s.push(node->left); 23 if(node->right) 24 s.push(node->right); 25 TreeNode* temp=node->left; 26 node->left=node->right; 27 node->right=temp; 28 } 29 return root; 30 } 31 };

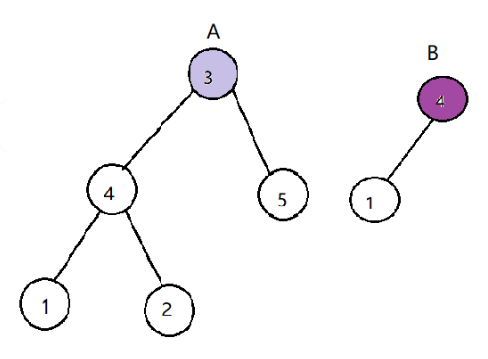
- 问题分析
若B是A的子结构,则子节点的根节点可能为树A的任意一个节点。因此,判断B是否是树A的子结构,需完成以下两步工作:
1. 首先遍历A中的每个节点Na(对应函数:isSubStructure)
2. 判断树A中以Na为根节点的子树是否包含树B(对应函数:DoesTree1HasTree2)
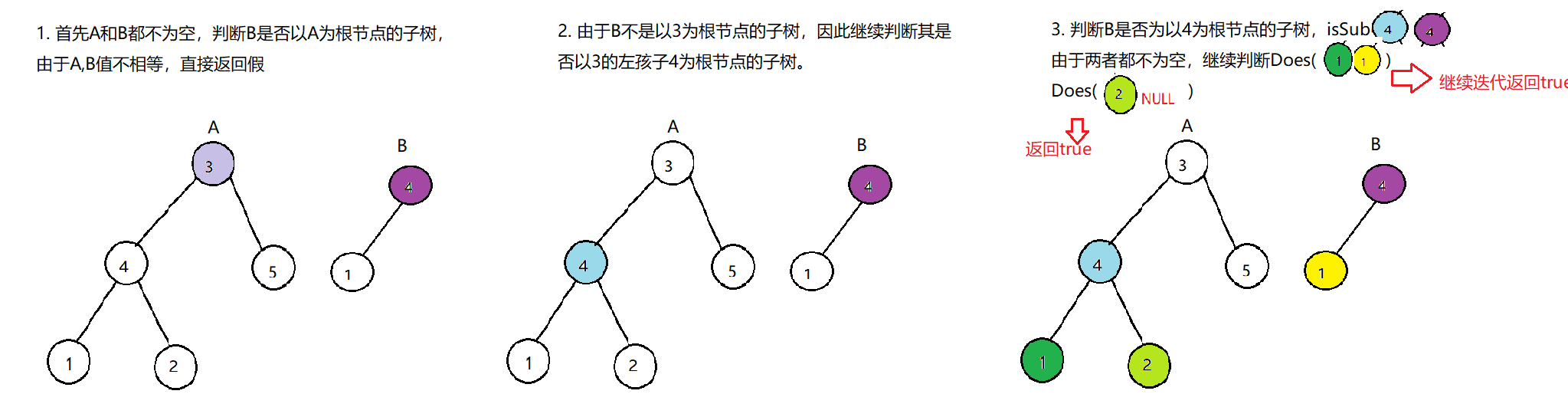
算法流程如下:
DoesTree1HasTree2()函数
1. 终止条件:
当节点B为空时,说明B已经匹配完成(越过叶子节点),因此返回true
当节点A为空时,说明已经越过树A叶子节点,则匹配失败,返回false
当节点A和B的值不同,说明匹配失败,返回false
2. 返回值:
判断A和B的左子节点是否相等,即DoesTree1HasTree2(A->left,B->left)
判断A和B的右子节点是否相等,即DoesTree1HasTree2(A->right,B->right)
isSubStructure()函数
1. 特例处理:
如果树A或者树B为空时,直接返回fasle;
2. 返回值:若树B是树A的子结构,必须满足一下三种情况之一:
以节点A为根节点的子树包含树B,对应DoesTree1HasTree2(),如果不满足,则继续判断
1. 若树B是树A左子树的子结构,对应isSubStructure(A->left,B)
2. 若树B是树A右子树的子结构,对应isSubStructure(A->right,B)
- 问题分析
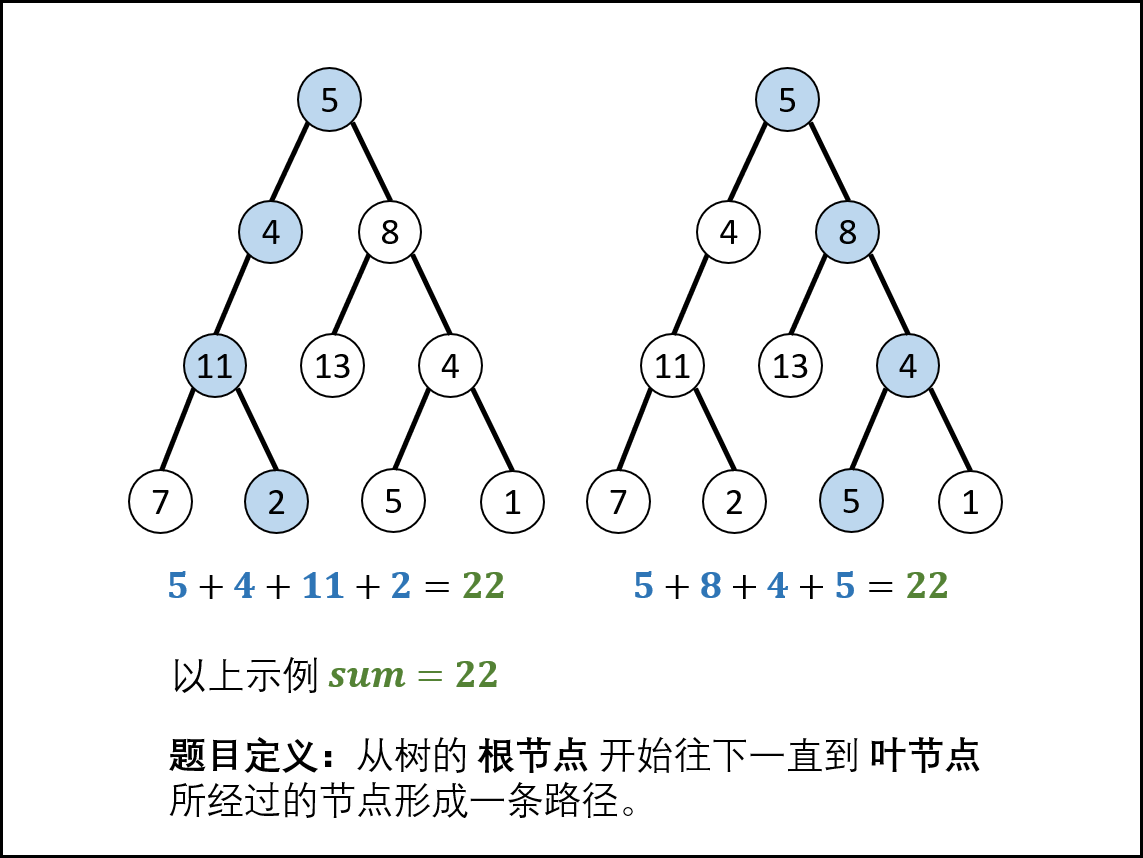
这是典型的二叉树方案搜索问题,使用回溯法解决,其包含前序遍历+路径记录两部分
先序遍历:按照“根、左、右的顺序遍历树的所有节点
路径记录:在先序遍历中,记录从根节点到当前节点的路径,当路径为
1. 根节点到叶节点形成的路径
2. 各节点的值等于目标值sum时,将此路径加入结果列表
pathSum()函数:
初始化:结果列表B,路径列表line
返回值:返回B即可
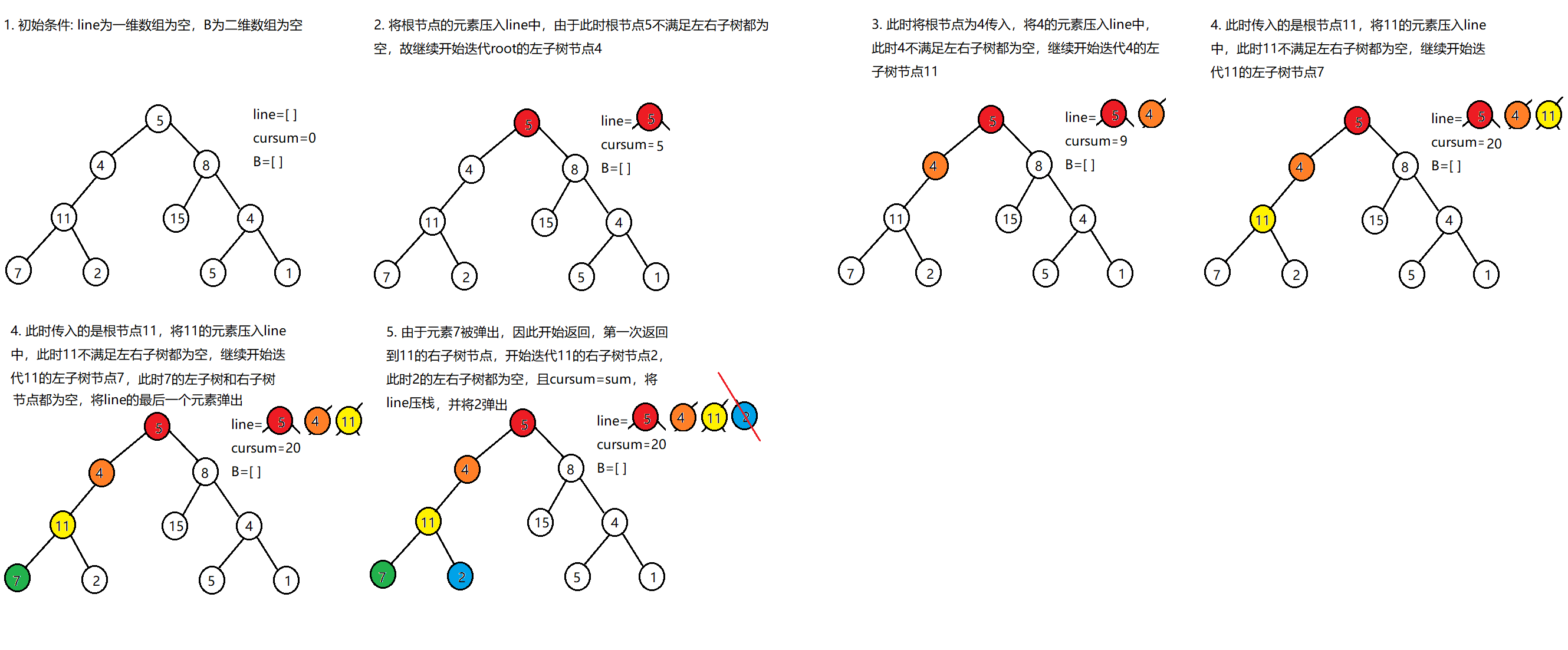
dfs()函数
递推参数:当前节点root,目标和sum,当前和cursum,返回列表B,路径列表line
终止条件:若节点root为空,直接返回
递推工作:
1. 路径更新,当前节点值root.val加入line中
2. 当前和更新:cursum+=root.val
3. 路径记录:(1)若root为叶节点且(2)路径和等于目标值,将line加入B
