

10操作手册
HDFS伪分布式集群搭建
tar -zxvf hadoop-2.7.7.tar.gz
echo $JAVA_HOME
/root/software/jdk1.8.0_221
#查看loaclhost
vim /root/software/hadoop-2.7.7/etc/hadoop/hadoop-env.sh
vim /root/software/hadoop-2.7.7/etc/hadoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoopData/temp</value>
</property>
vim /root/software/hadoop-2.7.7/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hadoopData/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoopData/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
vim /etc/profile
export HADOOP_HOME=/root/software/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
检测 Hadoop 环境变量是否设置成功,使用如下命令查看 Hadoop 版本:
hadoop version
#### 格式化文件系统
具体指令如下:
hdfs namenode -format
在本机上使用以下指令启动 NameNode 进程:
hadoop-daemon.sh start namenode
在本机上使用以下指令启动 SecondaryNameNode 进程:
hadoop-daemon.sh start secondarynamenode
脚本一键启动和关闭
start-dfs.sh
YARN伪分布式集群搭建
#配置环境变量yarn-env.sh
vim /root/software/hadoop-2.7.7/etc/hadoop/yarn-env.sh
/root/software/jdk1.8.0_221
#配置计算框架mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
#接着,打开 “mapred-site.xml” 文件进行修改:
vim /root/software/hadoop-2.7.7/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
#配置YARN系统yarn-site.xml
vim /root/software/hadoop-2.7.7/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
# 启动和关闭 YARN 集群
start-dfs.sh
#下面二选一
#单节点逐个启动和关闭
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
#脚本一键启动和关闭
start-yarn.sh
#http://localhost:8088
HDFS的shell命令——增删改查
# 常用命令:
# (1)ls:查看目录下文件或文件夹。
hadoop fs -cmd < args >
# 查看根目录下的目录和文件
hadoop fs -ls -R /
#(2)put:本地上传文件到HDFS。
# -f:覆盖目标文件。
# -p:保留访问和修改时间、权限。
# 将本地根目录下a.txt上传到HDFS根目录下
hadoop fs -put /a.txt /
#上传多个文件
hadoop fs -mkdir /merge
hadoop fs -put 1.txt 2.txt 3.txt /merge
#(3)get:HDFS文件下载到本地。
#格式:
hadoop fs -get < hdfs file > < local file or dir>
# 将HDFS根目录下a.txt复制到本地/root/目录下
hadoop fs -get /a.txt /root/
#(4)rm:删除文件/空白文件夹。
#格式
hadoop fs -rm [-skipTrash] <路径>
# 删除HDFS根目录下的a.txt
hadoop fs -rm /a.txt
#(5)mkdir:创建空白文件夹。
#格式:
hadoop fs -mkdir <hdfs路径>
# 在HDFS根目录下创建a文件夹
hadoop fs -mkdir /a
#(6)cp:复制。
#格式:
hadoop fs -cp < hdfs file > < hdfs file >
# 将HDFS根目录下的a.txt复制到HDFS/root/目录下
hadoop fs -cp /a.txt /root/
#(7)mv:移动。
#格式:
hadoop fs -mv < hdfs file > < hdfs file >
# 将HDFS根目录下a.txt移动到HDFS /root/目录下
hadoop fs -mv /a.txt /root/
#查看、追加、合并文本
#1. cat:查看文本内容命令。
#命令:
hadoop fs -cat [-ignoreCrc] <src>
# 查看根目录下的hadoop文件
hadoop fs -cat /hadoo.txt
#2. appendToFile:追加一个或者多个文件到hdfs指定文件中。
#命令:
hadoop fs -appendToFile <localsrc> ... <dst>
# 将当前文件*.xml追加到HDFS文件big.xml中。
hadoop fs -appendToFile *.xml /big.xml
#3. getmerge:合并下载多个文件。
#参数: 加上nl后,合并到local file中的hdfs文件之间会空出一行。
#命令:
hadoop fs -getmerge -nl < hdfs dir > < local file >
# 将HDFS目录下的log.*文件合并下载到本地log.sum文件中
hadoop fs -getmerge /aaa/log.* ./log.sum
#创建文件名命令
