Docker(二):理解容器编排工具Kubernetes内部工作原理
一、Kubernetes是什么
要说到Docker就不得不说说Kubernetes。当Docker容器在微服务的环境下数量一多,那么统一的,自动化的管理自然少不了。而Kubernetes就是一个这样的工具,它不仅仅提供了健康检查和自修复,还有自动扩容缩容,以及服务发现和负载均衡等等功能。总的来说它使我们对于大量的Docker容器管理更加的方便。
二、Kubernetes整体架构图及对应功能分析
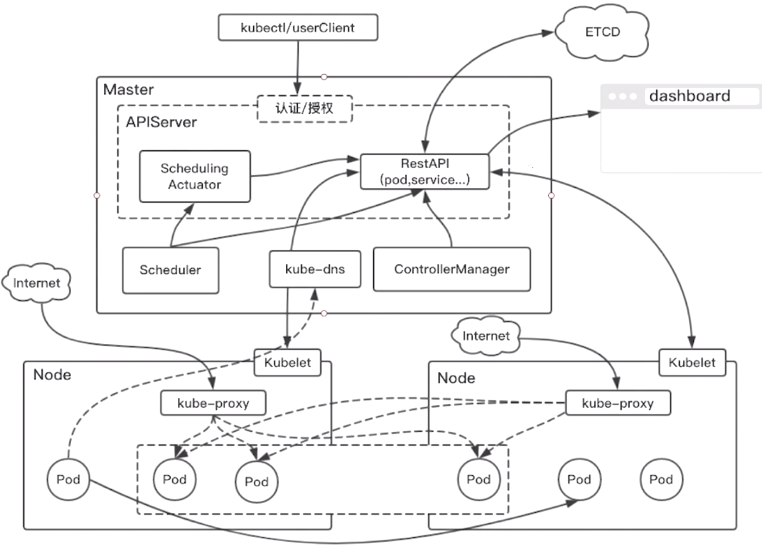
1、kubectl:这是相当于用户客户端一样,也是我们较常使用的命令行工具,通过这个工具可以发起对应的请求到master节点中,当然自己开发的客户端同样可以通过HTTP协议发起对应的RESTAPI请求访问APIServer。
2、Master:Master节点是整个Kubernetes的核心节点,主要职责是负责调度,即应用放在哪里运行,同样为了高可用可运行多个Master。而Master中主要有APIServer,ControllerManager,Scheduler,Etcd,Kube-dns。对应的职责分别如下:
2.1、APIServer:提供了资源操作的唯一入口,注意其他节点是无法被外面请求操作的(不是说内部运行的容器无法被访问,而是说无法通过发请求的方式直接操作Node),只有Master节点才能接受外面的请求进行操作Node节点,其中主要提供了认证、授权、访问控制整个集群。而dashboard是提供了一个展示界面。
2.2、Scheduler:负责资源的调度,根据一定的调度策略,将对应Node上面的Pod运行起来。
2.3、ControllerManager:负责维护集群的状态,比如故障检测,扩缩容,滚动更新。在Pod运行起来,就由ControllerManager负责管理其状态
2.4、ETCD:用于一致性存储,保存pod,service等等的Kubernetes状态。这里可以理解为MySQL在我们日常项目中的存储作用,只要是用于存取Kubernetes中所有的持久化数据。
2.5、Kube-dns:DNS组件负责整个集群的DNS服务。使得内部Pod相互之间可通过名字访问。有了这个功能就不需要写繁琐的IP地址,通过服务的名字即可访问对方。
3、Node:理解为分支节点,主要作用在于提供Kubernetes运行时的环境,以及维护Pod。内部主要有Kubblet,kube-proxy,docker等
3.1、Kubblet:通过Master发送的请求到Node分支上的Kubblet,然后就由Kubblet负责维护当前节点上容器的生命周期,也负责维护当前节点的数据卷及网络。
3.2、Kube-proxy:提供内部的服务发现和负载均衡。可以在图上看见虚线框起来的三个框,可以认为这三个Pod算是一个服务,即service,而外部可通过Kube-proxy暴露的端口来进行统一的访问。并且默认是使用轮询的负载均衡策略来访问。
三、Pod详解
Pod作为Kubernetes的核心资源,这里单独拿出来解释。在Kubernetes集群中,Pod是所有业务类型的基础,它是一个或多个容器的组合,也就是Pod内部可以有多个Docker容器存在,不是一个Pod代表一个容器,注意区分概念。在其中的这些容器共享存储、网络和命名空间,以及如何运行的规范。在Pod中,所有容器都被同一安排和调度,并运行在共享的上下文中。对于具体应用而言,Pod是它们的逻辑主机,Pod包含业务相关的多个应用容器。这些容器可以通过localhost发现彼此。每一个Pod有自己的一个IP地址。
1、Pod工作方式
在Kubernetes中一般不会直接创建一个独立的Pod,这是因为Pod是临时存在的一个实体。当直接创建一个独立的Pod时,如果缺少资源或者所被调度到的Node失败,则Pod会直接被删除。这里需要注意的是,重起Pod和重起Pod中的容器不是一个概念,Pod自身不会运行,它只是容器所运行的一个环境。Pod本身没有自愈能力,如果Pod所在的Node失败,或者如果调度操作本身失败,则Pod将会被删除;同样的,如果缺少资源,Pod也会失败。Kubernetes使用高层次的抽象,即控制器来管理临时的Pod。通过控制器能够创建和管理多个Pod,并在集群范围内处理副本、部署和提供自愈能力。