4. 先序遍历:递归左/右子节点
5. 路径恢复,向上回溯前,需要将当前节点从路径line中删除
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 vector<vector<int>> pathSum(TreeNode* root, int sum) { 13 vector<vector<int>> B; 14 if(root==nullptr) 15 return B; 16 vector<int> line; 17 stack<TreeNode*> s; 18 int cursum=0; 19 dfs(root,sum,cursum,line,B); 20 return B; 21 } 22 void dfs(TreeNode* root,int sum,int cursum,vector<int> &line,vector<vector<int>> &B) 23 { 24 line.push_back(root->val); 25 cursum+=root->val; 26 if(root->left==nullptr&&root->right==nullptr) 27 { 28 if(sum==cursum) 29 B.push_back(line); 30 } 31 if(root->left) 32 dfs(root->left,sum,cursum,line,B); 33 if(root->right) 34 dfs(root->right,sum,cursum,line,B); 35 line.pop_back(); 36 } 37 };

- 问题分析
二叉搜索树特性:如果左子树节点不为空,则左子树上所有节点值均小于其根节点的值;
若右子树节点不为空,则右子树上所有节点值均大于跟节点的值
由于二叉搜索树的根节点比左子树节点大,因此当前节点是其左子树值的上界(最大值)
由于二叉搜索树的根节点比右子树节点小,因此当前节点是其右子树值的下界(最小值)
因此可以用递归来解决
若跟节点为空,则返回true
若根节点的值小于最小值或根节点的值大于最大值,则返回false
继续递归,递归到其根节点的左子树节点和右子树节点
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 bool helper(TreeNode* root,long long lower,long long upper) 13 { 14 if(root==nullptr) 15 return true; 16 if(root->val<=lower||root->val>=upper) 17 return false; 18 return helper(root->left,lower,root->val)&&helper(root->right,root->val,upper); 19 } 20 bool isValidBST(TreeNode* root) { 21 return helper(root,LONG_MIN,LONG_MAX); 22 } 23 };