hadoop fs -touchz /abc.txt
实训
#shell命令实操:
#(1)查看HDFS根目录下结构。
#提示:因为我们根目录下没有问价或文件夹,因此不显示内容。
hadoop fs -ls -R /
#(2)在HDFS根目录下创建root文件夹。
hadoop fs -mkdir /root
#(3)在本地/root目录下创建hadoop.txt文件,添加如下内容:
#hadoop hdfs yarn
#hello hadoop
vi hadoop.txt
hadoop hdfs yarn
hello hadoop
#(4)将本地hadoop.txt上传到HDFS目录/root/下。
hadoop fs -put hadoop.txt /root/
#(5)将HDFS目录文件/root/hadoop.txt复制到根目录下并查看内容。
hadoop fs -get /root/hadoop.txt /
#(6)删除HDFS目录文件/root/hadoop.txt。
hadoop fs -rm /root/hadoop.txt
#(7)将HDFS目录文件/hadoop.txt迁移到HDFS目录/root/下并查看迁移是否成功。
hadoop fs -put /hadoop.txt /root/
#(8)将HDFS目录文件/root/hadoop.txt复制到本地根目录下并查看。
hadoop fs -get /root/hadoop.txt /
cat /hadoop.txt
#appendToFile命令实操:
#(1)在本地当前目录(/headless)下创建a.txt,b.txt,c.txt文件。
cd /headless
echo 123 > a.txt && echo 456 > b.txt && echo 789 > c.txt
#(2)分别添加内容123,456,789。
#(3)在HDFS根目录下创建abc.txt文件并查看。
#提示:创建文件名命令hadoop fs -touchz /abc.txt
hadoop fs -touchz /abc.txt
#(4)将本地a.txt,b.txt,c.txt追加到abc.txt文件。
hadoop fs -appendToFile *.txt /abc.txt
#(5)查看abc.txt文件。
hadoop fs -cat /abc.txt
#5. getmerge命令实操:
#(1)将刚才创建的a.txt,b.txt,c.txt文件上传到HDFS根目录。
hadoop fs -put a.txt b.txt c.txt /
#(2)将HDFS根目录下*.txt文件下载到本地/root/sum.txt。
hadoop fs -getmerge /*.txt /root/sum.txt
Linux下Eclipse连接Hadoop
1.Linux下Eclipse连接Hadoop:
(1)已上传hadoop-eclipse-plugin-2.7.7.jar,路径已设置为plugins目录。
(2)启动Eclipse,选择默认路径即可。
(3)关闭Welcome页面。
(4)点击Window->Preferences,左侧对话框选择Hadoop Map/Reduce选项。
(5)设置hadoop-2.7.7的安装路径。(实验环境hadoop-2.7.7的安装目录为:/root/software/hadoop-2.7.7)。
(6)点击Apply and Close。
(7)点击Window->Show View->Other,弹出Show View对话框,选中MapReduce Tools下的Map/Reduce Locations,点击Open。
(8)Eclipse底部出现Map/Reduce Locations窗口,点击其右边的蓝色小象图标。
(9)弹出New Hadoop locaiton...对话框,将Location name命名为hadoop。
(10)Map/Reduce(V2)Master下将Host修改为YARN集群主节点的IP地址或主机名localhost。
(11)DFS Master下将Host修改为HDFS集群主节点的IP地址或主机名localhost,Port修改为9000,将User name设置为搭建集群用户root。
2.测试连接
(1)选择File->New->Project->Map/Reduce Project->Next,弹出new MapReduce Project Wizard对话框。
(2)为Project name起名为Test,点击Finsh。
(3)弹出Open Associated Perspective对话框选择No。
(4)在左侧Project Explorer下出现DFS Locations列表栏和Test。
至此,我们Hadoop已经可以连接上Eclipse。后续可进行程序开发。
1. 创建项目:
(1)选择File->New->Project->Map/Reduce Project->Next,弹出new MapReduce Project Wizard对话框。Project name命名为:getFS,点击Finsh
(2)点击左侧getFS,在src下创建包结构:com.hongya.getfs。
(3)在包下创建测试类Test1,Test2。
2. 通过配置获取FileSystem对象:
(1)在Test1下使用new构造Configuration对象,获取配置信息类。
(2)通过set方法设置配置项,指定文件系统为HDFS,即fs.defaultFS参数的值为hdfs://localhost:9000。
(3)获取文件系统对象并打印URI地址。
package com.hongya.getfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
public class Test1 {
public static void main(String[] args) throws IOException {
Configuration conf=new Configuration();
//如果我们没有给conf设置文件系统,那么fileSystem默认获取的是本地文件系统的一个实例
//若是我们设置了“fs.defaultFS”参数,这表示获取的是该 URI 的文件系统的实例,就是我们需要的 HDFS 集群的一个 fs 对象
