

MySQL(二):快速理解MySQL数据库索引
索引
基本概念:索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。
数据结构
- Tree 指的是 Balance Tree,也就是平衡树。平衡树是一颗查找树,并且所有叶子节点位于同一层。
- B+ Tree 是基于 B Tree 和叶子节点顺序访问指针进行实现,它具有 B Tree 的平衡性,并且通过顺序访问指针来提高区间查询的性能。
- 在 B+ Tree 中,一个节点中的 key 从左到右非递减排列,如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,且不为 null,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。
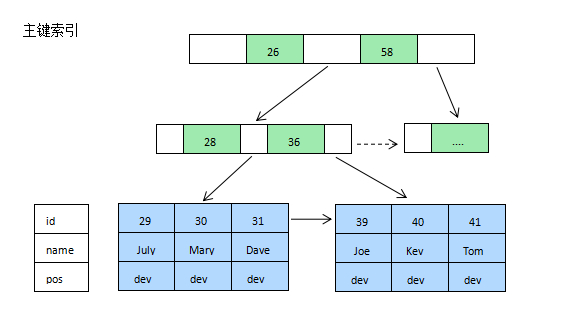
基本原理
- 进行查找操作时,首先在根节点进行二分查找,找到一个 key 所在的指针,然后递归地在指针所指向的节点进行查找。直到查找到叶子节点,然后在叶子节点上进行二分查找,找出 key 所对应的 data。
- 插入删除操作会破坏平衡树的平衡性,因此在进行插入删除操作之后,需要对树进行分裂、合并、旋转等操作来维护平衡性。
红黑树
红黑树等平衡树也可以用来实现索引,但是文件系统及数据库系统普遍采用 B+ Tree 作为索引结构,这是因为使用 B+ 树访问磁盘数据有更高的性能。
- B+ 树有更低的树高:平衡树的树高 O(h)=O(logdN),其中 d 为每个节点的出度。红黑树的出度为 2,而 B+ Tree 的出度一般都非常大,所以红黑树的树高 h 很明显比 B+ Tree 大非常多。
- 磁盘访问原理:操作系统一般将内存和磁盘分割成固定大小的块,每一块称为一页,内存与磁盘以页为单位交换数据。数据库系统将索引的一个节点的大小设置为页的大小,使得一次 I/O 就能完全载入一个节点。
如果数据不在同一个磁盘块上,那么通常需要移动制动手臂进行寻道,而制动手臂因为其物理结构导致了移动效率低下,从而增加磁盘数据读取时间。B+ 树相对于红黑树有更低的树高,进行寻道的次数与树高成正比,在同一个磁盘块上进行访问只需要很短的磁盘旋转时间,所以 B+ 树更适合磁盘数据的读取。 - 磁盘预读特性:为了减少磁盘 I/O 操作,磁盘往往不是严格按需读取,而是每次都会预读。预读过程中,磁盘进行顺序读取,顺序读取不需要进行磁盘寻道,并且只需要很短的磁盘旋转时间,速度会非常快。并且可以利用预读特性,相邻的节点也能够被预先载入。
索引分类
B+树索引
- 是大多数 MySQL 存储引擎的默认索引类型。
- 因为不再需要进行全表扫描,只需要对树进行搜索即可,所以查找速度快很多。
- 因为 B+ Tree 的有序性,所以除了用于查找,还可以用于排序和分组。
- 可以指定多个列作为索引列,多个索引列共同组成键。
- 适用于全键值、键值范围和键前缀查找,其中键前缀查找只适用于最左前缀查找。如果不是按照索引列的顺序进行查找,则无法使用索引。
- InnoDB 的 B+Tree 索引分为聚簇索引(主索引)和非聚簇索引(辅助索引)。
- 唯一索引:主键就是一种特殊的唯一索引,唯一索引允许null值,但主键列不允许为null值,一张表最多建议一个主键
哈希索引
- 哈希索引能以O(1)时间进行查找,但是失去了有序性特点InnoDB
- 存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree 索引具有哈希索引的一些优点,比如快速的哈希查找。
全文索引
- MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。