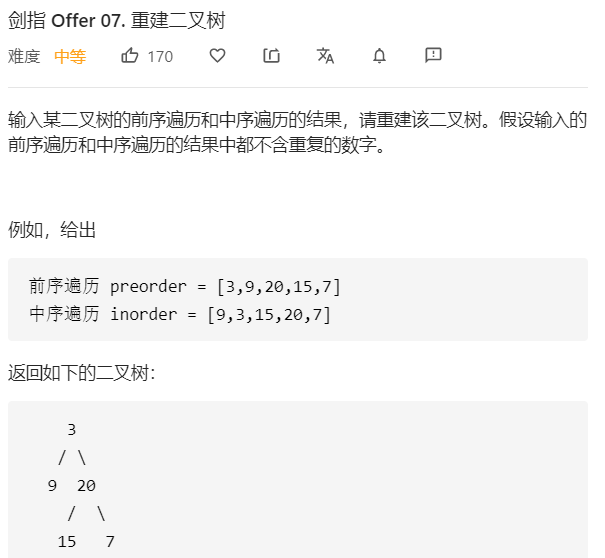
在这一小节中我们主要探讨已知树的两种遍历顺序对树进行重建或者是已知树的两种遍历顺序求出第三种遍历顺序。
- 问题分析
这就是已知两种遍历顺序求树的结构,我们首先对算法进行描述
前序遍历顺序
先访问跟节点
再访问左子树节点
再访问右子树节点
中序遍历顺序
先访问左子树节点
再访问根节点
再访问右子树节点
因此利用前序和中序遍历顺序构造树的算法是
用前序遍历的第一个元素构造出根节点
在中序遍历序列中找到前序遍历第一个元素,并记录其位置i
将前序数组和中序数组拆分成左右两部分
递归处理前序数组中序数组左边
递归处理前序数组中序数组右边
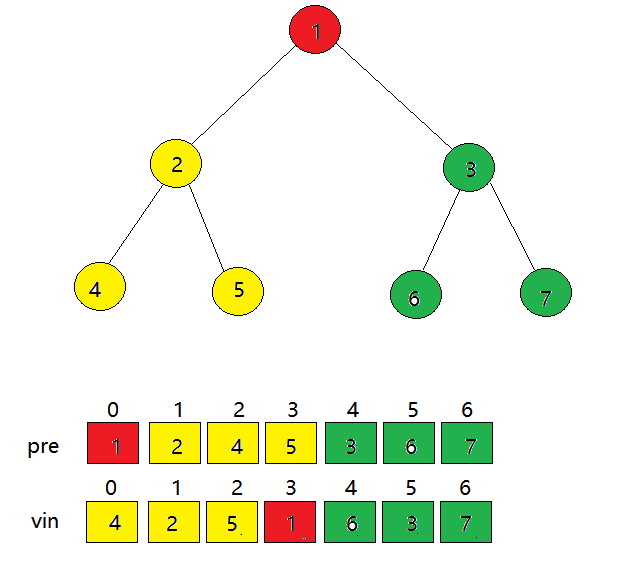
设前序遍历第一个节点在中序数组中出现的位置为i,N为数组中最后一个出现的位置
拆分前序数组:
左半部分:[1, i]
右半部分:[i+1,N]
拆分中序数组
左半部分[0,i)
右半部分:[i+1,N]
当前序遍历和中序遍历顺序不为空时,前序遍历顺序的第一个节点是跟节点,在中序遍历顺序中找到跟节点,根节点左边的序列是左子树节点,根节点右边的序列是右子树节点
因此采用递归操作
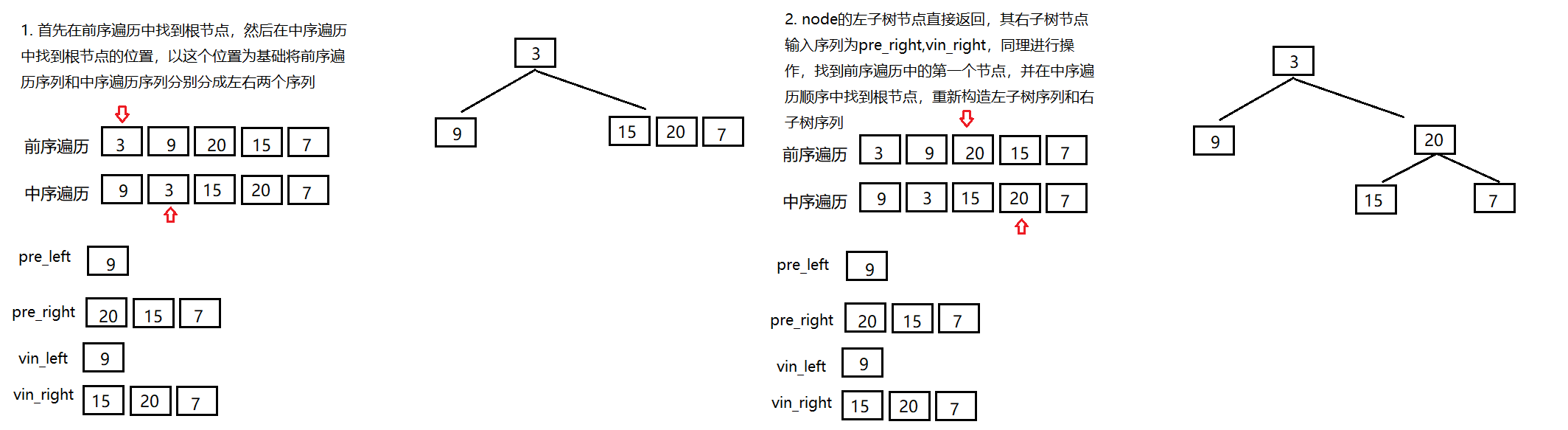
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) { 13 if(preorder.size()!=inorder.size()||preorder.size()<1) 14 return nullptr; 15 int i; 16 int root=preorder[0]; 17 //首先在中序遍历中找到跟节点的位置 18 for(i=0;i<inorder.size();++i) 19 { 20 if(inorder[i]==preorder[0]) 21 break; 22 } 23 //找到根节点后,又开始进行递归 24 vector<int> preorder_left,preorder_right,inorder_left,inorder_right; 25 int j=0; 26 while(j<i) 27 { 28 preorder_left.push_back(preorder[j+1]); 29 inorder_left.push_back(inorder[j]); 30 ++j; 31 } 32 j=i+1; 33 while(j<inorder.size()) 34 { 35 preorder_right.push_back(preorder[j]); 36 inorder_right.push_back(inorder[j]); 37 ++j; 38 } 39 TreeNode* node=new TreeNode(root); 40 node->left=buildTree(preorder_left,inorder_left); 41 node->right=buildTree(preorder_right,inorder_right); 42 return node; 43 } 44 };