conf.set("fs.defaultFS", "hdfs://localhost:9000");
//获取文件系统对象
FileSystem fs=FileSystem.get(conf);
//打印URI地址
System.out.println(fs.getUri());
}
}
3. 直接获取FileSystem对象:
(1)在Test2中用new构造Configuration对象,获取配置信息类。
(2)通过get方法获取HDFS文件系统对象,设置URI为hdfs://localhost:9000,安装集群用户名为root。
(3)打印获取的文件系统URI。
package com.hongya.getfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
public class Test2 {
public static void main(String[] args) throws InterruptedException, URISyntaxException, IOException {
Configuration conf = new Configuration();
// 不需要配置“fs.defaultFS”参数,直接传入URI和用户身份,最后一个参数是安装Hadoop集群的用户,我的是“root”
FileSystem fs = FileSystem.get(new URI("hdfs://localhost:9000"), conf, "root");
System.out.println(fs.getUri());
}
}
上传查看文件操作
1.创建项目:
(1)项目名:Api_hdfs。
(2)包名:com.hongya.api_hdfs 。
(3)类:
- 创建目录类:MkDemo。
- 上传文件类:PutDemo。
- 遍历文件类:ListDemo。
2. 代码逻辑:
(1)在MkDemo类中使用单元测试方法。
(2)直接创建FileSystem对象。
(3)使用mkdirs方法在根目录下创建test文件夹。
(4)关闭资源。
(5)运行程序并在Eclipse中的DFS Locations列表栏查看文件夹创建是否成功。
创建目录类:MkDemo
package com.hongya.api_hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class MkDemo {
FileSystem fs = null;
// 每次执行单元测试前都会执行该方法
@Before
public void setUp() throws IOException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
// 不需要配置“fs.defaultFS”参数,直接传入URI和用户身份,最后一个参数是安装Hadoop集群的用户,我的是“root”
fs = FileSystem.get(new URI("hdfs://localhost:9000"), conf, "root");
}
// 单元方法:创建目录
@Test
public void mkdir() throws IllegalArgumentException, IOException {
boolean mkdirs = fs.mkdirs(new Path("/test"));
System.out.println(mkdirs);
}
// 每次执行单元测试后都会执行该方法,关闭资源
@After
public void tearDown() {
if (null != fs) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
1. 在本地/root目录下创建test.txt文件。添加如下内容:
HDFS_API
2. 代码逻辑:
(1)在PutDemo类中使用单元测试方法。
(2)创建FileSystem对象。
(3)使用copyFromLocalFile方法上传文件test.txt。
(4)关闭资源。
(5)运行程序并在Eclipse中的DFS Locations列表栏查看文件上传是否成功。
注:如果查看test文件夹没有文件,右击test选择Refresh刷新即可。
PutDemo类
package com.hongya.api_hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class PutDemo {
FileSystem fs = null;
// 每次执行单元测试前都会执行该方法
@Before
public void setUp() throws IOException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
// 不需要配置“fs.defaultFS”参数,直接传入URI和用户身份,最后一个参数是安装Hadoop集群的用户,我的是“root”
fs = FileSystem.get(new URI("hdfs://localhost:9000"), conf, "root");
}
//单元方法:上传文件
@Test
public void addFileToHdfs() throws IOException{
/*
* src:要上传的文件所在的本地路径
* dst:要上传到HDFS的目标路径
*/
Path src=new Path("/root/test.txt");
Path dst=new Path("/test");
//默认不删除本地源文件,覆盖HDFS同名文件
fs.copyFromLocalFile(src, dst);
}
// 每次执行单元测试后都会执行该方法,关闭资源
@After
public void tearDown() {
if (null != fs) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
遍历文件
任务二中我们已经将文件上传到HDFS,接下来我们演示通过代码来遍历出创建的文件夹以及上传的文件。
遍历文件代码逻辑:
(1)在ListDemo类中使用单元测试方法。
(2)获取FileSystem对象。