2、重启策略
Pod既然内部运行着容器,那么免不了会因为异常等原因导致其终止退出,Pod支持三种重启策略,需要在配置文件中通过restartPolicy字段设置重启策略:
Always:只要退出就会重启
OnFailure:只有在失败退出(即exit code不等于0时),才会重启
Never:只要退出就不再重启
3、镜像拉取策略
前一篇博客有讲容器与镜像的概念,在Kubernetes中运行容器时,需要为容器获取镜像。Pod中容器的镜像有三个来源,即Docker公共镜像仓库、私有镜像仓库和本地镜像。当在内网使用的Kubernetes场景下,就需要搭建和使用私有镜像仓库。Pod支持三种镜像拉取策略,在配置文件中通过imagePullPolicy字段设置镜像拉取策略:
Always:不管本地是否存在镜像都会进行一次拉取
Never:不管本地是否存在镜像都不会进行拉取
IfNotPresent:仅在本地镜像不存在时,才会进行镜像拉取
这里有需要注意的点:镜像拉取策略的默认值IfNotPresent,但:lastest标签的镜像默认为Always。所以生产环境中避免使用:lastest标签。还有就是拉取镜像时docker会进行校验,如果镜像中的MD5码没有变,则不会拉取镜像数据。
4、资源限制
Kubernetes通过cgroups来限制容器的CPU和内存等计算资源,在创建Pod时,可以为Pod中的每个容器设置资源请求(request)和资源限制(limit),资源请求是容器需要的最小资源要求,资源限制为容器所能使用的资源上限。CPU的单位是核(core),内存(Memory)的单位是字节(byte)。
5、终止Pod
在集群中,Pod代表运行的进程,但不再需要这些进程时,如何优雅的终止这些进程是非常重要的。当用户请求删除一个Pod时,Kubernetes将会发送一个终止信号给每个容器,一旦过了优雅期,就会发送kill信号,从而通过APIServer删除Pod。通常默认的优雅退出时间为30s。缓慢关闭的Pod依然可以对外继续服务,直到负载均衡器将其移除,当超过优雅的退出时间,在Pod中任何正在运行的进程都会被kill。
四、Pod的生命周期
1、Pending
Pod已经被Kubernetes系统接受,但是还有一个或者多个容器镜像未被创建。这包括Pod正在被调度和从网络上下载镜像的时间。
2、Running
Pod已经被绑定到了一个Node,所有容器已经被创建,至少有一个容器在运行
3、Succeeded
在Pod中所有容器已经被成功停止,并且不再重启
4、Failed
在Pod中所有容器已经被终止,并且至少有一个容器是非正常终止的,即容器以非零状态退出或者被系统强行终止的。
5、Unknown
Pod在某些原因下不能被获取。通常是网络问题。
五、service图
前面有说到Docker目前在微服务架构运行的很广泛,而Kubernetes作为编排Docker容器的强大工具自然是我们的首选。而Kubernetes又是怎么和微服务结合起来的呢?
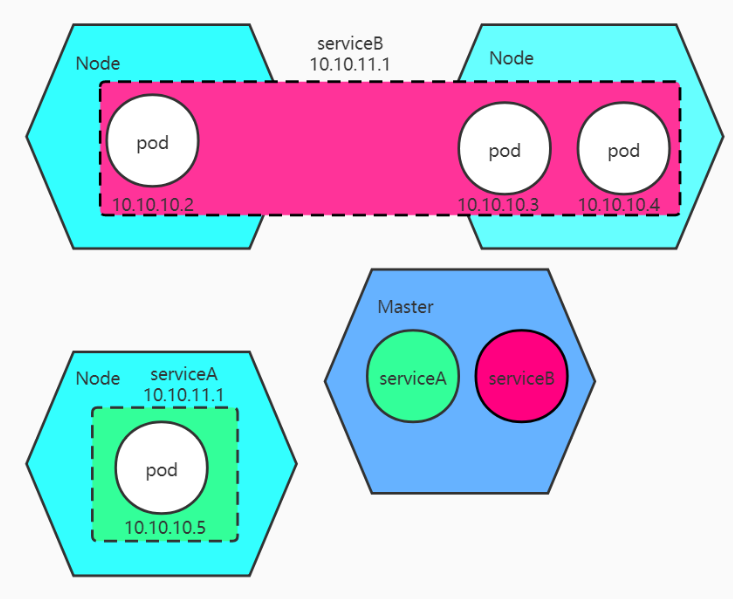
上面有说到Pod拥有自己的IP地址,实际上在Pod外面还包裹着一层Service,这个Service是逻辑存在的,在最上面的架构图中就类似kube-proxy串在一起的三个Pod,而service的IP是由kube-proxy给我们提供。这就是与微服务之间能够连起来了。其中同一个service的Pod应该是相同的,kube-proxy会自动给我们做负载均衡,默认使用轮询。同样与Docker不相同的是Pod之间是可以通过名字直接访问的,Node同样也是,这就为我们的服务调用提供了很便利的方式。
六、总结
Kubernetes是一个容器编排及其自动化管理的工具。随着业务增长Docker容器越来越多,如果需要每一个自己手动管理,那么将会翻倍的增加我们的工作量。所以Kubernetes是我们在学习Docker中需要进阶的知识。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号