- 问题分析
中序遍历的特点:先访问左子树节点,再访问根节点,最后访问右子树节点
后序遍历的特点:先访问左子树节点,再访问右子树节点,最后访问根节点
因此,要根据中序和后序遍历构造二叉树,我们可以先在后序遍历的最后一个节点中找到根节点,,在中序遍历中找到根节点,根节点的左边为左子树节点,根节点的右边为右子树节点。然后再继续进行遍历。
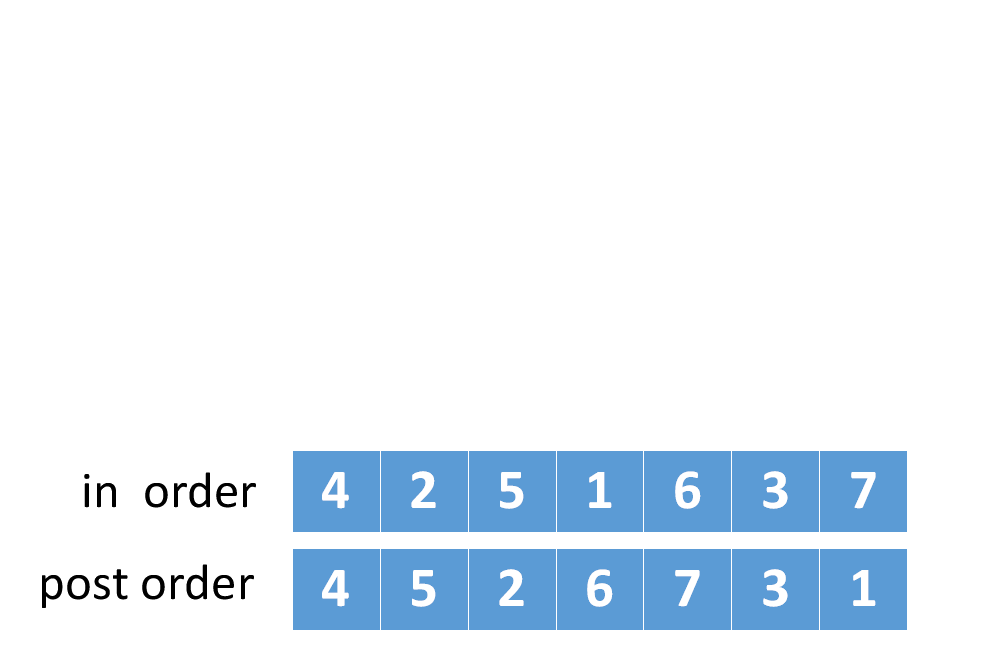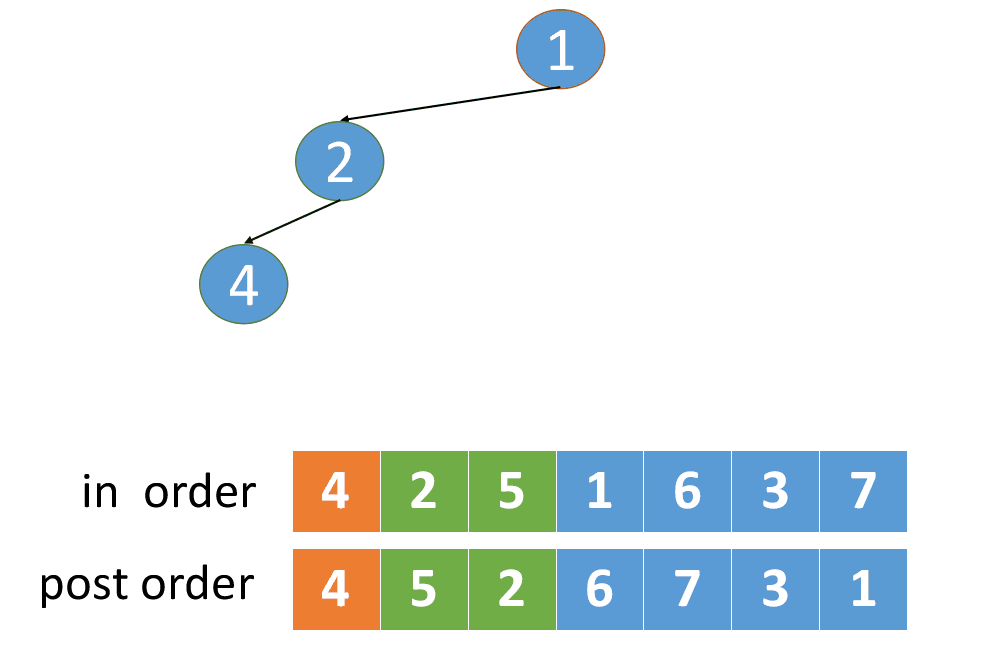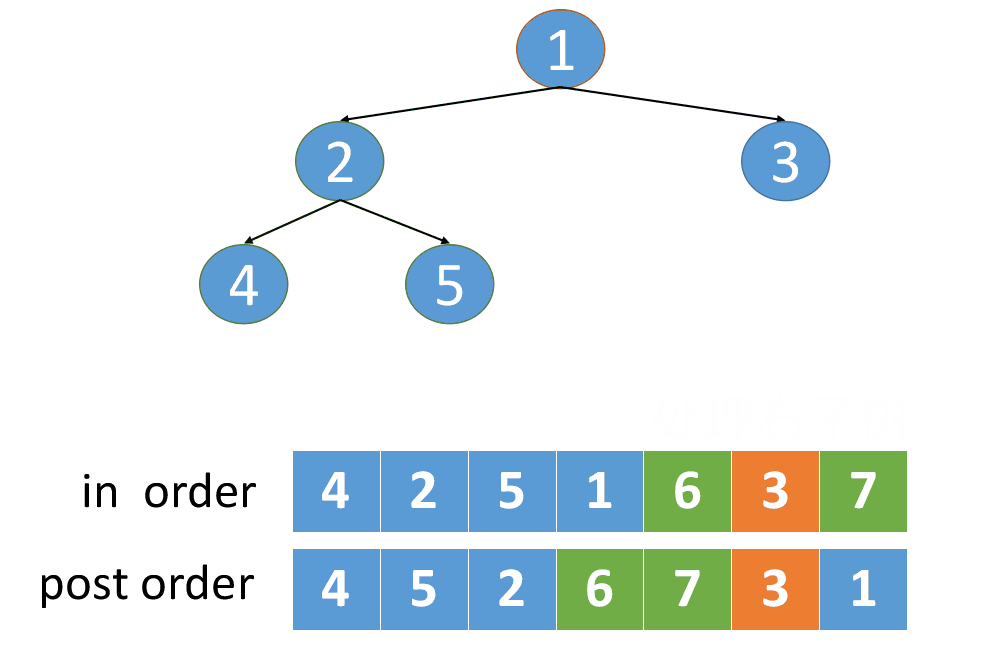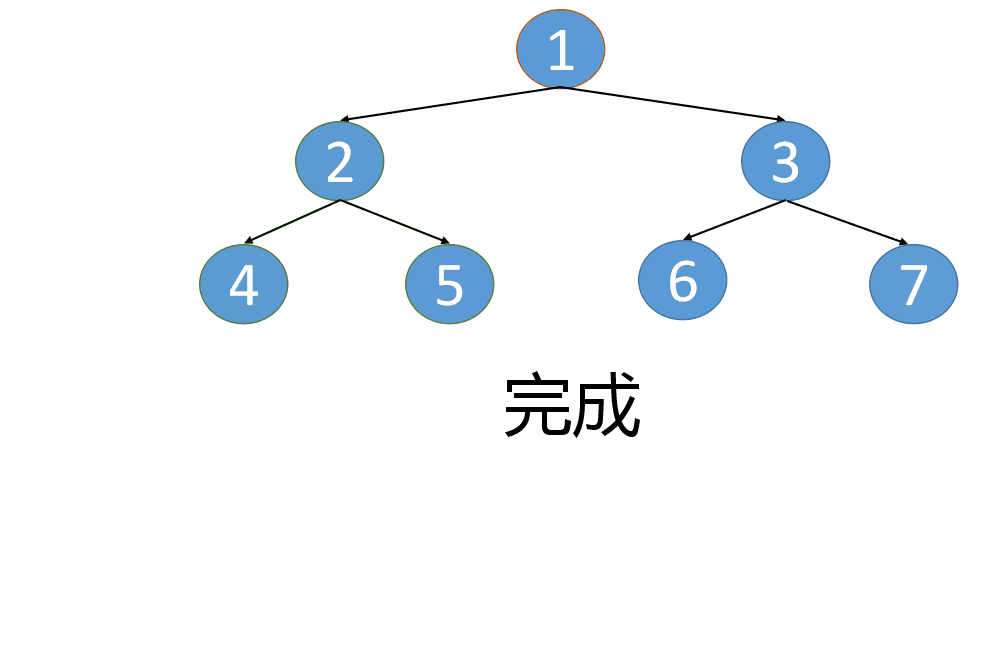
我们根据后序遍历序列的最后一个元素1,找到了中序遍历顺序中元素1的下标值index,
因为中序遍历的特点是根节点把数组分成了两部分,故,根据index,可以将其分为左子树节点和右子树节点

拆分规则如下:(若跟节点的下标值为index,数组最后一个元素的下标值是END_INDEX)
中序遍历左边序列:[0, index)
中序遍历右边序列:[index+1, END_INDEX]
后序遍历左边序列:[0, index)
中序遍历右边序列:[index, END_INDEX-1]
- 问题分析
我们前序遍历二叉树的顺序是:
打印根节点
访问左子树
访问右子树
我们后序遍历二叉树的顺序是:
访问左子树
访问右子树
打印根节点
因此我们肯定采用递归的方法
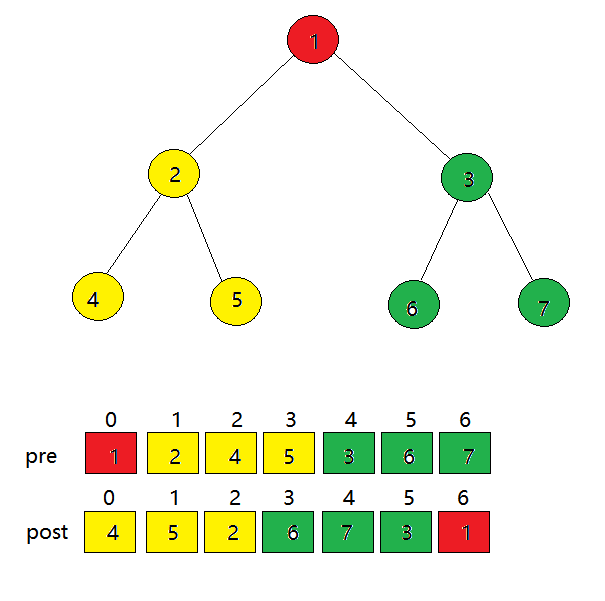
上图中,前序遍历第一个是根节点,后面那一堆是左子树,然后是右子树
后序遍历第一个出现的是左子树,然后是右子树,最后是根节点
在前序遍历和后序遍历序列中,用红色标记根节点,用黄色标记左子树节点,用绿色标记右子树节点
两种遍历方式得到黄色和绿色部分是一样的,索引不一样
利用前序遍历和后序遍历构造树的算法是:
用前序遍历序列中的第一个元素创建出根节点
找到前序遍历序列中的第二个元素x,在后序遍历序列中找到这个元素x,并记录出这个元素的下标i
将前序数组、后序数组拆分成左右两部分
递归处理前序数组左边,后序数组左边
递归处理前序数组右边,后序数组右边
i:记录出后序遍历序列中前序遍历第二个元素x的下标,N:最后一个元素的下标
拆分的前序数组
前序数组左:[1, i+1]
前序数组右:[i+2, N]
拆分后序数组
前序数组左:[0, i]
前序数组右:[i+1,N-1]
- 代码参考