(3)通过listFiles方法获取RemoteIterator得到所有的文件或者文件夹。
(4)递归遍历并打印文件夹或文件路径。
(5)关闭资源。
(6)运行程序查看控制台输出。
package com.hongya.api_hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.FileNotFoundException;
import org.apache.hadoop.fs.FileStatus;
import java.io.FileNotFoundException;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.RemoteIterator;
public class ListDemo {
FileSystem fs = null;
// 每次执行单元测试前都会执行该方法
@Before
public void setUp() throws IOException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
// 不需要配置“fs.defaultFS”参数,直接传入URI和用户身份,最后一个参数是安装Hadoop集群的用户,我的是“root”
fs = FileSystem.get(new URI("hdfs://localhost:9000"), conf, "root");
}
//单元方法:查看目录信息,只显示该目录下的文件信息
@Test
public void listFiles() throws FileNotFoundException, IllegalArgumentException, IOException{
//使用迭代器递归获取该目录下的所有文件
RemoteIterator<LocatedFileStatus> listfile=fs.listFiles(new Path("/"), true);
while(listfile.hasNext()){
LocatedFileStatus fileStatus=listfile.next();
System.out.println("文件路径:"+fileStatus.getPath());
System.out.println("文件名称:"+fileStatus.getPath().getName());
System.out.println("块的大小:"+fileStatus.getBlockSize());
System.out.println("文件所有者:"+fileStatus.getOwner());
System.out.println("文件所属组:"+fileStatus.getGroup());
System.out.println("文件权限:"+fileStatus.getPermission());
System.out.println("副本个数:"+fileStatus.getReplication());
System.out.println("文件长度:"+fileStatus.getLen());
System.out.println("-----块的信息-----");
BlockLocation[] blockLocations=fileStatus.getBlockLocations();
for(BlockLocation bLocation:blockLocations){
System.out.println("块的长度:"+bLocation.getLength()+"\t块起始偏移量:"+bLocation.getOffset());
//块所在的DataNode节点
String[] hosts = bLocation.getHosts();
System.out.print("DataNode: ");
for(String str:hosts){
System.out.print(str+"\t");
}
System.out.println();
}
System.out.println("------------------------");
}
}
// 每次执行单元测试后都会执行该方法,关闭资源
@After
public void tearDown() {
if (null != fs) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
修改删除文件操作
1. 创建项目:
(1)项目名:Api_hdfs。
(2)包名:com.hongya.api_hdfs 。
(3)类:
- 下载文件类:GetDemo。
- 重命名目录文件类:ReDemo。
- 删除文件目录类:RmDemo。
2. 数据准备:
(1)在本地/目录下创建test.txt文件,添加内容如下:
copyTolocalfile()
rename()
delete()
(2)创建并上传test.txt文件到HDFS目录:/test
需求:将HDFS文件test.txt下载到本地/root目录。
3. 下载文件代码逻辑:
(1)在GetDemo类中使用单元测试方法。
(2)直接创建FileSystem对象。
(3)使用copyTolocalfile方法将test.txt文件下载到/root。
(4)关闭资源。
package com.hongya.api_hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class GetDemo {
FileSystem fs = null;
// 每次执行单元测试前都会执行该方法
@Before
public void setUp() throws IOException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
// 不需要配置“fs.defaultFS”参数,直接传入URI和用户身份,最后一个参数是安装Hadoop集群的用户,我的是“root”
fs = FileSystem.get(new URI("hdfs://localhost:9000"), conf, "root");
}
// 单元方法:下载文件
@Test
public void downLoadFileToLocal() throws IOException {
