一个MySQL 5.7 分区表性能下降的案例分析
告知MySQL5.7.18的使用者分区表使用中存在的陷阱,避免在该版本上继续踩坑。同时通过对源码的讲解,升级MySQL5.7.18时分区表性能下降的根本原因,向MySQL源码爱好者展示分区表实现中锁的运用。
问题描述
MySQL 5.7版本中,性能相关的改进非常多。包括临时表相关的性能改进,连接建立速度的优化和复制分发相关的性能改进等等。基本上不需要做配置修改,只需要升级到5.7版本,就能带来不少性能的提升。
我们在测试环境,把数据库升级到5.7.18版本,验证MySQL 5.7.18版本是否符合我们的预期。观察运行了一段时间,有开发反馈,数据库的性能比之前的5.6.21版本有下降。主要的表现特征是遇到比较多的锁超时情况。开发另外反馈,性能下降相关的表都是分区表。更新走的都是主键。这个反馈引起了我们重视。我们做了如下尝试:
- 数据库的版本为5.7.18, 保留分区表,性能会下降。
- 数据库版本为5.7.18,把表调整为非分区表,性能正常。
- 把数据库的版本回退到5.6.21版本,保留分区表,性能也是正常
通过上述测试,我们大致判定,这个性能下降和MySQL 5.7版本升级有关。
问题重现
测试环境的数据库表结构比较多,并且调用关系也比较复杂。为了进一步分析并定位问题,我们抽丝剥茧,构建了如下一个简单的重现过程。
// 创建一个测试分区表t2:
CREATE TABLE `t2` (
`id` INT(11) NOT NULL,
`dt` DATETIME NOT NULL,
`data` VARCHAR(10) DEFAULT NULL,
PRIMARY KEY (`id`,`dt`),
KEY `idx_dt` (`dt`)
) ENGINE=INNODB DEFAULT CHARSET=latin1
/*!50100 PARTITION BY RANGE (to_days(dt))
(PARTITION p20170218 VALUES LESS THAN (736744) ENGINE = InnoDB,
PARTITION p20170219 VALUES LESS THAN (736745) ENGINE = InnoDB,
PARTITION pMax VALUES LESS THAN MAXVALUE ENGINE = InnoDB) */
// 插入测试数据
INSERT INTO t2 VALUES (1, NOW(), '1');
INSERT INTO t2 VALUES (2, NOW(), '2');
INSERT INTO t2 VALUES (3, NOW(), '3');
// SESSION 1 对id = 1的 记录 做一个更新操作,事务先不提交。
BEGIN;UPDATE t2 SET DATA = '12' WHERE id = 1;
// SESSION 2 对id = 2 的记录做一个更新。
BEGIN;UPDATE t2 SET DATA = '21' WHERE id = 2;
在SESSION 2,我们发现,这个更新操作一直在等待。ID是主键,按道理,主键id = 1 的记录更新,不至于影响到主键id = 2的记录更新。
查询information_schema下的innodb_locks这张表。这张表是用于记录InnoDB事务尝试申请但还未获取的锁,以及阻塞其他事务的事务所拥有的锁。有两条记录:
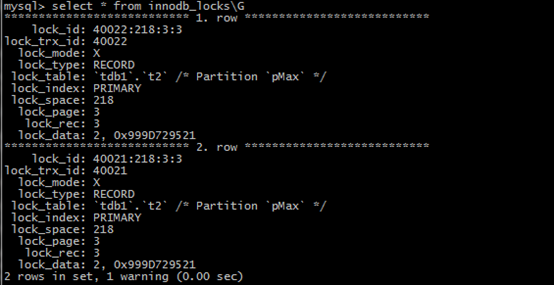
观察此时的innodb_locks表,事务id=40021锁住第3页的第2行记录,导致事务id=40022无法进行下去。
我们把数据库回退到5.6.21版本,则不能重现上述场景。
进一步分析