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode(int x) : val(x), left(NULL), right(NULL) {} * }; */ class Solution { public: TreeNode* constructFromPrePost(vector<int>& pre, vector<int>& post) { if(pre.size()!=post.size()||pre.size()<1) return nullptr; int rootnumber=pre[0]; int i; if(pre.size()==1) return new TreeNode(rootnumber); //用前序遍历的第二个元素,去后序遍历中找对应的下标y,将y+1就能找到左子树的个数了 for(i=0;i<post.size();++i) { if(pre[1]==post[i]) break; } // vector<int> pre_left,pre_right,post_left,post_right; int j=0; int left_count=i+1; while(j<=i) { pre_left.push_back(pre[j+1]); post_left.push_back(post[j]); ++j; } j=i+1; while(j<post.size()-1) { pre_right.push_back(pre[j+1]); post_right.push_back(post[j]); ++j; } TreeNode* node=new TreeNode(rootnumber); node->left=constructFromPrePost(pre_left,post_left); node->right=constructFromPrePost(pre_right,post_right); return node; } };

- 问题分析
这是一个经典的回溯法。由于路径是从根节点出发到叶节点,也就是说路径总是以根节点为起始点,因此我们首先需要遍历根节点,在树的前序、中序、后序遍历中,只有前序遍历是首先访问根节点的。分析步骤如 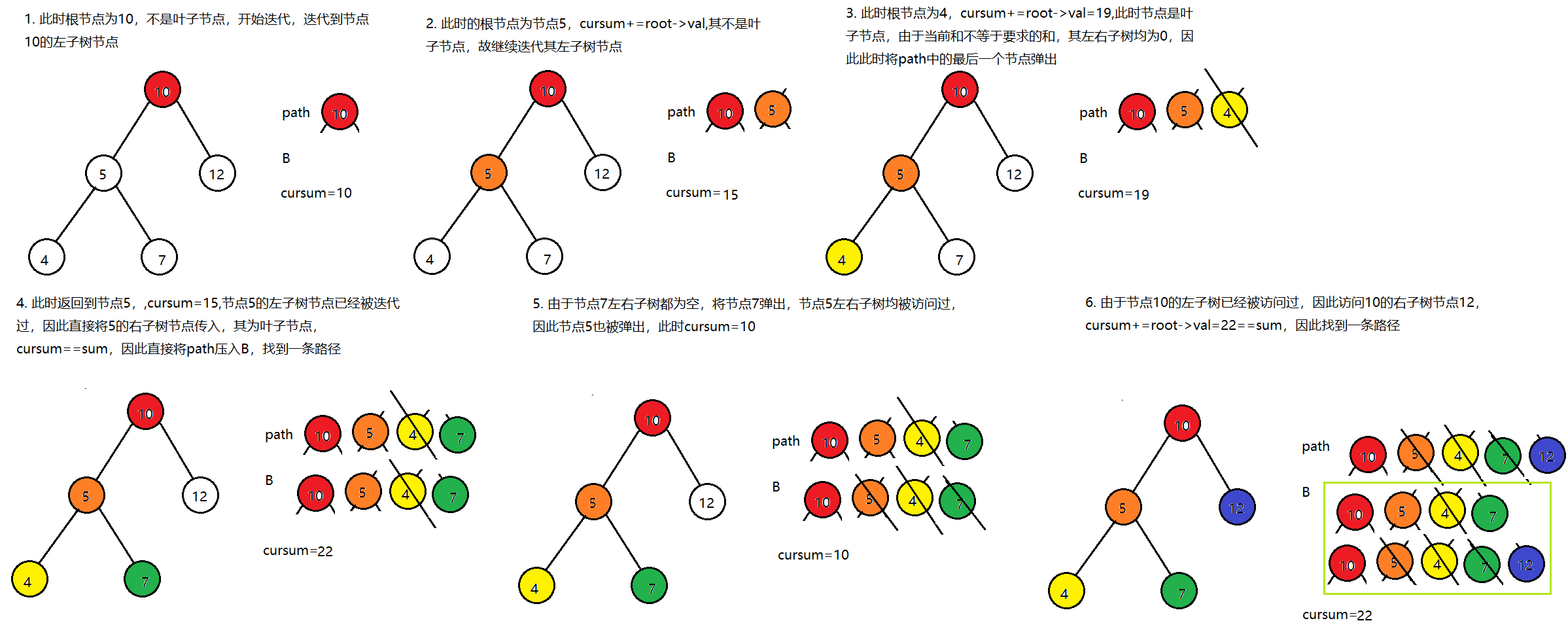
- 代码参考
1 /* 2 struct TreeNode { 3 int val; 4 struct TreeNode *left; 5 struct TreeNode *right; 6 TreeNode(int x) : 7 val(x), left(NULL), right(NULL) { 8 } 9 };*/ 10 class Solution { 11 public: 12 vector<vector<int> > FindPath(TreeNode* root,int expectNumber) { 13 vector<vector<int>> B; 14 if(root==nullptr) 15 return B; 16 vector<int> path; 17 int cursum=0; 18 ispath(root, expectNumber, cursum, path, B); 19 return B; 20 } 21 void ispath(TreeNode* root,int expectNumber,int