/*
* src:要下载的文件所在的HDFS路径 dst:要下载到本地的目标路径
*/
Path src = new Path("/test/test.txt");
Path dst = new Path("/root/");
// 默认不删除HDFS源路径的文件,覆盖本地同名文件
fs.copyToLocalFile(src, dst);
}
// 每次执行单元测试后都会执行该方法,关闭资源
@After
public void tearDown() {
if (null != fs) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
本节任务针对任务一中的HDFS文件****/test/test.txt进行操作。
需求1:将test.txt文件重命名为tmp.txt。
需求2:将test文件夹重命名为tmp。
代码逻辑:
(1)在ReDemo类中使用单元测试方法。
(2)直接创建FileSystem对象。
(3)使用rename方法重命名目录文件。
(4)关闭资源。
(5)运行程序并在Eclipse中的DFS Locations列表栏查看是否修改成功。
package com.hongya.api_hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class ReDemo {
FileSystem fs = null;
// 每次执行单元测试前都会执行该方法
@Before
public void setUp() throws IOException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
// 不需要配置“fs.defaultFS”参数,直接传入URI和用户身份,最后一个参数是安装Hadoop集群的用户,我的是“root”
fs = FileSystem.get(new URI("hdfs://localhost:9000"), conf, "root");
}
// 单元方法:重命名文件或者文件夹
@Test
public void renameFileOrDir() throws IllegalArgumentException, IOException {
//重命名文件
fs.rename(new Path("/test/test.txt"), new Path("/test/tmp.txt"));
//重命名文件夹
fs.rename(new Path("/test"), new Path("/tmp"));
}
// 每次执行单元测试后都会执行该方法,关闭资源
@After
public void tearDown() {
if (null != fs) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
需求1:删除任务二中修改后文件tmp.txt。
需求2:删除任务二中修改后文件夹tmp。
代码逻辑:
(1)在RmDemo类中使用单元测试方法。
(2)直接创建FileSystem对象。
(3)使用delete方法删除目录文件。
(4)关闭资源。
(5)运行程序并在Eclipse中的DFS Locations列表栏查看目录文件删除是否成功。
package com.hongya.api_hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class RmDemo {
FileSystem fs = null;
// 每次执行单元测试前都会执行该方法
@Before
public void setUp() throws IOException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
// 不需要配置“fs.defaultFS”参数,直接传入URI和用户身份,最后一个参数是安装Hadoop集群的用户,我的是“root”
fs = FileSystem.get(new URI("hdfs://localhost:9000"), conf, "root");
}
//单元方法:删除文件或者文件夹
@Test
public void deleteFileOrDir() throws IllegalArgumentException, IOException{
//删除文件,第二参数:是否递归,若是文件或者空文件夹时可以为false,若是非空文件夹则需要为true
fs.delete(new Path("/tmp/tmp.txt"),false);
//删除文件夹
fs.delete(new Path("/tmp"), true);
}
// 每次执行单元测试后都会执行该方法,关闭资源
@After
public void tearDown() {
if (null != fs) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
小文件合并
1. 创建项目:
(1)项目名:Api_hdfs。
(2)包结构:com.hongya.api_hdfs。
(3)合并文件实现类:MergeDemo
2. 数据准备:
(1)在本地/root目录下创建目录input。
(2)在input目录下创建a.txt文件,添加如下内容:
123
(3)在input目录下创建b.txt文件,添加如下内容:
456
(4)在input目录下创建c.txt文件,添加如下内容:
789
3. 代码逻辑:
(1)获取HDFS文件系统对象FileSystem。
(2)在HDFS根目录创建merge.txt文件。
(3)获取本地文件系统。
(4)获取本地文件系统文件列表集合。
(5)迭代遍历文件列表获取数据并进行数据拷贝。
(6)关闭资源。
package com.hongya.api_hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Test;
public class MergeDemo {
FileSystem fs = null;
// 每次执行单元测试前都会执行该方法
// 单元方法:下载文件
@Test
public void mergeFile() throws Exception{
//?????????