- 查找条件使用 MATCH(clo1,clo2..) AGAINST(value),而不是普通的 WHERE。全文索引使用倒排索引实现,它记录着关键词到其所在文档的映射。
- InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引。
FULLTEXT (clo1,clo2)只有建立的全文索引的列可以进行全文索引
索引优化
独立的列
进行查询时,索引列不能是表达式的一部分,也不能是函数的参数,否则无法使用索引
多列索引
在需要使用多个列作为条件进行查询时,使用多列索引比使用多个单列索引性能更好。
列如下面的语句中可以将actor_id和film_id设置多列索引
SELECT film_id, actor_ id FROM sakila.film_actor
WHERE actor_id = 1 AND film_id = 1;
索引列的顺序
索引的选择性是指:不重复的索引值和记录总数的比值。最大值为 1,此时每个记录都有唯一的索引与其对应。选择性越高,每个记录的区分度越高,查询效率也越高。
让选择性最强的索引列放在最前面
输入语句:
SELECT COUNT(DISTINCT addr_id)/COUNT(*) AS addr_id_selectivity,
COUNT(DISTINCT user_id)/COUNT(*) AS user_id_selectivity,
COUNT(*)
FROM user_address;
结果:
addr_id_selectivity:1.0000
user_id_selectivity:0.1250
count(*):64
从上述结果分析:主键是唯一的,user_id会有重复,所以写sql语句时,主键应该放在最前面
这样可以逐个分析对应的索引
前缀索引
- 对于 BLOB、TEXT 和 VARCHAR 类型的列,必须使用前缀索引,只索引开始的部分字符。
- 前缀长度的选取需要根据索引选择性来确定。某些列,一般是字符串类型,很长,全部作为索引大大增加存储空间,索引也需要维护,对于长字符串,又想作为索引列,一个可取的办法就是取前一部分(前缀),代表一整列作为索引串。
- 如何确保这个前缀能代表或大致代表这一列?所以mysql中有个概念是索引的选择性,是指索引中不重复的值的数目(也称基数)与整个表该列记录总数(#T)的比值,比如一个列表(1,2,2,3),总数是4,不重复值数目为3,选择性为3/4,因此选择性范围是[1/#T, 1],这个值越大,表示列中不重复值越多,越适合作为前缀索引,唯一索引(UNIQUE KEY)的选择性是1。
MySQL性能优化神器Explain使用分析
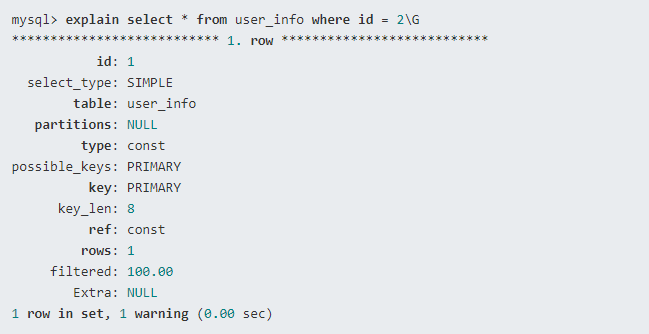
- Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。
- select_type : 查询类型,有简单查询、联合查询、子查询等
- key : 使用的索引
- rows : 扫描的行数
总结
- 数据库只做两件事情:存储数据、检索数据。而索引是在你存储的数据之外,额外保存一些路标(一般是B+树),以减少检索数据的时间。所以索引是主数据衍生的附加结构。
- 一张表可以建立任意多个索引,每个索引可以是任意多个字段的组合。索引可能会提高查询速度(如果查询时使用了索引),但一定会减慢写入速度,因为每次写入时都需要更新索引,所以索引只应该加在经常需要搜索的列上,不要加在写多读少的列上。
- 多使用explain对语句进行索引分析,任何理论都是建立在实际的分析基础上,explain语句关注那几个关键词即可。盲目的加索引并不是好的,有时候索引反而成为拖慢我们系统运行速度的源头.优化索引其实就两件事,第一找到区别度大的列,第二看生产的查询场景是否有用到这个列,加上索引用explain分析,看是否会比不加上索引性能提升更快

