

Dubbo(一):Dubbo运行原理
前言:
在开始入门Javaweb时,学的基本都是MVC开发模式,一个项目基本上就是model,view,controller三层。但是随着系统的服务逐渐加多,SOA模式更加适合目前项目开发。而SOA模式在Java开发过程中基本上是Dubbo和SpringCloud的天下。所以今天来看看Dubbo中的运行原理。
一、SOA模式
首先简单介绍一下SOA模式,这对我们后面理解Dubbo很有帮助。
SOA模式是什么?
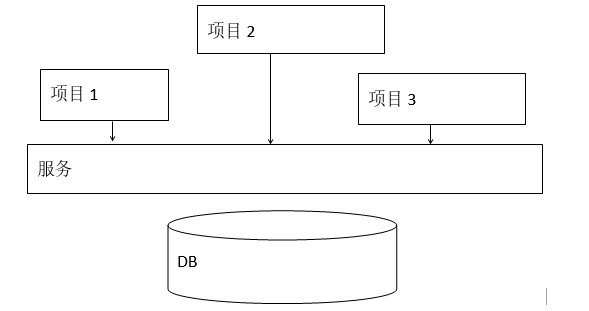
SQA(Service-Oriented Architecture)即面向服务架构,它将应用程序的不同功能单元(这里就理解为服务)进行了拆分。在这种架构下项目不会直接和数据库进行交互,而是通过调用不同服务的接口来访问数据库。
模式优点在哪?
这样最直接的好处就是解决代码冗余,如果多个项目同时都要访问数据库同一张表。比如用户表的访问。我们可以直接调用用户服务里面的接口进行开发,而不需要每个项目都去写一遍用户表的增删改查。除了这个,SOA能带给我们的好处就是能够让开发者以更迅速、更可靠、更具重用性架构整个业务系统。较之以往MVC开发模式,以SOA架构的系统能够更加从容地面对业务的急剧变化。
SOA示意图:
二、Dubbo基本组成
聊完了SOA,现在来看看Dubbo内部架构,相信大家多多少少看过下面这幅图:
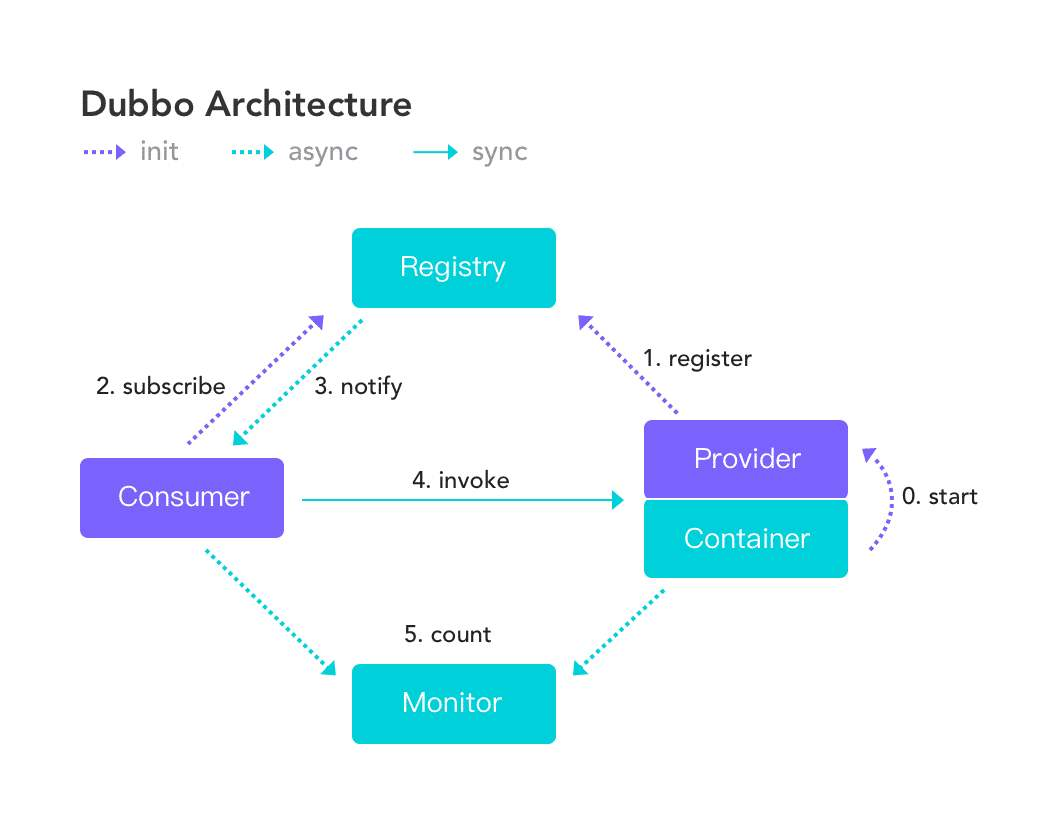
很多人会漏看上面线的示意图,下面解释一下:
紫色虚线:在Dubbo启动时完成的功能 蓝青色的线:都是程序运行过程中执行的功能,虚线是异步操作,实线是同步操作
Provider:提供者,服务发布方。如果是采用SOA开发的模式,这个就是和数据库交互的接口,也就是service主要放在生产者这边
Consumer:消费者,调用服务方。面向前端的Controller主要是在这边,可以远程调用生产者中的方法,生产者发生变化时也会实时更新消费者的调用列表。具体的看下面介绍
Container:Dubbo容器,依赖于Spring容器。这里比较注意的就是Dubbo是依赖与Spring容器的。所以必须要和Spring配合着使用
Registry:注册中心.当Container启动时把所有可以提供的服务列表上Registry中进行注册。作用:告诉Consumer提供了什么服务和服务方在哪里.