根据innodb_locks表提供的信息,我们知道问题在于InnoDB锁定了不恰当的行。该表是memory存储引擎。我们在memory 存储引擎的插入接口设置断点,得到如下堆栈信息。确定是红框部分,将锁信息写入到innodb_locks表中。
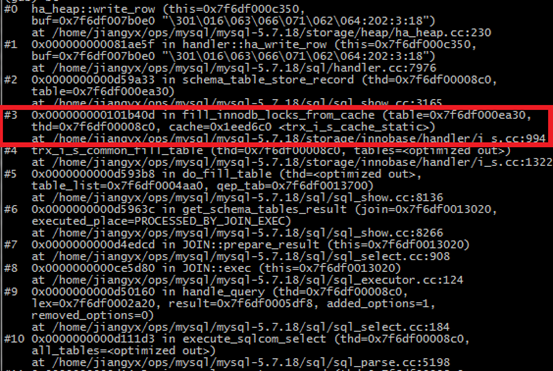
并在函数fill_innodb_locks_from_cache中得以确认,每次写入行的数据,都是从如下代码中Cache对象中获取的。
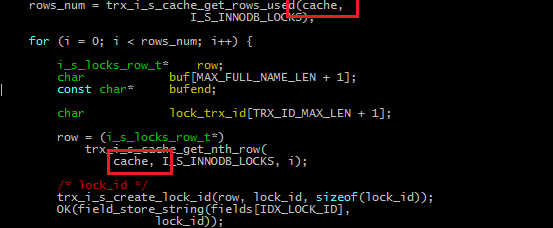
我们知道Cache中保存了事务锁的信息,因此需要进一步查找Cache中的数据,是如何添加进去的。通过搜索cache对象在innodb代码中出现的位置,找到函数add_lock_to_cache。在此函数设置断点进行调试后,发现其内容与填写innodb_locks表的数据一致。确定该函数使用的lock对象,就是我们要找的锁对象。
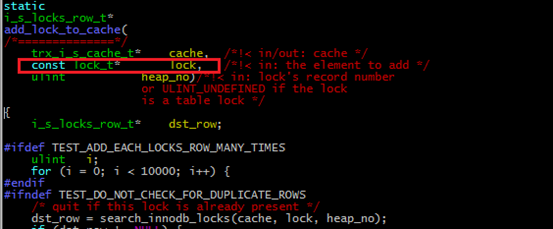
针对lock_t 类型的使用位置进行排查。经过筛选和调试,发现函数RecLock::lock_add中,生成的行锁被加入到该锁所在的事务链表中。
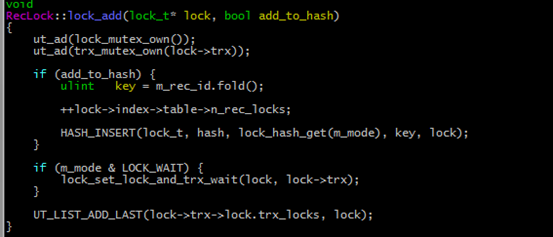
RecLock::lock_add函数可以推出行锁的生成原因。因此,通过对该函数进行断点设置,查看函数堆栈,在如下堆栈内,定位到红框位置的函数:
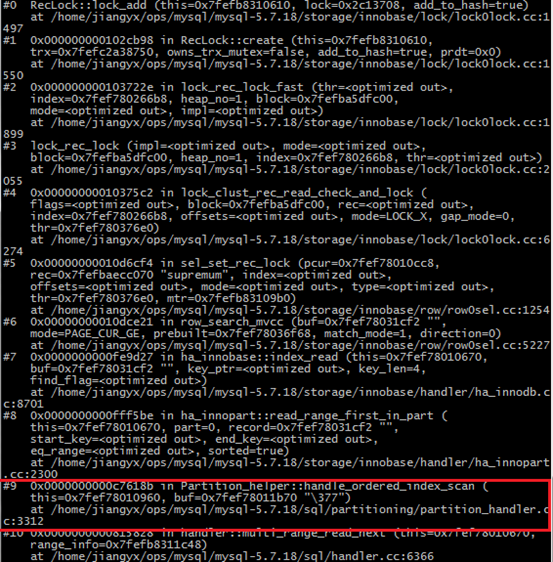
针对Partition_helper::handle_ordered_index_scan的如下代码进行跟踪,根据该段代码的分析,m_part_spec.end_part 决定了进行上锁的最大行数,此处即为非正常行锁生成的原因。

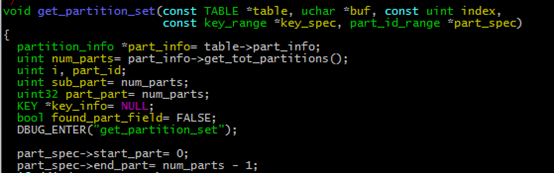
最终问题归结到m_part_spec.end_part 的生成原因。通过对end_part 使用地方进行排查,最终在get_partition_set函数中定位到该变量在使用前的初始设置值。从代码中可以看出,每次单条记录的update操作,在进行index scan上锁时,对分区表数目相同的行数进行上锁。这个是根本原因。
验证结论
根据之前的分析,每次单条记录的update操作,会对分区表数目相同的行数进行上锁。我们尝试验证我们的发现。
新增如下两条记录:
INSERT INTO t2 VALUES (4, NOW(), '4');
INSERT INTO t2 VALUES (5, NOW(), '5');
// SESSION 1 对id = 1的 记录 做一个更新操作,事务先不提交。
BEGIN;UPDATE t2 SET DATA = '12' WHERE id = 1;
// SESSION 2 现在对id = 4 的记录做一个更新。
BEGIN;UPDATE t2 SET DATA = '44' WHERE id = 4;
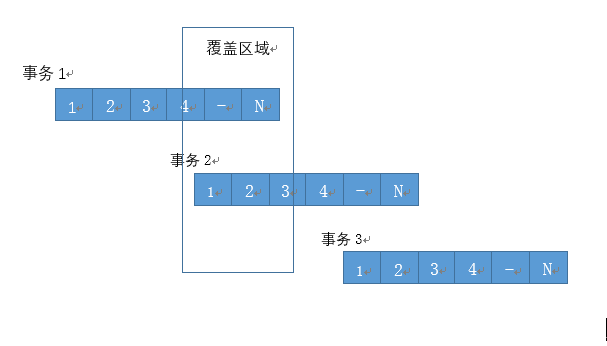
我们发现,对id = 4的更新可以正常进行。不会受到id = 1 的更新影响。这是因为id=4的记录,超过了测试案例的分区个数,不会被锁住。在实际应用中,分区表所定义分区数不会如测试用例中的只有3个,而是数十个乃至数百个。这样进行上锁的结果,将加剧更新情况下的锁冲突,导致事务处于锁等待状态。如下图所示,每个事务都上N个行锁,那么这些上锁记录互相覆盖的可能性就极大的提高,也就导致并发下降,效率降低。
结论
通过上述分析,我们非常确认,这个应该是MySQL 5.7版本的一个regression.我们提交了一个Bug到开源社区。Oracle确认是一个问题。需进一步分析调查这个Bug.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号