cursum,vector<int>& path,vector<vector<int>>& B) 22 { 23 path.push_back(root->val); 24 cursum+=root->val; 25 if(root->left==nullptr&&root->right==nullptr) 26 { 27 if(cursum==expectNumber) 28 B.push_back(path); 29 } 30 if(root->left) 31 ispath(root->left, expectNumber, cursum, path, B); 32 if(root->right) 33 ispath(root->right, expectNumber, cursum, path, B); 34 path.pop_back(); 35 } 36 };

- 问题分析
和上述方法类似,不同之处在于,只要有当前和等于目标和的情况,其就返回true。从根节点开始,每当遇到一个节点的时候,从目标值里扣除结点值,一直到叶子节点判断目标值是不是被扣完
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 bool hasPathSum(TreeNode* root, int sum) { 13 int cursum=0; 14 return isPathSum(root,sum,cursum); 15 } 16 bool isPathSum(TreeNode* root,int sum,int cursum) 17 { 18 if(root==nullptr) 19 return false; 20 cursum+=root->val; 21 //如果此时节点为叶子节点,则判断当前的和是否等于要求的和,如果当前的和等于要求的和,则找到一条路径,否则则没有找到 22 if(root->left==nullptr&&root->right==nullptr) 23 { 24 return cursum==sum; 25 } 26 else 27 return isPathSum(root->left,sum,cursum)||isPathSum(root->right,sum,cursum); 28 } 29 };
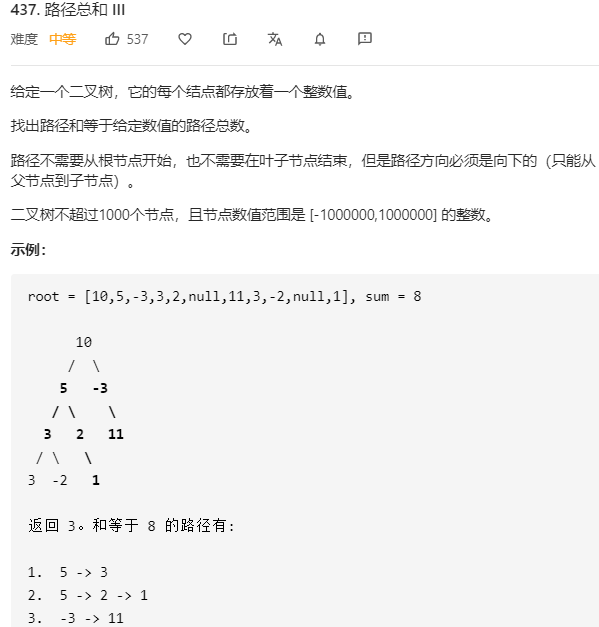
- 问题分析
首先先序递归遍历每个节点
以每个节点作为起始节点DFS寻找满足条件的路径
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode() : val(0), left(nullptr), right(nullptr) {} 8 * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} 9 * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} 10 * }; 11 */ 12 class Solution { 13 public: 14 int ans=0; 15 void dfs(TreeNode* root,int sum) 16 { 17 if(root==nullptr) 18 return; 19 sum-=root->val; 20 if(sum==0) 21 ++ans; 22 dfs(root->left,sum); 23 dfs(root->right,sum); 24 } 25 int pathSum(TreeNode* root, int sum) { 26 if(root==nullptr) 27 return ans; 28 dfs(root,sum); 29 pathSum(root->left,sum); 30 pathSum(root->right,sum); 31 return ans; 32 33 } 34 };
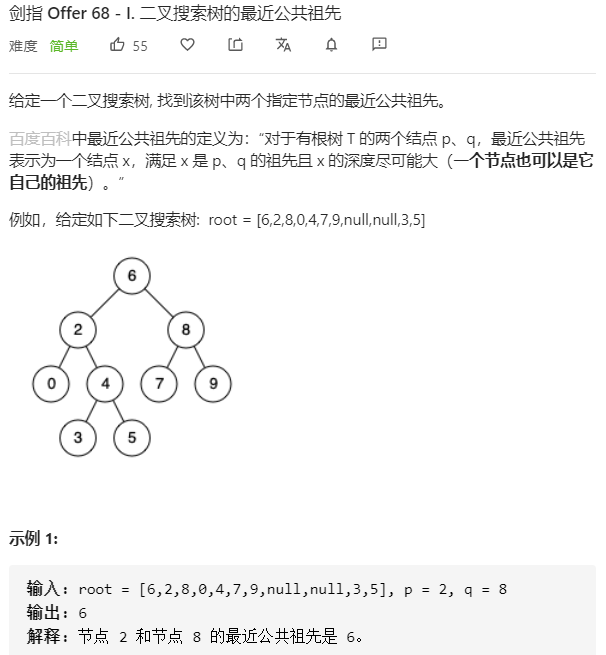
- 问题分析
二叉搜索树特性
若root->val<p->val,则p是root的右子树节点
若root->val>p->val,则q是root的左子树节点
若root->val=p->val,则q和root指向同一个节点
因此我们可以采用递归的方式找到最近的公共祖先
循环搜索,当root为空时直接跳出搜索
1. p,q都在root右子树节点时,则遍历至root->right
2. p,q都在root左子树节点时,则遍历至root->left
3. 否则,找到了最近的公共祖先
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) { 13 /* 14 二叉搜索树, 15 若root->val<p->val,p在root的右子树节点 16 若root->val>p->val,p在root的左子树节点 17 若root->val==p->val,p和root指向同一个节点 18 19 采用递归的方法找到最近的公共祖先 20 循环搜索,当root为空时跳出搜索 21 1. p,q都在root右子树节点时,则遍历至root->right 22 2. p,q都在root左子树节点时,则遍历至root->left 23 3. 否则,找到了最近公共祖先 24 */ 25 while(root!=nullptr) 26 { 27 //如果p,q都在root右子树节点,遍历至root->right 28 if(p->val>root->val&&q->val>root->val) 29 root=root->right; 30 else if(p->val<root->val&&q->val<root->val) 31 root=root->left; 32 else 33 break; 34 } 35 return root; 36 } 37 };
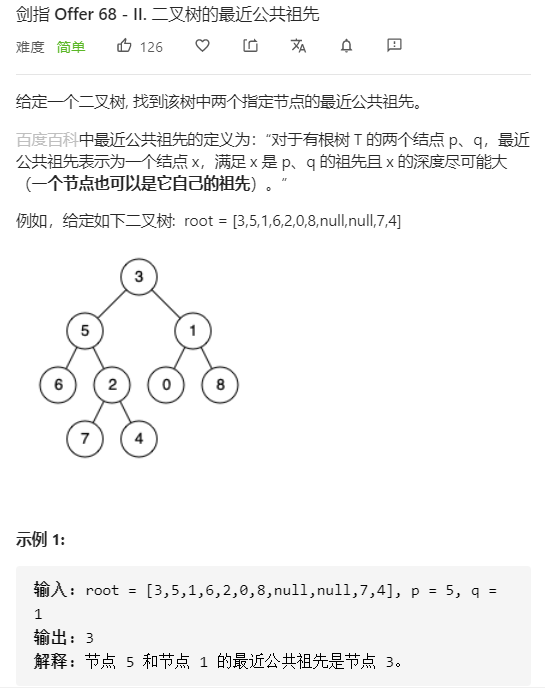
- 问题分析
首先明确祖先的定义
若节点p在root的左子树或右子树中,则root是p的祖先
最近公共祖先的定义
