01 Spark架构与运行流程
1. 阐述Hadoop生态系统中,HDFS, MapReduce, Yarn, Hbase及Spark的相互关系,为什么要引入Yarn和Spark。
答:
Hadoop是一个能够对大量数据进行分布式处理的软件框架。具有可靠、高效、可伸缩的特点。
Hadoop的核心是HDFS和MapReduce,hadoop2.0还包括YARN。
HDFS:负责海量数据的存储。
YARN:负责海量数据运算时的资源调度。
MapReduce:它其实是一个应用程序开发包。
从开源角度看,YARN的提出,从一定程度上弱化了多计算框架的优劣之争。YARN是在Hadoop MapReduce基础上演化而来的,在MapReduce时代,很多人批评MapReduce不适合迭代计算和流失计算,于是出现了Spark和Storm等计算框架,而这些系统的开发者则在自己的网站上或者论文里与MapReduce对比,鼓吹自己的系统多么先进高效,而出现了YARN之后,则形势变得明朗:MapReduce只是运行在YARN之上的一类应用程序抽象,Spark和Storm本质上也是,他们只是针对不同类型的应用开发的,没有优劣之别,各有所长,合并共处,而且,今后所有计算框架的开发,不出意外的话,也应是在YARN之上。这样,一个以YARN为底层资源管理平台,多种计算框架运行于其上的生态系统诞生了。
从架构和应用角度上看,spark是一个仅包含计算逻辑的开发库(尽管它提供个独立运行的master/slave服务,但考虑到稳定后以及与其他类型作业的继承性,通常不会被采用),而不包含任何资源管理和调度相关的实现,这使得spark可以灵活运行在目前比较主流的资源管理系统上,典型的代表是mesos和yarn,我们称之为“spark on mesos”和“spark on yarn”。将spark运行在资源管理系统上将带来非常多的收益,包括:与其他计算框架共享集群资源;资源按需分配,进而提高集群资源利用率等。
2. Spark已打造出结构一体化、功能多样化的大数据生态系统,请简述Spark生态系统。
MapReduce的局限性:代码繁琐、只能支持map和reduce方法、执行效率低下、不适合迭代多次、交互式、流式的处理。
Spark是基于内存计算的大数据分布式计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
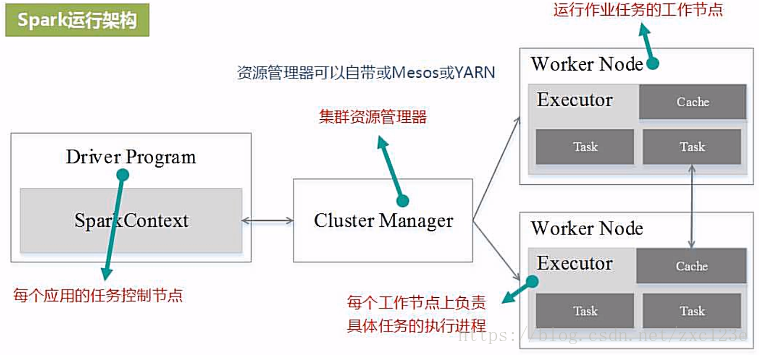
3. 用图文描述你所理解的Spark运行架构,运行流程。
4. 软件平台准备:Linux-Hadoop。
- Linux系统的安装
http://dblab.xmu.edu.cn/blog/285/
- 在Windows中使用VirtualBox安装Ubuntu
http://dblab.xmu.edu.cn/blog/337-2/
- Linux系统的常用命令
http://dblab.xmu.edu.cn/blog/1624-2/
- 在Windows系统中利用FTP软件向Ubuntu系统上传文件
http://dblab.xmu.edu.cn/blog/1608-2/
- Linux系统中下载安装文件和解压缩方法
http://dblab.xmu.edu.cn/blog/1606-2/
- Linux系统中vim编辑器的安装和使用方法
http://dblab.xmu.edu.cn/blog/1607-2/
- Hadoop的安装和使用
http://dblab.xmu.edu.cn/blog/install-hadoop/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号