FileSystem fileSystem = FileSystem.get(new URI("hdfs://localhost:9000"), new Configuration(),"root");
//????
FSDataOutputStream outputStream = fileSystem.create(new Path("/merge.txt"));
//????????
LocalFileSystem local = FileSystem.getLocal(new Configuration());
//????????????????
FileStatus[] fileStatuses = local.listStatus(new Path("/root/input/"));
//????????
for (FileStatus fileStatus : fileStatuses) {
//????
FSDataInputStream inputStream = local.open(fileStatus.getPath());
//????
IOUtils.copy(inputStream,outputStream);
//???????
IOUtils.closeQuietly(inputStream);
}
//????
IOUtils.closeQuietly(outputStream);
local.close();
fileSystem.close();
}
// 每次执行单元测试后都会执行该方法,关闭资源
@After
public void tearDown() {
if (null != fs) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
Map端程序编写
1. MapReduce项目创建:
(1)项目名:MRDemo。
(2)包结构:com.hongya.mrdemo。
(3)Map端程序业务类:WordCountMapper。
2. 需求介绍:
按照给定的文本,内容如下所示,对其进行WordCount统计,完成Map端程序代码。
hello,hadoop
hello,word
hello,hdfs
3. Map端编码步骤:
(1)定义的WordCountMapper类继承Mapper,设置泛型类型。
(2)重写map方法:
- 获取每一行数据并转换成String。
- 按逗号切分每行数据获取单词 。
- 遍历数组,获取每个单词。
(3)将单词作为key,value记为1写入上下文。
4.代码样例:
package com.hongya.mrdemo;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Mapper;
//(1)定义的WordCountMapper类继承Mapper,设置泛型类型。
public class WordCountMapper extends Mapper<LongWritable, Text, Text, Writable>{
//map方法的生命周期: 框架每传一行数据就被调用一次
//key : 这一行的起始点在文件中的偏移量
//value: 这一行的内容
/*
(2)重写map方法
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到一行数据转换为string
String line = value.toString();
//将这一行切分出各个单词