设节点root为节点p,q的某公共祖先,若其左子节点root->left和右子节点root->right都不是p,q的公共祖先。则root是最近的公共祖先。
根据以上定义,若root是p,q的最近公共祖先,则只可能为以下情况之一:
1. p和q在root的子树中,且分列root的异侧(即左、右子树中)
2. p=root,且q在root的左子树或右子树中
3. q=root,且p在root的左子树或右子树中
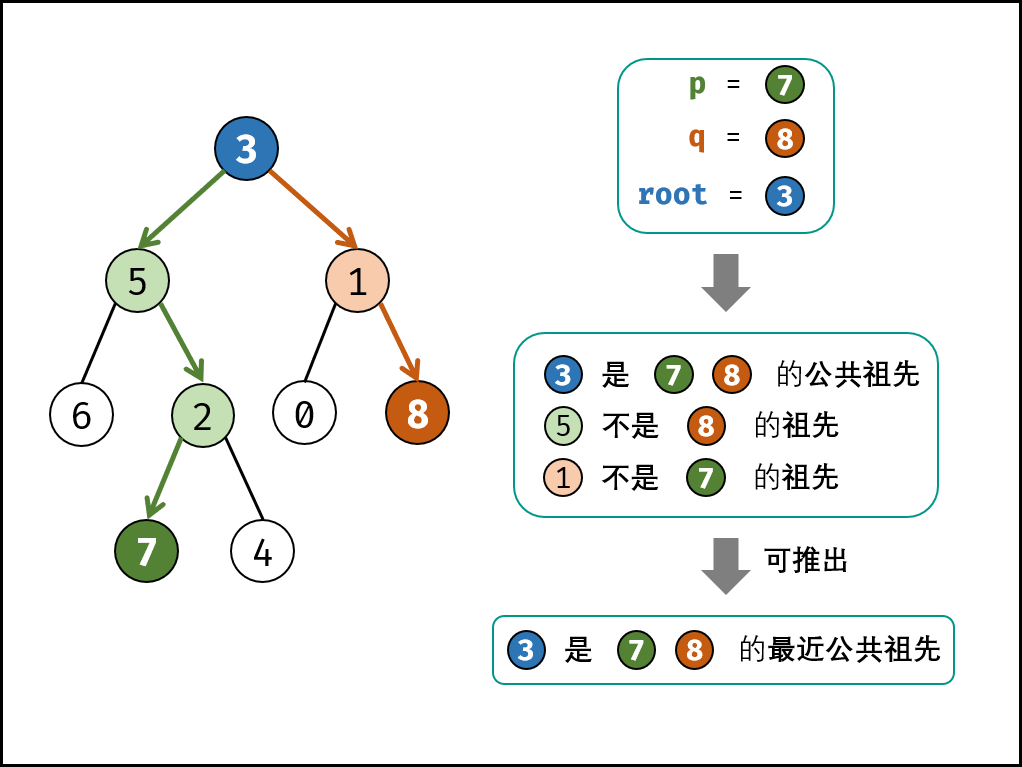
递归解析
1. 终止条件
1. 当越过叶节点,则返回值为nullptr
2. 当root等于p或q时,直接返回root
2. 递归工作
1. 开启递归左子节点,则返回值记为left
2. 开启递归右子节点,则返回值记为right
3. 返回值,根据left和right,可展开为四种情况
1. left和right都为空,则直接返回空
2. left和right都不为空,则p,q分布在root的异侧(分别为左子树和右子树),因此root为最公共祖先,返回root
3. left为空,right不为空:说明p,q都不在root的左子树中,直接返回right,具体可以分为两种情况
1. p,q其中一个在root的右子树中,此时right指向p
2. p,q都在right的右子树中,则此时的right指向最近公共祖先节点
4. left不为空,right为空,说明p,q都不在root的右子树中,直接返回left,具体可以分为两种情况
1. p,q其中一个在root的左子树中,此时left指向p
2. p,q都在left的左子树中,则此时的left指向最近公共祖先节点
- 代码参考
1 /** 2 * Definition for a binary tree node. 3 * struct TreeNode { 4 * int val; 5 * TreeNode *left; 6 * TreeNode *right; 7 * TreeNode(int x) : val(x), left(NULL), right(NULL) {} 8 * }; 9 */ 10 class Solution { 11 public: 12 TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) { 13 if(root==nullptr||root==p||root==q) 14 return root; 15 TreeNode* left=lowestCommonAncestor(root->left,p,q); 16 TreeNode* right=lowestCommonAncestor(root->right,p,q); 17 if(left==nullptr) 18 return right; 19 if(right==nullptr) 20 return left; 21 return root; 22 } 23 };

 浙公网安备 33010602011771号
浙公网安备 33010602011771号