Monitor:监听器
三、Dubbo运行原理
就着上面的架构图来看看Dubbo的运行原理:
0.Start: 启动容器,相当于在启动Dubbo的Provider,并且会创建对应的目录结构,例如代码中的共用接口名为com.learnDubbo.demo.DemoService,就会创建 /dubbo/com.learnDubbo.demo.DemoService目录,然后在创建providers目录,再在providers目录下写入自己的 URL 地址。
1.Register:启动后会去注册中心进行注册,注册所有可以提供的服务列表。即订阅/dubbo/com.learnDubbo.demo.DemoService 目录下的所有提供者和消费者 URL 地址。
2.Subscribe:Consumer在启动时,不仅仅会注册自身到 …/consumers/目录下,同时还会订阅…/providers目录,实时获取其上Provider的URL字符串信息。当服务消费者启动时:会在/dubbo/com.learnDubbo.demo.DemoService目录创建/consumers目录,并在/consumers目录写入自己的 URL 地址。
3.notify:当Provider有修改后,注册中心会把消息推送给Consummer。也就是注册中心会对Provider进行观察,这里就是使用设计模式中的观察者模式。以Zookeeper注册中心为例,Dubbo中有ZookeeperRegistry中的doSubscribe方法也就是进行生产者订阅和监听。下面分析一下源码,看看订阅过程
@Override protected void doSubscribe(final URL url, final NotifyListener listener) { try { if (Constants.ANY_VALUE.equals(url.getServiceInterface())) {//根据URL得到服务接口为*,也就是所有 String root = toRootPath(); ConcurrentMap<NotifyListener, ChildListener> listeners = zkListeners.get(url);//拿取URL下的监听器 if (listeners == null) {//不存在则进行创建 zkListeners.putIfAbsent(url, new ConcurrentHashMap<NotifyListener, ChildListener>()); listeners = zkListeners.get(url); } ChildListener zkListener = listeners.get(listener);//得到子目录的监听器 if (zkListener == null) {//无法得到子目录监听器,则会新建一个。 listeners.putIfAbsent(listener, new ChildListener() { @Override public void childChanged(String parentPath, List<String> currentChilds) { for (String child : currentChilds) { child = URL.decode(child); if (!anyServices.contains(child)) { anyServices.add(child); //如果consumer的interface为*,会订阅每一个url,会触发另一个分支的逻辑 //这里是用来对/dubbo下面提供者新增时的回调,相当于增量 subscribe(url.setPath(child).addParameters(Constants.INTERFACE_KEY, child, Constants.CHECK_KEY, String.valueOf(false)), listener); } } } }); zkListener = listeners.get(listener); } zkClient.create(root, false); //添加监听器会返回子节点集合 List<String> services = zkClient.addChildListener(root, zkListener);//订阅root目录下的子元素,比如:/dubbo/com.learnDubbo.demo.DemoService/providers if (services != null && !services.isEmpty()) { for (String service : services) { service = URL.decode(service); anyServices.add(service); subscribe(url.setPath(service).addParameters(Constants.INTERFACE_KEY, service, Constants.CHECK_KEY, String.valueOf(false)), listener); } } } else { //这边是针对明确interface的订阅逻辑 List<URL> urls = new ArrayList<URL>(); //针对每种category路径进行监听 for (String path : toCategoriesPath(url)) { ConcurrentMap<NotifyListener, ChildListener> listeners = zkListeners.get(url); if (listeners == null) { zkListeners.putIfAbsent(url, new ConcurrentHashMap<NotifyListener, ChildListener>()); listeners = zkListeners.get(url); } ChildListener zkListener = listeners.get(listener); if (zkListener == null) { //封装回调逻辑 listeners.putIfAbsent(listener, new ChildListener() { @Override public void childChanged(String parentPath, List<String> currentChilds) { ZookeeperRegistry.this.notify(url, listener, toUrlsWithEmpty(url, parentPath, currentChilds)); } }); zkListener = listeners.get(listener); } //创建节点 zkClient.create(path, false); //增加回调 List<String> children = zkClient.addChildListener(path, zkListener); if (children != null) { urls.addAll(toUrlsWithEmpty(url, path, children)); } } //并且会对订阅的URL下的服务进行监听,并会实时的更新Consumer中的invoke列表,使得能够进行调用。这个方法不展开讲 notify(url, listener, urls); } } catch (Throwable e) { throw new RpcException("Failed to subscribe " + url + " to zookeeper " + getUrl() + ", cause: " + e.getMessage(), e); } }
4、invoke:根据获取到的Provider地址,真实调用Provider中功能。这里就是唯一一个同步的方法,因为消费者要得到生产者传来的数据才能进行下一步操作,但是Dubbo是一个RPC框架,RPC的核心就在于只能知道接口不能知道内部具体实现。所以在Consumer方使用了代理设计模式,创建一个Provider方类的一个代理对象,通过代理对象获取Provider中真实功能,起到保护Provider真实功能的作用。
有兴趣的可以看看invoke调用过程
5、Monitor:Consumer和Provider每隔1分钟向Monitor发送统计信息,统计信息包含,访问次数,频率等
四、总结
这里只是稍微对Dubbo的原理做了一下分析,想要弄懂Dubbo还需要结合源码来看。尽管很多时候我们只是一个使用者,但是能够理解内部运行原理不但能够让我们更好的使用,同时里面的编程思路,设计模式也是我们需要学习的。后面还会做更多关于Dubbo的原理解析。