String[] words = line.split(",");
//遍历数组,输出<单词,1>
for(String word:words){
//(3)将单词作为key,value记为1写入上下文。
context.write(new Text(word), new LongWritable (1));
}
}
}
Reduce端程序编写
回顾1.1 Map端程序编写例一,我们对文本数据做WordCount实现了Map端程序,接着针对它实现Reduce端程序业务处理。文本数据如下所示:
hello,hadoop
hello,word
hello,hdfs
1. MapReduce项目创建:
(1)项目名:MRDemo。
(2)包结构:com.hongya.mrdemo。
(3)Reduce端程序业务类:WordCountReducer。
2. Reduce端编程步骤:
(1)定义的WordCountReducer类继承Reducer,设置泛型类型。
(2)重写reduce方法,对每个单词数求和统计。
(3)收集统计结果kv写入上下文。
package com.hongya.mrdemo;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text,LongWritable,Text,LongWritable> {
//生命周期:框架每传递进来一个kv 组,reduce方法被调用一次
@Override
protected void reduce(Text key, Iterable<LongWritable > values, Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = 0;
//遍历这一组kv的所有v,累加到count中
for(LongWritable value:values){
count += value.get();
}
//(3)收集统计结果kv写入上下文
context.write(key, new LongWritable (count));
}
}
Driver端程序编写
1. MapReduce创建项目:
(1)项目名:MRDemo。
(2)包结构:com.hongya.mrdemo。
(3)Driver端程序业务类:WordCountDriver。
2. 准备工作:
(1)点击按钮上传前两节Map和Reduce端代码,上传路径为:/root/eclipse-workspace/MRDemo/src/com/hongya/。
上传代码
(2)将其进行解压删除压缩包。
(3)在/root目录下创建wordcount.txt文件,添加我们例一单词统计数据,如下所示:
hello,hadoop
hello,word
hello,hdfs
3. Driver端代码逻辑:
(1)在main方法中创建job对象。
(2)指定job所在的jar包。
(3)指定Mapper类为例一的WordCountMaaper,Reducer类为例一的WordCountReducer。
(4)指定MapTask和ReduceTask的输出key-value类型。若两者输出类型一致,MapTask输出类型可省略。
(5)设置输入路径为/root/wordcount.txt,输出路径为/root/output1。
(6)将job提交给yarn集群。
4. 代码示例:
package com.hongya.mrdemo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver{
public static void main(String[] args) throws Exception {
//创建配置文件
Configuration conf = new Configuration();
//conf.set("mapreduce.framework.name", "local");// 指定MapReduce运行时框架为本地作业运行器
//conf.set("fs.defaultFS", "file:///"); // 获取本地文件系统实例
// 1:创建job对象
Job job = Job.getInstance(conf);
//2:指定job所在的jar包。
job.setJarByClass(WordCountDriver.class);
//3:指定 mapper 类和 reducer 类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//4.1:指定 MapTask 的输出key-value类型(可以省略)
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//4.2:指定 ReduceTask 的输出key-value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//5:设置输入输出路径
Path inPath=new Path("/root/wordcount.txt");
Path outpath=new Path("/root/output1");
FileSystem fs=FileSystem.get(conf);
//判断输出路径是否存在,存在将删除目录
if(fs.exists(outpath)){
fs.delete(outpath,true);
}
FileInputFormat.setInputPaths(job,inPath);
FileOutputFormat.setOutputPath(job, outpath);
//6:代码提交yarn集群,等待运行完反馈信息,客户端退出
boolean bl = job.waitForCompletion(true);
System.exit(bl?0:1);
}
}
至此,我们整个例一单词统计涉及到的程序已经编写完毕,接下来将运行程序查看我们处理结果。
程序打包
程序打包,如下示例所示。
右键项目MyMR,选择Export
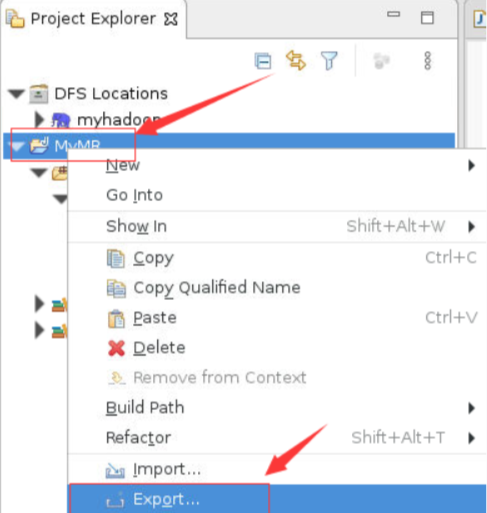
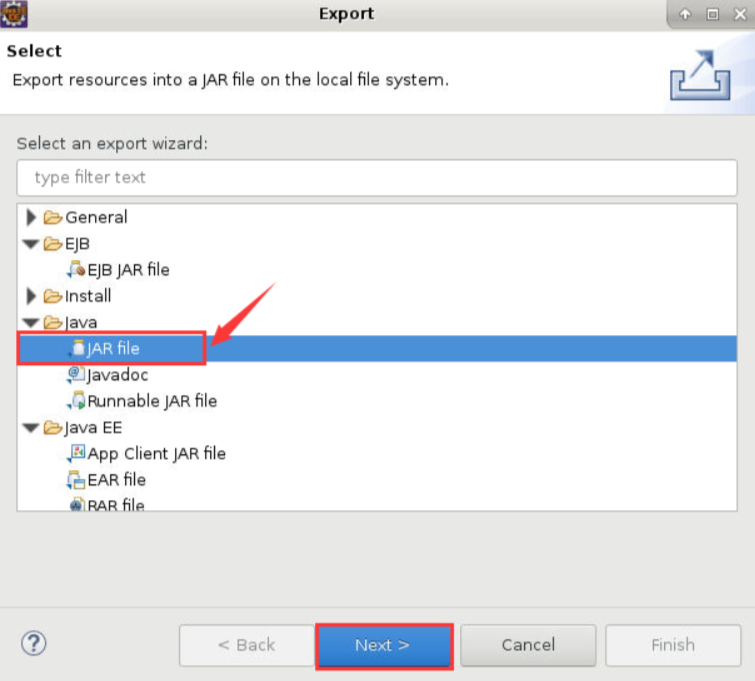
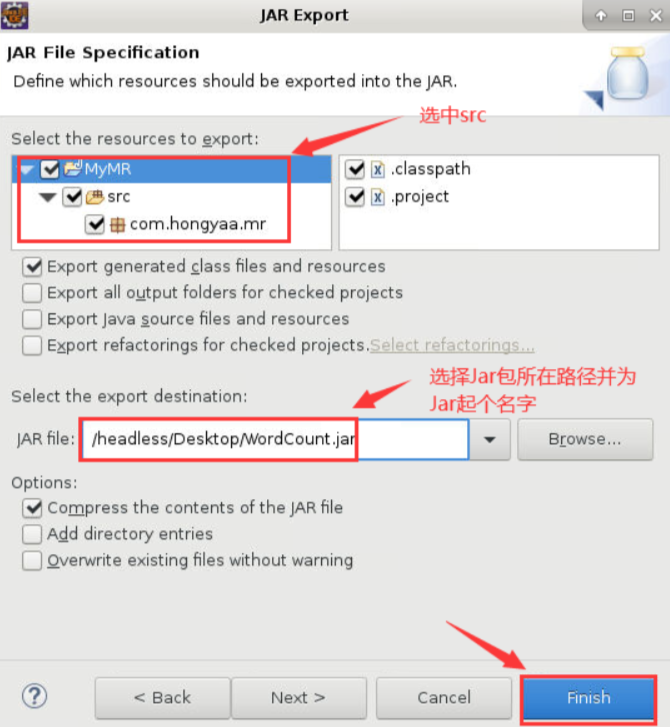
在弹出的对话框中,勾选MyMR项目中的src,然后在JAR file中选择保存的路径名(包含最终的jar包的名字),之后点击Finish
(3)jar包上传Linux,使用命令运行jar包。
hadoop jar WordCount.jar com.hongya.mrdemo.WordCountDriver
解释说明:
hadoop jar:用来执行一个Hadoop的jar包程序。WordCount.jar:执行的jar包的名字。com.hongyaa.mr.WordCount:包名.类名,此处的类名为我们主程序类的名字。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix